
Datawhale AI 夏令营:电力需求预测挑战赛笔记 #AI夏令营 #Datawhale #夏令营 #Datawhale AI 夏令营
tag: #AI夏令营 #Datawhale #夏令营 #Datawhale AI 夏令营
Datawhale AI 夏令营:电力需求预测挑战赛
举办方:科大讯飞xDatawhale
一、赛题背景
随着全球经济的快速发展和城市化进程的加速,电力系统面临着越来越大的挑战。电力需求的准确预测对于电网的稳定运行、能源的有效管理以及可再生能源的整合至关重要。
然而,电力需求受到多种因素的影响,为了提高电力需求预测的准确性和可靠性,推动智能电网和可持续能源系统的发展,本场以“电力需求预测”为赛题的数据算法挑战赛。选手需要根据历史数据构建有效的模型,能够准确的预测未来电力需求。
二、赛题任务
给定多个房屋对应电力消耗历史N天的相关序列数据等信息,预测房屋对应电力的消耗。
三、评审规则
1.数据说明
赛题数据由训练集和测试集组成,为了保证比赛的公平性,将每日日期进行脱敏,用1-N进行标识,即1为数据集最近一天,其中1-10为测试集数据。数据集由字段id(房屋id)、 dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。
特征字段 字段描述
id 房屋id
dt 日标识
type 房屋类型
target 实际电力消耗,预测目标
2.评审规则
预测结果以 mean square error 作为评判标准。
3.评测及排行
1)每支团队每天最多提交3次。
2)赛事提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
3)排行按照得分从低到高排序,排行榜将选择团队的历史最优成绩进行排名。
4)允许使用开源模型,但不允许使用外部数据集。
四、作品提交
1.文件格式:预测结果文件按照.csv格式提交
2.文件大小:无要求
3.提交次数:每支队伍每天最多3次
4.预测结果文件详细说明:
1)以csv格式提交,编码为UTF-8,第一行为表头;
2)提交前请确保预测结果的格式与sample_submit.csv中的格式一致。具体格式如下:
1 id,dt,target
2 00037f39cf,1,0
3 00037f39cf,2,0
4 00037f39cf,3,0
5 ...
赛题任务及研究目的:训练时序预测模型助力电力需求预测。电力需求的准确预测对于电网的稳定运行、能源的有效管理以及可再生能源的整合至关重要。
“Hello world”代码:
1. 导入需要用到的相关库
导入 pandas 库,用于数据处理和分析
import pandas as pd
导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
2. 读取训练集和测试集
使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train = pd.read_csv('train.csv')
使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test = pd.read_csv('test.csv')
3. 计算训练数据最近11-20单位时间内对应id的目标均值
target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()
4. 将target_mean作为测试集结果进行合并
test = test.merge(target_mean, on=['id'], how='left')
5. 保存结果文件到本地
test[['id','dt','target']].to_csv('submit.csv', index=None)
以上Pandas 和 NumPy 是 Python 编程语言 中两个非常重要的库,它们封装了很多函数功能,广泛应用于数据分析和科学计算领域,为我们的代码开发实现提供了便利。
-
Pandas 是基于 NumPy 的一个数据分析和操作库,提供了快速、灵活和表达力强的数据结构,旨在使数据清洗和分析工作变得更加简单易行。
-
NumPy 提供了多维数组对象、派生对象(如掩码数组和矩阵)以及用于快速操作数组的各种例程,包括数学、逻辑、形状操作、排序、选择、I/O、离散傅立叶变换、基本线性代数、基本统计运算、随机模拟等等。
Pandas 和 NumPy 通常一起使用,因为 Pandas 的设计初衷就是为了与 NumPy 无缝集成,利用 NumPy 的数组结构来提高性能。
以上baseline使用python代码构建了一个经验模型(使用均值作为结果数据)。主要通过了如下几个步骤对数据进行处理:
-
导入库:首先,代码导入了需要用到的库,包括
pandas(用于数据处理和分析)。 -
读取数据:代码通过使用
pd.read_csv函数从文件中读取训练集和测试集数据,并将其存储在train.csv和test.csv两个数据框中。 -
计算最近时间的用电均值:计算训练数据最近11-20单位时间内对应id的目标均值,可以用来反映最近的用电情况。
-
将用电均值直接作为预测结果:这里使用
merge函数根据'id'列将test和target_mean两个DataFrame进行左连接,这意味着测试集的所有行都会保留。 -
保存结果文件到本地:使用
to_csv()函数将测试集的'id'、'dt'和'target'列保存为CSV文件,文件名为'submit.csv'。index=None参数表示在保存时不包含行索引。
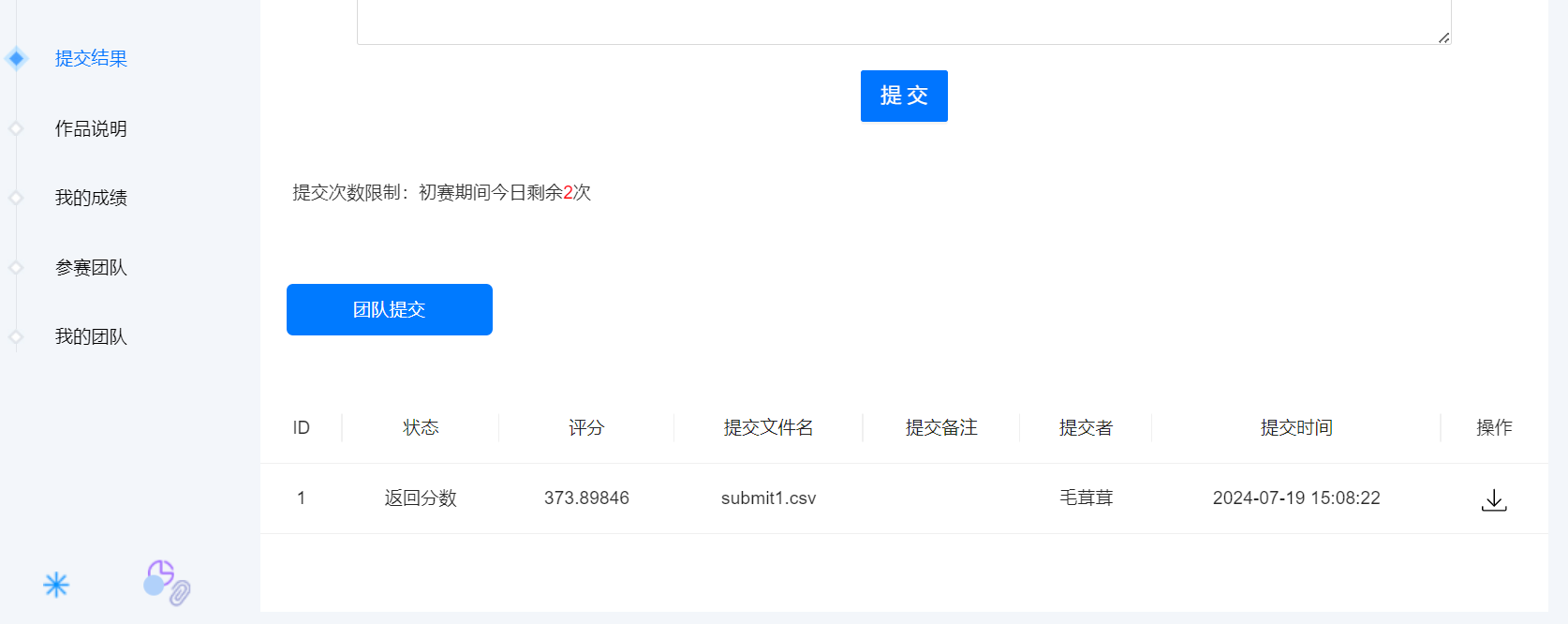
结果截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号