Python基础知识
知识目录
1、变量
2、编码
3、格式化输出
4、各种运算符
5、while循环
6、字符串
7、列表
8、字典
9、元组
10、集合
11、异常处理
12、线程和进程
13、文件操作
万年第一步
print('hello world')
变量
变量的作用:
就是,存储任何类型的数据和内容,就是方便以后再用的时候调用
变量定义的规则:
变量名只能是 字母、数字或下划线的任意组合
变量名的第一个字符不能是数字
变量名是区分大小写的,大写的name和小写的name是两个不相同的变量名
变量名有一定的描述意义
以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
Python中的关键字列表:
查看关键字的方法:
import keyword for i in keyword.kwlist: print(i)
False, None, True, and, as, assert, break, class, continue, def, del, elif, else, except, finally, for,
from, global, if, import, in, is, lambda, nonlocal, not, or, pass, raise, return, try, while, with, yield,
编码(coding)
ascll:最初的编码表 (一个字符占用一个字节)
gb2312:中国的第一个编码表(一共收录了7445个字符,包括6763个汉字和682个其它符号)
gbk1.0:还是中国的编码表,但是收入的汉字多一些(1995年的汉字扩展规范GBK1.0收录了21886个符号)
gb18030:也是中国的编码表,收入的汉字已经多达27000左右,还要注意的是现在的windowns系统默认的编码还是gb18030(取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字)
Unicode:因为当时的有很多的字符编码表,所以ISO(国际标准组织)就新搞了一个表收入了每个国家和地区的字符编码,这张编码表就叫做Unicode,每个字符占用两个字节
utf-8:因为当时考虑到,有些英文字符占用一个字节就可以了,所以避免一定的内存浪费,就出现了utf-8(可变长度编码),ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存... (英文占用一个字节,中文占用三个字节)
在Python2 中默认的编码为 ascll
在Python3 中默认的编码为 utf - 8
举例:
将utf - 8 转化成 gbk : string.decode('utf - 8') 将utf- 8 解码为Unicode string.decode('utf - 8').encode(' gbk ') 将Unicode 编码为 gbk
注释
单行注释:#
多行注释:''' ''' 或者 """ """
格式化输出:(实现动态赋值)
1、使用占位符,实现格式化输出
举例:
print('%s is a good man ', % marry) 运行结果: marry is a good man
2、使用字符串的format方法:(format中的{ }相当于的作用类似于一个占位符)
举例:
print(" { } is a good man " .format(marry)) 运行结果: marry is a good man
用户输入
input('please input your name:')
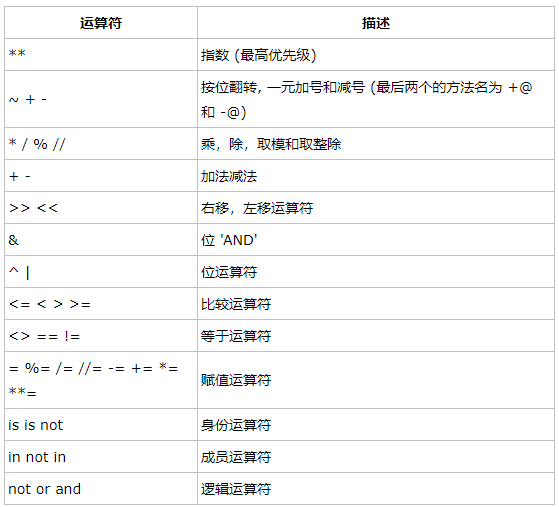
各种运算符
算术运算符
+ 加法
— 减法
* 乘法
/ 除法(结果可能是浮点数)
// 除法(结果向上取整,例如9//2 = 4)
% 取余(结果是两个数相除的余数)
比较运算符
>
<
==
<=
>=
!=
逻辑运算符
and
or
not
赋值运算符
=
+=
-=
/=
*=
%=
成员运算符
in
not in
身份运算符
is
is not
运算的优先级:
while循环
格式:
while 条件一: 符合条件执行的动作 while 条件一: 语句 else: 当while循环正常执行的时候,才会执行else的语句,也就是当while没有break语句的时候 注意: break: 直接跳出循环 continue : 跳出某次循环
end= 这个方法是将你所有在同一个循环内的东西合并在一行输出
Python 内置的进制转换方法
十进制转换二进制 :bin(十进制数字)
十进制转换八进制 :otc(十进制数字)
十进制转换十六进制 : hex(十进制数字)
二进制转换十进制 : int(二进制数字,2)
八进制转换十进制 : int(八进制数字,8)
十六进制转换十进制 : int(十六进制数字,16)
chr() 将ascll码转换为相应的字符
ord() 返回相应字符的ascll码值
注意: 其他类型的数据转换,就按照这几种嵌套来进行转换
Python之禅
import this
print(this.s)
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Gur Mra bs Clguba, ol Gvz Crgref
Ornhgvshy vf orggre guna htyl.
Rkcyvpvg vf orggre guna vzcyvpvg.
Fvzcyr vf orggre guna pbzcyrk.
Pbzcyrk vf orggre guna pbzcyvpngrq.
Syng vf orggre guna arfgrq.
Fcnefr vf orggre guna qrafr.
Ernqnovyvgl pbhagf.
Fcrpvny pnfrf nera'g fcrpvny rabhtu gb oernx gur ehyrf.
Nygubhtu cenpgvpnyvgl orngf chevgl.
Reebef fubhyq arire cnff fvyragyl.
Hayrff rkcyvpvgyl fvyraprq.
Va gur snpr bs nzovthvgl, ershfr gur grzcgngvba gb thrff.
Gurer fubhyq or bar-- naq cersrenoyl bayl bar --boivbhf jnl gb qb vg.
Nygubhtu gung jnl znl abg or boivbhf ng svefg hayrff lbh'er Qhgpu.
Abj vf orggre guna arire.
Nygubhtu arire vf bsgra orggre guna *evtug* abj.
Vs gur vzcyrzragngvba vf uneq gb rkcynva, vg'f n onq vqrn.
Vs gur vzcyrzragngvba vf rnfl gb rkcynva, vg znl or n tbbq vqrn.
Anzrfcnprf ner bar ubaxvat terng vqrn -- yrg'f qb zber bs gubfr!
字符串(string)
Python中字符串的方法
string.split( ) 这个方法实现以什么字符对一个字符串进行切片,然后存在一个列表中,参数是分隔符
python 中的print支持直接回车换行,虽然是不符合pep8规范 ,但是也是可行的
string.lower() 将所有的字母变成小写
string.upper() 将所有的字母变成大写
string.title() 以空格为分隔符,每个单词的首字母大写
string.capitalize() 将整个字符串的第一个字母大写
string.swapcase() 将大写变小写,小写变大写
string.islower() 判断是否 全为小写,返回布尔值
string.isupper() 判断是否 全为大写,返回布尔值
string.istitle() 判断是否 每个单词的首字母大写
‘ 分隔符 ’.join(list or tuple) 以分隔符连接列表或者元祖中的字符串 (用于拼接路径和网址的好方法)
string.split('分隔符') 以分隔符对字符串进行切片,将每个元素存在一个列表中返回
string.replace('befor', 'after') 对字符串中的元素进行替换 (当字符串中有多个符合条件的字符时,可以有第三个参数,可以指定替换的次数)
string.center(50,' * ') 将字符串放在最中间
string,rjust() 放在最右边
string.ljust() 放在最左边
srting.endswith() 判断句末的字符串
string.strartswith() 判断句首的字符串 (用来对文件中的行进行操作时的重要判断方法)
字符和ascll之间的转换关系
97 == a
122 == z
65 == A
90 == Z
ord() 方法:将字符转换为对应的ascll
chr() 方法:将ascll转换为对应的字符
列表(list)
对列表进行增删改查的操作
列表的样子(格式): name(变量名) = [1, 'jakf ' ,[ ]] 列表中可以存入各种的数据类型的元素
对列表进行增删改查:
增 (添加):
1、 list.append() 这个方法可以在列表中实现增加内容的功能,但是他增加的内容都只是在列表的最后进行一个追加的动作,有时候会显得不够灵活
2、list.insert() 这个方法就很好的弥补了append方法的不足,他可以在列表的任意索引处进行新元素的添加,这个方法需要两个参数,第一个参数,是需要将新元素添加到的索引,第二个参数是你需要添加的新的元素
查:
我们还可以对列表进行切片,也就是可以从列表中取出你想要的元素:
list[起始位置:结束位置:步长]
注意注意:他们三个参数之间使用冒号隔开的,当你需要对列表进行反向的操作时,就可以将步长设置为负一,当然任意的设置需要操作的范围,列表的切片的方法是很灵活的
删(实现删除列表中的某一个元素):
一共三种方法:
1. list.remove() 这个方法的参数是列表中的一个元素,有返回值,但是返回值为None,也就是返回值为空
2.list.pop() 这个方法的参数是你想要删除的元素在列表中对应的索引,但是这个方法是有返回值的,他的返回值正好就是你删除的元素,如果你想要对所删除的元素,进行某种判断或者某种操作的时候,也是很好用的
3.del list[索引] (比较霸气侧漏)) 这个方法是根据是先把,你想要删除的内容,通过索引取出来直接del删除,无返回值
改:
对列表进行修改的原理是,首先将你需要进行修改的元素,利用索引的方法,取出然后重新赋值就可以了
关于列表的几个常用的方法:
list.count() 这个方法的参数可以是列表中任意的一个元素,这个方法的返回值是参数在列表中的个数
list.insert() 可以指定的向列表中的某个位置插入内容
list.index() 参数是一个列表中的内容,返回的是他的在这个列表中的对应的索引值
list.sort() 将你的列表进行从大到小的排序,但是这个方法可以有一个参数,reverse = True 可以直接让排序后的列表然后再实现一个倒叙的操作,注意他是没有返回值的
sorted(list) 和list.sort() 的方法是相同的,但是这个方法是有返回值得,你可以通过变量赋值来拿到返回值,sort和sorted 的区别:返回值的有无
list.reverse() 将列表倒叙输出
list 1.extend(list 2) 这个方法是将list2中的元素全部一次的添加在list1 的末尾,但是只是对list1进行的改变,list 2还是原来的值,没有发生改变
list.append() 添加元素
list.remove() 参数是一个列表内的元素,删除,返回值为None
list.pop() 参数是列表内元素的索引值,删除,但是有返回值,返回值就是删除的元素
del list[ ] del 方法可以理解为相对来说一种比较粗暴的方法了,直接删除列表中的元素,甚至可以直接删除整个列表
list[ : : :] 对列表进行切片操作
enumerrate(list) 返回每个元素和相应的序号
难点:深浅拷贝
首先说一下变量存储是的原理:开辟一块内存空间来存储一个数据,但是一个变量存储的这个数据在内存中那块空间的内存地址,也就是变量指向的是内存地址,而内存地址指向的是原数据
拷贝的内容和之前的原内容共享的数据就是当一个改变另一个就会改变
调用copy模块(深拷贝)
浅拷贝(shallow copy):当你需要拷贝的数据中还有一层数据的时候,拷贝出来的数据和之前的原数据还是有联系的,换句话说就是浅拷贝只是拷贝第一层,第二层的数据就是共享的(也就是一个改变,另一个也是会变的)
深拷贝(deepcopy):当你对一个数据进行深拷贝的时候,拷贝出来的数据和原数据是没有任何联系的(也就是说,一个改变,另一个没有任何的改变)
深拷贝实例:
import copy test_list = [345, ['3', '4']] new_list = copy.deepcopy(test_list) # 深拷贝,原数据和拷贝数据没有任何关系 new_list[1][1] = 'sjklf' print(test_list) print(new_list)
元组(tuple)
元组和列表类似,元组和列表的区别就是,元组是只读的,而列表支持所有的增删改查
所以,元素也叫只读列表
集合(set)
集合的类型:
可变类型(set):
集合是无序的,也就是说不能通过索引来取值,在集合中取值有两种方法,一,for循环迭代取值 二,迭代器取值
创建集合有两种方法:
一,利用关键字创建集合,这种的创建方法也叫做工厂方法
二,直接使用大括号创建,但是注意集合和字典还有列表是不一样的,利用大括号创建的时候,大括号中必须有值
集合的特性:
集合的机制会直接pass掉集合中重复的内容,对于重复的内容只输出一次
* 集合中的内容必须是可哈希(不可变)的、
可变集合,可以实现增删改查,它的本身就是一个可变的数据类型,所以不能作为字典的键
可变集合的一些方法:
set.add() 只能添加一个元素
set.update() 将方法中的参数作为一个序列,将序列中的每个元素,分开存在集合中
set.pop() 随机删除(因为集合是无序的)
set.remove() 删除集合中的某一个元素
set.clear() 清空集合中的内容,但是不会删除集合本身,剩一个空的集合
集合的关系测试:
交集:
set_a.union(set_b)
set_a & set_b
并集:
set_a.intersection(set_b)
set_a | set_b
差集:
set_a.difference(set_b)
set_a - set_b
反差集:
set_a.symmetric_difference(set_b)
set_a ^ set_b
子集:
set_a.issuperset(set_b)
set_a > set_b
不可变类型(frozenset):
可以作为字典的键,本身是可哈希的数据类型,和元组,字符串一样,不能实现增删改
字典(dictionary)
字典是Python中唯一的一种映射类型,采用键值对的形式存储数据,Python对key进行哈希函数运算,根据计算的结果决定value的存储地址
所以字典是无序存储的,且key必须是可哈希的,可哈希表示key必须是不可变类型,如:数字,字符串,元组
字典是除列表以外Python之中最灵活的内置数据结构类型,列表是有序的对象的结合,字典是无序的对象集合,两者之间的区别在于:字典中个的元素是通过键来存取的,而不是通过偏移存取
注意:可哈希类型就是不可变类型的数据,不可哈希类型的就是可变数据类型
字典的两个特点:1.字典是无序的,所以导致他不能凭借索引来取值
2.字典的键是唯一的,所以导致他的键不能是一个不可哈希类型(可变的数据类型)
但是字典是一个可变的数据类型
字典的创建方式:
1.dic = {}
2.dic = dict( ( (键值对), ) )
可变的数据类型:字典, 列表
不可变的数据类型:整型, 字符串, 元组
字典的增删改查:
增:
dict.setdefualt(key,value) 注意是用逗号分开,参数是一个键一个值,当字典中已经有相应的键时,键和值不发生改动,返回值为,原来键所对应的值:若不存在这个键,那么就会在字典中新建一个键值对,返回值是现在的这个值
dict [ 'key'] = value 利用新建键值对的方式,来增加字典中的键值对
删:
del dict[key] 暴力删除
dict.pop() 这个方法的参数是字典中的键
dict.clear() 将整个字典清空
dict.pop.item() 随机删除字典中的键值对,有返回值,返回值为一个含有被删除的键值对的元组
改:
dict[key] = new_value 采用取出重新赋值的方法
dict.updadte(dict1) 将dict1 增加在 dict中,若两个字典中有重复的键,那么改变之后的字典是以dict1为主(可以理解为更新)
查:
dict.keys() 取出所有的键
dict,values() 取出所有的值
dict.items() 取出所有的键值对,每个键值对以元组的方式存在一个dict_items的类型中
对字典的一种排序方式
sorted( dict ) 默认对字典中所有的键进行排序,并且以列表的形式返回
sorted(dict.keys() or dict.value() or dict.items()) 这样就实现了,对字典中的键,值,还有键值对,都可以进行一个很好的排序了
对一个字典的格式化,就是将所有键所对应的值改成一样的
befor_dict = {'xing': 'kang', 'name': 'junhao'}
b = a.fromkeys(befor_dict.keys(), 'kang ')
print(b)
字典的遍历
1. for i in iterated: itetated 是一个 可迭代对象
2. for i in dict.items()
推荐使用第一种方法
文件操作
如果要对一个文件进行某些操作:
使用for i in file:的方法,for循环的内部机制将 file(文件句柄)转换成了一个迭代器,
创建文件句柄:
1、file = open(' file ' , ' r ')
2、with open(' file ' , ' r ' ) as file
file.close() 的作用:
1、将你写入的内容,从缓存区载入到你的磁盘中
2、关闭文件
对文件进行操作的基本模式:
r . 对文件进行只读模式 ,光标默认在最前面,因为在只读的时候,是从头开始读
w . 对文件进行只写模式
a . 可以对文件进行追加模式的写入 解决了写入格式化之前内容的问题,追加式的写入
u .
b . 以二进制的形式写入内容
a+. 追加读, 在写入内容的时候,光标默认是在最后面的
r+ . 读写,支持读操作,支持追加写操作,相比w+是的优点是不格式化之前的内容,直接在内容的最后面进行追加写操作
w+ . 写读,和w模式一样,在进行操作之前,会先将文件中的内容格式化,然后进行写操作
内存的存储机制只支持,从最后进行对文件的追加文件内容的操作方法,不能修改原文件的内容
文件句柄就是一个对象,可以调用方法的都是对象
文件句柄的一些方法:
file.read() 将文件中的所有内容打印在屏幕上,耗费内存
file.readline() 一次读取出文件中的一行的内容,读取的时候以换行符为标志输出
file.readlines() 一次性以行的形式取出文件中所有的内容,把取出来的内容都放在了内存,将每行的内容,放在一个列表中
file.write() 参数就是你想要写入文件的内容(字符串),但是每次输入的时候,都会先格式化文件中之前的内容
file.fileno() 文件描述符是一个非零整型,每个句柄都有唯一的文件描述符
file.tell() 返回当前的光标所在的位置
file.seek() 参数为光标的位置,可以实现将光标放在指定的位置,(最实际的应用: 断点续传)
file.flush() 在对文件进行读的操作的时候,我们的内容是放在缓存区中的,并不是磁盘中,所以我们用file.flush()进行实时的将缓存区中的内容存储到磁盘中
file.isatty() 主要的功能是查看你所拿到的文件句柄是不是一个终端设备(终端设备:电报机,)
难点:
1、 对文件进行操作,只有write权限时,在你写入新的内容的时候,会格式化之前文件中的内容,但是格式化这一步操作是在你将操作模式改为只写模式的时候,就已经格式化了并不是在,你写入内容的时候,这就是可以在一个句柄操作下只读模式的时候,可以写入多条内容
2、当你拿到一个文件句柄,结束你的操作时候,记得关闭你的文件,虽然Python的机制是可以帮你加上file.close()的,但是,这个机制具有一定的不定性,换句话说就是不怎么安全和保险,有的时候他不一定会给你加上file.close(),还是养成一个良好的习惯,记得自己手动加上比较好
3、如果有这样的一个情景下:两个py文件需要同时对同一个txt文件进行操作,实践证明这两个py文件可以同时拿到txt文件的文件句柄,并且还可以进行同时读和写的操作,只需要记住结论就可以,不用深究实践的过程
对象:
能调用方法的一定是对象
面向对象:
面向对象的三个基本特征: 继承 , 多态, 封装
迭代器:
用的时候就取一个,迭代器的好处就是用一个取一个,当你的取出下一个数据的时候,上一个数据已经被del 了,在内存中里永远只有一个数据,不会出现占用的内存的问题,
异常处理:
定义:当你在执行代码时不希望某一块的代码出错,而导致整个程序执行不下去的话,就可以使用异常处理,异常处理,可以捕获错误,并且不会影响其他的代码的执行
注意:利用Exception来捕捉错误也可以返回相对具体的错误说明
如果,在一个异常处理中,有具体的需要捕捉的错误类型,和Exception,那么就需要把指定的错误类型放在前面,否则没有意义,也会报错
异常处理的简单格式和示例:
try : # 放入需要执行的代码块 int('hello world') int('4') except ValueError as e: # 如果出现valueerror错误,就能捕获到,只能捕获对应类型的错误 print('value error') except Exception as e: # exception可以捕获所有的错误类型 print('error') else: # 只有try下的代码块顺利执行完,并且没有错误的时候,才执行else下的代码 print('run success') finally: # 无论是有错还有没错finally下的代码都执行 print('jobs is a good man')
1.主动触发异常:
应用场景:当你需要将异常信息写入日志文件的时候,就使用主动触发异常,可以减少代码量
2.自定义异常:
自定义的异常,继承Exception类,可以自己定义一个异常类型,捕获异常时需要主动触发异常
示例:
class myselferror(Exception): # 自定义异常 def __init__(self, info): self.info = info def __str__(self): # 用于输出捕获异常后的信息 return self.info try: raise myselferror('you are really error!!') # 主动触发异常 except myselferror as e: print(e) # 输出异常的信息
3.断言:
格式:assert 条件
如果在你的程序中只要是有不满足条件的值,就报错
示例:
for i in range(102): assert i == 100 print(i) 报错: assert i == 100 AssertionError
线程和进程
线程:
线程就是可以调度操作系统进行工作的最小的单位,换句话说也就是,线程就是一堆的指令集
进程:
其实一个.py文件就是一个进程,进程包含的多个线程,事实上这些线程之间可以实现通信
线程和进程之间的区别:
1、主进程中的子进程不但相互独立,而且大小一致,就是相当于深copy的主进程
2、线程之间可以传递信息,共享信息,但是进程之间不能实现通信
3、主线程可以影响子线程,但是主进程不能影响子进程
GIL(全球解释器锁)
是计算机程序设计语言实现同步线程的工具,使得无论任何的时候只能允许有一个线程在执行
I/O密集型任务或函数:
指的是在函数中存在I/O阻塞
计算密集型任务或函数:
指的就是在函数中没有存在I/O阻塞,没有任何阻挡的执行程序
同步锁(threading模块)
利用同步锁可以实现自定义控制cpu不切换的情况下执行某段代码
obj = threading.Lock() 创建一个同步锁对象
obj.acquire() 上锁
obj.release() 开锁
注意:锁以外的代码还是通过cpu的快速切换来执行的,锁内的代码就是串行执行的
实例代码
import threading import time num = 100 # 定义一个全局的变量 lock_obj = threading.Lock() # 创建一个锁对象 def sub(): global num # 为了可以看清同步锁的作用,可以将num-1的动作分为两步 lock_obj.acquire() # 上锁 middle = num middle -= 1 time.sleep(0.0001) # 阻塞一下也是看为了清楚锁的作用 num = middle lock_obj.release() # 开锁 # 现在创建100的线程,同时的来减去全局变量 obj_list = [] # 存放100个线程对象,用于查看最后的num为多少 for times in range(100): # 控制循环次数 obj = threading.Thread(target=sub) obj.start() # 开始执行子线程 obj_list.append(obj) for i in obj_list: i.join() # 阻塞看结果 # print(num) # 经过尝试,这样不加锁的情况下,结果是不唯一的,原因就是在进行函数中代码的时候,cpu进行了切换,导致多个线程重复赋值 print(num) # 这样有锁的情况下,num最后的值就是唯一的了,也就是锁内的代码执行完后,cpu才能切换到另外一个线程执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号