
T网站景点评论爬虫分享
由于学校作业需要对景点评论做一个汇总和分析,这里以T程网站为例,进行爬虫分析,爬取景点评论。开干!
景点评论页面
首先找到我们要爬取的评论页面:
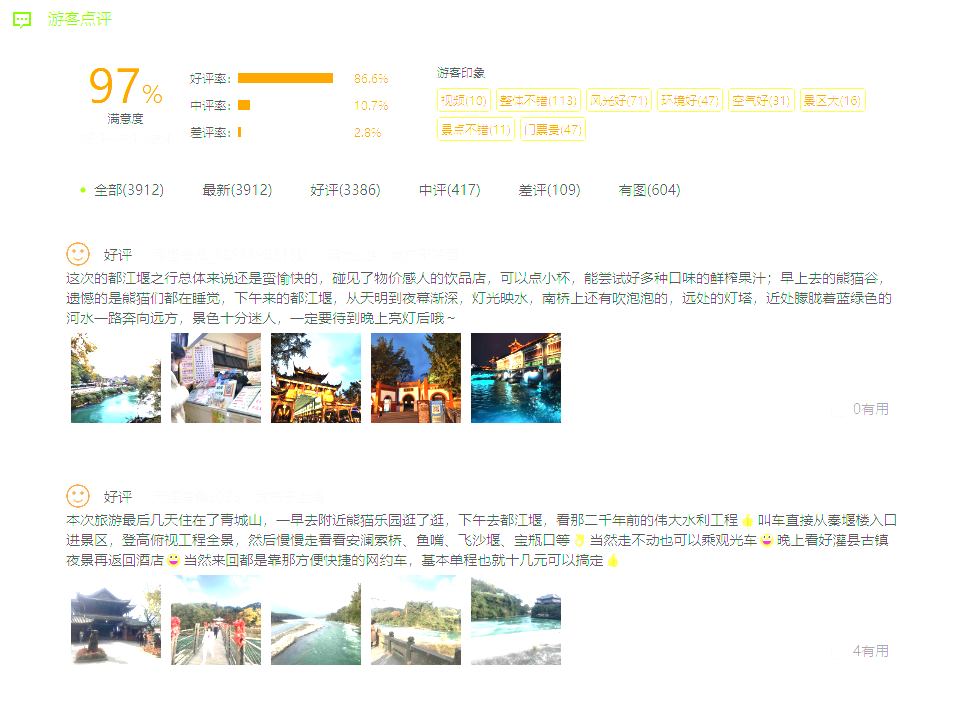
F12打开开发者工具,点击Network,Fetch/XHR:
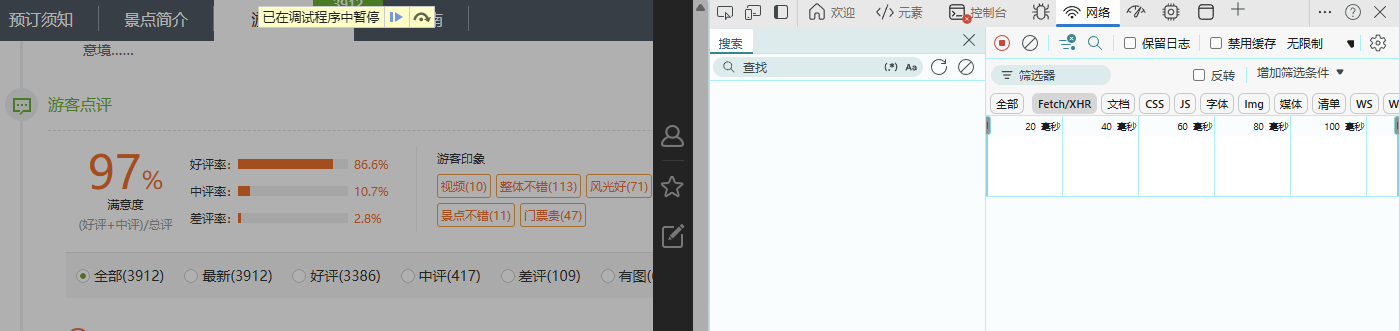
这里遇到个问题,页面被添加了无限断点,Fetch/XHR中没有任何数据,推荐用以下方法规避
打开F12的console,输入以下代码:
(function(){}).constructor === Function
回车
Function.prototype.constructor = function(){}
继续回车
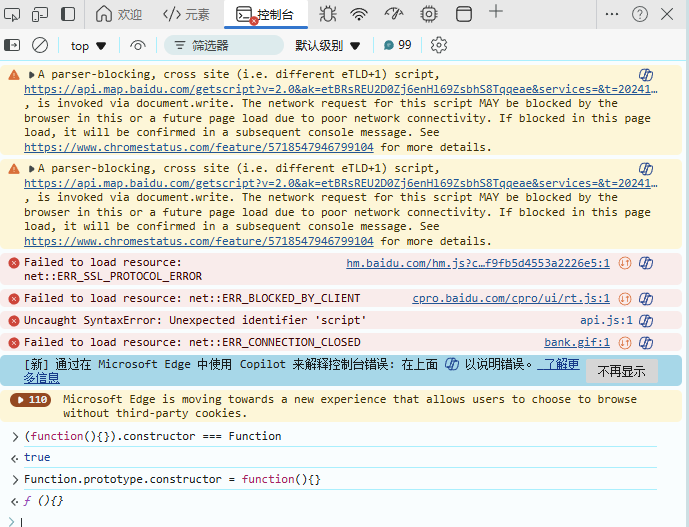
得到以上回复,再按F8,断点就消失了。
点击页码2,在Fetch/XHR中可看到以下get请求。
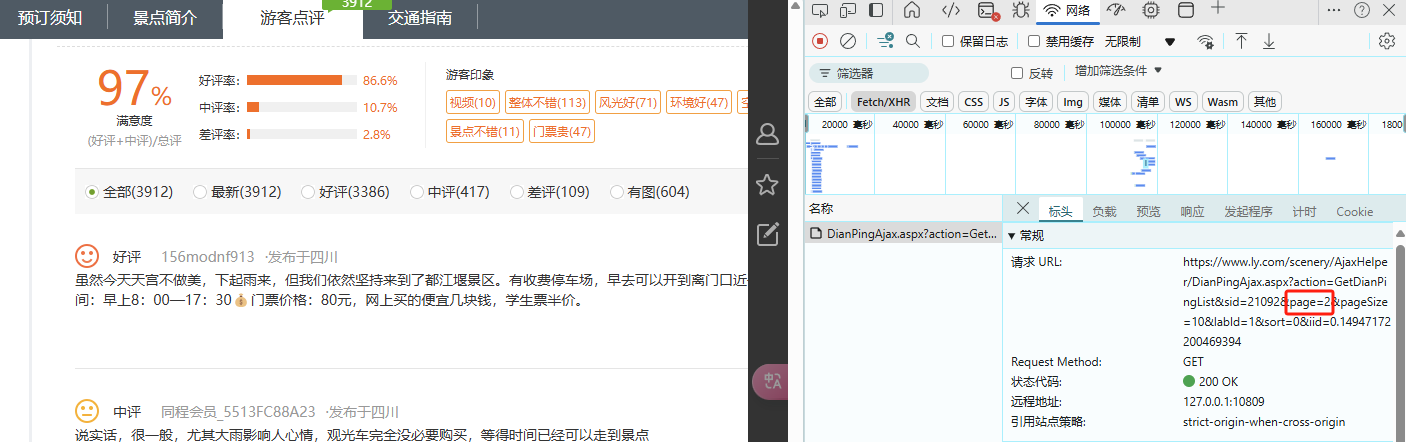
响应数据正是我们需要的评论数据,接下来就是分析请求参数了。

请求参数分析
python爬虫其实就是模拟网页发起HTTP请求,获取响应数据。只要我们能够构造出正确的请求参数,就可以获取到我们想要的数据。下面我们使用curl命令转代码的在线工具,分析请求参数。
先获取该get请求的curl命令:
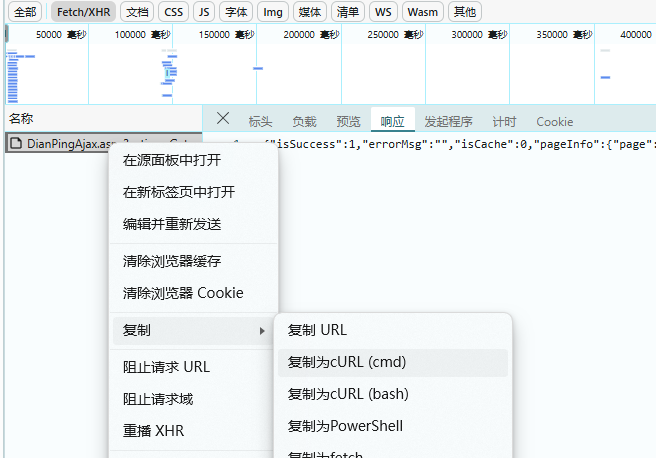
粘贴到转换工具中,可以生成得到python代码:
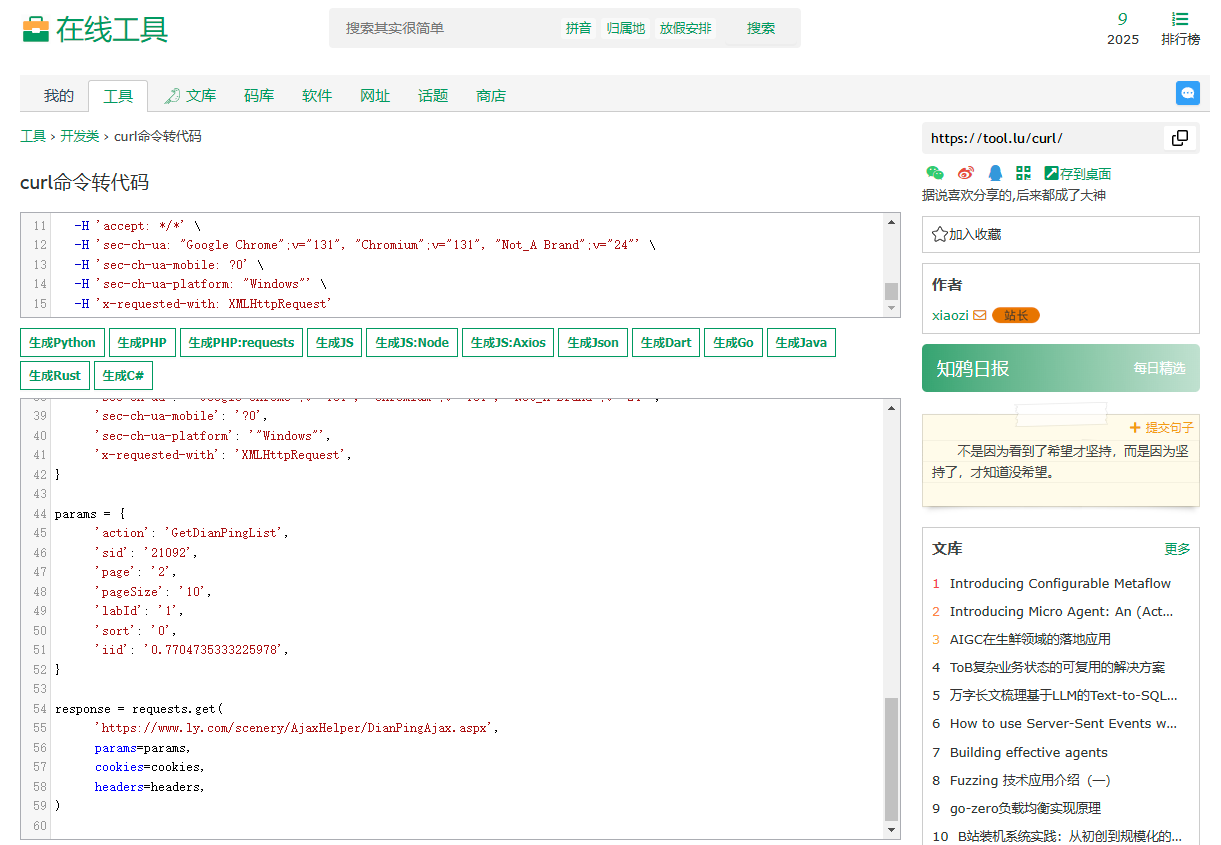
也就是说,我们用request库,运行以上python代码就可以请求得到评论数据。
而实际上,以上有些参数不是必须的,经过尝试使用以下参数就可以获取数据了。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
}
params = {
'action': 'GetDianPingList',
'sid': '21092',
'page': '2',
'pageSize': '10',
}
response = requests.get(
'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx',
params=params,
headers=headers,
)
print(response.text)
最后,就可以从获取到的回复中去解析自己想要的数据了。如果爬取的速度太慢,还可以使用线程池的方式,提高爬取速度。但是要注意,爬取速度过快,可能会被封IP,所以爬取速度要控制好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号