
SeaTunnel(2.3.12)的高级用法(二):CDC(实时增量采集)MySQL-CDC、Postgresql-CDC
一、实时增量采集-变更数据捕获(CDC)(datax没有的功能)
- mysql-cdc官方文档:https://seatunnel.apache.org/zh-CN/docs/2.3.3/connector-v2/source/MySQL-CDC/
- cdc可以一个seatunnel的cdc任务监控多个表,进行同步
- 必须用mysql8.0.33以上的jdbc驱动
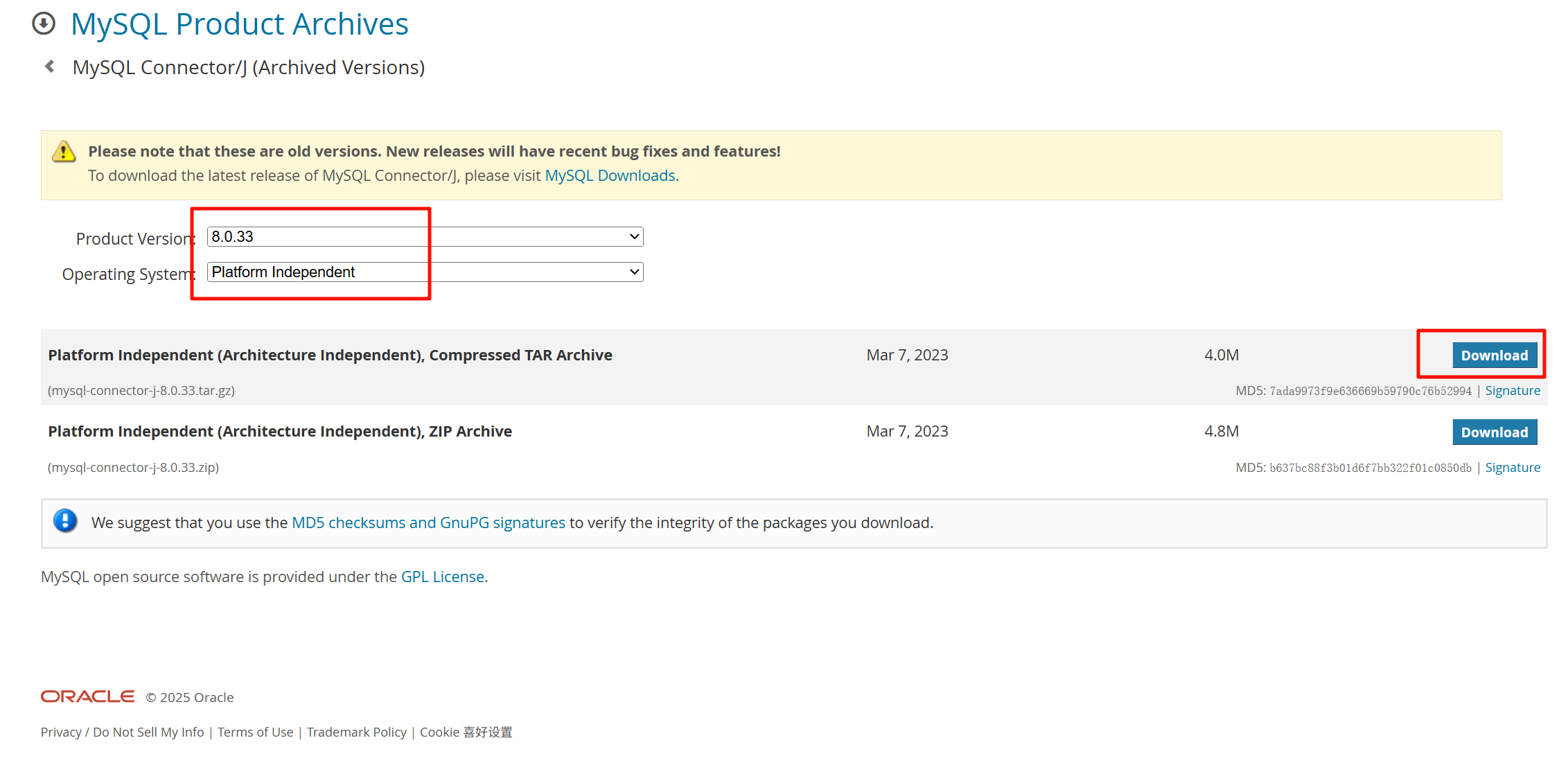
1、seatunnel支持几个数据库的CDC?
官方支持的 CDC 源连接器
1、MongoDB CDC 源连接器
2、MySQL CDC 源连接器
3、Opengauss CDC 源连接器
4、Oracle CDC 源连接器
5、PostgreSQL CDC 源连接器
6、SQL Server CDC 源连接器
7、TiDB CDC 源连接器
2、CDC的seatunnel服务启动后,不会停止
一个标准的CDC(Change Data Capture)任务,其设计目标就是“持续运行,永不停止”的流式服务。
-
核心区别:
- 离线/批处理任务:
job.mode = "BATCH"。执行一次全量或增量的SQL查询,处理完现有数据后,任务自然结束。 - CDC/流处理任务:
job.mode = "STREAMING"。启动后,它会:- 首先进行可选的初始全量快照(如果配置了
scan.startup.mode = "initial")。 - 然后挂起并持续监听MySQL的binlog文件流。
- 一旦源数据库有任何新的数据变更(增、删、改),任务会立即捕获、处理并写入目标端。
- 这个监听过程理论上会无限期进行下去,直到你手动停止任务,或任务因错误而失败。
- 首先进行可选的初始全量快照(如果配置了
- 离线/批处理任务:
-
如何停止任务:在运行SeaTunnel的终端中,通常可以按
Ctrl + C组合键来优雅地停止正在运行的CDC任务。在生产环境中,可能需要通过作业调度或管理平台来发送停止指令。
简单来说,你可以把CDC任务理解为一个 “常驻的订阅服务” ,它订阅了数据库的变更日志,并在有新事件时实时处理。这不同于执行一次就退出的“离线任务”。
- 💡 配置建议与常见问题
- 关于
startup.mode:对于首次启动任务,强烈建议使用initial,这样可以确保先获取一份完整的当前数据快照,之后再无缝衔接增量变更。如果设为latest,则会丢失所有历史数据,只监听启动后的新变更。 - 关于
server-id:生产环境中务必手动设置一个唯一值,避免使用随机值可能导致的冲突,从而引发任务不稳定。
3、cdc模式与jdbc模式
- 区别
| 特性维度 | MySQL-CDC (流式处理) | JDBC批处理 (批处理) |
|---|---|---|
任务模式 (job.mode) |
STREAMING |
BATCH |
| 数据来源 | 数据库的二进制日志 (Binlog) | 自定义的 SQL 查询结果集 |
| 数据内容 | 变更事件流 (包含op操作类型、前后镜像数据、元数据) |
静态数据快照 (查询返回的原始行数据) |
| 配置核心 | table-names (指定要监控的表) |
query 或 table + sql (指定要查询的SQL) |
| 同步类型 | 实时增量 (可先全量快照,再持续增量) | 一次性全量/批量增量 |
| 输出持续性 | 持续运行,直到手动停止 | 自动结束,数据读取完毕后任务停止 |
| 典型场景 | 实时数仓、实时分析、异地容灾 | T+1报表、数据迁移、历史数据补录 |
| 对源库压力 | 增量阶段持续低压力读取Binlog | 每次执行查询时产生一次性压力 |
| 数据完整性 | 可保证不丢不重 (Exactly-once) | 依赖查询条件,可能重复或遗漏 |
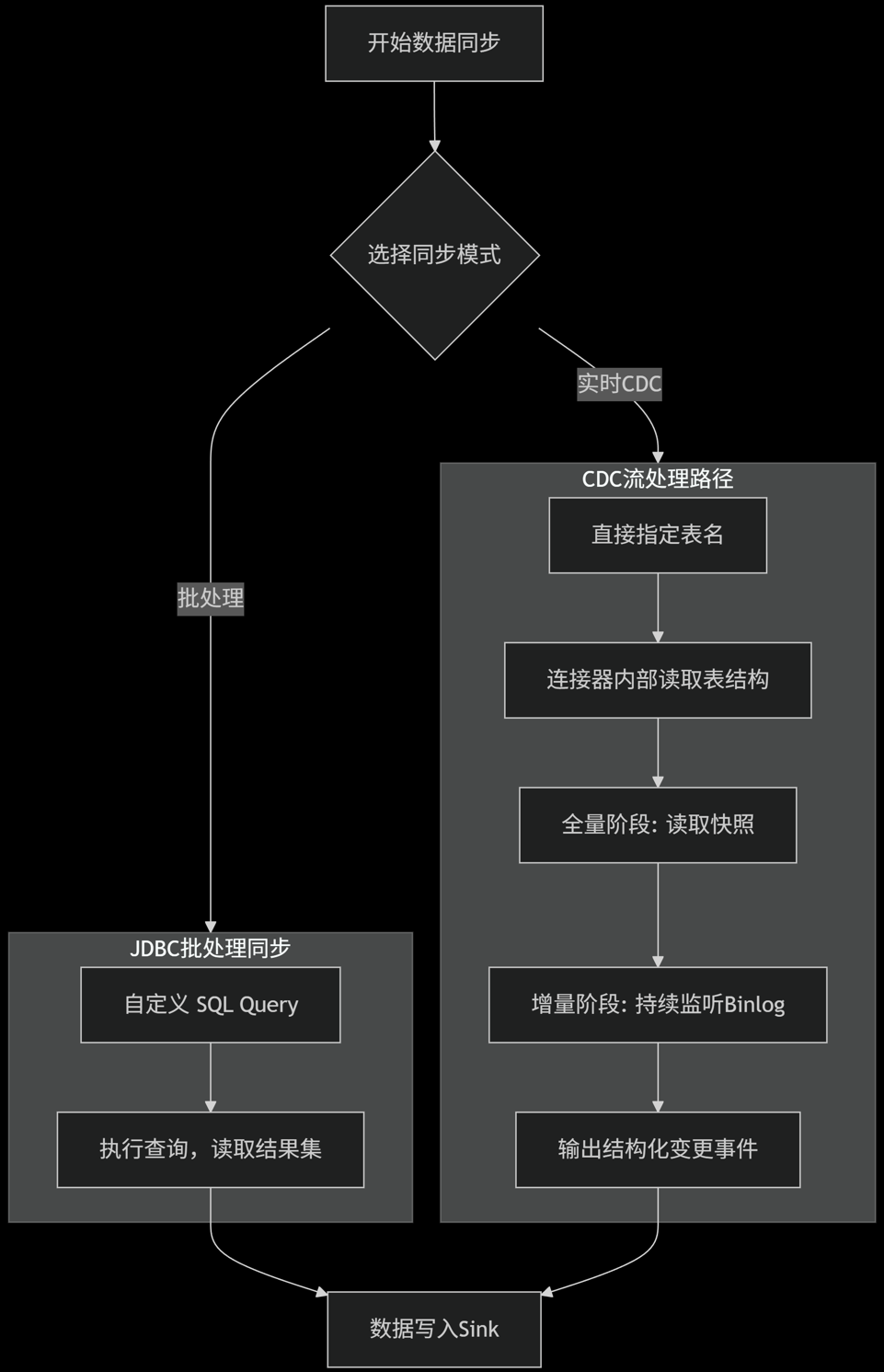
- 区别图
+-------------------+ +------------------------------+
| 开始数据同步 | | CDC流处理路径 |
+-------------------+ +------------------------------+
| |
v v
+-------------------+ +------------------------------+
| 选择同步模式 |-----> | 1. 指定表名 |
| (决策点) | | table-names=["db.tbl"] |
+-------------------+ +------------------------------+
| |
| v
| +------------------------------+
| | 2. 连接器读取表结构 |
| +------------------------------+
| |
| v
| +------------------------------+
| | 3. 全量阶段: 读取快照 |
| +------------------------------+
| |
| v
| +------------------------------+
| | 4. 增量阶段: 持续监听Binlog |
| +------------------------------+
| |
| v
| +------------------------------+
| | 5. 输出结构化变更事件 |
| | (+I/-U/+U/-D 等) |
| +------------------------------+
| |
| |
v v
+-------------------+ +------------------------------+
| 批处理JDBC路径 | | |
+-------------------+ | 数据汇聚 |
| | (写入Sink) |
v | |
+-------------------+ +------------------------------+
| 1. 自定义SQL查询 | ^
| SELECT ... | |
+-------------------+ |
| |
v |
+-------------------+ |
| 2. 执行查询 |--------------------+
| 读取结果集 |
+-------------------+
-
图2
-
cdc下,无法用source的query定制sql过滤
-
如果要做数据清洗转换、过滤,只能再transform中做
在MySQL-CDC模式下,你通常无法像使用普通的JDBC Source那样,在 source 模块里通过一个自定义的 query 参数(例如 SELECT * FROM ... WHERE ...)来指定任意SQL语句。
CDC不支持自定义query的主要原因:
-
数据来源不同
- JDBC批处理:数据来源于你自定义的SQL查询结果集。连接器只是执行并返回这个结果。
- MySQL-CDC:数据来源于数据库的二进制日志(Binlog)。CDC连接器(底层基于Debezium)会将自己伪装成一个MySQL副本,持续接收并解析原始的行级别变更事件流。
-
数据形态不同
- JDBC批处理:你查询出来的是什么数据,同步的就是什么数据。
- MySQL-CDC:它输出的是变更事件,每条记录不仅包含变更后的数据(
after状态),还包含变更类型(op字段,如+I表示插入,-U表示更新前,+U表示更新后,-D表示删除)以及元数据(如源库、表、时间戳等)。自定义的SELECT语句无法生成这种结构化的变更事件。
4、 如何在CDC模式下实现“筛选”或“转换”
虽然无法在数据源头(source)进行筛选,但你有多种方式在后续环节处理数据:
| 方法 | 实施位置 | 说明 |
|---|---|---|
| 1. 使用 Transform 转换 | SeaTunnel 配置文件的 transform 部分 |
这是最常用和推荐的方式。你可以在数据流出Source后、写入Sink前,通过SQL语句进行过滤、字段选择、重命名等操作。 |
| 2. 在 Sink 中处理 | Sink 连接器的配置中 | 部分Sink支持在生成写入语句时进行条件过滤或字段映射,但能力有限,不如Transform灵活。 |
| 3. 启用 Schema 演进 | 表级别同步 | 通过只同步部分列的方式间接实现“列筛选”,但这需要表结构预先变更,且通常用于长期同步场景。 |
5、CDC可以同时监控多张表,进行实时同步
当你需要用一个CDC任务监控多个表时,SeaTunnel的配置非常直观。关键在于源端(Source)的“一对多”配置,以及Sink的“一对一”自动映射。
📝 如何配置“一对多”CDC监控
你只需要在 source 部分的 table-names 列表中指定所有需要监控的表即可。
source {
MySQL-CDC {
base-url = "jdbc:mysql://192.168.1.107:51382/cs1"
username = "root"
password = "zysoft"
database-names = ["cs1"]
# 核心:在列表中添加多个表,格式必须是:数据库名.表名
table-names = [
"cs1.t_8_100w", # 表1
"cs1.order_table", # 表2
"cs1.user_profile" # 表3
# ... 可以继续添加更多表
]
startup.mode = "initial"
server-id = 5400
server-time-zone = "Asia/Shanghai"
}
}
🎯 Sink的配置:自动路由与并行写入
SeaTunnel的JDBC Sink有一个非常强大的特性:自动表路由。你几乎不需要为多表同步做特殊配置。
1. 核心配置(与单表一致,关键在 table 参数):
sink {
jdbc {
url = "jdbc:mysql://192.168.1.107:51382/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
generate_sink_sql = true
database = "cs2" # 目标数据库
# 核心技巧:使用变量动态匹配来源表名
table = "${table_name}"
# table = "prefix_${table_name}" # 也可以加前缀
# table = "${database_name}_${table_name}_suffix" # 或使用库名、后缀
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode = "APPEND_DATA"
batch_size = 5000
# ... 其他连接和调优参数保持不变
}
}
关键说明:
${table_name}和${database_name}是SeaTunnel的内置变量。运行时,它们会自动被替换为上游CDC数据记录中携带的源表名和源数据库名。- 这样,
cs1.t_8_100w的数据会自动写入cs2.t_8_100w,cs1.order_table的数据会自动写入cs2.order_table,实现完美的 1:1 映射。
2. 如果需要对不同表采用不同的写入策略怎么办?
你需要为每个表单独配置一个 sink 模块,并使用 filter 条件进行路由:
sink {
# Sink 1: 专门处理 t_8_100w 表
jdbc {
# 通过目标表名固定,明确写入哪个表
table = "t_8_100w_target"
# 使用 filter 只让来自特定源表的数据流入此sink
source_table_name = "t_8_100w"
# ... 其他配置
}
}
sink {
# Sink 2: 专门处理 order_table 表,可以采用不同的 data_save_mode 等
jdbc {
table = "order_table_target"
source_table_name = "order_table"
data_save_mode = "DROP_DATA" # 例如,对这个表采用清空重灌策略
# ... 其他配置
}
}
💡 重要提醒与最佳实践
- 目标表结构:确保目标数据库
cs2中已经存在与源表结构兼容的表(或启用schema_save_mode = “CREATE_SCHEMA_WHEN_NOT_EXIST”让SeaTunnel自动创建)。 - 性能与隔离:监控多表时,所有表的变更会共用同一个数据流。如果某个表变更异常频繁,可能会轻微影响其他表的同步延迟。对于重要性或流量差异极大的表,建议拆分到独立的CDC任务中,以获得更好的隔离性和可维护性。
- 初始快照:当
startup.mode = “initial”时,任务启动时会依次对所有监控表进行全量快照读取。请确保数据库有足够资源应对同时进行的多个全表扫描。
总结:对于大多数“多表同步到对应结构目标表”的场景,你只需要在 source 中列出多个表,然后在 sink 中配置 table = “${table_name}” 即可,SeaTunnel会自动完成路由和写入。
如果你需要对特定表进行特殊的数据转换,可以在 transform 部分使用SQL,并同样通过 filter 或条件判断来区分不同表的数据流。
路由filter
- 路由与过滤:如果你希望数据有选择地流入不同的
sink,而不是全部复制到每一个sink,则需要在每个sink前配置filter或使用侧流输出等更高级的API(在配置文件中通常通过条件表达式实现)。
💡 针对你“多表CDC”场景的配置建议
结合你之前的问题,一个典型的多表CDC同步到不同目标表的配置如下:
source {
MySQL-CDC {
table-names = ["cs1.t_order", "cs1.t_user", "cs1.t_log"]
# ... 其他配置
}
}
sink {
# 订单表 -> 订单归档库
jdbc {
table = "t_order_archive"
# 使用filter,只同步t_order表的数据
filter {
source_table_name == "t_order"
}
# ...
}
# 用户表 -> 用户分析库
jdbc {
table = "t_user_analysis"
filter {
source_table_name == "t_user"
}
data_save_mode = "OVERWRITE" # 对这个表采用覆盖策略
# ...
}
# 日志表 -> 日志中心(这里示例写入HDFS)
hdfs {
path = "/data/lake/log/${source_table_name}/dt=${now(date='yyyy-MM-dd')}"
filter {
source_table_name == "t_log"
}
# ...
}
}
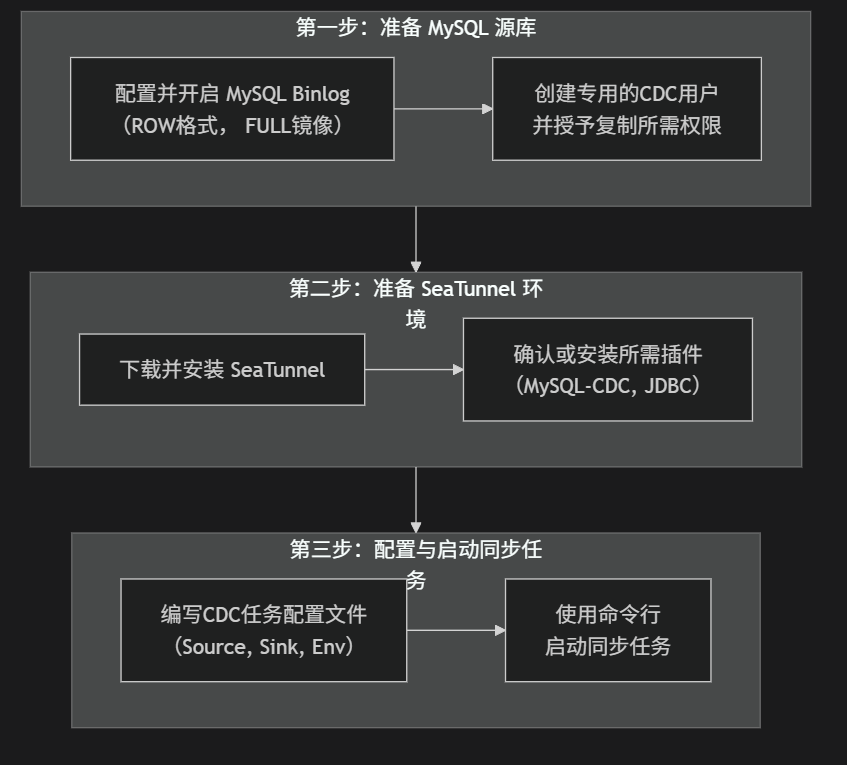
二、实现Mysql-CDC的步奏
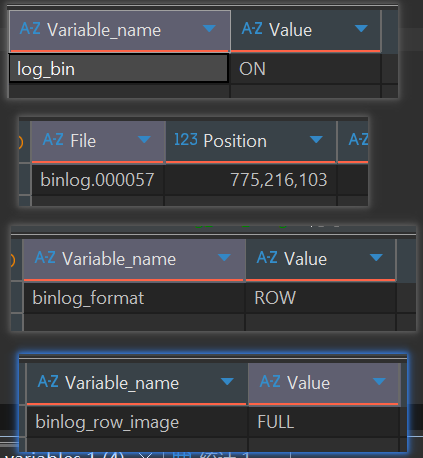
1、查看MySQL Binlog是否开启、开启
-- 最直接的查看方式
SHOW VARIABLES LIKE 'log_bin';
-- 更详细的查看,会显示binlog的文件名和路径
SHOW MASTER STATUS;
-- 查看binlog的格式,确认是否为ROW
SHOW VARIABLES LIKE 'binlog_format';
-- 查看binlog镜像模式,确认是否为FULL
SHOW VARIABLES LIKE 'binlog_row_image';
- 如果没开启binlog,需要修改mysql配置文件,然后重启
[mysqld]
server-id = 123 # 设置一个唯一的服务器ID[citation:2]
log_bin = /var/lib/mysql/mysql-bin # 开启binlog并指定路径
binlog_format = ROW # 必须设置为ROW模式[citation:2][citation:3][citation:5]
binlog_row_image = FULL # 必须设置为FULL[citation:2][citation:4]
expire_logs_days = 10 # 日志保留天数,建议至少2天[citation:2]
2、Mysql-CDC常用参数
| 参数组 | 参数名 | 类型 | 必须 | 默认值 | 说明与注意事项 |
|---|---|---|---|---|---|
| 基础连接 | base-url |
String | 是 | - | JDBC连接字符串,格式如 jdbc:mysql://主机:端口/数据库名。这是建立连接的基础。 |
username / password |
String | 是 | - | 数据库用户名和密码。确保用户有复制(REPLICATION)权限。 | |
| 监控范围 | database-names |
List | 否 | - | 要监控的数据库名列表。若不指定,则需在table-names中完整指定。 |
table-names |
List | 是 | - | 要监控的表名列表。格式必须为 数据库名.表名,例如 inventory.products。 |
|
| 启动与停止 | startup.mode |
Enum | 否 | initial |
启动模式,决定从何处开始读取: • initial:先做全量快照,再持续读增量(常用)。• earliest:从最早可用的binlog位置开始。• latest:仅从最新位置开始读增量。• specific:从指定binlog文件位置开始。 |
startup.specific-offset.file |
String | 否 | - | 当 startup.mode='specific' 时必须,指定起始的binlog文件名。 |
|
startup.specific-offset.pos |
Long | 否 | - | 当 startup.mode='specific' 时必须,指定起始的binlog位置。 |
|
stop.mode |
Enum | 否 | never |
停止模式,目前文档显示主要选项是 never(即持续运行)。 |
|
| 性能与调优 | server-id |
String | 否 | 随机 | 非常重要!指定CDC客户端的唯一ID(如5400)或范围(如5400-5408),不能与MySQL集群中任何现有服务器ID冲突。 |
server-time-zone |
String | 否 | UTC | 数据库服务器的会话时区,建议设置为 Asia/Shanghai 以正确解析时间戳。 |
|
snapshot.split.size |
Integer | 否 | 8096 | 表快照读取时每个分块的行数,影响全量阶段读取并行度和内存使用。 | |
incremental.parallelism |
Integer | 否 | 1 | 增量读取阶段的并行度,对于高流量表可适当调大以提升消费速度。 | |
| 高级特性 | exactly_once |
Boolean | 否 | true | 是否启用精确一次语义,通常保持默认以确保数据不丢不重。 |
debezium.* |
Config | 否 | - | 透传Debezium底层引擎的属性,用于实现更精细的控制(如跳过快照、处理特殊数据类型)。 |
实现Postgresql-CDC的步奏
- todo
三、2.9.2、演示Mysql-CDC(单表)
- 建表
-- demo7-1-mysql-cdc2mysql-qxzh-st-107.conf
CREATE TABLE cs2.`t_8_100w_imp_st_qxzh_cdc_demo7_1` (
`id` bigint NOT NULL COMMENT '主键',
`user_name` varchar(2000) NULL COMMENT '名字',
`sex` varchar(20) null COMMENT '性别:男;女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) COMMENT '电话',
`age` int NULL COMMENT '字符串年龄转数字',
`create_time` timestamp COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
- 执行语句
# demo7-1-mysql-cdc2mysql-qxzh-st-107.conf
sh /data/tools/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /data/tools/seatunnel/myconf/demo7-1-mysql-cdc2mysql-qxzh-st-107.conf -m local
- conf
# demo7-1-mysql-cdc2mysql-qxzh-st-107.conf
env {
# 并行度(线程数)
execution.parallelism = 5
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式(CDC的关键)
job.mode = "STREAMING"
}
source {
MySQL-CDC {
base-url = "jdbc:mysql://ip:port/cs1"
username = "root"
password = "zysoft"
# query在cdc中无效
# 数据库
database-names = ["cs1"]
# 监控的表,必须带数据库名(The table name needs to include the database name, for example: database_name.table_name)
table-names = ["cs1.t_8_100w"]
# 启动模式:'initial'表示先做全量快照,再持续读增量;'latest'表示只从最新位点读增量
# Optional startup mode for MySQL CDC consumer, valid enumerations are "initial", "earliest", "latest" and "specific".
startup.mode = initial
# 启动时间,可以设置这个时间之后再启动。startup.mode=timestamp时,这个参数必须有
# startup.timestamp
# 会生成随机数,非常重要!指定CDC客户端的唯一ID(如5400)或范围(如5400-6408),不能与MySQL集群中任何现有服务器ID冲突。
server-id = 5400
# 停止模式
# stop.mode
# 停止时间。当stop.mode=timestamp时,这个参数必须有
# stop.timestamp
# 数据库服务器的会话时区,建议设置为 Asia/Shanghai 以正确解析时间戳。
server-time-zone = "Asia/Shanghai"
}
}
# 清洗转换(cdc的清洗转换,必须在transform中来做)
transform {
# 1. 字段映射
# 除了Sql插件,还可以用:FieldMapper插件,来映射字段。必须写出目标需要的字段。不写的字段的值不会采集。
FieldMapper {
field_mapper = {
id = id
name = user_name
sex = sex
decimal_f = decimal_f
phone_number = phone_number
age = age
create_time = create_time
description = description
}
}
# 2. 手机号脱敏:13812341234 -> 138****1234
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# 5. 数据过滤:只保留 age > 25 的记录。
# 6. 地址默认值:空地址设为'未知'
}
sink {
jdbc {
url = "jdbc:mysql://ip:port/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = cs2
table = "t_8_100w_imp_st_qxzh_cdc_demo7_1"
# 表不存在时报错(任务失败),一般用:CREATE_SCHEMA_WHEN_NOT_EXIST(表不存在时创建表;表存在时跳过操作(保留数据))
schema_save_mode = "ERROR_WHEN_SCHEMA_NOT_EXIST"
# APPEND_DATA:保留表结构和数据,追加新数据(不删除现有数据)(一般用这个)
# DROP_DATA:保留表结构,删除表中所有数据(清空表)——实现清空重灌
data_save_mode = "APPEND_DATA"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
# batch_interval_ms = 0
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
- 结果
2025-12-11 15:23:41,170 INFO [o.a.s.e.s.CoordinatorService ] [pool-7-thread-1] - [localhost]:5801 [seatunnel-186786] [5.1]
***********************************************
CoordinatorService Thread Pool Status
***********************************************
activeCount : 2
corePoolSize : 10
maximumPoolSize : 2147483647
poolSize : 10
completedTaskCount : 218
taskCount : 220
***********************************************
2025-12-11 15:23:41,172 INFO [o.a.s.e.s.CoordinatorService ] [pool-7-thread-1] - [localhost]:5801 [seatunnel-186786] [5.1]
***********************************************
Job info detail
***********************************************
createdJobCount : 0
pendingJobCount : 0
scheduledJobCount : 0
runningJobCount : 1
failingJobCount : 0
failedJobCount : 0
cancellingJobCount : 0
canceledJobCount : 0
finishedJobCount : 0
***********************************************
2025-12-11 15:23:46,167 INFO [o.a.s.e.c.j.JobMetricsRunner ] [job-metrics-runner-1051397352734064641] -
***********************************************
Job Progress Information
***********************************************
Job Id : 1051397352734064641
Read Count So Far : 1000009
Write Count So Far : 1000009
Average Read Count : 0/s
Average Write Count : 0/s
Last Statistic Time : 2025-12-11 15:22:46
Current Statistic Time : 2025-12-11 15:23:46
***********************************************
2025-12-11 15:23:46,573 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - wait checkpoint completed: 36
2025-12-11 15:23:46,597 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - pending checkpoint(36/1@1051397352734064641) notify finished!
2025-12-11 15:23:46,597 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - start notify checkpoint completed, job id: 1051397352734064641, pipeline id: 1, checkpoint id:36
2025-12-11 15:23:56,573 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - wait checkpoint completed: 37
2025-12-11 15:23:56,588 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - pending checkpoint(37/1@1051397352734064641) notify finished!
2025-12-11 15:23:56,588 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - start notify checkpoint completed, job id: 1051397352734064641, pipeline id: 1, checkpoint id:37
2025-12-11 15:24:06,573 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - wait checkpoint completed: 38
2025-12-11 15:24:06,589 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - pending checkpoint(38/1@1051397352734064641) notify finished!
2025-12-11 15:24:06,589 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - start notify checkpoint completed, job id: 1051397352734064641, pipeline id: 1, checkpoint id:38
2025-12-11 15:24:16,574 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - wait checkpoint completed: 39
2025-12-11 15:24:16,603 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - pending checkpoint(39/1@1051397352734064641) notify finished!
2025-12-11 15:24:16,603 INFO [.s.e.s.c.CheckpointCoordinator] [seatunnel-coordinator-service-8] - start notify checkpoint completed, job id: 1051397352734064641, pipeline id: 1, checkpoint id:39
- 结果图

四、演示Mysql-CDC(单表-清洗转换)
五、演示Mysql-CDC(多表)
-
演示多个表同时cdc监控,一个conf的job


 浙公网安备 33010602011771号
浙公网安备 33010602011771号