


实际压测学习记录一
一、数据库连接数是否够
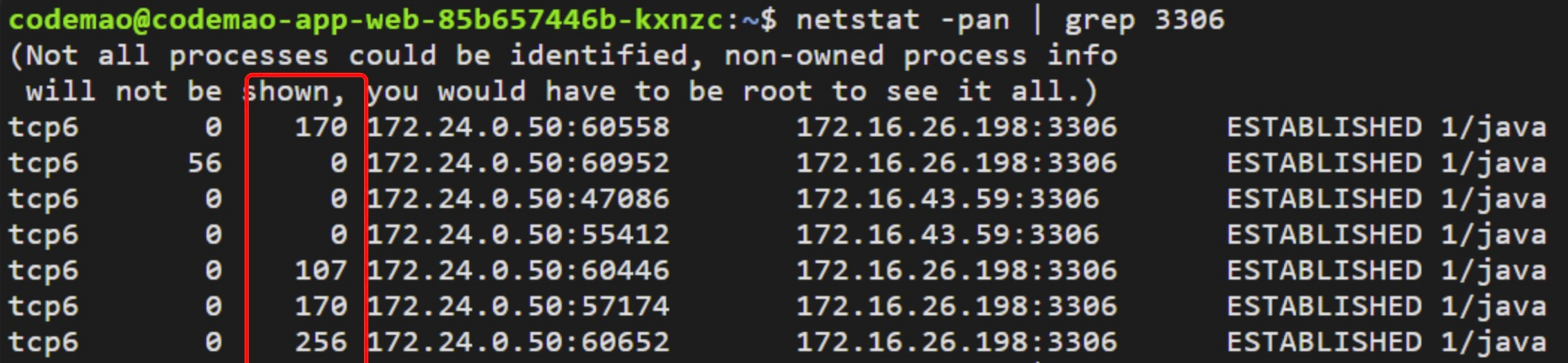
使用 netstat -pan | grep 3306
查看第三列 存在非0 就是表示发送队列有数据,也就是服务给mysql发数据时,还没有发出去的数据。一般是指mysql有瓶颈
使用 netstat -pan head
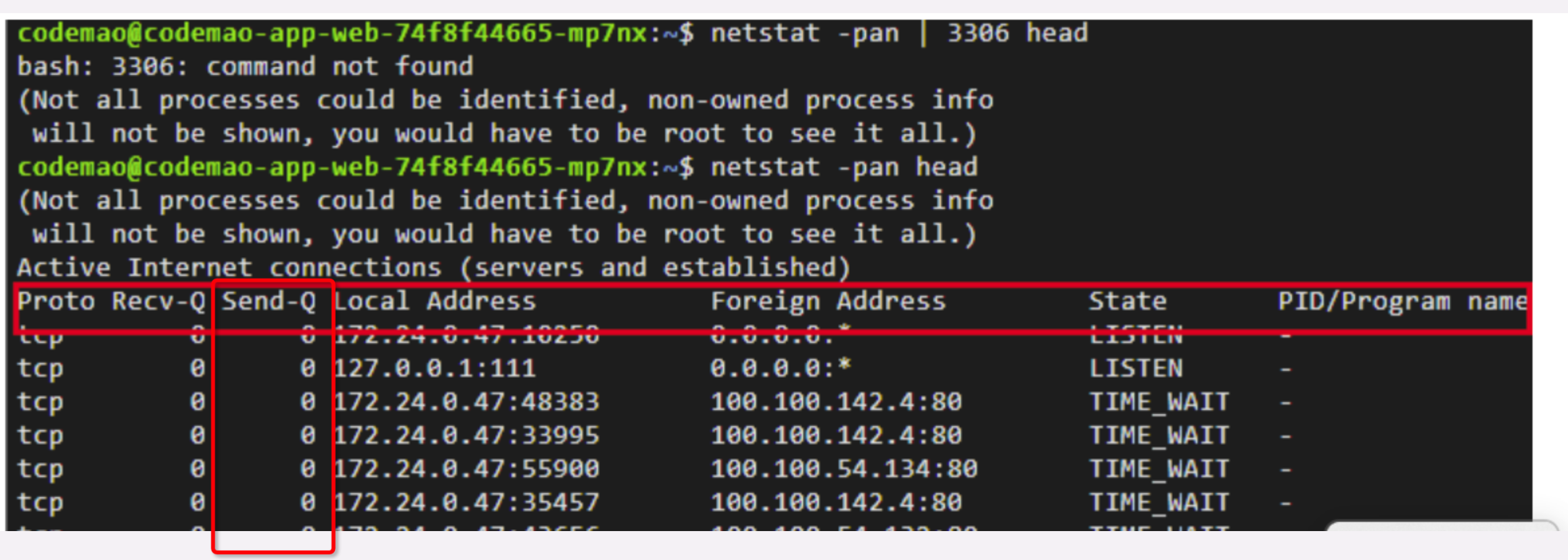
原因 服务数据库连接数设置太小

调整为 max-pool-size:100,min-idle:30
be有值-园姐说 这一列说明请求在等db,数据连接可能不够,也有可能是db爆了,处理不过来

二、容器带宽是否用完
常识:
1024kb=1mb (兆)
1024mb=1GB
内网一般是10000mb
网线一般是 1000mb
使用 sar -n DEV 1 2 命令
rxkb为读(获取回来) 每秒接收数据量
txkb为传输出去 每秒发送数据量
https://blog.csdn.net/volitationlong/article/details/81741754

三、cpu利用率高
用arthas导出火焰图看那个方法占用,且用trace追踪方法的调用过程 方法耗时多少
https://www.cnblogs.com/kaibindirver/p/17142217.html (怎么导出火焰图)
https://www.cnblogs.com/kaibindirver/p/17142318.html (火焰图怎么看)
https://www.cnblogs.com/kaibindirver/p/15354410.html (trace方法追踪)
比如下面追踪耗cpu方法中看到调用了skywalking监控 0.044s 100吞吐量 100*0.044=0.4s(处理100人/s 平均多耗费了0.4s)
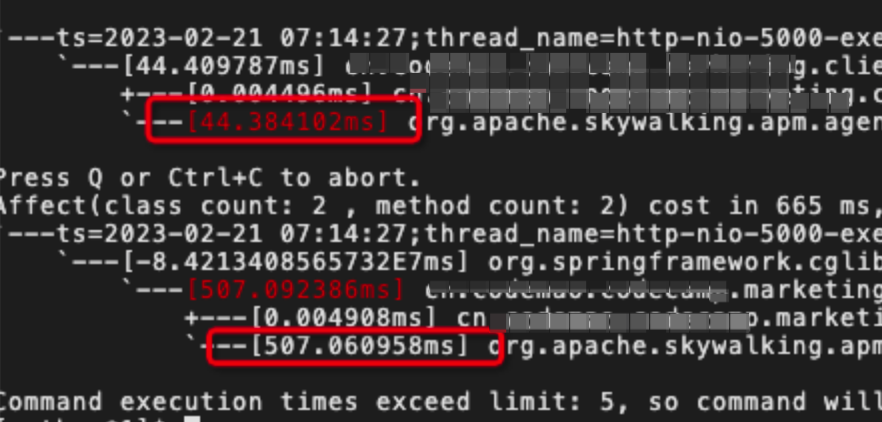
三、关闭多余日志
四、上下调整并发线程 找到最佳吞吐量
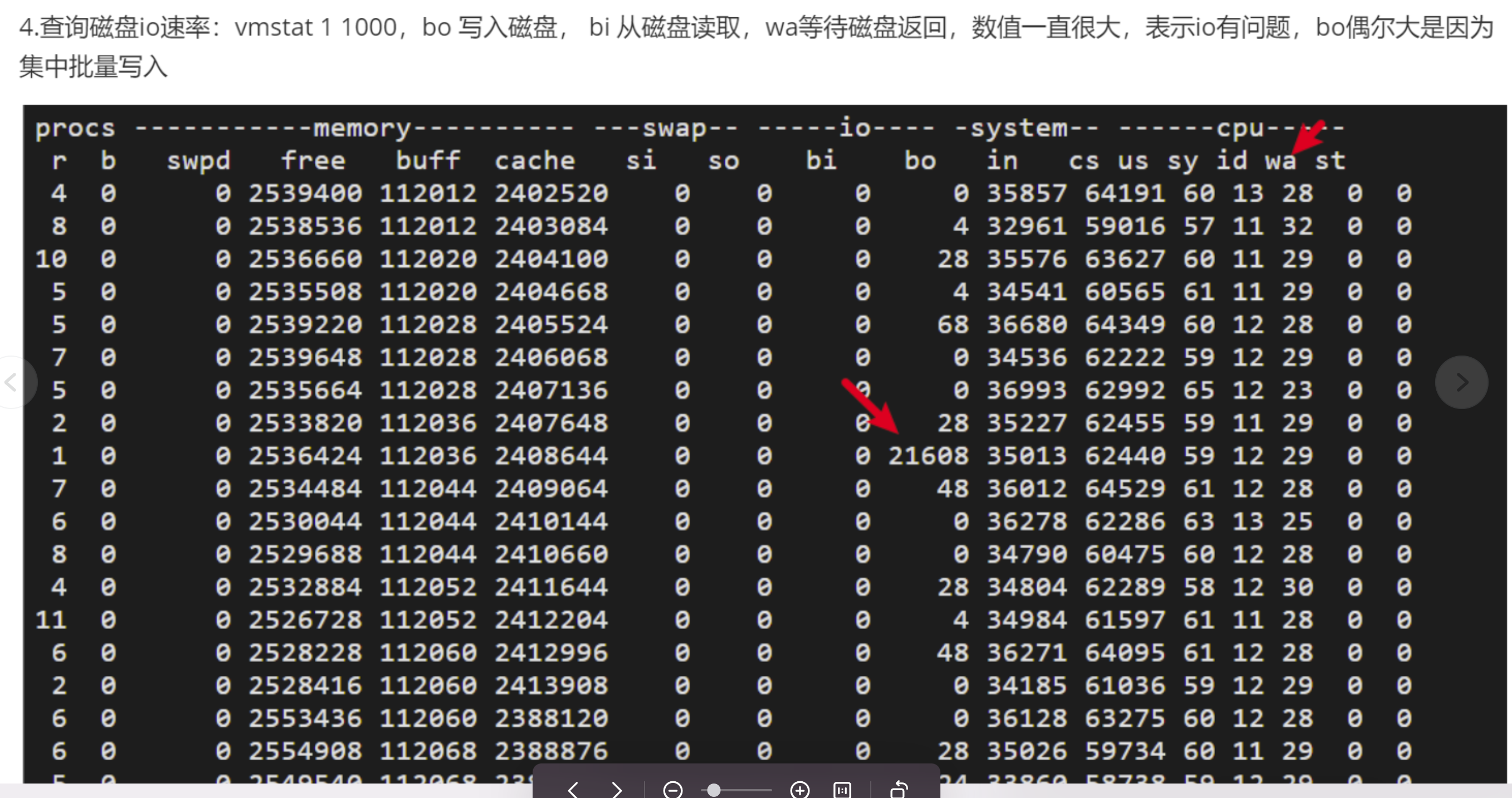
五、查询内存数据写入池盘io问题
服务器资源分析-内存瓶颈
五、数据库连接数
https://www.cnblogs.com/kaibindirver/p/17100305.html
六、在arthus中动态调整日志级别
待补充
七、数据库cpu 100%
https://www.cnblogs.com/kaibindirver/p/17104905.html
八、查找短链接
netstat -npt |grep TIME_WAIT |wc -l

netstat -npt |grep TIME_WAIT (这个是出来明细)
场景:
可以修改feign
怎么使用长链接配置,貌似是 Feign中使用OkHttp 连接池啥的
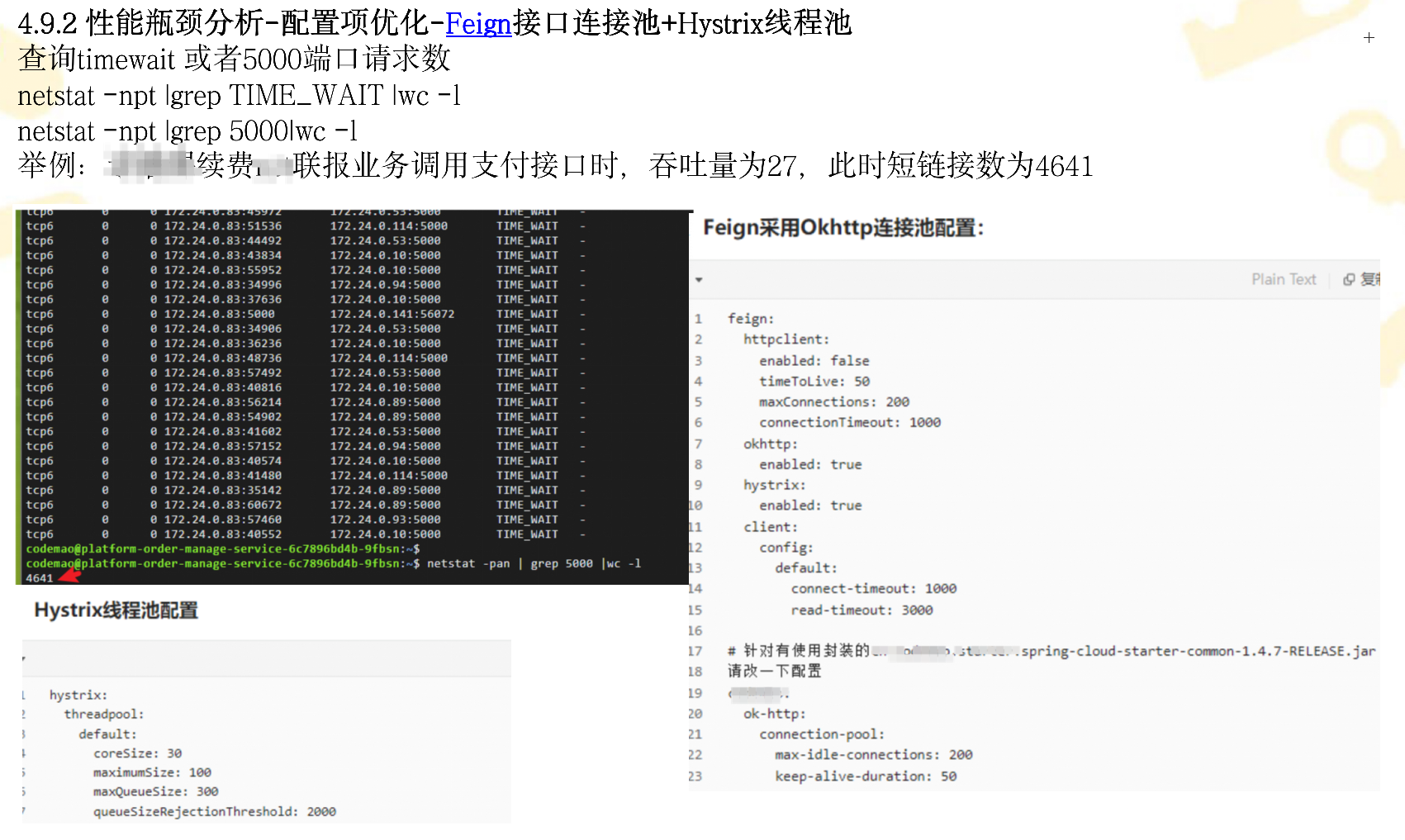
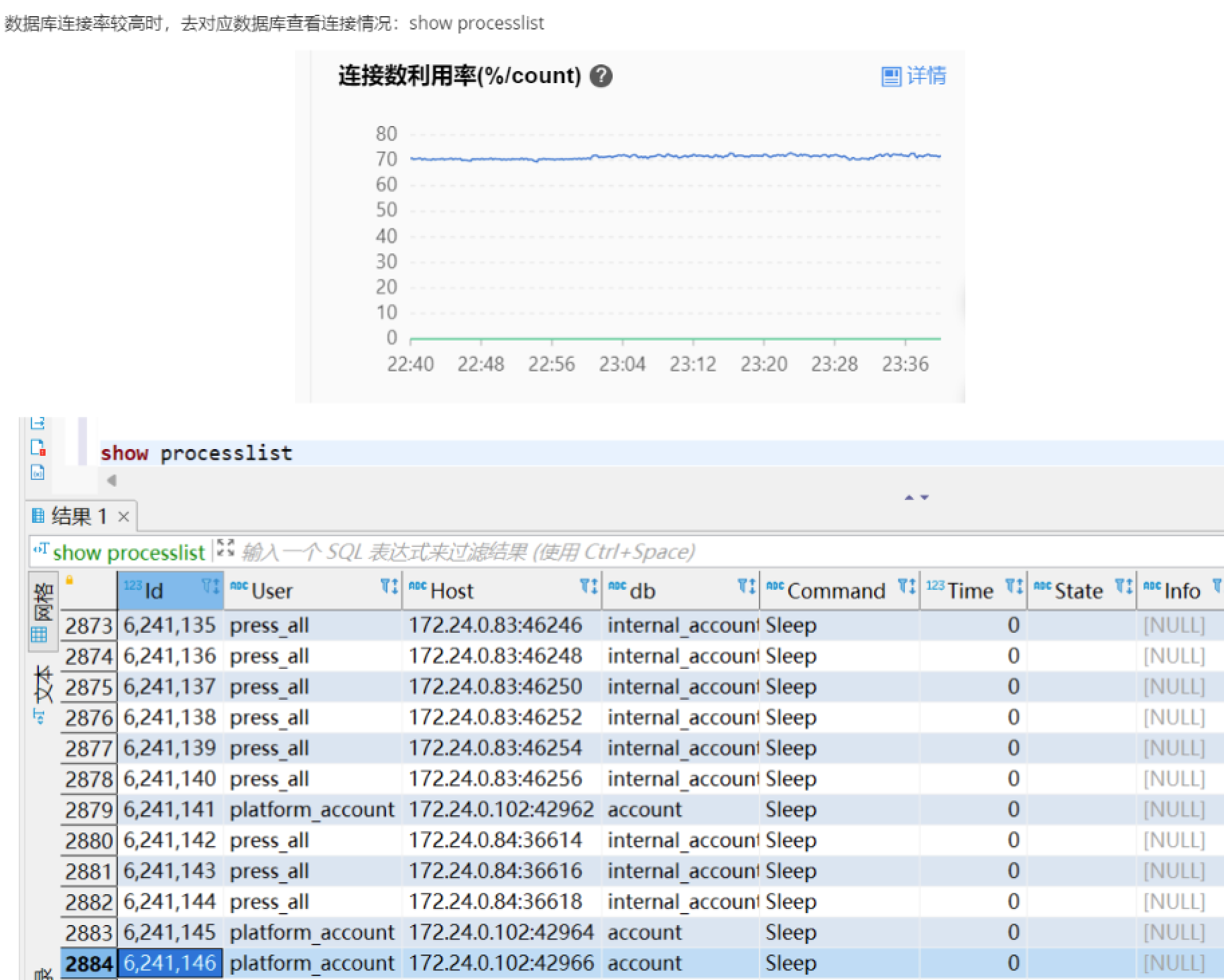
九、数据库连接率
服务没有跑之前连接数利用率就偏高 用下面的命令看下,肯能是最小连接数 设置太大了
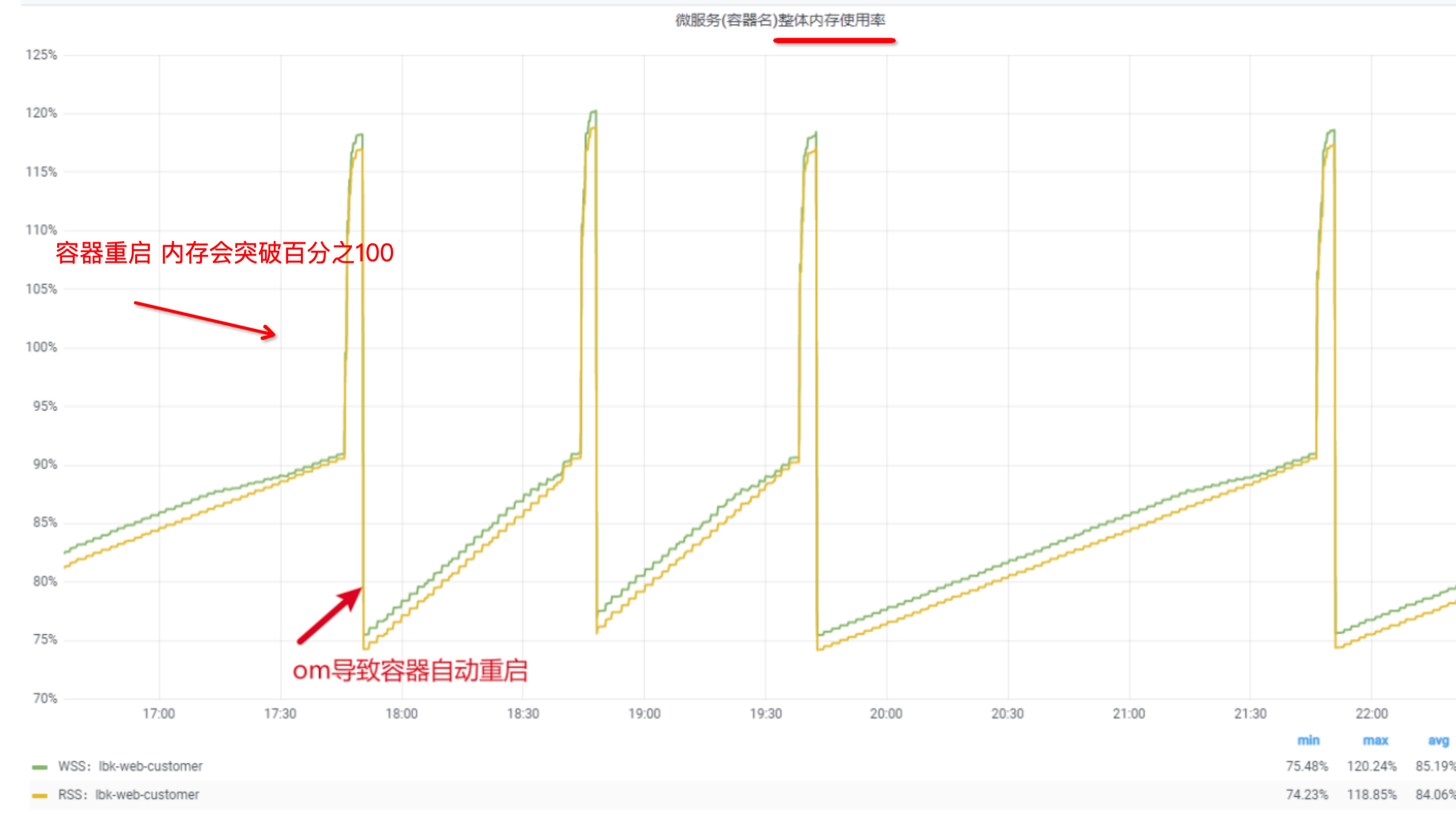
十、内存溢出
使用 dmesg 命令
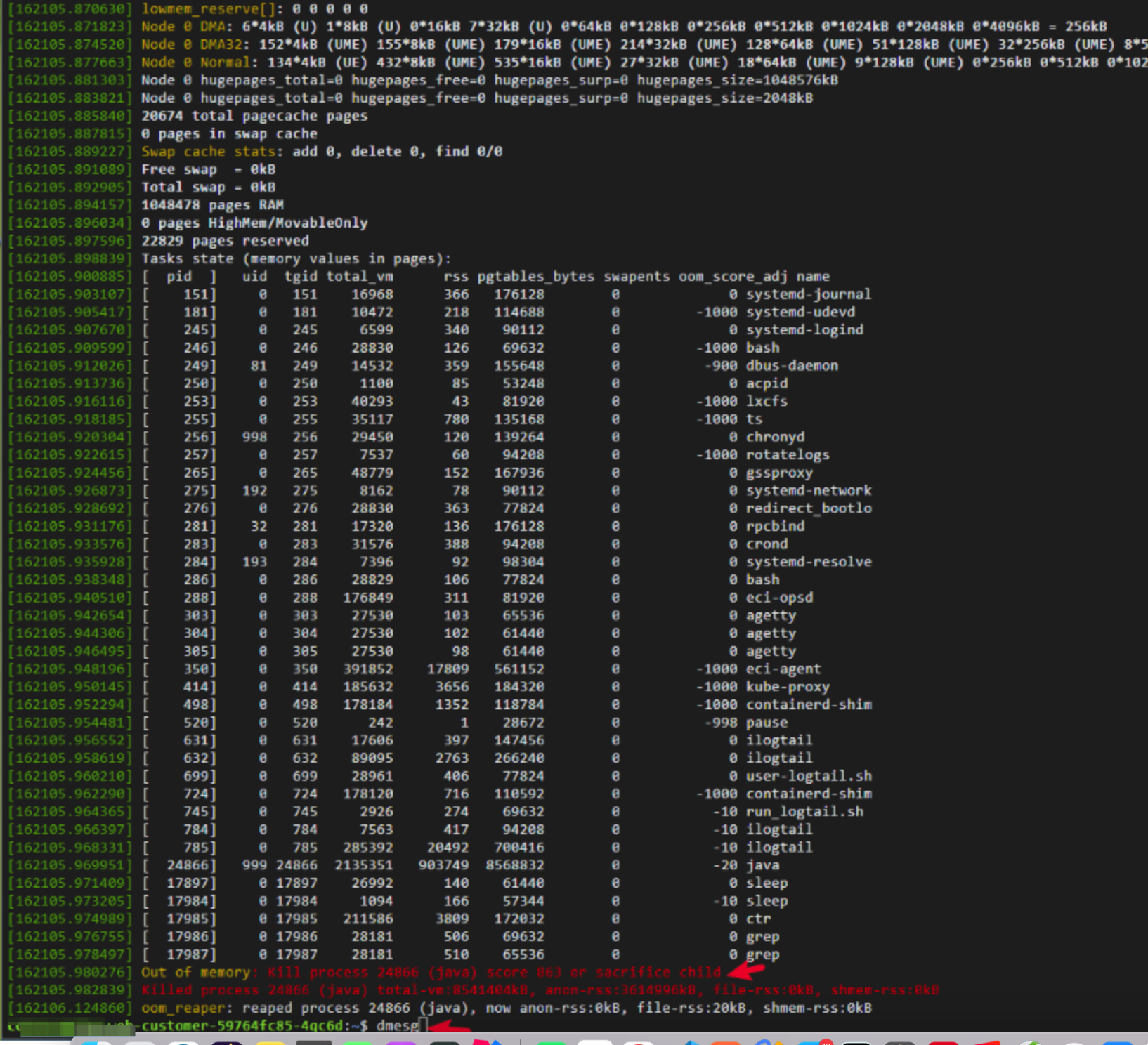
下面会告诉你这个容器到现在有木有内存不足的问题 见底部
我们用
出现问题把堆栈信息导出
jmap -dump:live,format=b,file=myjmapfile.hprof 19570 保存内存快照下来分析
https://www.cnblogs.com/kaibindirver/p/15982389.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号