

Flink简介
是什么
Apache Flink是Apache基金会开发的开源流处理框架,其核心是由Java和Scala编写的分布式数据流引擎。对无界和有界数据进行有状态计算。
Flink 是有状态的和容错的,可以在维护一次应用程序状态的同时无缝地从故障中恢复;它支持大规模计算能力,能够在数千个节点上并发运行;它具有很好的吞吐量和延迟特性。同时,Flink 提供了多种灵活的窗口函数
API
-
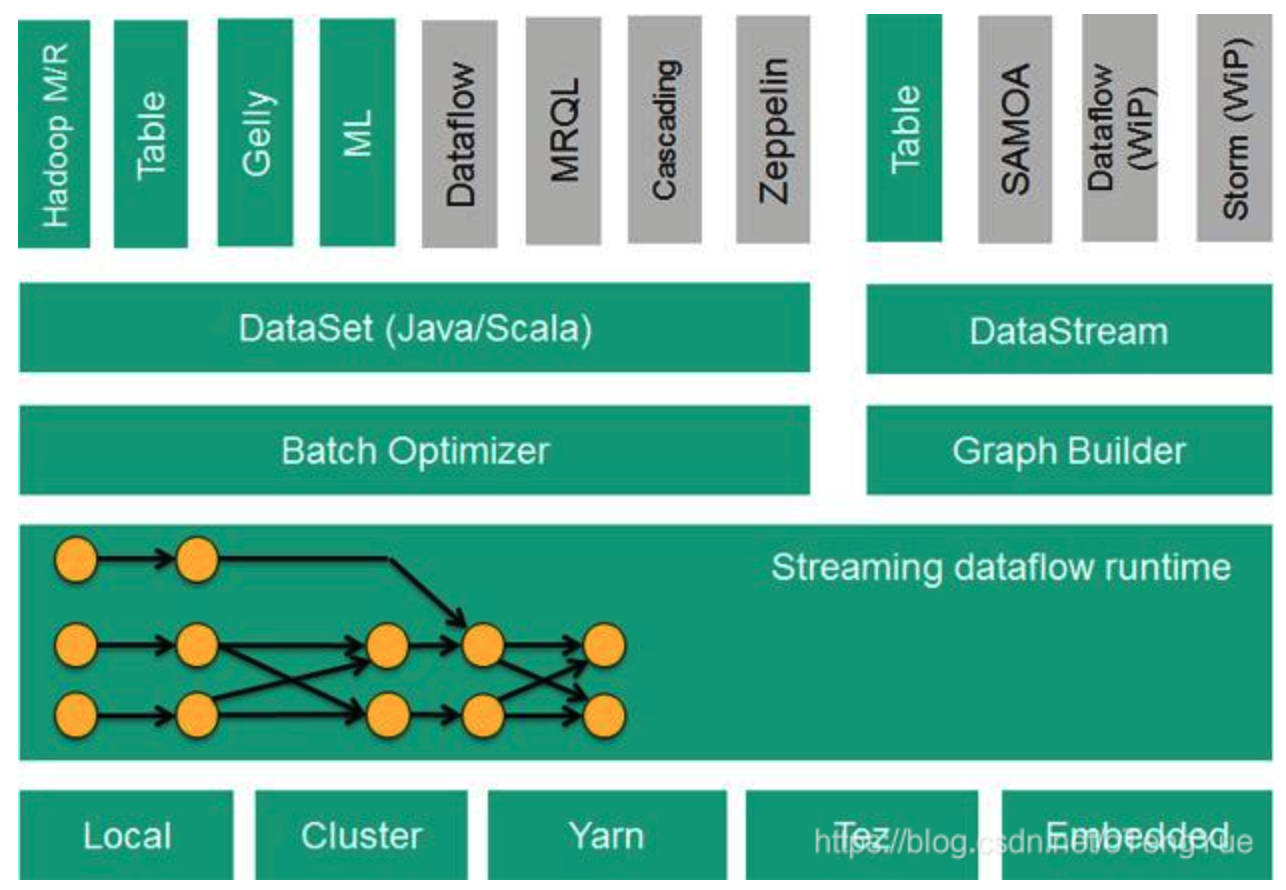
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
-
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
-
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
优点
- 提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下
- 它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误
- 大规模运行,在上千个节点运行时有很好的吞吐量和低延迟
应用场景
| 场景 | 定义 | 举例 | |
| 事件驱动型应用 | 事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。 |
反欺诈 基于规则的报警 业务流程监控 |
|
| 数据分析型应用 | 数据分析任务需要从原始数据中提取有价值的信息和指标 | 消费者技术中的实时数据即席分析 | |
| 数据管道应用 |
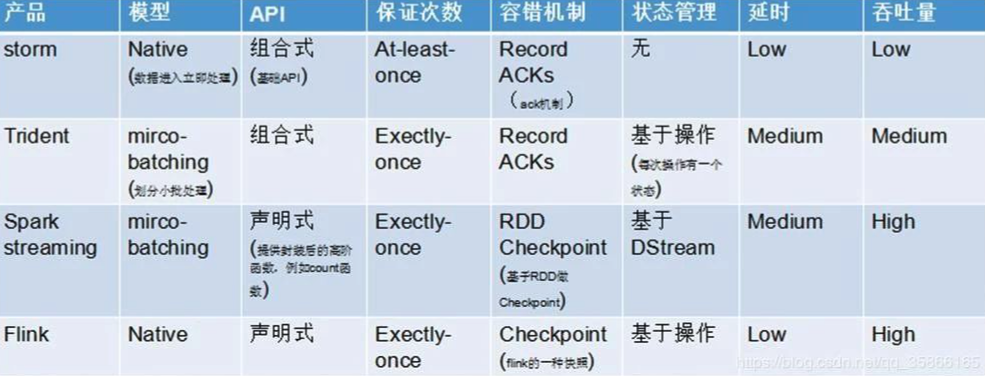
Flink & Storm & SparkStreaming 流处理框架的区别
- Strom:纯实时处理数据,吞吐量小 --水龙头滴水。Strom 的容错机制需要对每条数据进行 ack,因此其吞吐量瓶颈也是备受诟病
- SparkStreaming : 准实时处理数据,微批处理数据,吞吐量大 --河道中开闸关闸。生态总体更为完善一些,且在机器学习的集成和应用性暂时领先
- Flink:纯实时处理数据,吞吐量大 --河流远远不断。真正意义上的单条处理,每一条数据都触发计算;容错机制较为轻量,对吞吐量影响较小
参考
https://flink.apache.org/zh/usecases.html
https://zhuanlan.zhihu.com/p/90024398

 浙公网安备 33010602011771号
浙公网安备 33010602011771号