
SeaTunnel(2.3.12)的高级用法(一):SeaTunnel的核心能力总结
seatunnel:抽取数据的引擎
- SeaTunnel Zeta(本地引擎)
- Spark(集群)
- Flink(集群)
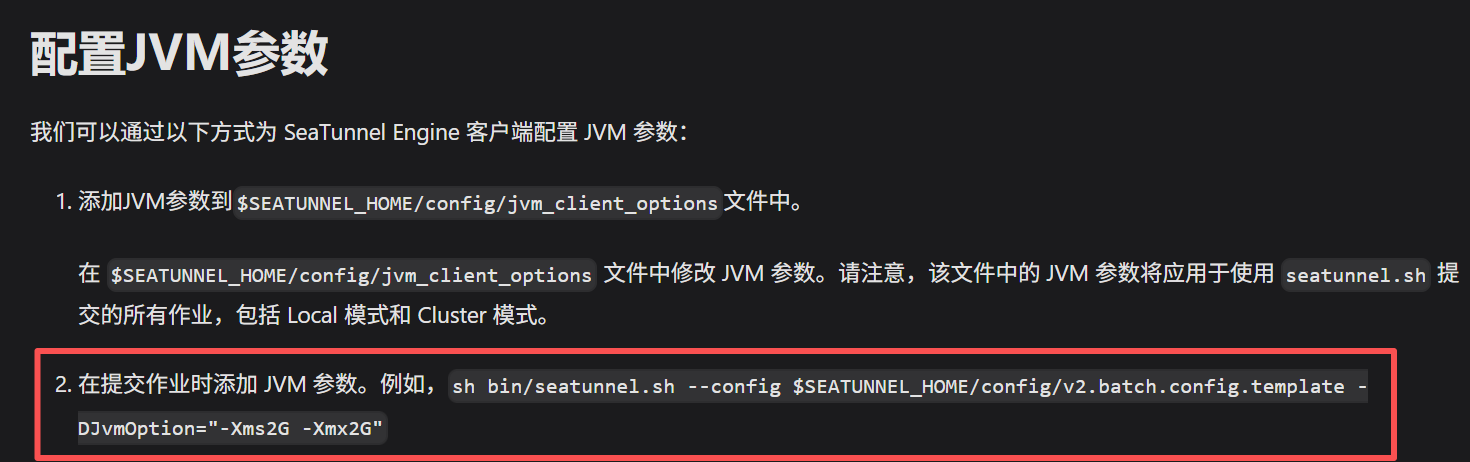
seatunnel:执行命令
| 参数 | 解释 | 备注 |
|---|---|---|
| JAVA_OPTS='-Xmx2g -Xms2g' | 设置本次运行的内存大小 | AI给我设的,好像也生效了 |
| -DJvmOption="-Xms5G -Xmx5G" | 设置本次运行的内存大小 | 官方文档推荐 |
| -m local | 本地模式运行 |
- SeaTunnel Zeta(本地引擎)
sh /……/seatunnel-2.3.12/bin/seatunnel.sh --config /……/my.conf -i JAVA_OPTS='-Xmx2g -Xms2g' -m local
sh /……/seatunnel-2.3.12/bin/seatunnel.sh --config /……/my.conf -i -DJvmOption="-Xms5G -Xmx5G" -m local
-
Spark引擎
-
Flink引擎
source:大表分片(分片采集)
-
seatunnel:天生支持分片,和以前版本的做法不一样了
-
partition_num:官方将要弃用
-
现在分片的配置:只需要两个参数:partition_column、split.size
-
partition_num 通常指期望将数据划分成的分片数量,而 split.size 可能指每个分片预期处理的数据量(如行数)。工具在实际运行时,会根据表的总数据量和 split.size 来动态计算实际的分片数。
-
版本分界与配置对比
特性维度 v1.x 及 v2.0.0 早期 v2.0.0 及之后的新版本 分片方式 手动策略:需在 query配置中明确写出WHERE条件,并配套使用split参数自动分片:通过 partition_column和split.size等参数声明,引擎自动计算配置示例 需写 "query": "SELECT * FROM table WHERE id BETWEEN ? AND ?", 并配"split": {"id": {"range": [1, 100, 200]}}只需配 "partition_column": "id"和"split.size": 10核心思想 用户驱动:用户需了解数据分布并计算分片点 引擎驱动:用户声明意图,引擎负责优化执行 文档参考 旧版 Wiki 或 v1.x 文档 你提供的当前最新官方文档
# 并行读取配置
# 分片的字段:支持:String、Number(int, bigint, decimal, ...)、Date
partition_column = "id"
# 表的分割大小(行数):每个分片的数据行(默认8096行)。最后分片数=表的总行数 / split.size
split.size = 10000
# 分片数,匹配并行度parallelism(2.3.12已不推荐配置了,用split.size来代替)
# partition_num = 5
sink:schema_save_mode、data_save_mode
| 参数 | 类型 | 是否必须 | 默认值 | 解释 |
|---|---|---|---|---|
| schema_save_mode | Enum | 否 | CREATE_SCHEMA_WHEN_NOT_EXIST | 在同步任务开启之前,根据目标端现有表结构选择不同处理方案。 |
| data_save_mode | Enum | 否 | APPEND_DATA | 在同步任务开启之前,根据目标端现有数据选择不同处理方案。 |
- schema_save_mode [枚举]
在同步任务开启之前,根据目标端现有表结构选择不同处理方案。
选项介绍:
RECREATE_SCHEMA :当表不存在时将创建,保存时删除并重建。
CREATE_SCHEMA_WHEN_NOT_EXIST :当表不存在时创建,保存时跳过。
ERROR_WHEN_SCHEMA_NOT_EXIST :当表不存在时报告错误。
IGNORE :忽略对表的处理。
- data_save_mode [枚举]
在同步任务开启之前,根据目标端现有数据选择不同处理方案。
选项介绍:
DROP_DATA:保留数据库结构并删除数据。
APPEND_DATA:保留数据库结构,保留数据。
CUSTOM_PROCESSING:用户定义处理。必须配置:custom_sql参数
ERROR_WHEN_DATA_EXISTS:当存在数据时报告错误。
sink:前置sql执行
- data_save_mode = "CUSTOM_PROCESSING"
- custom_sql
- 当 data_save_mode 选择 CUSTOM_PROCESSING 时,您应该填写 CUSTOM_SQL 参数。此参数通常填入可执行的 SQL。SQL 将在同步任务之前执行。
SQL 将在同步任务之前执行。
- 可以实现:同步删除(执行前置update、truncate的sql等)
- 注意:这个sql要执行。
- 必须设置:generate_sink_sql=true。才会执行custom_sql。(只有自动生成sql的时候,这个才会执行)
- 不能使用:query的sql
sink:开启postgresql的upsert
- seatunnel自动生成:INSERT INTO …… ON CONFLICT ("主键") DO UPDATE SET …… 的sql
- 插入数据的时候:
- 如果主键不重复就插入;
- 如果主键重复,数据有变化就更新,没变化就不管;
- 插入数据的时候:
# 生成类似:INSERT INTO …… ON CONFLICT ("主键") DO UPDATE SET …… 的sql
enable_upsert = true
# 判断值唯一的健:此选项用于支持在自动生成 SQL 时进行 insert,delete 和 update 操作。
primary_keys = ["id"]
sink:query(目标的query的sql不仅可以写insert,还可以写update或者其他sql)
- 可以实现:只更新,不新增数据
query = """UPDATE "public"."t_8_100w_imp_st_ds_demo6_zl_jgx_sjcjzzzd"
SET "user_name"=?, "sex"=?, "decimal_f"=?, "phone_number"=?, "age"=?, "create_time"=?, "description"=?, "address"=?
WHERE "id"=?;"""
seatunnel:数据流的概念
- 数据流的概念:seatunnel中有数据流的概念,通过:plugin_output、plugin_input 实现数据流向
- 数据流的名字都是自己取的,唯一就行
# demo4-1-mysql2mysql-qxzh-st-107.conf
env {
……
}
source {
jdbc {
……
plugin_output = "source_data"
……
}
}
# 清洗转换
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
FieldRename {
plugin_input = "source_data"
plugin_output = "FieldRename_data"
……
}
# 2. 手机号脱敏:13812341234 -> 138****1234
Replace {
plugin_input = "FieldRename_data"
plugin_output = "Replace_phone_number_data"
……
}
# 4. 性别转换:1->男,2->女
# sql的方式替换(演示成功),这种方式,还不如写到source.query的sql中
Sql {
plugin_input = "Replace_phone_number_data"
plugin_output = "Sql_sex_data"
……
}
# 6. 地址默认值:空地址设为'未知'
Sql {
plugin_input = "Sql_sex_data"
plugin_output = "Sql_address_data"
}
}
sink {
jdbc {
……
# 接收的最终数据集
plugin_input = "Sql_address_data"
……
}
}
transform:清洗转换
-
transform中会用到:数据流 (transform如果只有一个组件,可以不用数据流,有两个及以上必须用数据流的概念)
-
清洗转换方式:
- 清洗转换方式1:使用seatunnel的transform插件(不推荐,能力有限,大多数用Sql插件实现)
- 清洗转换方式2:直接在源头的query的sql中搞定(seatunnel的设计倾向)
-
清洗转换规则:
字段映射:name → user_name(不用特殊处理:sql中使用as,出来的字段是目标库的字段名就行)
数据清洗:手机号脱敏 138****1234
类型转换:年龄字段:字符串转数字(本身是字符串的数字:可以直接保存,不用特殊操作。如果转换错误会报错)
值转换:性别字段:1=>男;2=>女
数据过滤:只保留 age>25 的记录
默认值设置:地址:空地址设为'未知'
- 清洗转换方式1:conf中的transform插件
env {
……
}
source {
jdbc {
……
}
}
# 清洗转换
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
FieldRename {
plugin_input = "source_data"
plugin_output = "FieldRename_data"
specific = [
{
field_name = "name"
target_name = "user_name"
}
]
}
# 还可以用:FieldMapper插件,来映射字段
# 2. 手机号脱敏:13812341234 -> 138****1234
Replace {
plugin_input = "FieldRename_data"
plugin_output = "Replace_phone_number_data"
replace_field = "phone_number"
# 正则匹配:第4位到第7位(共11位手机号)
pattern = "(\\d{3})\\d{4}(\\d{4})"
replacement = "$1****$2"
is_regex = true
replace_first = true
}
# 还可以用Sql插件来做脱敏,用这个方式做,还不如直接写到source中query的sql中直接转换
#Sql {
# query = "select id,user_name,sex,decimal_f,CONCAT(LEFT(phone_number, 3), '****', RIGHT(phone_number, 4)) AS phone_number,age,create_time,description,address FROM dual"
#}
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# sql的方式替换(演示成功),这种方式,还不如写到source.query的sql中
Sql {
plugin_input = "Replace_phone_number_data"
plugin_output = "Sql_sex_data"
# 注意:1、使用sql插件,字段必须和source中的字段一致;2、表名可以固定:dual
query = "SELECT id,user_name,CASE sex WHEN 1 THEN '男' WHEN 2 THEN '女' ELSE '未知' END AS sex,decimal_f,phone_number,age,create_time,description,address FROM dual"
}
# Replace的连续替换方案会报错:因为源头sex是int类型,目标sex是varchar类型,Replace1的时候,用的是源头表的sex的int类型,会报错:转换错误,所以转换只能用Sql或者自己写插件
# 第一个Replace:将"1"替换为"男"
#Replace {
# plugin_input = "Replace_phone_number_data"
# plugin_output = "Replace_sex_1_data"
# replace_field = "sex"
# pattern = 1
# replacement = "男"
# is_regex = false
# # 当 is_regex=false 时,不需要 replace_first 参数
#}
# 第二个Replace:将"2"替换为"女"
#Replace {
# plugin_input = "Replace_sex_1_data"
# plugin_output = "Replace_sex_2_data"
# replace_field = "sex"
# pattern = 2
# replacement = "女"
# is_regex = false
# # 当 is_regex=false 时,不需要 replace_first 参数
#}
# 5. 数据过滤:只保留 age > 25 的记录。
# 注意:不能用:Filter,Filter是过滤字段是否要不要的,不是过滤值的。只有使用Sql插件
# (只能用这种方式)注意:实际生成中,数据过滤不在这里做,在source.Jdbc.query的sql中的where过滤做(效率高)
# 注意:age在源头表中的类型是varchar,目标库age的类型是int。这里转换类型会报错
# Sql插件使用的是SeaTunnel内置的SQL解析与执行引擎,它并非完整的数据库,因此在SQL语法支持(特别是类型转换函数)上远不如真实的MySQL。
#Sql {
# plugin_input = "Sql_sex_data"
# plugin_output = "Sql_age_data"
# # 注意:1、使用sql插件,字段必须和source中的字段一致;2、表名可以固定:dual
# query = "SELECT id,user_name,sex,decimal_f,phone_number,CAST(age AS SIGNED) as age,create_time,description,address FROM dual where age > 25"
#}
# 6. 地址默认值:空地址设为'未知'
Sql {
plugin_input = "Sql_sex_data"
plugin_output = "Sql_address_data"
query = "SELECT id,user_name,sex,decimal_f,phone_number,age,create_time,description,case when address is null then '未知' else address end as address FROM dual"
}
# 注意:Replace的正则无法匹配null,会直接跳过,所以不能用Replace
# 第一步:将 NULL 值替换为特殊标记字符串
#Replace {
# plugin_input = "Sql_sex_data"
# plugin_output = "Replace_address_1_data"
# replace_field = "address"
# pattern = "Null"
# replacement = "未知"
# is_regex = false
#}
}
sink {
jdbc {
……
}
}
- 清洗转换方式2:直接在source的query的sql中实现数据过滤和转换
# demo4-3-mysql2mysql-qxzh-st-107.conf
env {
# 并行度(线程数)
execution.parallelism = 5
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
jdbc {
……
# 使用sql来做清洗转换
query = "select id,name as user_name,CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '未知' END AS sex,decimal_f,CONCAT(LEFT(phone_number, 3), '****', RIGHT(phone_number, 4)) AS phone_number,CAST(age AS SIGNED) as age,create_time,description,case when address is null then '未知' else address end as address from t_8_100w where age > 25"
……
}
}
# 清洗转换(简单的清洗转换,直接在source的query的sql中处理了就行)
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
# 还可以用:FieldMapper插件,来映射字段
# 2. 手机号脱敏:13812341234 -> 138****1234
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# 5. 数据过滤:只保留 age > 25 的记录。
# 6. 地址默认值:空地址设为'未知'
}
sink {
jdbc {
……
}
}
sink:自动建表、控制自动建表的字段
自动建表
触发条件:
- 目标表未建表
- schema_save_mode=CREATE_SCHEMA_WHEN_NOT_EXIST(默认就是,可以不设置)
- 启用自动生成sql:
控制自动建表的字段
-
自动建表的基础上,还可以对建表的字段做映射和修改操作,来控制表的创建
-
有空再做demo
一个任务:多源头、多目标采集
- 有空再做demo
1


 浙公网安备 33010602011771号
浙公网安备 33010602011771号