


canal笔记
工作原理
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
一、mysql创建一个可用的账号
-- 使用命令登录:mysql -u root -p
-- 创建用户 用户名:canal 密码:Canal@123456
create user 'canal'@'%' identified by 'Canal@123456';
-- 授权 *.*表示所有库
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by 'Canal@123456';数据库开启binlog
查看binglog日志及开启方法请移步: https://www.cnblogs.com/kaibindirver/p/16540069.html
一、下载canal.deployer 及启动
https://github.com/alibaba/canal/releases
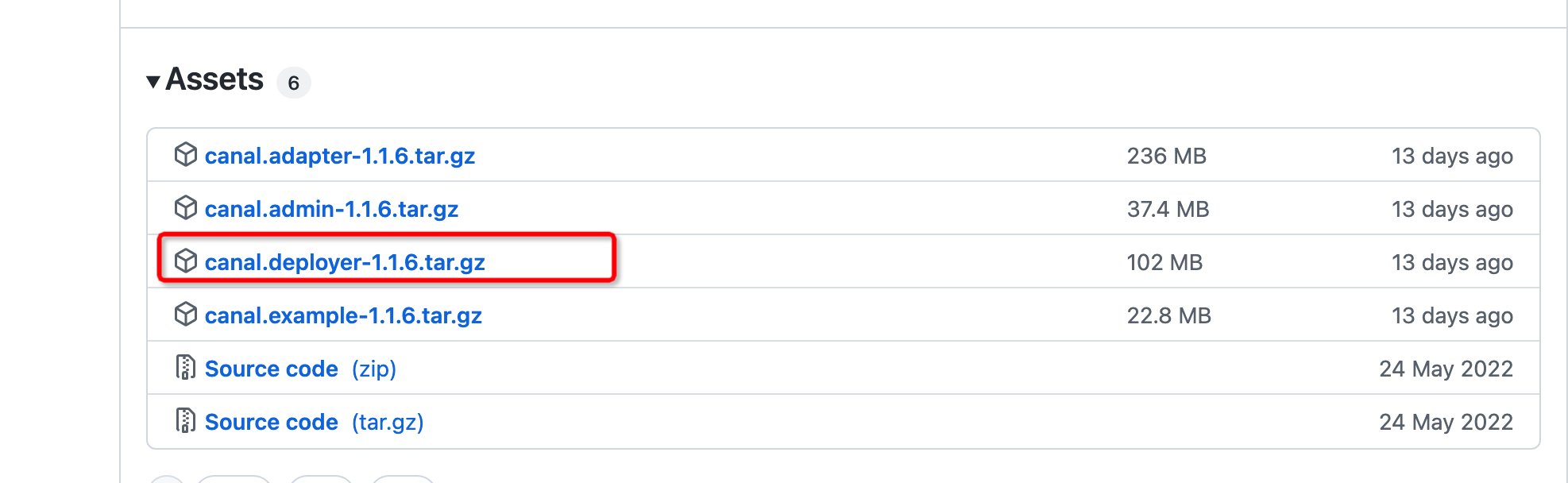
官方说明: https://github.com/alibaba/canal/wiki/QuickStart
解压后对其配置文件进行修改
配置文件conf/example/instance.propertiesv
## mysql serverId--随便写但是不要重复
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = 192.168.1.103:3317
canal.instance.master.journal.name = mysql-bin.000005
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = Canal@123456
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex # mysql 数据解析表的-只接收某表,多个表用,隔开 见 https://blog.csdn.net/leilei1366615/article/details/108819651
canal.instance.filter.regex = .\*\\\\..\*
//mysql 数据解析关注的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠(\) 常见例子:1. 所有表:.* or .\… 2. canal schema下所有表: canal\…* 3. canal下的以canal打头的表:canal\.canal.* 4. canal schema下的一张表:canal\.test15. 多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)这里开始的时候制定了binlog文件,后续数据库binglog变了,canal.deployer也会自动记录在上面instance.properties配置文件下的meta.dat里面记录最新的
canal.instance.filter.regex 指定接收某库某表的,adapter只会接收到指定的库表信息 对呀log日志文件就不会你那么大
canal.instance.filter.regex = eee_mlz_bbb\…* 只接收eee_mlz_bbbeee_mlz_bbb库下的所有表信息变更
在bin目录下启动
sh startup.sh
/canal/canal.deployer-1.1.5/logs/canal/canal.log
log会打印出服务的ip和暴露的端口

/logs/example/example.log
log这个是binlog的变动

遇到问题解决:
canal deployer运行出现 org.h2.jdbc.JdbcSQLException: Wrong user name or password
解决: 删除canal.deployer/conf/example中的XX.mv.db文件
参考: https://blog.csdn.net/weixin_41098099/article/details/115656887
目录: /conf/example/meta.dat
有时候客户端接收不到数据,是因为meta.dat里面指定的log文件不对,把他删了重新启动即可
二、编写客户端,从canal获取变更的消息
1、创建springboot项目
2、首先引入maven依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
目录结构
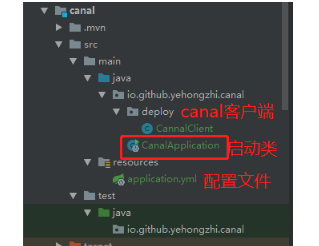
在CannalClient类使用Spring Bean的生命周期函数afterPropertiesSet():
@Component
public class CannalClient implements InitializingBean {
private final static int BATCH_SIZE = 1000;
@Override
public void afterPropertiesSet() throws Exception {
// 创建链接 ,这里输入的是cannel的服务ip和他默认暴露的端口11111
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
//打开连接
connector.connect();
//订阅数据库表,全部表
connector.subscribe(".*\\..*");
//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(BATCH_SIZE);
//获取批量ID
long batchId = message.getId();
//获取批量的数量
int size = message.getEntries().size();
//如果没有数据
if (batchId == -1 || size == 0) {
try {
//线程休眠2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//如果有数据,处理数据
printEntry(message.getEntries());
}
//进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
}
/**
* 打印canal server解析binlog获得的实体类信息
*/
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
//开启/关闭事务的实体类型,跳过
continue;
}
//RowChange对象,包含了一行数据变化的所有特征
//比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等
RowChange rowChage;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
//获取操作类型:insert/update/delete类型
EventType eventType = rowChage.getEventType();
//打印Header信息
System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
//判断是否是DDL语句
if (rowChage.getIsDdl()) {
System.out.println("================》;isDdl: true,sql:" + rowChage.getSql());
}
//获取RowChange对象里的每一行数据,打印出来
for (RowData rowData : rowChage.getRowDatasList()) {
//如果是删除语句
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
//如果是新增语句
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
//如果是更新的语句
} else {
//变更前的数据
System.out.println("------->; before");
printColumn(rowData.getBeforeColumnsList());
//变更后的数据
System.out.println("------->; after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}当数据库发生变化时,就会收到消息,如果收不到查看下 cannel服务的/logs目录下各log文件,看有没有报错的信息

这里有个别人写好可 以直接插入数据库的到时看看 https://blog.csdn.net/qq_36971119/article/details/122856561
三、同步到其他数据库的方法
1、下载adapter文件
https://github.com/alibaba/canal/releases
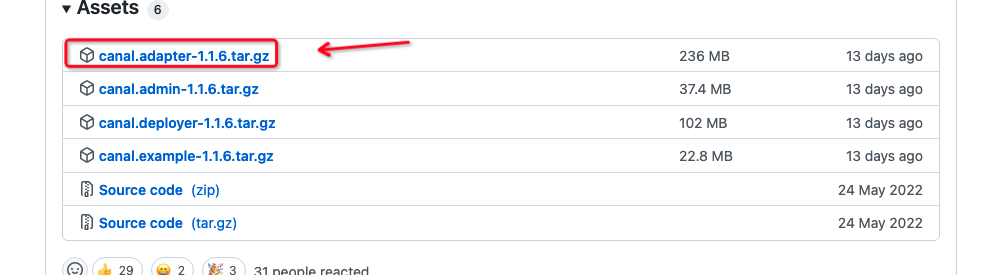
官方说明 https://github.com/alibaba/canal/wiki/ClientAdapter
(注意这个文件要放到没有中文的目录下面!!!!!!!!---晕死踩坑2次)
有中文会启动报 Caused by: java.lang.RuntimeException: Config dir not found.
目录文件
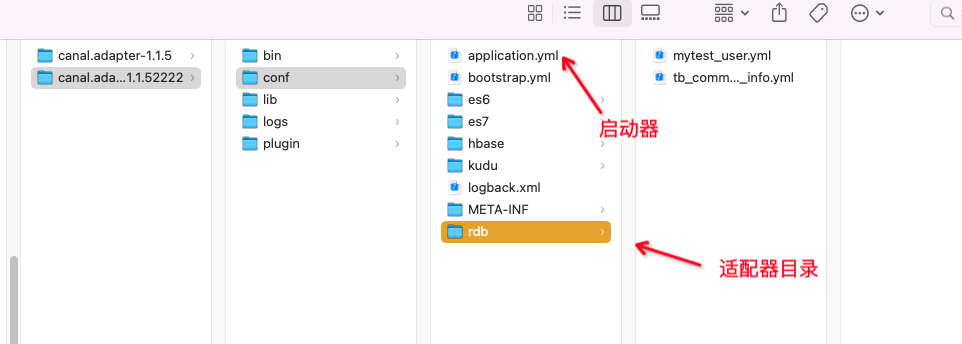
2、配置配置文件及启动
启动器文件 application.yml
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
# srcDataSources:
# defaultDS:
# url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true
# username: root
# password: 121212
canalAdapters:
- instance: example # canal instance Name or mq topic name --给要同步的目标数据库启个别名
groups:
- groupId: g1
outerAdapters:
- name: logger //这个注释掉貌似少了些信息,canal.deployer 配置获取的表命中才打出日志
- name: rdb
key: mysql1
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://192.168.1.103:3306/max?useUnicode=true
jdbc.username: root
jdbc.password: 123456
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
# - name: es
# hosts: 127.0.0.1:9300 # 127.0.0.1:9200 for rest mode
# properties:
# mode: transport # or rest
# # security.auth: test:123456 # only used for rest mode
# cluster.name: elasticsearch
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
适配器文件
同步max库 student2 表
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # cannal的instance或者MQ的topic
groupId: g1
outerAdapterKey: mysql1 # adapter key, 对应上面配置outAdapters中的key
concurrent: true # 是否按主键hase并行同步, 并行同步的表必须保证主键不会更改及主键不能为其他同步表的外键!!
dbMapping:
database: 123 # 源数据源的database/shcema
table: student # 源数据源表名
targetTable: student2 # 目标数据源的库名.表名--我在启动器指定了数据库的库了
targetPk: # 主键映射
id: id # 如果是复合主键可以换行映射多个
# mapAll: true # 是否整表映射, 要求源表和目标表字段名一模一样 (如果targetColumns也配置了映射,则以targetColumns配置为准)
targetColumns: # 字段映射, 格式: 目标表字段: 源表字段, 如果字段名一样源表字段名可不填
id: id
name2: name
# dbMapping:
# mirrorDb: true
# database: 123
同步max库 tb_commodity_info 表
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # cannal的instance或者MQ的topic
groupId: g1
outerAdapterKey: mysql1 # adapter key, 对应上面配置outAdapters中的key
concurrent: true # 是否按主键hase并行同步, 并行同步的表必须保证主键不会更改及主键不能为其他同步表的外键!!
dbMapping:
database: 123 # 源数据源的database/shcema
table: tb_commodity_info # 源数据源表名
targetTable: tb_commodity_info # 目标数据源的库名.表名 ----我在启动器指定了数据库的库了
targetPk: # 主键映射
id: id # 如果是复合主键可以换行映射多个
mapAll: true # 是否整表映射, 要求源表和目标表字段名一模一样 (如果targetColumns也配置了映射,则以targetColumns配置为准)
# targetColumns: # 字段映射, 格式: 目标表字段: 源表字段, 如果字段名一样源表字段名可不填
# id: id
# name2: name
# dbMapping:
# mirrorDb: true
# database: 123
在bin目录下启动
sh startup.sh
3、操作控制接口
查询所有订阅同步的canal destination 的状态 --(这个可以查询后说明服务已启动好了,不然还得等等)
http://127.0.0.1:8081/destinations

查看单独某个目标数据库
http://127.0.0.1:8081/syncSwitch/example
关闭别名为example的目标数据库同步
curl http://127.0.0.1:8081/syncSwitch/example/off -X PUT
开启别名为example的目标数据库同步
curl http://127.0.0.1:8081/syncSwitch/example/on -X PUT
有个查看目标数据库同步数据的 请求 回头研究下
参考文档:
简单实现cannel入门---canal.deployer
https://blog.csdn.net/yehongzhi1994/article/details/107880162
cannel往mq或redis发
https://blog.csdn.net/yehongzhi1994/article/details/108034330
adapter配置参考
https://blog.csdn.net/weixin_39748445/article/details/113231208
https://blog.csdn.net/qq_29860591/article/details/110217909 --主要参考了这个
https://www.wenjiangs.com/doc/client-adapter ---貌似出处在这里
视频
https://www.bilibili.com/video/BV1jY41177Qh?spm_id_from=333.337.search-card.all.click&vd_source=caabcbd2a759a67e2a3de8acbaaf08ea
官网wiki介绍:
https://github.com/alibaba/canal/wiki
这篇挺全的还有个canal的后台可以操作
https://blog.csdn.net/leilei1366615/article/details/108819651
源码去启动见这篇
https://blog.csdn.net/wx2207/article/details/121538475
部署到服务器
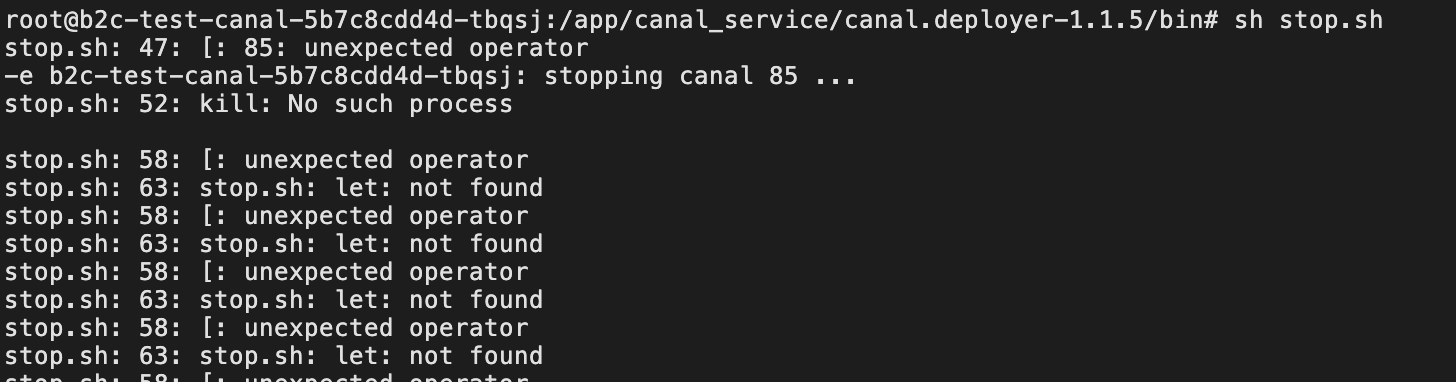
sh命令后面要加&,不然无法使用2个sh的命令,不加会报下面的错误
sh startup.sh &

let: 命令无法识别解决:
sudo dpkg-reconfigure dash 选择 "否", 表示用bash代替dash
https://www.cnblogs.com/fanjp666888/p/10022038.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号