
论文:> https://arxiv.org/abs/2110.04627 >
参考代码:> https://github.com/thuanz123/enhancing-transformers >
原理部分参考:> https://zhuanlan.zhihu.com/p/611689477 > > https://zhuanlan.zhihu.com/p/1937234761945949010 > > https://juejin.cn/post/7416899377878630427 >
一、ViT-VQGAN简介
ViT-VQGAN的框架从现在来看已然比较泛用,但实际情况下常常因为开销较大,人们更倾向于使用。框架上来看,ViT最大的改动就在于对encoder和decoder创新性地使用了transformer做feature extraction和相应的loss的修改。
ViT-VQGAN的主要贡献如下:
1.stage1(image quantization ViT-VQGAN):
基于ViT的VQGAN encoder。基于VQGAN做了从架构到码本学习方式的多种改进——>提升了efficiency和reconstruction fidelity.
包括logits-laplace loss,L2 loss,adversarial loss 和 perceptual loss.
2.stage2(vector-quantized image modeling VIM):
学习了一个自回归的transformer,包括无条件生成/类条件生成/无监督表示学习。
为了评估无监督学习质量,对中间transformer特征进行平均,学习一个linear head(linear-probe)来预测类的logits。
ViT-VQGAN的方法框架图如下所示。
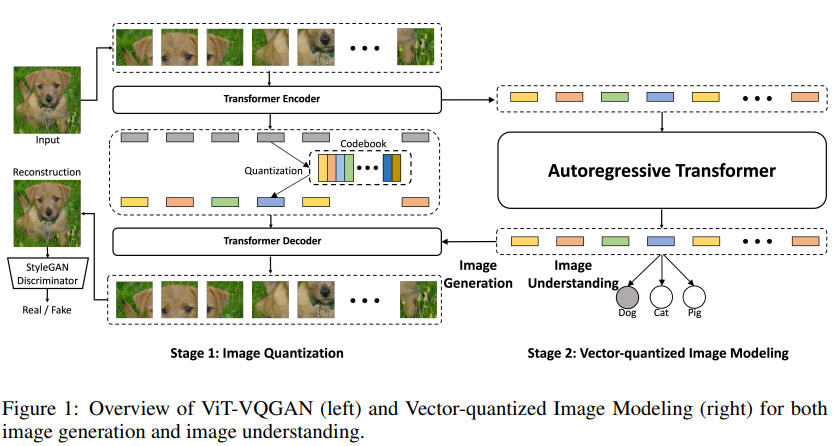
我们展开来看:
Stage 1 VQGAN with Vision Transformers
将VQGAN中的CNN部分,即encoder和decoder替换为ViT。VQVAE和VQGAN核心网络架构为CNN,VQGAN以non-local attention的形式引入了transformer元素,使其能够以较少的层捕获远距离交互。
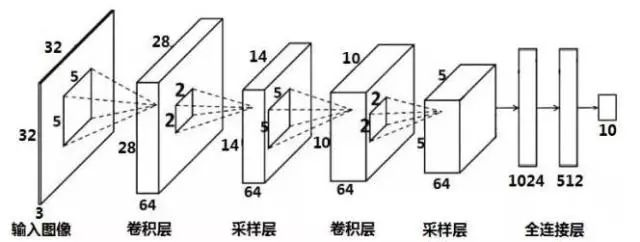
首先重新了解一下CNN,也就是卷积神经网络。CNN的设计基于以下几个关键观察:
局部性:图像中相邻像素关系更紧密。
平移不变性:同一个物体无论出现在图像哪个位置,都应该被识别为同一类。
层次化特征提取:从低级特征(边缘、角点)到高级特征(人脸、汽车)逐层抽象。
但同时对图像的这些“先验知识”(也叫做归纳偏置,inductive bias)也顺势束缚了一些模型能力:
长距离依赖建模需深层堆叠或复杂设计(如空洞卷积、ASPP),效率较低。
计算模式不规则,不利于现代加速器(GPU/TPU)的极致并行化。CNN的卷积操作涉及复杂的局部相关性计算,需要结合空间局部性和平移等变性原则。这种特性导致计算流程呈现非规则性,例如特征图的梯度计算依赖于特定卷积核的排列方式,难以通过简单的矩阵运算实现完全并行化。
不难看出,CNN的架构扩展性受限,难以像Transformer那样通过简单堆叠实现性能持续提升。
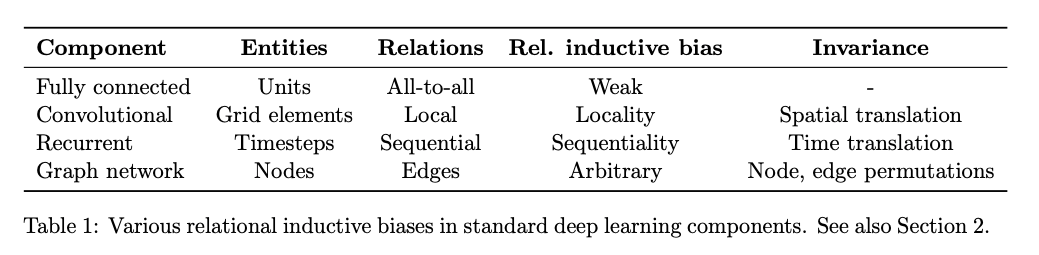
下图给出了机器学习中主要的神经网络结构背后的inductive bias是什么。可以看到,全连接网络的inductive bias是最轻微的,它就是假设所有的单元都可能会有联系;卷积则是假设数据的特征具有局部性和平移不变性,循环神经网络则是假设数据具有序列相关性和时序不变性,而图神经网络则是假设节点的特征的聚合方式是一致的。总之,网络的结构本身就包含了设计者的假设和偏好,这就是归纳偏置。
为了解决这个问题,有一些对CNN设计的改进来降低这种偏置的影响:
1.卷积神经网络和自注意力混合,例如CNN提取特征图之后,在特征图上进行计算自注意力。
2.全用自注意力 stand-alone self-attention 对图像中的窗口做自注意力,也是像CNN一样一块一块取。
但这些不仅增加了CNN的结构复杂度,也不利于进一步对整体进行优化。
Transformer在NLP中展现出惊人潜力,最重要的一点就是性能随模型规模和数据量持续提升(无明显饱和),另外还有计算高度并行化,适合 GPU/TPU 大规模训练;架构简洁统一,易于扩展和迁移等特点,因此不难想到Transformer在CV上的转移应用。
为了成功应用,需要考虑Transformer的几个问题:
一、Transformer中的自注意力计算复杂度为 \(O(N^2)\),不能直接进行像素级细节的建模。但这一点我们可以参考原本在NLP中token的处理方式,不是对句子中的每一个字划分为单一token,而是先进行分词做embedding,然后再输入进去。对于图像来说,一个容易想到的方法就是对图像切块成多个patch,这样1个patch就是1个token,就能套用NLP的范式。但这不意味着就能完美解决计算复杂度这一根本问题,笔者在做ViT的复现时注意到,在图像方面之前使用Transformer的工作大都还是停留在256这一尺度上,这一特殊性主要是由patch_size=16决定的,每个patch都要和其他所有patch计算注意力得到全局自注意力,这个量在256上就已经是\(1024^2\)。因此还是需要对Transformer本身动刀。
(1)分层结构:如Swin Transformer使用滑动窗口机制,在局部窗口内计算注意力,降低全局计算量。简单来说就是对总体patch再分patch(即window),那么这就要对自注意力头进行改造,让他在窗口内计算patch之间的自注意力,再通过滑动窗口的方式弥补窗口之间的自注意力互动。这个方法将计算复杂度从\(O(L^2)\)降低到了\(O(L)\)。另外有一个技巧就是借助了CNN的分层提取特征的结构,对四种分辨率尺度下的输入分别应用Swin Block去提取特征;
(2)稀疏注意力(Sparse Attention):只关注局部邻域或固定位置(如 axial attention,其原理在于分别在行和列方向上进行注意力而非对整体做注意力,这样同样将复杂度降低为O(L))具体的一些方法参考原文> https://arxiv.org/pdf/1904.10509 > ,这里不做展开;
(3)线性注意力 / 高效注意力(Efficient Attention):使用数学近似将\(O(L^2)\)降为\(O(L)\),如 Linformer(对注意力矩阵用低秩投影逼近)、Performer(随机傅里叶特征映射)。(FlashAttention是对注意力在GPU上的运算做了分配优化提高了计算效率,只能算作)
二、原始的ViT只能进行相对固定分辨率的特征输出,无法支持目标检测、语义分割等密集预测任务(需要多尺度特征图)。因此像Swin Transformer就去考虑了下采样+多尺度特征的这种方式来做文章,还有一些方法如PVT、T2T-ViT也是类似参考了这种缩短token序列长度的思想。
在解决了第一个问题之后,ViT便横空出世。尽管效果上看相当出色,但论文的实验结果上是有一个需要关注的点的,即在小数据集上,ViT < ResNet:
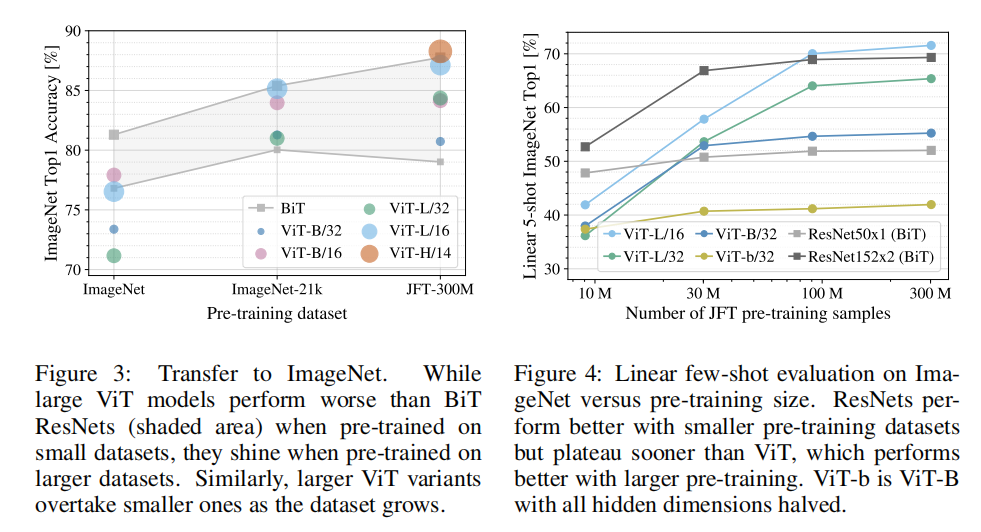
上图是数据集大小(左)与模型内在效果(右)的对比效果。灰色部分是BiT网络(基于ResNet)的效果范围,最底下是ResNet50,顶上是ResNet152。
可以看到使用ImageNet数据集时候,ViT的效果是比不上BiT的,随着数据集增大到ImageNet-21k,ViT的表现已经在BiT表现的范围之内了。而继续增大数据集到JFT-300M,ViT可以实现对BiT的效果碾压。所以如果想训练一个好用的ViT,你至少要保证数据集的大小能达到ImageNet-21k,不然是不如同类型CNN的模型的。
因为训练过程中用了dropout.weight decay、label smoothing等。为了证明不是因为这些策略,而是Transformer本身的效果就很好,作者在不同规模的JFT-300M的子集上进行训练,对模型用ImageNet做5-shot,用这些模型特征抽取之后做Logistics Regression。结果也可以看出训练集很小的时候,ViT效果是不如ResNet的,但是随着模型增大,ViT的表现逐渐超越ResNet,这证明了基于Transformer的模型效果确实就是好。另外作者也认为训练好的ViT更适合小样本任务。
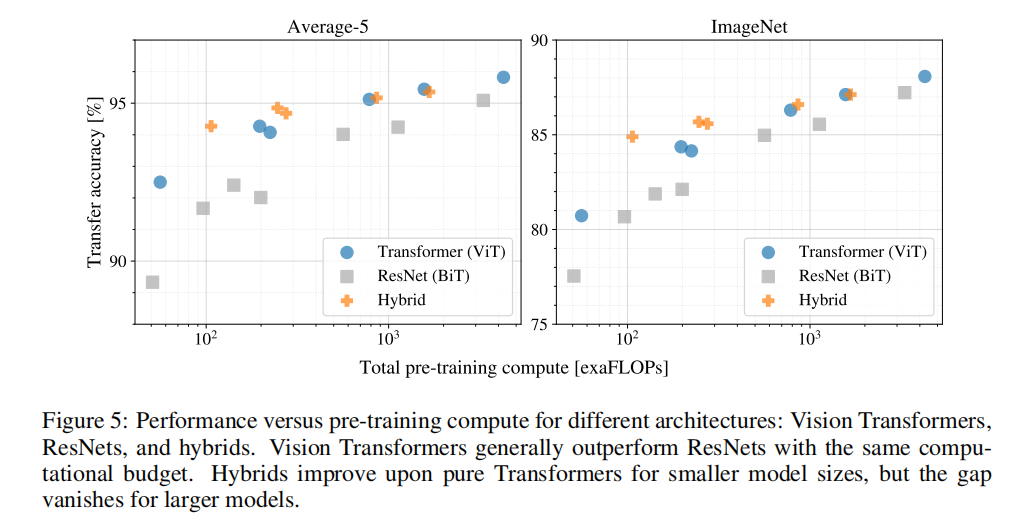
上图是算力指标的对比效果。左侧是五个数据集都测试然后取平均值,右侧是只拿ImageNet测试。数据集都是在JFT-300M上训练的。可以看到在同样的计算复杂度下,Transformer的表现都优于ResNet,所以证明了训练ViT是真的经济实惠好用。有趣的是混合模型,也就是橙色的点,用CNN特征图作为Transformer输入的部分。可以看到计算复杂度低的时候,混合模型的效果是最好的,但是随着计算复杂度增加,混合模型逐渐和ViT持平。
这里的原因就回到了之前的疑问。ViT的归纳偏置是什么呢?
其实我们在介绍ViT的引入问题时就介绍过。如果说ViT相比于卷积,在图像任务上没有显著优势,那大概率就是指ViT对这两种先验的维护没有CNN做的好,来看ViT的模型结构:
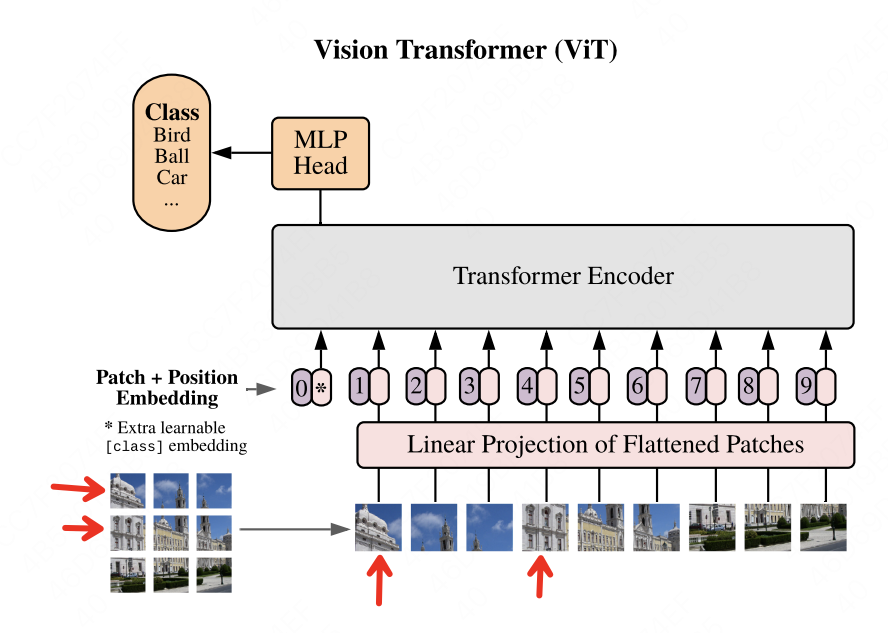
图中箭头所指的两部分都属于同一栋建筑。在卷积中,我们可以用大小适当的卷积核将它们圈在一起。但是在ViT中,它们之间的位置却拉远了,如果我把patch再切分细一些,它们的距离就更远了。虽然attention可以学习到向量间的关系,但是ViT在空间局部性的维护上,确实没有卷积做的好。而在平移等边性上,由于ViT需要对patch的位置进行学习,所以对于一个patch,当它位置变换时,它的输出结果也是不一样的。所以,ViT的架构没有很好维护图像问题中的归纳偏置假设。
但是,Transformer架构的模型与实验已经告诉我们:大力出奇迹。只要它见过的数据够多,它就能更好地学习像素块之间的关联性,当然也能抹去归纳偏置的问题。
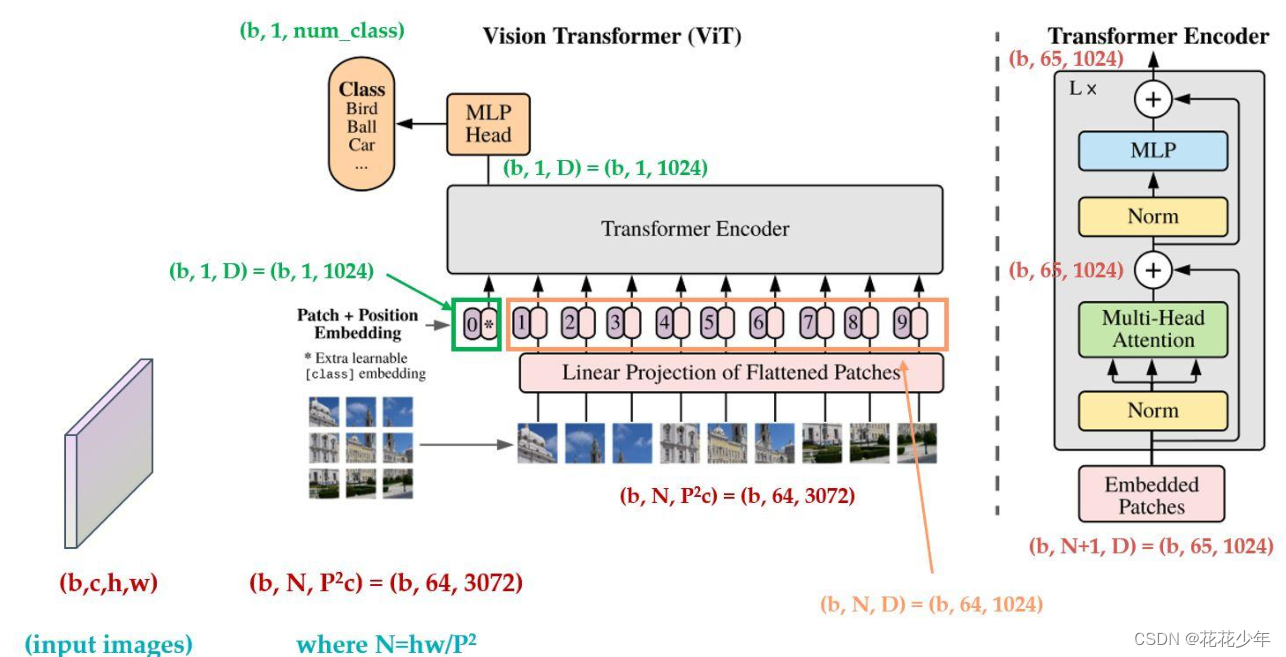
深入了结构许多,至少我们弄清楚了Transformer替换CNN是有迹可循的。因此,我们先过一遍ViT的数据流(图片参考ViT的模型结构):
step1:224×224×3的图像输入,按Batch走就是[B,224,224,3],分成了14×14个patch,即一个patch是16×16×3,那么embedding的大小就是768。通过FC层将其展开成一个序列,长度就是14×14=196,即拉伸为[B,196,768]。
step2:分隔开的patches是有顺序的,所以跟NLP中一样为其添加位置编码position embedding。位置编码pos_emb∈\(R^{1×768}\),与特征x相连(concat)后得到[B,197,768]。同时和BERT一样,添加extra learnable embedding,也就是
step3:进入第一个 Transformer Block。每个 Transformer Block 包含两个子模块:Multi-Head Self-Attention(MSA)和MLP(前馈网络),并使用 Pre-LN 结构(即LayerNorm + MSA + LayerNorm + MLP),最终输出[B, 197, 768]。纵深这样的流程到最后一个Transformer Block,最后分类输出[B,1000]。至此前向传播的流程结束。
step4:反向传播使用的是交叉熵损失 loss = F.cross_entropy(logits, labels)。logits就是MLP-head得到的分类输出。
这里还有一张数据流图片可供参考:
那么以VQGAN为范式,ViT-VQGAN的Stage1图像编码与量化过程的数据流如下:
step1.224×224×3的图像输入被分割为16×16大小的patches,形成14×14=196个图像块,每个图像块被展平为向量并通过线性投影层转换为768维嵌入向量。
step2.将196个patch嵌入向量与可学习的位置编码相加,将这些嵌入输入到多层Vision Transformer编码器中处理,Transformer编码器通过自注意力机制捕获全局依赖关系,输出相同数量的特征向量[B,196,768]
step3.将Transformer输出的特征向量通过一个投影层映射到与码本维度匹配的空间,如果码本也是768的维度,则仍然是[B,196,768],否则就经过一个池化层或是插值卷积层。使用码本大小为8192的向量量化操作(码本大小延续了VQ-VAE的设定)。对每个特征向量,计算其与码本中所有向量的欧氏距离,选择最近的码字索引,量化过程可表示为:\(z_{q(x)} = e_q(argmin_j ||z(x)-e_j||_2)\),其中\(e_j\)是码本向量,通过码本生成768维的离散整数网格,总共有196个离散标记,即[B,196]。
step4.将量化的向量\(z_{q(x)}\)通过解码器(通常是转置卷积网络)重建为原始图像尺寸。解码器将离散表示转换回224×224的RGB图像。训练目标包括:像素级重建损失、感知损失、码本损失和对抗损失。通过对抗训练提高重建图像的视觉质量。[B,196]->[B,196,768]->[B,196,768]->[B,224,224,3]
其中,Step2没有使用CLS是因为Stage1的目标在于重构提取空间结构化的latent表示,这种分类头的训练是没有必要的。
特别地,我们来看一下VQGAN中的重要部分VQ的代码实现:
BaseQuantize是一个通用的向量量化模块基类,它所继承的父类nn.Module是 PyTorch 深度学习框架中最核心、最基础的类之一,它是所有神经网络模块(layers)、模型(models)和可学习组件的基类,通常是用来进行这些基础部分定义的地方。主要用来支持以下特性:1.向量量化:使用 nearest neighbor 查找码本中最匹配的向量;2.归一化:支持 L2 归一化(适用于球面码本);3.直通估计:允许梯度流过不可导的量化操作;4.残差量化:多级量化,提高表达能力(如 RVQ)5:可扩展:子类需实现quantize()方法(如普通 VQ、Gumbel VQ、RQ 等)
点击查看VQ-BaseQuantize代码
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from Taming Transformers (https://github.com/CompVis/taming-transformers)
# Copyright (c) 2020 Patrick Esser and Robin Rombach and Björn Ommer. All Rights Reserved.
# ------------------------------------------------------------------------------------
import math
from functools import partial
from typing import Tuple, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
class BaseQuantizer(nn.Module):
def __init__(self, embed_dim: int, n_embed: int, straight_through: bool = True, use_norm: bool = True,
use_residual: bool = False, num_quantizers: Optional[int] = None) -> None:
# embed_dim: 每个嵌入向量的维度(即特征大小)。
# n_embed: 嵌入码本(codebook)中向量的数量(即“词典”大小)。
# straight_through: 是否使用直通估计(Straight-Through Estimator),用于在反向传播时保留梯度。
# use_norm: 是否对输入和嵌入进行 L2 归一化(常见于 RQ 或 VQ-VAE 中)。
# use_residual: 是否使用残差量化(如 Residual Vector Quantization, RVQ)。
# num_quantizers: 如果使用残差量化,表示要堆叠多少层量化器。
super().__init__()
self.straight_through = straight_through
self.norm = lambda x: F.normalize(x, dim=-1) if use_norm else x
# norm: 一个可调用函数,根据 use_norm 决定是否对张量做 L2 归一化(沿最后一个维度)。这有助于稳定训练,特别是在使用余弦相似度时。
self.use_residual = use_residual
self.num_quantizers = num_quantizers
self.embed_dim = embed_dim
self.n_embed = n_embed
self.embedding = nn.Embedding(self.n_embed, self.embed_dim)
self.embedding.weight.data.normal_()
# 初始化码本权重为标准正态分布(N(0,1))。实际应用中有时也会用均匀初始化或 Xavier 初始化。
# 这是一个抽象方法(虽然没用 abc 模块强制),子类必须实现它。它的作用是:输入连续向量 z,找到最接近的码本向量(最近邻)。返回:z_q: 量化后的向量(从码本中查表得到),loss: 量化损失(例如 commitment loss),encoding_indices: 最近邻码本向量的索引(整数)
def quantize(self, z: torch.FloatTensor) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.LongTensor]:
pass
def forward(self, z: torch.FloatTensor) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.LongTensor]:
if not self.use_residual:
z_q, loss, encoding_indices = self.quantize(z)
else:
# 残差量化(RVQ)。目标:逐步逼近原始输入
z_q = torch.zeros_like(z)
residual = z.detach().clone()
losses = []
encoding_indices = []
for _ in range(self.num_quantizers):
z_qi, loss, indices = self.quantize(residual.clone())
residual.sub_(z_qi)
z_q.add_(z_qi)
encoding_indices.append(indices)
losses.append(loss)
losses, encoding_indices = map(partial(torch.stack, dim = -1), (losses, encoding_indices)) # 把每轮的 loss 和 indices 在最后一维堆叠起来,变成 shape 为 [B, ..., num_quantizers] 的张量。
loss = losses.mean()
# preserve gradients with straight-through estimator,让网络可以训练,尽管中间有非可导的 argmin/nearest neighbor 操作。
if self.straight_through:
z_q = z + (z_q - z).detach()
return z_q, loss, encoding_indices
VectorQuantize主要定义了VQ的具体quantize方法。
特别地,其中的距离矩阵公式为\(\| \mathbf{z}_i - \mathbf{e}_j \|^2 = \| \mathbf{z}_i \|^2 + \| \mathbf{e}_j \|^2 - 2 \mathbf{z}_i^\top \mathbf{e}_j\),其中torch.einsum('bd, nd -> bn') → \(z_i^⊤e_j\) 这个einsum方法通过对矩阵z_reshaped_norm, embedding_norm分别规定两个方向的定义,即z_reshaped_norm -> [b,d] , embedding_norm -> [n,d], 并进行归一化展平,即B个归一化的输入向量(展平后),记作\(z_i∈R^D\);令一个类似记作\(e_j∈R^D\)。'-> b n'表示输出只保留 b 和 n 维度,d 维度被“收缩”,即沿着 d 求和。 这也就是说,该方法等价于实现了两个向量的点积,类似的方法可以用>similarity = torch.matmul(z_reshaped_norm, embedding_norm.t()) # [B, D] @ [D, N] -> [B, N] 或 similarity = z_reshaped_norm @ embedding_norm.t(),einsum 的优势在于:更直观表达“哪些维度参与运算”且易于扩展到高维或复杂操作(如注意力机制中的 b h q d, b h k d -> b h q k)。最终得到一个 (BHW, n_embed) 的距离矩阵 \(d[i,j] = dist(z_i, e_j)\)。这种方式避免了显式循环,完全向量化,效率高。
点击查看VectorQuantize代码
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from Taming Transformers (https://github.com/CompVis/taming-transformers)
# Copyright (c) 2020 Patrick Esser and Robin Rombach and Björn Ommer. All Rights Reserved.
# ------------------------------------------------------------------------------------
class VectorQuantizer(BaseQuantizer):
def __init__(self, embed_dim: int, n_embed: int, beta: float = 0.25, use_norm: bool = True,
use_residual: bool = False, num_quantizers: Optional[int] = None, **kwargs) -> None:
# beta: 权衡“码本损失”与“承诺损失”的超参数(常见于 VQ-VAE),**kwargs: 允许接收额外参数(可能用于兼容未来扩展)
# 调用父类构造函数,并固定 straight_through=True(总是使用直通估计)。
super().__init__(embed_dim, n_embed, True,
use_norm, use_residual, num_quantizers)
self.beta = beta
def quantize(self, z: torch.FloatTensor) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.LongTensor]:
# 第一步:展平 + 归一化, 把多维输入压平成二维:(batch_size * height * width, embed_dim),方便批量计算距离。当使用余弦相似度或内积作为匹配准则时,L2 归一化可以让比较更关注方向而非模长,提升稳定性。
z_reshaped_norm = self.norm(z.view(-1, self.embed_dim))
embedding_norm = self.norm(self.embedding.weight)
# 第二步:计算距离矩阵:
d = torch.sum(z_reshaped_norm ** 2, dim=1, keepdim=True) + \
torch.sum(embedding_norm ** 2, dim=1) - 2 * \
torch.einsum('b d, n d -> b n', z_reshaped_norm, embedding_norm)
# 第三步:查找最近邻(编码索引),.unsqueeze(1)用于在指定维度插入一个大小为 1 的新维度,主要是强调这是一个“索引序列”,而非标量集合,有一种说法是以便批处理多个码本(如 RVQ),即使当前只用一个。
encoding_indices = torch.argmin(d, dim=1).unsqueeze(1)
encoding_indices = encoding_indices.view(*z.shape[:-1])
z_q = self.embedding(encoding_indices).view(z.shape)
z_qnorm, z_norm = self.norm(z_q), self.norm(z)
# compute loss for embedding , 对偶学习机制:编码器学会选择合适的码字,码本学会更好表达这些码字
loss = self.beta * torch.mean((z_qnorm.detach() - z_norm)**2) + \
torch.mean((z_qnorm - z_norm.detach())**2)
return z_qnorm, loss, encoding_indices
GumbelQuantizer是一个基于 Gumbel-Softmax 技术的可微向量量化器,用于在训练时允许梯度流过离散选择过程。不需要直通估计,而是通过“软分布 + 可微采样”实现可导。
点击查看GumbelQuantizer代码
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from Taming Transformers (https://github.com/CompVis/taming-transformers)
# Copyright (c) 2020 Patrick Esser and Robin Rombach and Björn Ommer. All Rights Reserved.
# ------------------------------------------------------------------------------------
class GumbelQuantizer(BaseQuantizer):
def __init__(self, embed_dim: int, n_embed: int, temp_init: float = 1.0,
use_norm: bool = True, use_residual: bool = False, num_quantizers: Optional[int] = None, **kwargs) -> None:
super().__init__(embed_dim, n_embed, False,
use_norm, use_residual, num_quantizers)
# 保存初始温度。温度越高 → 输出越接近均匀分布;温度越低 → 越接近 one-hot(趋近于 argmax)。
self.temperature = temp_init
def quantize(self, z: torch.FloatTensor, temp: Optional[float] = None) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.LongTensor]:
# force hard = True when we are in eval mode, as we must quantize
# hard:训练时:hard=False → 使用 soft 分布(可导),推理/验证时:hard=True → 使用 hard one-hot(真正离散化)
hard = not self.training
# 训练初期用高温度(更随机),后期降低温度 → 更确定性地选择码字。
temp = self.temperature if temp is None else temp
z_reshaped_norm = self.norm(z.view(-1, self.embed_dim))
embedding_norm = self.norm(self.embedding.weight)
# logits是负距离,最终得到一个 shape 为 (N, n_embed) 的 logits 矩阵,每一行是每个位置上各码字的匹配分数。
logits = - torch.sum(z_reshaped_norm ** 2, dim=1, keepdim=True) - \
torch.sum(embedding_norm ** 2, dim=1) + 2 * \
torch.einsum('b d, n d -> b n', z_reshaped_norm, embedding_norm)
logits = logits.view(*z.shape[:-1], -1)
# 核心步骤:生成一个“近似 one-hot”的分布向量,使得我们可以:在 forward 中做出类似“选择某个码字”的行为、在 backward 中让梯度穿过这个“选择”操作
# 当 hard=True 时,其实就是选中了一个码本向量。即使 hard=True,PyTorch 的 gumbel_softmax 也会保持梯度连续性(模拟 STE 行为)
soft_one_hot = F.gumbel_softmax(logits, tau=temp, dim=-1, hard=hard)
z_qnorm = torch.matmul(soft_one_hot, embedding_norm) #加权求和得到量化向量
# kl divergence to the prior loss 均匀先验下的KL散度,损失只影响码本和编码器,不涉及解码器部分。
logits = F.log_softmax(logits, dim=-1) # use log_softmax because it is more numerically stable
loss = torch.sum(logits.exp() * (logits+math.log(self.n_embed)), dim=-1).mean()
# get encoding via argmax,返回每个位置上得分最高的码本索引
encoding_indices = soft_one_hot.argmax(dim=-1)
return z_qnorm, loss, encoding_indices
该部分具体展示了前向传播的框架搭建,主要需要理解2D和1D位置编码、Transformer的实现路径,以及Encoder-Decoder的具体架构
点击查看layers部分代码
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from Taming Transformers (https://github.com/CompVis/taming-transformers)
# Copyright (c) 2020 Patrick Esser and Robin Rombach and Björn Ommer. All Rights Reserved.
# ------------------------------------------------------------------------------------
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from ViT-Pytorch (https://github.com/lucidrains/vit-pytorch)
# Copyright (c) 2020 Phil Wang. All Rights Reserved.
# ------------------------------------------------------------------------------------
import math
import numpy as np
from typing import Union, Tuple, List
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
def get_2d_sincos_pos_embed(embed_dim, grid_size):
"""
grid_size: int or (int, int) of the grid height and width
return:
pos_embed: [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
"""
grid_size = (grid_size, grid_size) if type(grid_size) != tuple else grid_size
grid_h = np.arange(grid_size[0], dtype=np.float32)
grid_w = np.arange(grid_size[1], dtype=np.float32)
grid = np.meshgrid(grid_w, grid_h) # here w goes first
grid = np.stack(grid, axis=0)
grid = grid.reshape([2, 1, grid_size[0], grid_size[1]])
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
return pos_embed
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
assert embed_dim % 2 == 0
# use half of dimensions to encode grid_h
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
return emb
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
"""
embed_dim: output dimension for each position
pos: a list of positions to be encoded: size (M,)
out: (M, D)
"""
assert embed_dim % 2 == 0
omega = np.arange(embed_dim // 2, dtype=np.float)
omega /= embed_dim / 2.
omega = 1. / 10000**omega # (D/2,)
pos = pos.reshape(-1) # (M,)
out = np.einsum('m,d->md', pos, omega) # (M, D/2), outer product
emb_sin = np.sin(out) # (M, D/2)
emb_cos = np.cos(out) # (M, D/2)
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
return emb
def init_weights(m):
if isinstance(m, nn.Linear):
# we use xavier_uniform following official JAX ViT:
torch.nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
w = m.weight.data
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
class PreNorm(nn.Module):
def __init__(self, dim: int, fn: nn.Module) -> None:
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x: torch.FloatTensor, **kwargs) -> torch.FloatTensor:
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim: int, hidden_dim: int) -> None:
super().__init__()
# 值得注意的是,除了Tanh这一能保持在[-1,1]的连续值输出的激活函数以外,还有GeLU、ReLU、Swish(SiLU)等可作替换,其中ReLU存在死亡神经元的问题,需要谨慎使用
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, dim)
)
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim: int, heads: int = 8, dim_head: int = 64) -> None:
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5 # 缩放因子,防止点积过大导致 softmax 梯度消失
self.attend = nn.Softmax(dim = -1) # 对最后一个维度(即 key 维度)做 softmax,得到注意力权重(概率分布)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Linear(inner_dim, dim) if project_out else nn.Identity() #nn.Identity()表示恒等映射
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
qkv = self.to_qkv(x).chunk(3, dim = -1) # .chunk(3, dim=-1) 沿最后一维切成三块:大小均为[B, N, inner_dim],返回一个元组 (q, k, v)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv) #q.shape = [B, heads, N, dim_head]
attn = torch.matmul(q, k.transpose(-1, -2)) * self.scale #q @ k^T /sqrt(dim_head)
attn = self.attend(attn)
out = torch.matmul(attn, v) # 每个位置的输出是 value 的加权平均,权重来自 attention 分布
out = rearrange(out, 'b h n d -> b n (h d)') # 将多头结果重新拼接回单一向量
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim: int, depth: int, heads: int, dim_head: int, mlp_dim: int) -> None:
super().__init__()
self.layers = nn.ModuleList([])
for idx in range(depth):
layer = nn.ModuleList([PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head)),
PreNorm(dim, FeedForward(dim, mlp_dim))])
self.layers.append(layer)
self.norm = nn.LayerNorm(dim)
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
for attn, ff in self.layers: # 从layer封装中取出Attention与FeedForward
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
class ViTEncoder(nn.Module):
def __init__(self, image_size: Union[Tuple[int, int], int], patch_size: Union[Tuple[int, int], int],
dim: int, depth: int, heads: int, mlp_dim: int, channels: int = 3, dim_head: int = 64) -> None:
super().__init__()
image_height, image_width = image_size if isinstance(image_size, tuple) \
else (image_size, image_size)
patch_height, patch_width = patch_size if isinstance(patch_size, tuple) \
else (patch_size, patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
en_pos_embedding = get_2d_sincos_pos_embed(dim, (image_height // patch_height, image_width // patch_width))
self.num_patches = (image_height // patch_height) * (image_width // patch_width)
self.patch_dim = channels * patch_height * patch_width
self.to_patch_embedding = nn.Sequential(
nn.Conv2d(channels, dim, kernel_size=patch_size, stride=patch_size),
Rearrange('b c h w -> b (h w) c'),
)
self.en_pos_embedding = nn.Parameter(torch.from_numpy(en_pos_embedding).float().unsqueeze(0), requires_grad=False)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim)
self.apply(init_weights)
def forward(self, img: torch.FloatTensor) -> torch.FloatTensor:
x = self.to_patch_embedding(img)
x = x + self.en_pos_embedding
x = self.transformer(x)
return x
class ViTDecoder(nn.Module):
def __init__(self, image_size: Union[Tuple[int, int], int], patch_size: Union[Tuple[int, int], int],
dim: int, depth: int, heads: int, mlp_dim: int, channels: int = 3, dim_head: int = 64) -> None:
super().__init__()
image_height, image_width = image_size if isinstance(image_size, tuple) \
else (image_size, image_size)
patch_height, patch_width = patch_size if isinstance(patch_size, tuple) \
else (patch_size, patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
de_pos_embedding = get_2d_sincos_pos_embed(dim, (image_height // patch_height, image_width // patch_width))
self.num_patches = (image_height // patch_height) * (image_width // patch_width)
self.patch_dim = channels * patch_height * patch_width
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim)
self.de_pos_embedding = nn.Parameter(torch.from_numpy(de_pos_embedding).float().unsqueeze(0), requires_grad=False)
self.to_pixel = nn.Sequential(
Rearrange('b (h w) c -> b c h w', h=image_height // patch_height),
nn.ConvTranspose2d(dim, channels, kernel_size=patch_size, stride=patch_size)
)
self.apply(init_weights)
def forward(self, token: torch.FloatTensor) -> torch.FloatTensor:
x = token + self.de_pos_embedding
x = self.transformer(x)
x = self.to_pixel(x)
return x
def get_last_layer(self) -> nn.Parameter:
return self.to_pixel[-1].weight
剩余的训练部署部分代码留到之后统一介绍,我们只需要了解loss部分即可。
我们看如下model部分的代码,其中的xrec与qloss分别是前向传播返回的dec和diff,而diff是encode中的emb_loss返回的,也就是分别对应重构图像向量x_reconstruction和向量量化loss。这两个部分就可以构成loss文件中total_loss的计算了:
nll_loss = self.loglaplace_weight * loglaplace_loss + self.loggaussian_weight * loggaussian_loss + self.perceptual_weight * perceptual_loss
其中,
\begin{align} L = L_{VQ} + L_{\mathrm{logit-laplace}} + L_{\mathrm{adv}} + L_{\mathrm{perceptual}} + L_{\mathrm{2}} \tag{2} \end{align}
点击查看stage1_model代码
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
quant, diff = self.encode(x)
dec = self.decode(quant)
return dec, diff
def encode(self, x: torch.FloatTensor) -> Tuple[torch.FloatTensor, torch.FloatTensor]:
h = self.encoder(x)
h = self.pre_quant(h)
quant, emb_loss, _ = self.quantizer(h)
return quant, emb_loss
def training_step(self, batch: Tuple[Any, Any], batch_idx: int, optimizer_idx: int = 0) -> torch.FloatTensor:
x = self.get_input(batch, self.image_key)
xrec, qloss = self(x)
if optimizer_idx == 0:
# autoencoder
aeloss, log_dict_ae = self.loss(qloss, x, xrec, optimizer_idx, self.global_step, batch_idx,
last_layer=self.decoder.get_last_layer(), split="train") #self.loss = initialize_from_config(loss)
# loss:
# target: enhancing.losses.vqperceptual.VQLPIPSWithDiscriminator
# params:
# loglaplace_weight: 0.0
# loggaussian_weight: 1.0
# perceptual_weight: 0.1
# adversarial_weight: 0.1
self.log("train/total_loss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
del log_dict_ae["train/total_loss"]
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return aeloss
if optimizer_idx == 1:
# discriminator
discloss, log_dict_disc = self.loss(qloss, x, xrec, optimizer_idx, self.global_step, batch_idx,
last_layer=self.decoder.get_last_layer(), split="train")
self.log("train/disc_loss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
del log_dict_disc["train/disc_loss"]
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return discloss
## from vqperceptual_loss file
class VQLPIPSWithDiscriminator(nn.Module):
def __init__(self, disc_start: int = 0,
disc_loss: str = 'vanilla',
disc_params: Optional[OmegaConf] = dict(),
codebook_weight: float = 1.0,
loglaplace_weight: float = 1.0,
loggaussian_weight: float = 1.0,
perceptual_weight: float = 1.0,
adversarial_weight: float = 1.0,
use_adaptive_adv: bool = False,
r1_gamma: float = 10,
do_r1_every: int = 16) -> None:
super().__init__()
assert disc_loss in ["hinge", "vanilla", "least_square"], f"Unknown GAN loss '{disc_loss}'."
self.perceptual_loss = lpips.LPIPS(net="vgg", verbose=False)
self.codebook_weight = codebook_weight
self.loglaplace_weight = loglaplace_weight
self.loggaussian_weight = loggaussian_weight
self.perceptual_weight = perceptual_weight
self.discriminator = StyleDiscriminator(**disc_params)
self.discriminator_iter_start = disc_start
if disc_loss == "hinge":
self.disc_loss = hinge_d_loss
elif disc_loss == "vanilla":
self.disc_loss = vanilla_d_loss
elif disc_loss == "least_square":
self.disc_loss = least_square_d_loss
self.adversarial_weight = adversarial_weight
self.use_adaptive_adv = use_adaptive_adv
self.r1_gamma = r1_gamma
self.do_r1_every = do_r1_every
def calculate_adaptive_factor(self, nll_loss: torch.FloatTensor,
g_loss: torch.FloatTensor, last_layer: nn.Module) -> torch.FloatTensor:
nll_grads = torch.autograd.grad(nll_loss, last_layer, retain_graph=True)[0]
g_grads = torch.autograd.grad(g_loss, last_layer, retain_graph=True)[0]
adapt_factor = torch.norm(nll_grads) / (torch.norm(g_grads) + 1e-4)
adapt_factor = adapt_factor.clamp(0.0, 1e4).detach()
return adapt_factor
def forward(self, codebook_loss: torch.FloatTensor, inputs: torch.FloatTensor, reconstructions: torch.FloatTensor, optimizer_idx: int,
global_step: int, batch_idx: int, last_layer: Optional[nn.Module] = None, split: Optional[str] = "train") -> Tuple:
inputs = inputs.contiguous()
reconstructions = reconstructions.contiguous()
# now the GAN part
if optimizer_idx == 0:
# generator update
loglaplace_loss = (reconstructions - inputs).abs().mean()
loggaussian_loss = (reconstructions - inputs).pow(2).mean()
perceptual_loss = self.perceptual_loss(inputs*2-1, reconstructions*2-1).mean()
nll_loss = self.loglaplace_weight * loglaplace_loss + self.loggaussian_weight * loggaussian_loss + self.perceptual_weight * perceptual_loss #total_loss
logits_fake = self.discriminator(reconstructions)
g_loss = self.disc_loss(logits_fake)
try:
d_weight = self.adversarial_weight
if self.use_adaptive_adv:
d_weight *= self.calculate_adaptive_factor(nll_loss, g_loss, last_layer=last_layer)
except RuntimeError:
assert not self.training
d_weight = torch.tensor(0.0)
disc_factor = 1 if global_step >= self.discriminator_iter_start else 0
loss = nll_loss + disc_factor * d_weight * g_loss + self.codebook_weight * codebook_loss
log = {"{}/total_loss".format(split): loss.clone().detach(),
"{}/quant_loss".format(split): codebook_loss.detach(),
"{}/rec_loss".format(split): nll_loss.detach(),
"{}/loglaplace_loss".format(split): loglaplace_loss.detach(),
"{}/loggaussian_loss".format(split): loggaussian_loss.detach(),
"{}/perceptual_loss".format(split): perceptual_loss.detach(),
"{}/g_loss".format(split): g_loss.detach(),
}
if self.use_adaptive_adv:
log["{}/d_weight".format(split)] = d_weight.detach()
return loss, log
if optimizer_idx == 1:
# second pass for discriminator update
disc_factor = 1 if global_step >= self.discriminator_iter_start else 0
do_r1 = self.training and bool(disc_factor) and batch_idx % self.do_r1_every == 0
logits_real = self.discriminator(inputs.requires_grad_(do_r1))
logits_fake = self.discriminator(reconstructions.detach())
d_loss = disc_factor * self.disc_loss(logits_fake, logits_real)
if do_r1:
with conv2d_gradfix.no_weight_gradients():
gradients, = torch.autograd.grad(outputs=logits_real.sum(), inputs=inputs, create_graph=True)
gradients_norm = gradients.square().sum([1,2,3]).mean()
d_loss += self.r1_gamma * self.do_r1_every * gradients_norm/2
log = {"{}/disc_loss".format(split): d_loss.detach(),
"{}/logits_real".format(split): logits_real.detach().mean(),
"{}/logits_fake".format(split): logits_fake.detach().mean(),
}
if do_r1:
log["{}/r1_reg".format(split)] = gradients_norm.detach()
return d_loss, log
Stage 2 Vector-quantized Image Modeling
训练一个Transformer模型来自回归预测栅格化32×32 = 1024图像标记,其中图像标记由学习的Stage 1 Vit-VQGAN编码。对于无条件图像合成或无监督学习,预先训练一个仅解码器的Transformer模型来预测下一个令牌。为评估无监督学习的质量,平均中间Transformer特征,并学习一个linear head来预测类的logit(也就是linear-probe)。
需要注意的是,在code这版中Transformer参考了minGPT,使用了一个时间平移与混合的trick来提升训练速度,具体可以参考RWKV的一篇解析:> https://zhuanlan.zhihu.com/p/636551276 > ,简单来说就是引入了两种先验,通过前后错位concat与可学习权重来进行融合计算。
点击查看Transformer代码
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from minDALL-E (https://github.com/kakaobrain/minDALL-E)
# Copyright (c) 2021 KakaoBrain. All Rights Reserved.
# ------------------------------------------------------------------------------------
# Modified from minGPT (https://github.com/karpathy/minGPT)
# Copyright (c) 2020 Andrej Karpathy. All Rights Reserved.
# ------------------------------------------------------------------------------------
import math
from omegaconf import OmegaConf
from typing import Optional, Tuple, List
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.cuda.amp import autocast
class MultiHeadSelfAttention(nn.Module):
def __init__(self,
ctx_len: int, # 上下文最大长度
cond_len: int, # 条件序列长度(如 prefix/prompt)
embed_dim: int, # 嵌入维度 C
n_heads: int, # 注意力头数
attn_bias: bool, # 是否在 QKV 和输出层使用偏置
use_mask: bool = True):
super().__init__()
assert embed_dim % n_heads == 0
# key, query, value projections for all heads
self.key = nn.Linear(embed_dim, embed_dim, bias=attn_bias)
self.query = nn.Linear(embed_dim, embed_dim, bias=attn_bias)
self.value = nn.Linear(embed_dim, embed_dim, bias=attn_bias)
# output projection
self.proj = nn.Linear(embed_dim, embed_dim, attn_bias)
self.n_heads = n_heads
self.ctx_len = ctx_len
self.use_mask = use_mask
# 创建下三角掩码(不允许过去看到未来)特别地:前 cond_len 个位置之间完全可见(即 prompt 内部可以双向通信),后续图像 tokens 只能看到前面的所有内容(包括 prompt)
if self.use_mask:
self.register_buffer("mask", torch.ones(ctx_len, ctx_len), persistent=False)
self.mask = torch.tril(self.mask).view(1, ctx_len, ctx_len)
self.mask[:, :cond_len, :cond_len] = 1
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
with torch.no_grad():
ww = torch.zeros(1, 1, embed_dim)
for i in range(embed_dim):
ww[0, 0, i] = i / (embed_dim - 1)
self.time_mix = nn.Parameter(ww)
def forward(self, x, use_cache=False, layer_past=None):
B, T, C = x.shape
x = x * self.time_mix + self.time_shift(x) * (1 - self.time_mix)
x = x.transpose(0, 1).contiguous() # (B, T, C) -> (T, B, C)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
k = self.key(x).view(T, B*self.n_heads, C//self.n_heads).transpose(0, 1) # (B*nh, T, hs)
q = self.query(x).view(T, B*self.n_heads, C//self.n_heads).transpose(0, 1) # (B*nh, T, hs)
v = self.value(x).view(T, B*self.n_heads, C//self.n_heads).transpose(0, 1) # (B*nh, T, hs)
# 在生成阶段用于缓存历史 K/V,避免重复计算。
if use_cache:
present = torch.stack([k, v])
# 返回当前层的 KV 缓存。若有 layer_past,则拼接之前的缓存。
if layer_past is not None:
past_key, past_value = layer_past
k = torch.cat([past_key, k], dim=-2)
v = torch.cat([past_value, v], dim=-2)
# 当启用 use_cache 且已有 past 时:query 只取最后一个时间步(因为只生成一个 token), 计算 (B*nh, 1, T) 的 attention 分布, 输出也仅对应最新 token
if use_cache and layer_past is not None:
# Tensor shape below: (B * nh, 1, hs) X (B * nh, hs, K) -> (B * nh, 1, K)
att = torch.bmm(q, (k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))) #torch.bmm 批量矩阵乘法
att = F.softmax(att, dim=-1)
y = torch.bmm(att, v) # (B*nh, 1, K) X (B*nh, K, hs) -> (B*nh, 1, hs)
else:
# Tensor shape below: (B * nh, T, hs) X (B * nh, hs, T) -> (B * nh, T, T)
att = torch.bmm(q, (k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))))
if self.use_mask:
mask = self.mask if T == self.ctx_len else self.mask[:, :T, :T]
att = att.masked_fill(mask == 0, float('-inf'))
att = F.softmax(att, dim=-1)
y = torch.bmm(att, v) # (B*nh, T, T) X (B*nh, T, hs) -> (B*nh, T, hs)
y = y.transpose(0, 1).contiguous().view(T, B, C) # re-assemble all head outputs side by side
# output projection
y = self.proj(y)
if use_cache:
return y.transpose(0, 1).contiguous(), present # (T, B, C) -> (B, T, C)
else:
return y.transpose(0, 1).contiguous() # (T, B, C) -> (B, T, C)
# ReLU^2 way
class FFN(nn.Module):
def __init__(self, embed_dim, mlp_bias):
super().__init__()
self.p0 = nn.Linear(embed_dim, 4 * embed_dim, bias=mlp_bias)
self.p1 = nn.Linear(4 * embed_dim, embed_dim, bias=mlp_bias)
def forward(self, x):
x = self.p0(x)
# x = F.gelu(x)
x = torch.square(torch.relu(x))
x = self.p1(x)
return x
class Block(nn.Module):
def __init__(self,
ctx_len: int,
cond_len: int,
embed_dim: int,
n_heads: int,
mlp_bias: bool,
attn_bias: bool):
super().__init__()
self.ln1 = nn.LayerNorm(embed_dim)
self.ln2 = nn.LayerNorm(embed_dim)
self.attn = MultiHeadSelfAttention(ctx_len=ctx_len,
cond_len=cond_len,
embed_dim=embed_dim,
n_heads=n_heads,
attn_bias=attn_bias,
use_mask=True)
self.mlp = FFN(embed_dim=embed_dim, mlp_bias=mlp_bias)
def forward(self, x):
x = x + self.attn(self.ln1(x))
x = x + self.mlp(self.ln2(x))
return x
def sample(self, x, layer_past=None):
attn, present = self.attn(self.ln1(x), use_cache=True, layer_past=layer_past)
x = x + attn
x = x + self.mlp(self.ln2(x))
return x, present
class GPT(nn.Module):
def __init__(self,
vocab_cond_size: int,
vocab_img_size: int,
embed_dim: int,
cond_num_tokens: int,
img_num_tokens: int,
n_heads: int,
n_layers: int,
mlp_bias: bool = True,
attn_bias: bool = True) -> None:
super().__init__()
self.img_num_tokens = img_num_tokens
self.vocab_cond_size = vocab_cond_size
# condition token and position embedding
self.tok_emb_cond = nn.Embedding(vocab_cond_size, embed_dim)
self.pos_emb_cond = nn.Parameter(torch.zeros(1, cond_num_tokens, embed_dim))
# input token and position embedding
self.tok_emb_code = nn.Embedding(vocab_img_size, embed_dim)
self.pos_emb_code = nn.Parameter(torch.zeros(1, img_num_tokens, embed_dim))
# transformer blocks
self.blocks = [Block(ctx_len=cond_num_tokens + img_num_tokens,
cond_len=cond_num_tokens,
embed_dim=embed_dim,
n_heads=n_heads,
mlp_bias=mlp_bias,
attn_bias=attn_bias) for i in range(1, n_layers+1)]
self.blocks = nn.Sequential(*self.blocks)
# head
self.layer_norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, vocab_img_size, bias=False)
self.apply(self._init_weights)
def _init_weights(self, module: nn.Module) -> None:
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def forward(self,
codes: torch.LongTensor,
conds: torch.LongTensor) -> torch.FloatTensor:
codes = codes.view(codes.shape[0], -1)
codes = self.tok_emb_code(codes)
conds = self.tok_emb_cond(conds)
codes = codes + self.pos_emb_code
conds = conds + self.pos_emb_cond
x = torch.cat([conds, codes], axis=1).contiguous()
x = self.blocks(x)
x = self.layer_norm(x)
x = x[:, conds.shape[1]-1:-1].contiguous()
logits = self.head(x)
return logits
def sample(self,
conds: torch.LongTensor,
top_k: Optional[float] = None,
top_p: Optional[float] = None,
softmax_temperature: float = 1.0,
use_fp16: bool = True) -> Tuple[torch.FloatTensor, torch.LongTensor]:
past = codes = logits = None
for i in range(self.img_num_tokens):
if codes is None:
codes_ = None
pos_code = None
else:
codes_ = codes.clone().detach()
codes_ = codes_[:, -1:]
pos_code = self.pos_emb_code[:, i-1:i, :]
logits_, presents = self.sample_step(codes_, conds, pos_code, use_fp16, past)
logits_ = logits_.to(dtype=torch.float32)
logits_ = logits_ / softmax_temperature
presents = torch.stack(presents).clone().detach()
if past is None:
past = [presents]
else:
past.append(presents)
if top_k is not None:
v, ix = torch.topk(logits_, top_k)
logits_[logits_ < v[:, [-1]]] = -float('Inf')
probs = F.softmax(logits_, dim=-1)
if top_p is not None:
sorted_probs, sorted_indices = torch.sort(probs, dim=-1, descending=True)
cum_probs = torch.cumsum(sorted_probs, dim=-1)
sorted_idx_remove_cond = cum_probs >= top_p
sorted_idx_remove_cond[..., 1:] = sorted_idx_remove_cond[..., :-1].clone()
sorted_idx_remove_cond[..., 0] = 0
indices_to_remove = sorted_idx_remove_cond.scatter(-1, sorted_indices, sorted_idx_remove_cond)
probs = probs.masked_fill(indices_to_remove, 0.0)
probs = probs / torch.sum(probs, dim=-1, keepdim=True)
idx = torch.multinomial(probs, num_samples=1).clone().detach()
codes = idx if codes is None else torch.cat([codes, idx], axis=1)
logits = logits_ if logits is None else torch.cat([logits, logits_], axis=1)
del past
return logits, codes
def sample_step(self,
codes: torch.LongTensor,
conds: torch.LongTensor,
pos_code: torch.LongTensor,
use_fp16: bool = True,
past: Optional[torch.FloatTensor] = None) -> Tuple[torch.FloatTensor, List[torch.FloatTensor]]:
with autocast(enabled=use_fp16):
presents = []
if codes is None:
assert past is None
conds = self.tok_emb_cond(conds)
x = conds + self.pos_emb_cond
for i, block in enumerate(self.blocks):
x, present = block.sample(x, layer_past=None)
presents.append(present)
x = self.layer_norm(x)
x = x[:, conds.shape[1]-1].contiguous()
else:
assert past is not None
codes = self.tok_emb_code(codes)
x = codes + pos_code
past = torch.cat(past, dim=-2)
for i, block in enumerate(self.blocks):
x, present = block.sample(x, layer_past=past[i])
presents.append(present)
x = self.layer_norm(x)
x = x[:, -1].contiguous()
logits = self.head(x)
return logits, presents
class RQTransformer(nn.Module):
def __init__(self,
vocab_cond_size: int,
vocab_img_size: int,
embed_dim: int,
cond_num_tokens: int,
img_num_tokens: int,
depth_num_tokens: int,
spatial_n_heads: int,
depth_n_heads: int,
spatial_n_layers: int,
depth_n_layers: int,
mlp_bias: bool = True,
attn_bias: bool = True) -> None:
super().__init__()
self.img_num_tokens = img_num_tokens
self.depth_num_tokens = depth_num_tokens
self.vocab_img_size = vocab_img_size
# condition token and position embedding
self.tok_emb_cond = nn.Embedding(vocab_cond_size, embed_dim)
self.pos_emb_cond = nn.Parameter(torch.rand(1, cond_num_tokens, embed_dim))
# spatial token and position embedding
self.tok_emb_code = nn.Embedding(vocab_img_size, embed_dim)
self.pos_emb_code = nn.Parameter(torch.rand(1, img_num_tokens, embed_dim))
# depth position embedding
self.pos_emb_depth = nn.Parameter(torch.rand(1, depth_num_tokens-1, embed_dim))
# spatial transformer
self.spatial_transformer = [Block(ctx_len=cond_num_tokens + img_num_tokens,
cond_len=cond_num_tokens,
embed_dim=embed_dim,
n_heads=spatial_n_heads,
mlp_bias=mlp_bias,
attn_bias=attn_bias) for i in range(1, spatial_n_layers+1)]
self.spatial_transformer = nn.Sequential(*self.spatial_transformer)
# depth transformer
self.depth_transformer = [Block(ctx_len=depth_num_tokens,
cond_len=0,
embed_dim=embed_dim,
n_heads=depth_n_heads,
mlp_bias=mlp_bias,
attn_bias=attn_bias) for i in range(1, depth_n_layers+1)]
self.depth_transformer = nn.Sequential(*self.depth_transformer)
# head
self.ln_spatial = nn.LayerNorm(embed_dim)
self.ln_depth = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, vocab_img_size, bias=False)
self.apply(self._init_weights)
def _init_weights(self, module: nn.Module) -> None:
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def forward(self,
codes: torch.LongTensor,
conds: torch.LongTensor) -> torch.FloatTensor:
codes = codes.view(codes.shape[0], -1, codes.shape[-1])
codes = self.tok_emb_code(codes)
conds = self.tok_emb_cond(conds)
codes_cumsum = codes.cumsum(-1)
codes_sum = codes_cumsum[..., -1, :]
codes = codes_sum + self.pos_emb_code
conds = conds + self.pos_emb_cond
h = torch.cat([conds, codes], axis=1).contiguous()
h = self.ln_spatial(self.spatial_transformer(h))
h = h[:, conds.shape[1]-1:-1].contiguous()
v = codes_cumsum[..., :-1, :] + self.pos_emb_depth
v = torch.cat([h.unsqueeze(2), v], axis=2).contiguous()
v = v.view(-1, *v.shape[2:])
v = self.depth_transformer(v)
logits = self.head(self.ln_depth(v))
return logits
def sample(self,
conds: torch.LongTensor,
top_k: Optional[float] = None,
top_p: Optional[float] = None,
softmax_temperature: float = 1.0,
use_fp16: bool = True) -> Tuple[torch.FloatTensor, torch.LongTensor]:
past = codes = logits = None
B, T, D, S = conds.shape[0], self.img_num_tokens, self.depth_num_tokens, self.vocab_img_size
for i in range(self.img_num_tokens):
depth_past = None
if codes is None:
codes_ = None
pos_code = None
else:
codes_ = codes.clone().detach()
codes_ = codes_[:, -self.depth_num_tokens:]
pos_code = self.pos_emb_code[:, i-1:i, :]
hidden, presents = self.sample_spatial_step(codes_, conds, pos_code, use_fp16, past)
presents = torch.stack(presents).clone().detach()
if past is None:
past = [presents]
else:
past.append(presents)
last_len = 0 if codes is None else codes.shape[-1]
for d in range(self.depth_num_tokens):
if depth_past is None:
codes_ = None
pos_depth = None
else:
codes_ = codes.clone().detach()
codes_ = codes_[:, last_len:]
pos_depth = self.pos_emb_depth[:, d-1:d, :]
logits_, depth_presents = self.sample_depth_step(codes_, hidden, pos_depth, use_fp16, depth_past)
logits_ = logits_.to(dtype=torch.float32)
logits_ = logits_ / softmax_temperature
depth_presents = torch.stack(depth_presents).clone().detach()
if depth_past is None:
depth_past = [depth_presents]
else:
depth_past.append(depth_presents)
if top_k is not None:
v, ix = torch.topk(logits_, top_k)
logits_[logits_ < v[:, [-1]]] = -float('Inf')
probs = F.softmax(logits_, dim=-1)
if top_p is not None:
sorted_probs, sorted_indices = torch.sort(probs, dim=-1, descending=True)
cum_probs = torch.cumsum(sorted_probs, dim=-1)
sorted_idx_remove_cond = cum_probs >= top_p
sorted_idx_remove_cond[..., 1:] = sorted_idx_remove_cond[..., :-1].clone()
sorted_idx_remove_cond[..., 0] = 0
indices_to_remove = sorted_idx_remove_cond.scatter(-1, sorted_indices, sorted_idx_remove_cond)
probs = probs.masked_fill(indices_to_remove, 0.0)
probs = probs / torch.sum(probs, dim=-1, keepdim=True)
idx = torch.multinomial(probs, num_samples=1).clone().detach()
codes = idx if codes is None else torch.cat([codes, idx], axis=1)
logits = logits_ if logits is None else torch.cat([logits, logits_], axis=1)
del depth_past
del past
codes = codes.view(B, T, D)
logits = logits.view(B * T, D, S)
return logits, codes
def sample_spatial_step(self,
codes: torch.LongTensor,
conds: torch.LongTensor,
pos_code: torch.LongTensor,
use_fp16: bool = True,
past: Optional[torch.Tensor] = None) -> Tuple[torch.FloatTensor, List[torch.FloatTensor]]:
with autocast(enabled=use_fp16):
presents = []
if codes is None:
assert past is None
conds = self.tok_emb_cond(conds)
x = conds + self.pos_emb_cond
for i, block in enumerate(self.spatial_transformer):
x, present = block.sample(x, layer_past=None)
presents.append(present)
x = self.ln_spatial(x)
x = x[:, conds.shape[1]-1:conds.shape[1]].contiguous()
else:
assert past is not None
codes = self.tok_emb_code(codes)
x = codes.sum(1, keepdim=True) + pos_code
past = torch.cat(past, dim=-2)
for i, block in enumerate(self.spatial_transformer):
x, present = block.sample(x, layer_past=past[i])
presents.append(present)
x = self.ln_spatial(x)
x = x[:, -1:].contiguous()
return x, presents
def sample_depth_step(self,
codes: torch.LongTensor,
hidden: torch.FloatTensor,
pos_depth: torch.LongTensor,
use_fp16: bool = True,
past: Optional[torch.Tensor] = None) -> Tuple[torch.FloatTensor, List[torch.FloatTensor]]:
with autocast(enabled=use_fp16):
presents = []
if codes is None:
assert past is None
x = hidden
for i, block in enumerate(self.depth_transformer):
x, present = block.sample(x, layer_past=None)
presents.append(present)
x = self.ln_depth(x)
else:
assert past is not None
codes = self.tok_emb_code(codes)
x = codes.sum(1, keepdim=True) + pos_depth
past = torch.cat(past, dim=-2)
for i, block in enumerate(self.depth_transformer):
x, present = block.sample(x, layer_past=past[i])
presents.append(present)
x = self.ln_depth(x)
x = x[:, -1].contiguous()
logits = self.head(x)
return logits, presents
二、训练流程
BasicSR提供了一个非常结构化的SR训练框架,但可惜的是ViT-VQGAN使用的是自搭的训练流程。因此需要进行一下迁移。我们不妨以此为契机来了解一下训练方法。
一个完整的训练流程如下:
点击查看ViT-VQGAN model代码
# ------------------------------------------------------------------------------------
# Enhancing Transformers
# Copyright (c) 2022 Thuan H. Nguyen. All Rights Reserved.
# Licensed under the MIT License [see LICENSE for details]
# ------------------------------------------------------------------------------------
# Modified from Taming Transformers (https://github.com/CompVis/taming-transformers)
# Copyright (c) 2020 Patrick Esser and Robin Rombach and Björn Ommer. All Rights Reserved.
# ------------------------------------------------------------------------------------
from typing import List, Tuple, Dict, Any, Optional
from omegaconf import OmegaConf
import PIL
import torch
import torch.nn as nn
from torch.optim import lr_scheduler
from torchvision import transforms as T
import pytorch_lightning as pl
from .layers import ViTEncoder as Encoder, ViTDecoder as Decoder
from .quantizers import VectorQuantizer, GumbelQuantizer
from ...utils.general import initialize_from_config
class ViTVQ(pl.LightningModule):
def __init__(self, image_key: str, image_size: int, patch_size: int, encoder: OmegaConf, decoder: OmegaConf, quantizer: OmegaConf,
loss: OmegaConf, path: Optional[str] = None, ignore_keys: List[str] = list(), scheduler: Optional[OmegaConf] = None) -> None:
super().__init__()
self.path = path
self.ignore_keys = ignore_keys
self.image_key = image_key
self.scheduler = scheduler
self.loss = initialize_from_config(loss)
self.encoder = Encoder(image_size=image_size, patch_size=patch_size, **encoder)
self.decoder = Decoder(image_size=image_size, patch_size=patch_size, **decoder)
self.quantizer = VectorQuantizer(**quantizer)
self.pre_quant = nn.Linear(encoder.dim, quantizer.embed_dim)
self.post_quant = nn.Linear(quantizer.embed_dim, decoder.dim)
if path is not None:
self.init_from_ckpt(path, ignore_keys)
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
quant, diff = self.encode(x)
dec = self.decode(quant)
return dec, diff
def init_from_ckpt(self, path: str, ignore_keys: List[str] = list()):
sd = torch.load(path, map_location="cpu")["state_dict"]
keys = list(sd.keys())
for k in keys:
for ik in ignore_keys:
if k.startswith(ik):
print("Deleting key {} from state_dict.".format(k))
del sd[k]
self.load_state_dict(sd, strict=False)
print(f"Restored from {path}")
def encode(self, x: torch.FloatTensor) -> Tuple[torch.FloatTensor, torch.FloatTensor]:
h = self.encoder(x)
h = self.pre_quant(h)
quant, emb_loss, _ = self.quantizer(h)
return quant, emb_loss
def decode(self, quant: torch.FloatTensor) -> torch.FloatTensor:
quant = self.post_quant(quant)
dec = self.decoder(quant)
return dec
def encode_codes(self, x: torch.FloatTensor) -> torch.LongTensor:
h = self.encoder(x)
h = self.pre_quant(h)
_, _, codes = self.quantizer(h)
return codes
def decode_codes(self, code: torch.LongTensor) -> torch.FloatTensor:
quant = self.quantizer.embedding(code)
quant = self.quantizer.norm(quant)
if self.quantizer.use_residual:
quant = quant.sum(-2)
dec = self.decode(quant)
return dec
def get_input(self, batch: Tuple[Any, Any], key: str = 'image') -> Any:
x = batch[key]
if len(x.shape) == 3:
x = x[..., None]
if x.dtype == torch.double:
x = x.float()
return x.contiguous()
def training_step(self, batch: Tuple[Any, Any], batch_idx: int, optimizer_idx: int = 0) -> torch.FloatTensor:
x = self.get_input(batch, self.image_key)
xrec, qloss = self(x)
if optimizer_idx == 0:
# autoencoder
aeloss, log_dict_ae = self.loss(qloss, x, xrec, optimizer_idx, self.global_step, batch_idx,
last_layer=self.decoder.get_last_layer(), split="train")
self.log("train/total_loss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
del log_dict_ae["train/total_loss"]
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return aeloss
if optimizer_idx == 1:
# discriminator
discloss, log_dict_disc = self.loss(qloss, x, xrec, optimizer_idx, self.global_step, batch_idx,
last_layer=self.decoder.get_last_layer(), split="train")
self.log("train/disc_loss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
del log_dict_disc["train/disc_loss"]
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return discloss
def validation_step(self, batch: Tuple[Any, Any], batch_idx: int) -> Dict:
x = self.get_input(batch, self.image_key)
xrec, qloss = self(x)
aeloss, log_dict_ae = self.loss(qloss, x, xrec, 0, self.global_step, batch_idx,
last_layer=self.decoder.get_last_layer(), split="val")
rec_loss = log_dict_ae["val/rec_loss"]
self.log("val/rec_loss", rec_loss, prog_bar=True, logger=True, on_step=True, on_epoch=True, sync_dist=True)
self.log("val/total_loss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True, sync_dist=True)
del log_dict_ae["val/rec_loss"]
del log_dict_ae["val/total_loss"]
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=True)
if hasattr(self.loss, 'discriminator'):
discloss, log_dict_disc = self.loss(qloss, x, xrec, 1, self.global_step, batch_idx,
last_layer=self.decoder.get_last_layer(), split="val")
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return self.log_dict
def configure_optimizers(self) -> Tuple[List, List]:
lr = self.learning_rate
optim_groups = list(self.encoder.parameters()) + \
list(self.decoder.parameters()) + \
list(self.pre_quant.parameters()) + \
list(self.post_quant.parameters()) + \
list(self.quantizer.parameters())
optimizers = [torch.optim.AdamW(optim_groups, lr=lr, betas=(0.9, 0.99), weight_decay=1e-4)]
schedulers = []
if hasattr(self.loss, 'discriminator'):
optimizers.append(torch.optim.AdamW(self.loss.discriminator.parameters(), lr=lr, betas=(0.9, 0.99), weight_decay=1e-4))
if self.scheduler is not None:
self.scheduler.params.start = lr
scheduler = initialize_from_config(self.scheduler)
schedulers = [
{
'scheduler': lr_scheduler.LambdaLR(optimizer, lr_lambda=scheduler.schedule),
'interval': 'step',
'frequency': 1
} for optimizer in optimizers
]
return optimizers, schedulers
def log_images(self, batch: Tuple[Any, Any], *args, **kwargs) -> Dict:
log = dict()
x = self.get_input(batch, self.image_key).to(self.device)
quant, _ = self.encode(x)
log["originals"] = x
log["reconstructions"] = self.decode(quant)
return log
class ViTVQGumbel(ViTVQ):
def __init__(self, image_key: str, image_size: int, patch_size: int, encoder: OmegaConf, decoder: OmegaConf, quantizer: OmegaConf, loss: OmegaConf,
path: Optional[str] = None, ignore_keys: List[str] = list(), temperature_scheduler: OmegaConf = None, scheduler: Optional[OmegaConf] = None) -> None:
super().__init__(image_key, image_size, patch_size, encoder, decoder, quantizer, loss, None, None, scheduler)
self.temperature_scheduler = initialize_from_config(temperature_scheduler) \
if temperature_scheduler else None
self.quantizer = GumbelQuantizer(**quantizer)
if path is not None:
self.init_from_ckpt(path, ignore_keys)
def training_step(self, batch: Tuple[Any, Any], batch_idx: int, optimizer_idx: int = 0) -> torch.FloatTensor:
if self.temperature_scheduler:
self.quantizer.temperature = self.temperature_scheduler(self.global_step)
loss = super().training_step(batch, batch_idx, optimizer_idx)
if optimizer_idx == 0:
self.log("temperature", self.quantizer.temperature, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return loss
暂时搁置,之后更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号