

数据库模型---之mysql(操作数据库)含序列化模型对象(类似java实体类映射)
Django==2.1.10首先看看我的目录

字段唯一。unique
name = models.CharField(max_length=30,unique = True,verbose_name='部门名字')
现在guest项目下的__init__.py 加上
import pymysql
pymysql.version_info = (1, 4, 13, "final", 0)
pymysql.install_as_MySQLdb() # 使用pymysql代替mysqldb连接数据库如果不想加那么就安装下面2个库 (啊栋推荐)
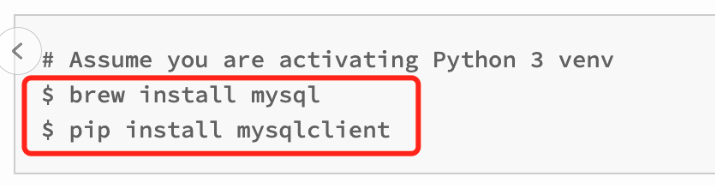
现在guest项目下的settings 加上数据库配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # mysql数据库引擎,
'NAME': 'Django_model', # 数据库名字
'USER': 'root', # 用户名
'PASSWORD': '123456', # 密码
'HOST': 'localhost', # 主机
'PORT': '3317' # 端口
}
}然后在sign应用models.py 写你要创建的表
# Create your models here.
from django.db import models
# 创建表一
class Publisher(models.Model):
"""出版社"""
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
country = models.CharField(max_length=50)
phone=models.CharField(max_length=50)
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')# 创建时间(自动获取当前时间)
update_time = models.DateTimeField(auto_now=True, verbose_name='更新时间')
description=serializers.CharField(allow_null=True,blank=True) #允许客户端不填内容,或者传递一个""
#这个原来是控制 Publisher.objeck.all() 对象返回的字段的,这个返回可以翔数组一样取aa[0]
def __str__(self):
return self.name
class Meta:
db_table = 'article' # 通过db_table自定义数据表名
unique_together=("phone","name") # phone+name 为唯一
verbose_name = "部门类型表" 指定表备注名
app_label = 'Django_model' 指定数据库
# 创建表二
class PublisherTwo(models.Model):
"""出版社"""
name = models.CharField(max_length=30)
phone=models.CharField(max_length=50)
class Meta:
db_table = 'articletwo' # 通过db_table自定义数据表名
unique_together=("phone","name") # phone+name 为唯一
# 模型类 会自动生成 id字段
from django.db import models
class BookInfo(models.Model):
# 书名、发布日期、阅读量、评论量、售空
# 书名 字符串类型 max_length=20最大长度为20
name = models.CharField(max_length=20, verbose_name='书名')
# 发布日期 日期类型 null=True允许为空
pub_date = models.DateField(null=True, verbose_name='发布日期')
# 阅读量 整形 default=0默认为0
read_count = models.IntegerField(default=0, verbose_name='阅读量')
# 评论量 整形 default=0默认为0
comment_count = models.IntegerField(default=0, verbose_name='评论量')
# 售空 布尔类型 default=False默认为假
sale_out = models.BooleanField(default=False, verbose_name='售空')
class Meta:
db_table = 'bookinfo' # 指明数据库表名,如果不设置会叫books_BookInfo
verbose_name = '书籍信息表' # 在admin站点中显示的名称
verbose_name_plural = verbose_name# 在admin站点中显示的名称复数
def __str__(self):
"""定义每个数据对象的显示信息"""
return self.name
# 准备人物列表信息的模型类
class PeopleInfo(models.Model):
GENDER_CHOICES = (
(0, 'male'),
(1, 'female')
)
name = models.CharField(max_length=20, verbose_name='名称')
gender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别')
description = models.CharField(max_length=200, null=True, verbose_name='描述信息')
book = models.ForeignKey(bookinfo, on_delete=models.CASCADE, verbose_name='图书') # 外键
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')
class Meta:
db_table = 'peopleinfo'
verbose_name = '人物信息'
verbose_name_plural=verbose_name
def __str__(self):
return self.name语发参考: https://blog.csdn.net/qishaoawei/article/details/124461222
在项目目录下执行命令(命令行)
//更新表数据变化--会在应用的migrations目录下产生记录文件
sudo python3 manage.py makemigrations
//同步表数据变化(变更数据库表结构)
python3 manage.py migrate
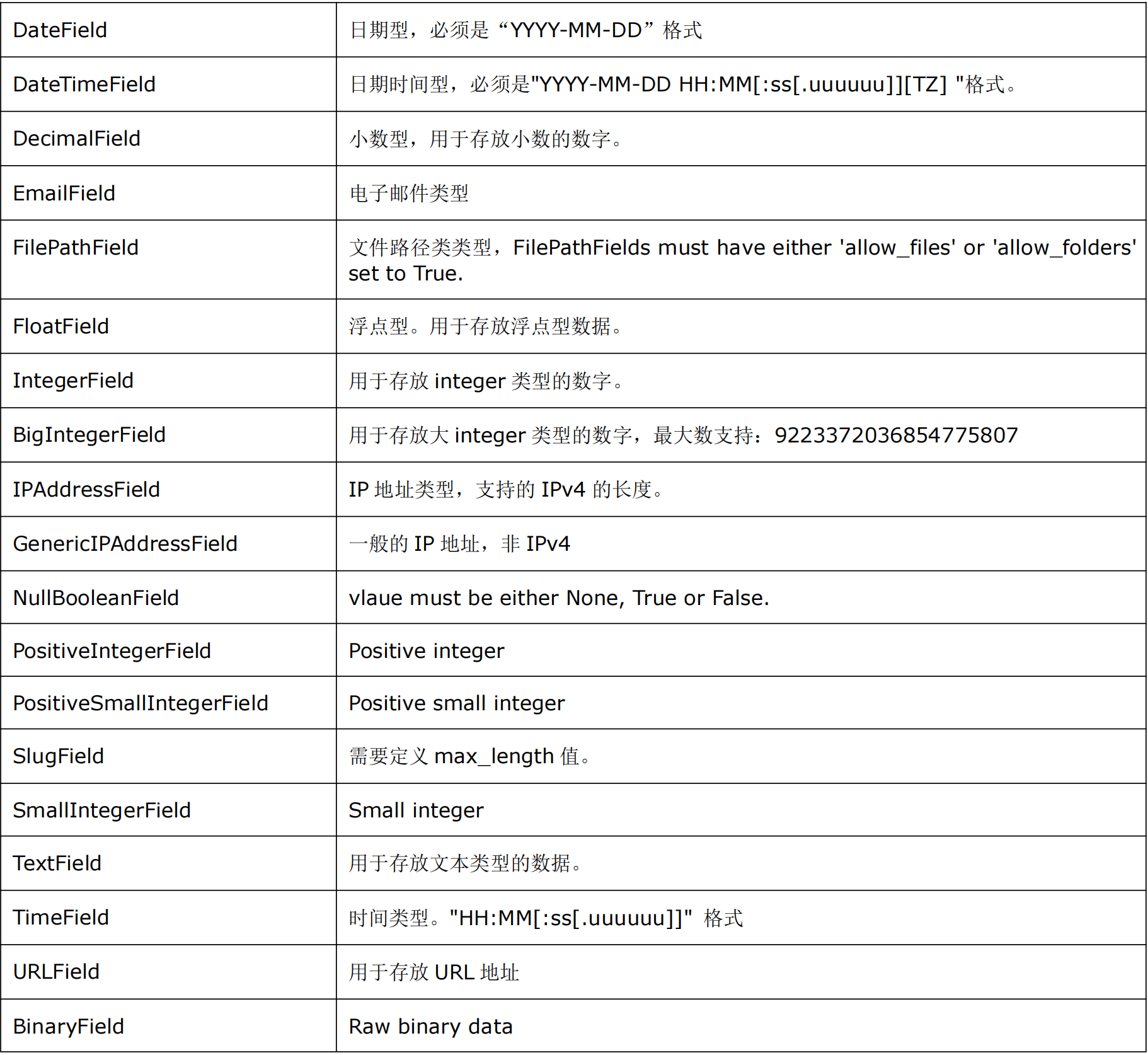
数据库数据类型
- AutoField: 一个自动递增的整型字段,添加记录时它会自动增长。AutoField字段通常只用于充当数据表的主键;如果在模型中没有指定主键字段,则Django会自动添加一个AutoField字段;

具体的可看 https://zhuanlan.zhihu.com/p/535988287 (很详细)
增删改查参考:
https://blog.csdn.net/Fe_cow/article/details/80669146
https://blog.csdn.net/weixin_45451320/article/details/124826361
插入
# uri: sqlGet
def sqlGet(request):
#表的模型
from sign.models import Publisher
# 增
# 1、save无返回值,要执行save后再插入
author = Publisher(name="123911",phone=111111)
author.save()
#2、create有返回值,一条语句就插入
try:
aa=Publisher.objects.create(name="123911",phone=1111121)
except Exception as err:
print("插入失败: ",err)
# 3、先查后插入,防止重复
author=Publisher.objects.get_or_create(last_name='fe_cow')
print(author)
# 4、存在就更新,不存在就插入
Model.objects.update_or_create(defaults,**kwargs)
参考: https://blog.csdn.net/qq_35968173/article/details/107639786
用 python manage.py shell 也可以进入命令行 敲上面上面代码执行查询
def get(self, request):
# 获取数据---所有
scripts = Publisher.objects.all()
#构建序列化对象--查询结果为多个 需要加上many属性
serializer = BookSerializers(instance=scripts, many=True)
# # 调用序列化对象的data获取序列化后的数据
data = serializer.data
return JsonResponse(data,status=200,safe=False,json_dumps_params={"ensure_ascii":False})
# 获取数据---一条
scripts = Publisher.objects.frist()
# # # # 构建序列化对象
serializer = BookSerializers(instance=scripts)
查询后返回json格式
参考: https://blog.csdn.net/qq_21137441/article/details/113133113
1、用django自带的
import json
from django.http import HttpResponse
from django.core import serializers
def db_to_json(request):
//Scripts是实体类---上面模型类的 def __str__(self): 就是控制他的字段返回的,但是下面serialize序列化的时候还是会展示所有的
scripts = Scripts.objects.all()[0:1]
json_data = serializers.serialize('json', scripts)
return HttpResponse(json_data, content_type="application/json")
返回: 如下面返回2条数据
[{"model": "api.publisher", "pk": 1, "fields": {"name": "123", "address": "123", "city": "123", "country": "123", "phone": "123", "create_time": "2011-11-11T01:00:00Z"}}, {"model": "api.publisher", "pk": 2, "fields": {"name": "123", "address": "123", "city": "123", "country": "123", "phone": "1112", "create_time": "2011-11-11T00:00:00Z"}}]
2、用drf组件序列化数据模型
from django.http import HttpResponse,JsonResponse
from OneApp.models import Publisher
from rest_framework import serializers
from rest_framework.views import APIView
from rest_framework.response import Response
# 针对模型设计序列化器
class BookSerializers(serializers.Serializer):
id=serializers.IntegerField()
name=serializers.CharField(max_length=32)
# Create your views here.
class BookView(APIView):
def get(self, request):
# 获取数据,Publisher是实体类--上面models里面的
scripts = Publisher.objects.all()
# # # # 构建序列化对象--查询结果为多个 需要加上many属性
serializer = BookSerializers(instance=scripts, many=True)
# # 调用序列化对象的data获取序列化后的数据
data = serializer.data
#如果返回的数据中文乱码,那么就加上 json_dumps_params属性
#return JsonResponse(data,status=200,safe=False,json_dumps_params={"ensure_ascii":False})
#直接用drf组件的
return Response(data)
返回如下2条
[{"id": 1, "name": "123"}, {"id": 2, "name": "123"}]https://www.bilibili.com/video/BV1XR4y157rk?p=5&vd_source=caabcbd2a759a67e2a3de8acbaaf08ea
针对模型字段和属性见 https://blog.csdn.net/weixin_45827423/article/details/113405360
展示查询日志的方法
在项目settings文件最下面添加一下配置
LOGGING = {
'version':1,
'disable_existing_loggers':False,
'handlers':{
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers':{
'django.db.backends':{
'handlers':['console'],
'propagate':True,
'level':'DEBUG'
},
}
}例子:

查询
查询id条件
Book.objects.get(pk=id)
查询条件
Member.objects.filter(department_id=64)
in查询 department_id in(1,2,3)
Member.objects.filter(department_id__in =department_id_list)
不等于查询
Member.objects.exclude(username=‘老王’)
between查询
Member.objects.filter(commit_time__range=(be,en))
判断字段是否包含某字段
Member.objects.filter(personnel__contains="老王")
还有其他查询方法
https://blog.csdn.net/wtwcsdn123/article/details/88951325
https://blog.csdn.net/m0_37422217/article/details/106881632修改
Book.objects.filter(pk=id).update(title=111,price=11111)删除
(单条)
Book.objects.get(pk=id).delete()(多条)
Book.objects.filter(name="测试员").delete()like 和 or 这些可以使用 Django的Q类 (含让字段默认+1 )
https://www.cnblogs.com/kaibindirver/p/17270963.html
result = table.objects.filter(string__contains='pattern')
等于 string="%pattern%" container = tbl_user.objects.filter(Q(vocation__contains='开发')|Q(vocation__contains='技术'),email=msg).values_list("username")
等于 where vocation like "%开发%" or vocation like "%技术%" and email=msg
模型类需要自动新增的创建时间和更新时间
create_time = models.DateTimeField(auto_now_add=True,verbose_name='创建时间')
update_time = models.DateTimeField(auto_now=True,verbose_name='更新时间')还要去数据库里面设置一下字段
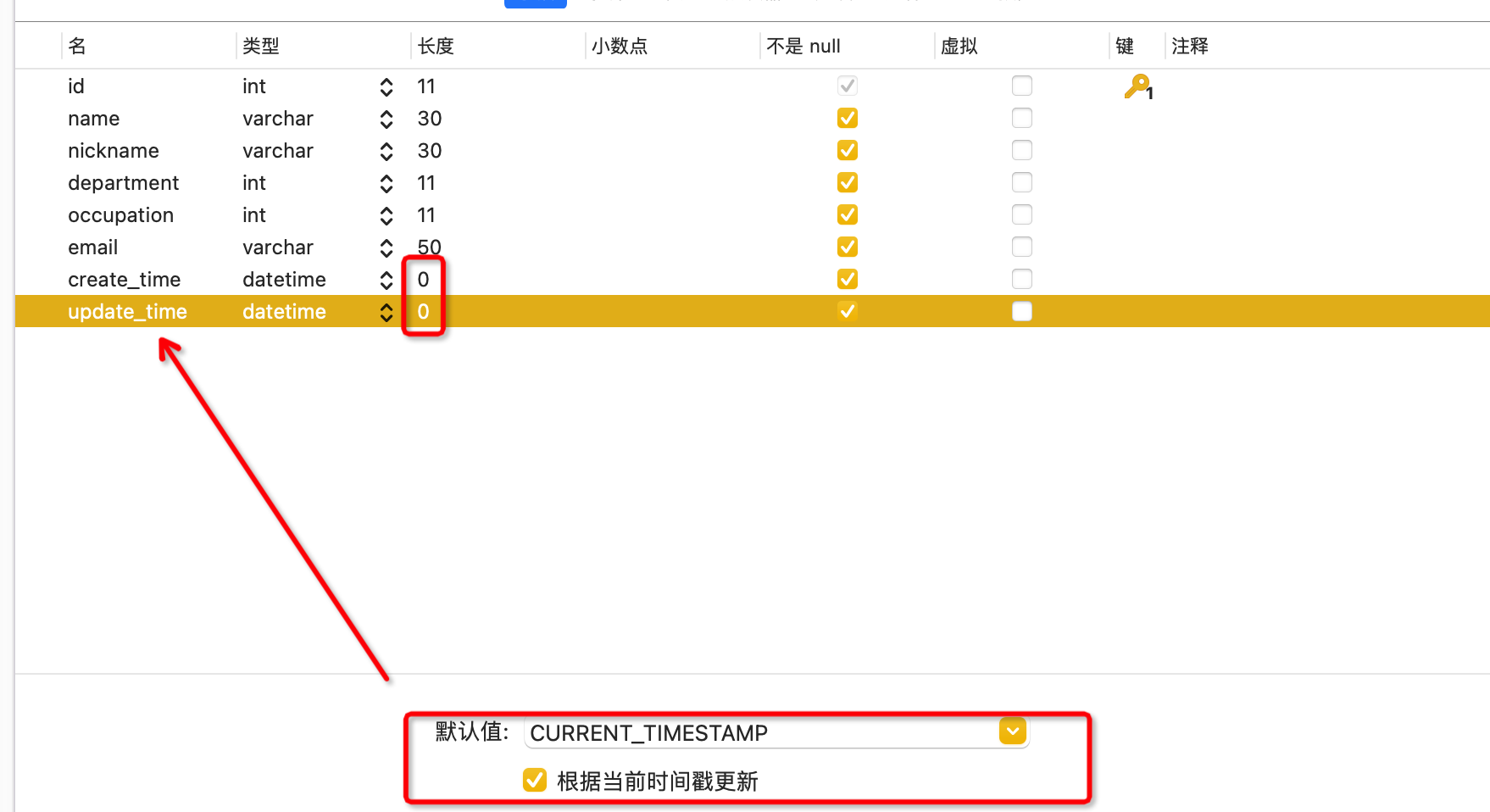

设置一下,让表可以存中文
alter table tapd_department convert to character set utf8;
踩坑1
模型类里面输出字段,如果是int类型的要加str(),不然查询后获取会报错
def __str__(self):
"""定义每个数据对象的显示信息"""
return str(self.nicknameid)
踩坑2
def __str__(self):
return self.name
这里只能返回str类型的,如果要传多个可以这么写,然后接受后再把他转成list即可
def __str__(self):
return f"{self.department_id},{self.department_id}"
接收的这么写
#查询所有人员+部门
def get_ALL_Members():
manList=Member.objects.filter()
for i in manList:
print(str(i).split(",")[0])
从踩坑2 发现 不用 __str__ retun 也可以拿字段!!!!!! 用 .values_list 获取要的字段就可以了!!!返回的是元组
manList=Member.objects.all().values_list("department_id", "email")
for i in manList:
print(i)
踩坑3 只有一个字段唯一 要写多一个不然会报错
class Meta:
db_table = 'articletwo' # 通过db_table自定义数据表名
unique_together=("name","name") # name 为唯一
这样写可以不用序列化可以像数组那样取值 ,并且中文也显示正常(亲测ok)
查出来的数据里面存在日期见: https://www.cnblogs.com/kaibindirver/p/17029991.html
import json
import datetime
class DateEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime.datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
else:
return json.JSONEncoder.default(self, obj)
#存在datatime类型的值
id_obje = tbl_api_info.objects.values().filter(pk__in=ids)
param_config = eval(json.dumps(list(id_obje), cls=DateEncoder, ensure_ascii=False))
#不存在datatime类型这样写也可以
json.dumps(list(id_obje),ensure_ascii=False)
#不存在datatime类型也可以这么写
scripts = PatrolReq.objects.filter(patrol_task_id=int(patrol_task_id))
serializer = PatrolReqSerializers(instance=scripts, many=True)
data = serializer.data
print(
json.dumps(list(data))
)
[{"name":2},{"name":1}]
values() 和 values_list()
id_obje = PatrolTask.objects.values_list().filter(id=taskid)
print(list(id_obje))
返回 [(1, '任务一', 1, '0', '0', '0', 0, 999999, 1, 0, datetime.datetime(2022, 12, 28, 17, 8, 3), datetime.datetime(2022, 12, 28, 17, 8, 3))]
id_obje = PatrolTask.objects.values().filter(id=taskid)
print(list(id_obje))
[{'id': 1, 'patrolname': '任务一', 'tapd_department_id': 1, 'createduser': '0', 'updatauser': '0', 'dingding': '0', 'last_result': 0, 'time': 999999, 'status': 1, 'is_delete': 0, 'create_ti: datetime.datetime(2022, 12, 28, 17, 8, 3), 'update_time': datetime.datetime(2022, 12, 28, 17, 8, 3)}]
查询所有(还没试)
# 获取查询集
queryset = MyModel.objects.all()
# 将查询集转换为列表
list_of_dicts = list(queryset.values())后计:
批量插入多条bulk_create
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "mysite.settings")
def main():
from blog.models import Blog
f = open('oldblog.txt')
BlogList = []
for line in f:
title,content = line.split('****')
blog = Blog(title=title,content=content)
BlogList.append(blog)
f.close()
Blog.objects.bulk_create(BlogList)
if __name__ == "__main__":
main()
print('Done!')参考: https://www.cnblogs.com/jiumo/p/12240831.html
另外一只用 ** 不用指定插入字段
queryset_list = [] # 创建列表,用与承载批量更新的对象数据
for goods_data in goods_list: # 用for循环遍历需要创建的数据列表,注:这里默认为列表内元素goods_data 是字典格式
queryset_list.append(MyModel(**goods_data)) # 把创建元素添加到列表
MyModel.objects.bulk_create(queryset_list) # 批量创建
参考:https://blog.csdn.net/wuwei_201/article/details/127935064
插入数据后获取他的主键id
index2=tbl_project_inform.objects.create(
group_ids= str(group_ids)
)
print(66666,index2.id)排序
aa=CdnToken.objects.all().order_by("-id")
获取前端参数经过序列化器 额外传入字符的方法
#当序列化的时候 加上 context={}
视图类
def post(self, request, *args, **kwargs):
depart_id = request.data.get('depart_id')
environment = request.data.get('environment')
obj = tbl_project_category.objects.filter(is_deleted=False)
objs = WeekApiSerializers(obj, many=True, context={'request': environment})
return APIRespones(1000, 'OK', results=objs.data)
#在序列化器中可以使用 self.context['request'] 获取视图类中传入的 request参数
序列化类
# 统计本周数据
class WeekApiSerializers(serializers.ModelSerializer):
class Meta:
model = tbl_project_category
fields = ('id', 'pro_name', 'case_total')
case_total = serializers.SerializerMethodField() #本周新增用例
def get_case_total(self, obj):
environment = self.context['request']
groupids = tbl_group_case.objects.filter(project_id__exact=obj.id, is_deleted=False,
environment=environment).values('id').all()
return len(api_total)
类似limit的方法
a=uc_checklist.objects.filter(iterations_id=iterId).order_by("-id")[0:1] 左闭右开
数据库字段很大的话 用 TextField
send_email = models.TextField(validators=[int_list_validator], default=[], verbose_name='关联用户ID')(模型字段类型可以参考)
https://www.cnblogs.com/chenxdnote/p/17223102.html
分组且统计
results=Gitlab_commit_Log.objects.filter(commit_time__range=(be,en)).values('author_email').annotate(sum=Sum('total'))
xxxx__range 为between >=和<=
.values('author_email').annotate(sum=Sum('total')) 为 select author_email,sum('total') from xx groupb by author_email
from django.db.models import Max
aa=uc_report.objects.filter(iterations_id__in=(905,891)).values('iterations_id').annotate(id=Max("id"))
分组且id取最大的
使用原生sql语句的方法
from django.db import connection
with connection.cursor() as cursor:
cursor.execute("select * from table")
results = cursor.fetchall()
=result = [{'author_email': author_email, 'additions': int(addition)} for author_email, addition in list(results)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号