
正则表达式


# 场景 # 在发短信之前应该先来验证一下 手机号码是不是正确 # 邮箱地址 # 身份证号 # 爬虫 # 访问一个网页,网页源代码 # 对于pyhon来说 是一串字符串 # 从一大段的文字当中提取你想要的数据 # 正则表达式的常见使用场景 # 1.判断某一个字符串是否符合规则 注册页-判断手机号、身份证号 是否合法 # 2.将符合规则的内容从一个庞大的字符串体系当中提取出来 爬虫、日志分析 # 什么是正则表达式? 只和字符串打交道 # 是一种规则 来约束字符串的规则 # [1234567890] # 字符组 是元字符中的一个 # 在字符组中所有的字符都可以匹配任意一个字符位置上能出现的内容 # 如果在字符串中有任意一个字符是字符组中的内容,那么就是匹配上的项 # [0-9] # [a-z] # [A-Z] # ascii编码小的值 指向一个大的值 也就是a的编码是97 ,z的是122 A的是65 Z的是90 ,可以混合匹配,比如A-a ,这样在ascii里会夹杂一些其他字符匹配。 # [0-9a-zA-Z] # [1-9][0-9] # \d表示匹配一个数字 [0-9] # 元字符 # \w word \d digit \s space \n next \t tab \W \D \S # 元字符 # \w \d \s \W \D \S \n \t 匹配特殊的字符 # ^ $ \b # 匹配边界 # [] [^] # 字符组相关的 # | # 或 # () # 分组 # . # 匹配除了换行符之外的任意字符 # 写一个正则规则匹配一个手机号码 # 量词 # ?+ * {n} {n,} {n,m} # \d+整数 # \d+\.\d+ 小数 # \d+\.\d+|\d+ 整数或者小数 # \d+(\.\d+)? # 贪婪匹配 : 正则会尽量多的帮我们匹配 # 默认贪婪 回溯算法 # 非贪婪匹配 :会尽量少为我们匹配 # 量词?表示非贪婪 惰性匹配 # .*?x 表示匹配任意长度任意字符遇到一个x就立即停止 # 身份证号码是一个长度为15或18个字符的字符串, # 如果是15位则全部 数字组成,首位不能为0; [1-9]\d{14} # 如果是18位,首位不能为0 前17位全部是数字,末位可能是数字或x [1-9]\d{16}[\dx] # [1-9]\d{16}[\dx]|[1-9]\d{14} # [1-9]\d{14}(\d{2}[\dx])? # 匹配网址 # www\.(baidu|oldboy|qq)\.com # www.baidu.com # www.oldboy.com # www.qq.com # 元字符 # 元字符 量词 # 元字符 量词 ? 在量词的范围内尽量少的匹配这个元字符 # 分组 对某些固定的内容做量词约束 # 或 把长的放前面 # 转义符 # pattern = r'\\n' # s = r'\n'
一说规则我已经知道你很晕了,现在就让我们先来看一些实际的应用。在线测试工具 http://tool.chinaz.com/regex/
首先你要知道的是,谈到正则,就只和字符串相关了。在我给你提供的工具中,你输入的每一个字都是一个字符串。
其次,如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的。
比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上。这连python的字符串操作都可以轻松做到。
那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
正则 |
待匹配字符 |
匹配 |
说明 |
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 |
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
字符:
元字符 |
匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的边界 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W |
匹配非字母或数字或下划线 |
| \D |
匹配非数字 |
| \S |
匹配非空白符 |
| a|b |
匹配字符a或字符b |
| () |
匹配括号内的表达式,也表示一个组 |
| [...] |
匹配字符组中的字符 |
| [^...] |
匹配除了字符组中字符的所有字符 |
量词:
量词 |
用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
. ^ $
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有"海."的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
* + ? { }
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
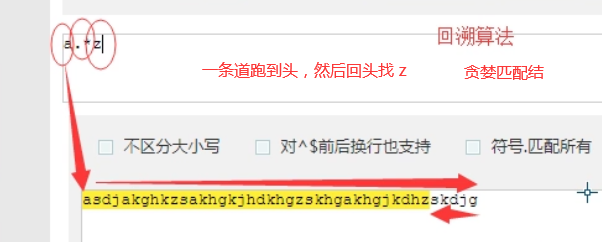
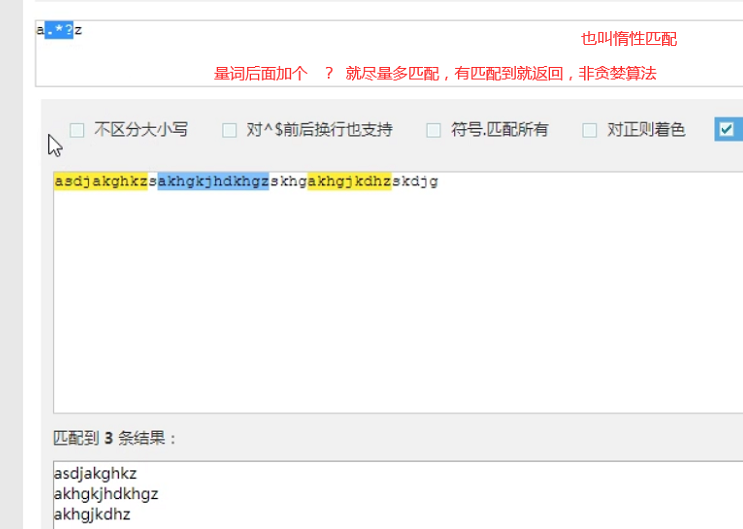
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.*? | 李杰和李莲英和李二棍子 | 李 李 李 |
惰性匹配 |
字符集[][^]
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李[杰莲英二棍子]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰莲英二棍子]的字符任意次 |
| 李[^和]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配一个不是"和"的字符任意次 |
| [\d] | 456bdha3 |
4 |
表示匹配任意一个数字,匹配到4个结果 |
| [\d]+ | 456bdha3 |
456 |
表示匹配任意个数字,匹配到2个结果 |
分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部🈶️数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
或:使用或的时候把长的放前面
分组:对某些固定内容的量词进行约束
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配这串数字,但这并不是一个正确的身份证号码,它是一个16位的数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
现在不会匹配错误的身份证号了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
|
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \n | \n | False |
因为在正则表达式中\是有特殊意义的字符,所以要匹配\n本身,用表达式\n无法匹配 |
| \\n | \n | True |
转义\之后变成\\,即可匹配 |
| "\\\\n" | '\\n' | True |
如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r'\\n' | r'\n' | True |
在字符串之前加r,让整个字符串不转义 |
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> |
<script>...<script> |
<script>...<script> |
默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | r'\d' |
<script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法

. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
re模块下的常用方法
import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() print(ret) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : 'a' ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果

注意:
1 findall的优先级查询:
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
2 split的优先级查询
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
import re # 从一个字符串中获取要匹配的内容 # findall ****半 # 列表 # search ***** 验证用户输入内容 '^正则规则$' # ret = re.search('^\d+','293ahs293djjk293sahf2938u') # print(ret) # match 验证用户输入内容 # ret = re.match('\d+','293ahs293djjk293sahf2938u') # print(ret) # print(ret.group()) # 切割split # s1 = 'alex||egon|boss_jin' # print(s1.split('|')) # s = 'alex8123egon1120boss_jin' # ret = re.split('\d+',s) # print(ret) # ret = re.split('(\d+)',s) # (\d)+ \d\d\d\d\d...(\d) # print(ret) # ret = re.split('\d(\d)',s) # print(ret) # 替换sub # s = 'alex|egon|boss_jin' # print(s.replace('|','-')) # s1 = 'alex8123egon1120boss_jin626356' # ret = re.sub('\d+','|',s1) # print(ret) # ret = re.sub('\d+','|',s1,1) # print(ret) # ret = re.subn('\d+','|',s1) # print(ret) # compile ****半 编译正则规则 # com = re.compile('\d+') # print(com) # ret = com.search('abc1cde2fgh3skhfk') # print(ret.group()) # ret = com.findall('abc1cde2fgh3skhfk') # print(ret) # ret = com.finditer('abc1cde2fgh3skhfk') # for i in ret: # print(i.group()) # finditer ****半 节省空间的方法 # ret = re.finditer('\d+','abc1cde2fgh3skhfk') # print(ret) # for i in ret: # print(i.group()) # findall search # compile finditer # 分组命名、分组约束 # 前端 # <h1>函数</h1> # <h2>初识函数</h2> # 花花绿绿的样式 # 实际上对于前端语言来说 都是把不同样式的字体放在不同的标签中 # 标签语言 # <h1>函数</h1> # <a>函数</a> # <(.*?)>.*?</(.*?)> # # pattern = '<(?P<tag>.*?)>.*?</(?P=tag)>' # ret = re.search(pattern,'<h1>函数</h1>') # print(ret) # if ret: # print(ret.group()) # print(ret.group(1)) # print(ret.group('tag')) # pattern = r'<(.*?)>.*?</\1>' # ret = re.search(pattern,'<a>函数</a>') # print(ret) # if ret: # print(ret.group()) # print(ret.group(1)) # (?:正则表达式) 表示取消优先显示功能 # (?P<组名>正则表达式) 表示给这个组起一个名字 # (?P=组名) 表示引用之前组的名字,引用部分匹配到的内容必须和之前那个组中的内容一模一样
综合练习与扩展
1、匹配标签
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group('名字')拿到对应的值 print(ret.group('tag_name')) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group()) #结果 :<h1>hello</h1>
2、匹配整数
import re ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '2', '60', '40', '35', '5', '4', '3'] ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '-2', '60', '', '5', '-4', '3'] ret.remove("") print(ret) #['1', '-2', '60', '5', '-4', '3']
3、数字匹配
1、 匹配一段文本中的每行的邮箱 http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、 一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 6、 匹配出所有整数
4、爬虫练习
import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__ == '__main__': count=0 for i in range(10): main(count) count+=25
import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) count += 25
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
课后练习题
# 1、匹配整数或者小数(包括正数和负数) # 2、匹配年月日日期 格式2018-12-31 # 3、匹配qq号 5-12 # 4、11位的电话号码 # 5、长度为8-10位的用户密码 : 包含数字字母下划线 # 6、匹配验证码:4位数字字母组成的 # 7、匹配邮箱地址 邮箱规则 # 8、从类似 # <a>wahaha</a> # <b>banana</b> # <h1>qqxing</h1> # <h1>q</h1> # 这样的字符串中, # 1)匹配出wahaha,banana,qqxing内容。 # 2)匹配出a,b,h1这样的内容 a = '1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))' # 9、1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)) # 1)从上面算式中匹配出最内层小括号以及小括号内的表达式 # 10、从类似9.0-2.22*5/3+7/3*99/4*2998+10*568/14的表达式中匹配出从左到右第一个乘法或除法
# 1、匹配整数或者小数(包括正数和负数) # -?\d+(\.\d+)? # 2、匹配年月日日期 格式2018-12-31 # [1-9]\d{3}-(0?[1-9]|1[0-2])-(0?[1-9]|[12]\d|3[01]) # 3、匹配qq号 5-12 # [1-9]\d{4,11} # 4、11位的电话号码 # 1[3-9]\d{9} # 5、长度为8-10位的用户密码 : 包含数字字母下划线 # \w{8,10} # 6、匹配验证码:4位数字字母组成的 # [\da-zA-Z]{4} # 7、匹配邮箱地址 邮箱规则 # 邮箱规则 # @之前必须有内容且只能是字母(大小写)、数字、下划线(_)、减号(-)、点(.) # @和最后一个点(.)之间必须有内容且只能是字母(大小写)、数字、点(.)、减号(-),且两个点不能挨着 # 最后一个点(.)之后必须有内容且内容只能是字母(大小写)、数字且长度为大于等于2个字节,小于等于6个字节 # [\w\-.]+@[\da-zA-Z\-]+(\.[\da-zA-Z\-]+)*\.[a-zA-Z\d]{2,6} # 126 163 qq hotmail sina # 8、从类似 # <a>wahaha</a> # <b>banana</b> # <h1>qqxing</h1> # <h1>q</h1> # 这样的字符串中, # 1)匹配出wahaha,banana,qqxing内容。 # 2)匹配出a,b,h1这样的内容 # import re # ret = re.findall('<(.*?)>(.*?)<.*?>','<a>wahaha</a>') # print(ret[0][1]) # print(ret[0][0]) # ret = re.findall('<(.*?)>.*?<.*?>','<a>wahaha</a>') # print(ret) # ret = re.search('<(.*?)>(.*?)<.*?>','<a>wahaha</a>') # print(ret.group(2)) # print(ret.group(1)) a = '1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))' # 9、1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)) # 1)从上面算式中匹配出最内层小括号以及小括号内的表达式 # \([^()]+\) # 10、从类似9.0-2.22*5/3+7/3*99/4*2998+10*568/14的表达式中匹配出从左到右第一个乘法或除法 # \d+(\.\d+)?[*/]-?\d+(\.\d+)? # '2*3/4*5' 乘除法 exp = '2*3/4*5' import re def mul_div(son_exp): if '*' in son_exp: a, b = son_exp.split('*') mul = str(float(a) * float(b)) # 6 return mul elif '/' in son_exp: a, b = son_exp.split('/') div = str(float(a) / float(b)) # 6 return div # '6/4*5 while True: ret = re.search('\d+(\.\d+)?[*/]-?\d+(\.\d+)?',exp) if ret: son_exp = ret.group() # '2*3' res = mul_div(son_exp) exp = exp.replace(son_exp,res) else:break print(exp)
# 2、匹配年月日日期 格式2018-12-31 # [1-9]\d{3}-(0?[1-9]|1[0-2])-([12]\d|3[01]|0?[1-9]) #调整了下日的顺序,否则匹配了3 就不往下匹配了。
作业
实现能计算类似
1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式的计算器程序
import re def cal_atom(exp): # '2/5' if '*' in exp: a,b = exp.split('*') return str(float(a)*float(b)) if '/' in exp: a,b = exp.split('/') return str(float(a)/float(b)) def exp_format(exp): exp = exp.replace('--','+') exp = exp.replace('+-','-') exp = exp.replace('++','+') exp = exp.replace('-+','-') return exp # 加减乘除 def inner_bracket(s): while True: parttern = r'\d+(\.\d+)?[*/]-?\d+(\.\d+)?' ret = re.search(parttern, s) if ret: exp = ret.group() res = cal_atom(exp) s = s.replace(exp, res) else:break s = exp_format(s) ret = re.findall('[-+]?\d+(?:\.\d+)?', s) count = 0 for i in ret: count += float(i) return count # 去除括号 def remove_bracket(s): while True: ret = re.search('\([^()]+\)',s) if ret: no_bracket = ret.group() res = inner_bracket(no_bracket) s = s.replace(no_bracket,str(res)) s = exp_format(s) else:return s def main(s): s = s.replace(' ', '') s = remove_bracket(s) return inner_bracket(s) s = '1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )' ret = main(s) print(ret)
import re def cal_atom(exp): # '2/5' if '*' in exp: a,b = exp.split('*') return str(float(a)*float(b)) if '/' in exp: a,b = exp.split('/') return str(float(a)/float(b)) def exp_format(exp): exp = exp.replace('--','+') exp = exp.replace('+-','-') exp = exp.replace('++','+') exp = exp.replace('-+','-') return exp # 加减乘除 def inner_bracket(s,muldiv_re,addsub_re): while True: ret = muldiv_re.search(s) if ret: exp = ret.group() res = cal_atom(exp) s = s.replace(exp, res) else:break s = exp_format(s) ret = addsub_re.findall(s) count = 0 for i in ret: count += float(i) return count # 去除括号 def remove_bracket(s,breacket_re,muldiv_re,addsub_re): while True: ret = breacket_re.search(s) if ret: no_bracket = ret.group() res = inner_bracket(no_bracket,muldiv_re,addsub_re) s = s.replace(no_bracket,str(res)) s = exp_format(s) else:return s def main(s): breacket_re = re.compile('\([^()]+\)') muldiv_re = re.compile( r'\d+(\.\d+)?[*/]-?\d+(\.\d+)?') addsub_re = re.compile( '[-+]?\d+(?:\.\d+)?') s = s.replace(' ', '') s = remove_bracket(s,breacket_re,muldiv_re,addsub_re) return inner_bracket(s,muldiv_re,addsub_re) s = '1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )' ret = main(s) print(ret)
#camgl333 import time class csdnfind: def __init__(self): #初始化 self.file = open(r'D:\CSDN-中文IT社区-600万\CSDN-中文IT社区-600万\www.csdn.net.sql',mode='rb') def menload(self):#加载内存 self.filelist = self.file.readlines() self.file.seek(0,0) def memfind(self,findstr): #内存查 for list in self.filelist: list = list.decode('gbk',errors='ignore') #解码 linelist = list.split(' # ') if findstr == linelist[0]: print(list) def diskfind(self,findstr): #硬盘查 self.file.seek(0,0) while True: line = self.file.readline() if not line: break line = line.decode('gbk', errors='ignore') # 解码 linelist = line.split(' # ') if findstr == linelist[0]: print(line) def findtime(self,fun,findstr,seachtype): statime = time.time() fun(findstr) endtime = time.time() print(seachtype,'用了多少时间%s秒' % (endtime - statime) ) def __del__(self): #关闭文件 self.file.close() csdn = csdnfind() csdn.menload() print('内存加载完成') csdn.findtime(csdn.memfind,'camgl333','内存查找') csdn.findtime(csdn.diskfind,'camgl333','硬盘查找')
ps:部分内容来自于互联网整理,如有侵权请联系我们,我们会在看到通知后24小时内做出处理。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号