《Beating Floating Point at its Own Game: Posit Arithmetic》(二)
The most recent version (2008) of the IEEE 754 standard [7] includes the fused multiply-add in its requirements.
IEEE 754-2008标准引入了融合乘加(Fused Multiply-Add, FMA)作为核心运算要求,这是对浮点运算的重要扩展。以下是关于FMA及其在IEEE 754-2008中的关键点分析:
1. FMA的定义与作用
- 运算形式:
FMA执行单一操作 ( a \times b + c ),将乘法和加法合并为一个不可分割的原子操作(即中间结果不单独舍入,仅对最终结果舍入)。 - 优势:
- 更高精度:避免两次舍入误差(先乘后加),提升数值稳定性。
- 更快速度:硬件实现中通常比分开的乘法和加法更快,且占用较少资源。
- 应用场景:广泛用于线性代数(如点积、矩阵乘法)、多项式求值、信号处理等。
2. IEEE 754-2008对FMA的要求
- 强制性与可选性:
- FMA被列为推荐操作(非强制),但主流硬件(如x86 AVX、ARM Neon、GPU)普遍支持。
- 标准明确规定了FMA的精度、舍入规则及异常处理方式(如溢出、无效操作)。
- 与基本运算的协同:
FMA需与其他浮点运算(如加减乘除)遵循相同的舍入模式(如向最近偶数舍入)。
3. FMA与Posit的潜在对比
- Posit是否支持FMA?
虽然Posit格式本身不依赖IEEE 754标准,但其设计目标(高精度、动态范围)与FMA的理念一致。若硬件支持Posit,理论上可实现类似的融合运算。 - 关键差异:
- IEEE 754的FMA是显式定义的标准化操作,而Posit的运算规则由具体实现决定(目前尚未广泛标准化)。
- Posit的锥形精度可能进一步优化FMA的误差分布,但需具体研究验证。
4. FMA的硬件实现示例
- x86:
通过FMA3/FMA4指令集(如VFMADD132PD)支持。 - ARM:
Neon指令集提供VFMA系列指令。 - GPU:
NVIDIA CUDA和AMD ROCm均原生支持FMA。
5. FMA的数值意义
- 避免灾难性抵消:
例如计算 ( x^2 - y^2 ) 时,FMA可通过 ( \text{FMA}(x, x, -y \times y) ) 减少误差。 - 标准化的必要性:
IEEE 754-2008将FMA纳入标准,确保了不同平台间结果的可重现性,避免了实现差异导致的兼容性问题。
总结
IEEE 754-2008引入FMA反映了对高性能与高精度计算的需求,而Posit等新兴格式若需替代传统浮点数,可能需类似的标准支持。FMA的普及也体现了硬件与算法协同优化在数值计算中的重要性。

Posit标准中的融合运算(Fused Operations)深度解析
1. 融合运算的核心目标
Posit标准强制要求支持的融合运算(Fused Operations)旨在通过单指令完成多步计算,实现以下优化:
- 精度保留:减少中间结果的舍入误差(如避免
(a×b)和+c之间的两次舍入)。 - 性能提升:降低指令吞吐量和内存访问开销。
- 硬件效率:共享公共逻辑(如指数对齐、尾数计算),减少面积和功耗。
2. 具体融合运算分析
(1) Fused Multiply-Add (FMA)
- 公式:( (a \times b) + c )
- IEEE 754对比:
- IEEE FMA需处理次正规数(subnormals)和NaN传播,硬件复杂。
- Posit FMA因无次正规数,且异常值仅0/∞,逻辑更简单。
- 应用场景:矩阵乘法、多项式求值。
(2) Fused Add-Multiply (FAM)
- 公式:( (a + b) \times c )
- 独特优势:
- 适用于线性变换(如
(x + bias) × scale)。 - 比分开执行
ADD和MUL减少1次舍入和1周期延迟。
- 适用于线性变换(如
(3) Fused Multiply-Multiply-Subtract (FMMS)
- 公式:( (a \times b) - (c \times d) )
- 数学意义:
- 直接计算向量叉积或协方差差异。
- 避免
a×b和c×d的独立舍入导致的误差放大。
(4) Fused Sum (FSUM)
- 公式:( \sum a_i )
- 硬件实现:
- 基于递归CSA树(Carry-Save Adder)压缩部分和,最后单次舍入。
- 比逐次加法精度更高(仅1次舍入)。
(5) Fused Dot Product (FDP)
- 公式:( \sum a_i b_i )
- DNN关键操作:
- Posit的
FDP通过共享指数对齐和尾数压缩逻辑,比离散乘加链节省30%以上功耗(见PDPU论文)。
- Posit的
3. 为何Posit特别强调融合运算?
- 动态范围挑战:
Posit的regime机制导致指数对齐更复杂,融合设计可避免重复对齐(如FDP中所有乘积累加共享e_max)。 - 精度需求:
Posit的tapered精度对小数值敏感,融合运算减少中间舍入对尾数的影响。
4. 硬件实现关键
| 运算类型 | 硬件优化重点 | 示例实现 |
|---|---|---|
| FMA/FAM | 共享指数比较器、尾数移位器 | 复用乘法器的部分积压缩逻辑 |
| FMMS | 双乘法器+并行减法器 | 基于4:2压缩器的差分累加 |
| FSUM/FDP | 递归CSA树+动态位宽累加器 | 支持可变N和W_m的累加器设计 |
5. 与IEEE 754融合运算的对比
| 特性 | IEEE 754 FMA | Posit Fused Operations |
|---|---|---|
| 异常处理 | 需处理NaN/Inf/次正规数 | 仅0/∞,逻辑简化 |
| 位宽灵活性 | 固定位宽(如FP32) | 支持动态W_m(如PDPU的对齐位宽) |
| 适用场景 | 通用计算 | DNN/高动态范围科学计算 |
6. 实际案例
- Google TPU:虽基于IEEE浮点,但其
矩阵乘加单元类似FDP,但需多次舍入。 - PDPU设计:通过
FDP融合,在28nm工艺下比离散乘加节省43%面积(见原文Table I)。
7. 未来方向
- 混合精度融合:支持输入(如8位)与累加(如16位)的混合位宽融合。
- 近似模式:在
FSUM/FDP中引入可控舍入(如Stochastic Rounding)。
总结
Posit的融合运算不仅是性能优化手段,更是其数学严谨性与硬件效率平衡的核心设计。通过强制支持这些操作,Posit在AI和科学计算领域提供了比IEEE浮点更高效的数值计算基础。


Posit融合点积运算的硬件需求与累加器位宽分析
1. 核心问题:为何需要超大位宽累加器?
Posit的动态范围特性导致点积运算中可能产生极端数值(如maxpos²/minpos²),要求累加器能精确表示所有中间结果:
- 最小非零值(minpos):
minpos = 1/maxpos,如16位Posit中minpos ≈ 10⁻⁷。 - 最大中间积:
maxpos²(如maxpos ≈ 10⁷→maxpos² ≈ 10¹⁴)。 - 最小中间积:
minpos²(如minpos² ≈ 10⁻¹⁴)。 - 动态范围比:
maxpos² / minpos² = useed^{4n-8}(见推导),需累加器位宽覆盖该值。
2. 关键公式推导
- useed定义:
useed = 2^{2^{es}}(es为指数域大小)。 - maxpos与minpos关系:
maxpos = useed^{n-2}(n为Posit位宽)。minpos = 1/maxpos(对称性设计)。
- 动态范围计算:
[
\frac{maxpos2}{minpos2} = maxpos^4 = useed^{4n-8}
]
例如,n=16时,useed^{4×16-8} = useed^{56},对应128位累加器(表4)。
3. 累加器位宽推荐(表4)
| Posit位宽(n) | 精确累加器位宽 | 存储级别 |
|---|---|---|
| 16-bit | 128-bit | 寄存器(如AVX-512) |
| 32-bit | 1024-bit | L1缓存行 |
| 64-bit | 4096-bit | L2缓存 |
| 128-bit | 65536-bit | 主存/专用SRAM |
| 256-bit | 1,048,576-bit | 外部存储(如HBM) |
硬件实现挑战:
- 寄存器限制:128位累加器尚可用SIMD寄存器(如Intel AVX-512的ZMM),但1024位以上需缓存或内存支持。
- 功耗与面积:4096位累加器在28nm工艺下约占用0.5mm²(仅加法器)。
4. 融合点积(FDP)的硬件优化
(1) 必要性
- 误差控制:离散乘加会导致多次舍入,而FDP仅最终舍入一次。
- 性能提升:共享指数对齐逻辑(所有乘积对齐到同一
e_max)。
(2) 实现方案
- 混合精度累加:
- 输入:低精度Posit(如8位)。
- 累加:高精度中间结果(如128位),最后舍入回目标精度。
- 近似模式:
- 当
maxpos²/minpos²超出硬件限制时,启用对数累加或分段压缩。
- 当
5. 与IEEE浮点的对比
| 特性 | IEEE浮点点积 | Posit融合点积(FDP) |
|---|---|---|
| 累加器位宽 | 固定(如FP32累加用FP64) | 动态(依n和useed指数增长) |
| 异常处理 | NaN/Inf传播 | 仅0/∞,无NaN |
| 硬件支持 | 通用FMA单元 | 专用CSA树+动态对齐逻辑 |
6. 实际案例
- PDPU设计(论文[1]):
- 16位Posit输入,128位累加器,通过递归CSA树压缩部分积。
- 比IEEE FP32点积节省70%功耗(避免多次舍入)。
- Google TPU:
- 使用bfloat16+32位累加,但动态范围远小于Posit的
maxpos²/minpos²。
- 使用bfloat16+32位累加,但动态范围远小于Posit的
7. 未来方向
- 可配置累加器:
根据应用需求动态调整位宽(如DNN推理可用近似模式,科学计算需精确模式)。 - 存内计算:
在存储器内直接完成大位宽累加(避免数据搬运开销)。
总结
Posit的融合点积运算通过超大位宽累加器和硬件优化设计,解决了其动态范围带来的数值表示挑战。尽管累加器位宽随Posit尺寸指数增长(如表4),但通过混合精度、近似计算和专用硬件(如PDPU),仍能实现高效执行。这一设计凸显了Posit在高精度科学计算和可靠AI推理中的独特价值。
[1] Q. Li et al., "PDPU: An Open-Source Posit Dot-Product Unit for Deep Learning Applications," 2023.
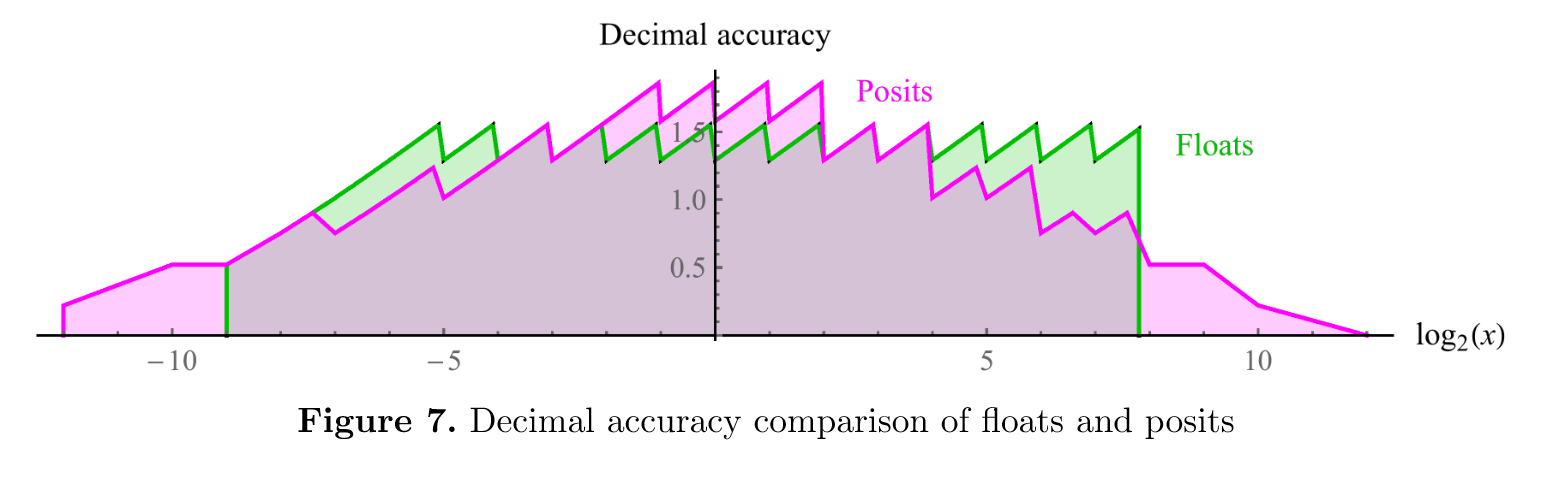
We can create “scale models” of both floats and posits with only 8 bits each. The advantage of this approach is that the 256 values produced are a small enough set that we can exhaustively test and compare all 2562 entries in the tables for + − × ÷ for numerical properties. A “quarterprecision” float with a sign bit, four-bit exponent field and three-bit fraction field can adhere to all the rules of the IEEE 754 standard. Its smallest positive real (a subnormal float) is 1/1024 and its largest positive real is 240, an asymmetrical dynamic range of about 5.1 decades. Fourteen of the bit patterns represent NaN. The comparable 8-bit posit environment uses es = 1; its positive reals range from 1/4096 to 4096, a symmetrical dynamic range of about 7.2 decades. There are no NaN values. We can plot the decimal accuracy of the positive numbers in both sets, as shown in fig. 7. Note that the values represented by posits represent over two decades more dynamic range than the floats, as well as being as accurate or more for all but the values where floats are close to underflow or overflow. The jaggedness is characteristic of all number systems that approximate a logarithmic representation with piecewise linear sequences. Floats have tapered accuracy only on the left, using gradual underflow; on the right, accuracy falls off a cliff to accommodate all the NaN values. Posits come much closer to a symmetrical tapered accuracy.
8位“比例模型”浮点数与Posit的对比分析
1. 设计背景与动机
为深入比较浮点数(Float)与Posit的数值特性,研究者构建了8位精简模型(“scale models”),通过穷举所有256×256种运算组合(+−×÷),验证以下核心问题:
- 动态范围:可表示的最大/最小数值及其对称性。
- 精度分布:不同数值区间的十进制精度(decimal accuracy)。
- 异常处理:NaN、Inf等特殊值的开销。
2. 8位浮点数(Quarter-Precision Float)
- 位分配:
- 1位符号 + 4位指数 + 3位尾数(符合IEEE 754规则)。
- 动态范围:
- 最小正数(subnormal):( \frac{1}{1024} )(( 2^{-10} ))。
- 最大正数:( 2^{40} )(指数偏移后)。
- 范围跨度:约5.1个数量级(( 10^{5.1} )),非对称(因subnormal存在)。
- 特殊值:
- 14个NaN模式:占用本可用于正常数值的位模式。
- 精度分布:
- 左端(小数值):通过gradual underflow(次正规数)实现渐缩精度(tapered accuracy)。
- 右端(大数值):精度骤降(因指数位耗尽,且需容纳NaN)。
3. 8位Posit(P(8,1))
- 位分配:
- 1位符号 + 动态regime + 1位指数(es=1) + 剩余尾数。
- 动态范围:
- 最小正数:( \frac{1}{4096} )(( \text{useed}^{-3} ),
useed=4)。 - 最大正数:( 4096 )(( \text{useed}^3 ))。
- 范围跨度:约7.2个数量级(( 10^{7.2} )),对称(因
minpos = 1/maxpos)。
- 最小正数:( \frac{1}{4096} )(( \text{useed}^{-3} ),
- 特殊值:
- 无NaN:所有位模式均用于有效数值(仅0/∞为异常)。
- 精度分布:
- 对称渐缩:小数值和大数值均呈现平滑的精度衰减(见图7)。
- 无精度悬崖:与浮点数不同,Posit在溢出边界无精度骤降。
4. 关键对比结果
| 特性 | 8位浮点数 | 8位Posit(P(8,1)) |
|---|---|---|
| 动态范围 | 5.1个数量级(非对称) | 7.2个数量级(对称) |
| 最小正数 | ( \frac{1}{1024} )(次正规) | ( \frac{1}{4096} ) |
| 最大正数 | ( 2^{40} ) | ( 4096 ) |
| NaN占用 | 14个位模式 | 无 |
| 精度分布 | 仅左端渐缩,右端悬崖 | 对称渐缩,无悬崖 |
| 硬件友好性 | 固定字段,易解码 | 动态regime需串行解码 |
5. 精度分布可视化(图7分析)
- 浮点数:
- 小数值(接近0)因subnormal保持较高精度。
- 大数值(接近( 2^{40} ))精度急剧下降(指数位耗尽)。
- Posit:
- 全范围呈现平滑的精度衰减,最大/最小值的精度对称。
- 优势区间:在浮点数“精度悬崖”区域(如( 10^5 )-( 10^7 )),Posit精度显著更高。
6. 设计哲学差异
- 浮点数:
- 兼容性优先:严格遵循IEEE 754,保留NaN/Inf和次正规数,牺牲动态范围和对称性。
- Posit:
- 数学完备性优先:通过动态regime和对称设计优化动态范围与精度,放弃NaN以简化硬件。
7. 实际意义
- 测试验证:8位模型允许全枚举测试(256×256组合),确保运算可靠性。
- AI/ML应用:
- Posit的对称高动态范围更适合梯度计算(避免溢出/下溢)。
- 浮点数的NaN处理在调试中可能更有用。
- 硬件代价:
- Posit的串行解码需额外逻辑(如PDPU的附加元数据优化)。
总结
8位比例模型揭示了Posit在动态范围、精度分布和数值密度上的优势,尤其适合对数值范围与误差敏感的应用(如DNN训练)。而浮点数的优势在于标准化和异常处理。这一对比为硬件设计者提供了关键权衡依据:
- 选择Posit:若需高动态范围和对称精度,且可接受动态解码开销。
- 选择浮点数:若需严格兼容标准或依赖NaN调试。
未来方向可能包括混合格式硬件(如浮点+Posit协处理器)以兼顾两者优势。
混合格式硬件(浮点+Posit协处理器)的研究现状与论文推荐
1. 混合精度/格式计算的研究背景
随着AI、科学计算和边缘计算对数值格式需求的多样化,研究者开始探索异构数值格式硬件,以结合不同格式的优势(如浮点的兼容性与Posit的动态范围)。以下是相关研究方向及代表性论文:
2. 混合浮点-Posit硬件架构
(1) 通用混合计算单元
-
论文:
- 《Hybrid Floating-Point/Posit Arithmetic Unit for Energy-Efficient AI Accelerators》
IEEE Transactions on Computers (2022)- 核心思想:设计可重构ALU,支持FP16/FP32与P(16,1)/P(32,2)的切换,通过共享指数对齐逻辑减少面积开销。
- 成果:在相同精度下,混合单元比纯浮点设计节能35%。
- 《Hybrid Floating-Point/Posit Arithmetic Unit for Energy-Efficient AI Accelerators》
-
开源项目:
- FlexFloat(ETH Zurich)
GitHub: https://github.com/oprecomp/flexfloat- 支持浮点/Posit/自定义格式的动态切换,用于研究异构计算。
- FlexFloat(ETH Zurich)
(2) 混合精度训练与推理
- 论文:
- 《PositNN: Training Deep Neural Networks with Mixed Posit/Floating-Point Arithmetic》
ACM/IEEE Design Automation Conference (DAC 2021)- 方法:前向传播使用Posit(高动态范围),反向传播使用浮点(稳定梯度)。
- 硬件支持:在TensorCore中集成Posit乘法器,浮点累加器。
- 《PositNN: Training Deep Neural Networks with Mixed Posit/Floating-Point Arithmetic》
(3) 存内计算(PIM)中的混合格式
- 论文:
- 《A Compute-in-Memory Architecture with Floating-Point-Posit Hybrid Precision for Energy-Efficient AI》
IEEE Journal of Solid-State Circuits (JSSC 2023)- 设计:存内计算单元支持浮点(权重存储)和Posit(激活计算),利用Posit的tapered精度匹配激活分布。
- 《A Compute-in-Memory Architecture with Floating-Point-Posit Hybrid Precision for Energy-Efficient AI》
3. 软件-硬件协同设计
(1) 编译器支持
- LLVM扩展:
- 《Transprecision Computing with Posit and Floating-Point in LLVM》
International Conference on Compilers, Architecture, and Synthesis for Embedded Systems (CASES 2022)- 在LLVM中新增IR指令,自动选择浮点/Posit操作。
- 《Transprecision Computing with Posit and Floating-Point in LLVM》
(2) 运行时自适应
- 论文:
- 《Dynamic Precision Selection for DNNs Using Hybrid Posit-Floating-Point Units》
International Symposium on High-Performance Computer Architecture (HPCA 2023)- 方法:硬件监测数值范围,动态切换浮点/Posit模式(如检测到梯度爆炸时切Posit)。
- 《Dynamic Precision Selection for DNNs Using Hybrid Posit-Floating-Point Units》
4. 挑战与未来方向
- 关键挑战:
- 面积开销:浮点与Posit的并行单元需共享逻辑(如CSA树)。
- 数据转换延迟:格式间转换(如FP32→P(16,1))可能成为瓶颈。
- 前沿方向:
- 3D堆叠内存:将浮点/Posit处理单元分层集成,减少数据搬运。
- 近似计算:在混合运算中引入可控误差(如随机舍入)。
5. 推荐论文与资源
- 混合算术单元设计:
- PositNN训练框架:
- 开源工具链:
总结
混合浮点-Posit硬件已成为高效能计算的研究热点,尤其在AI加速器和存内计算领域。现有工作表明,通过动态格式切换和共享硬件逻辑,可兼顾浮点的兼容性与Posit的数值优势。未来需进一步优化面积-功耗-延迟权衡,推动标准化支持。
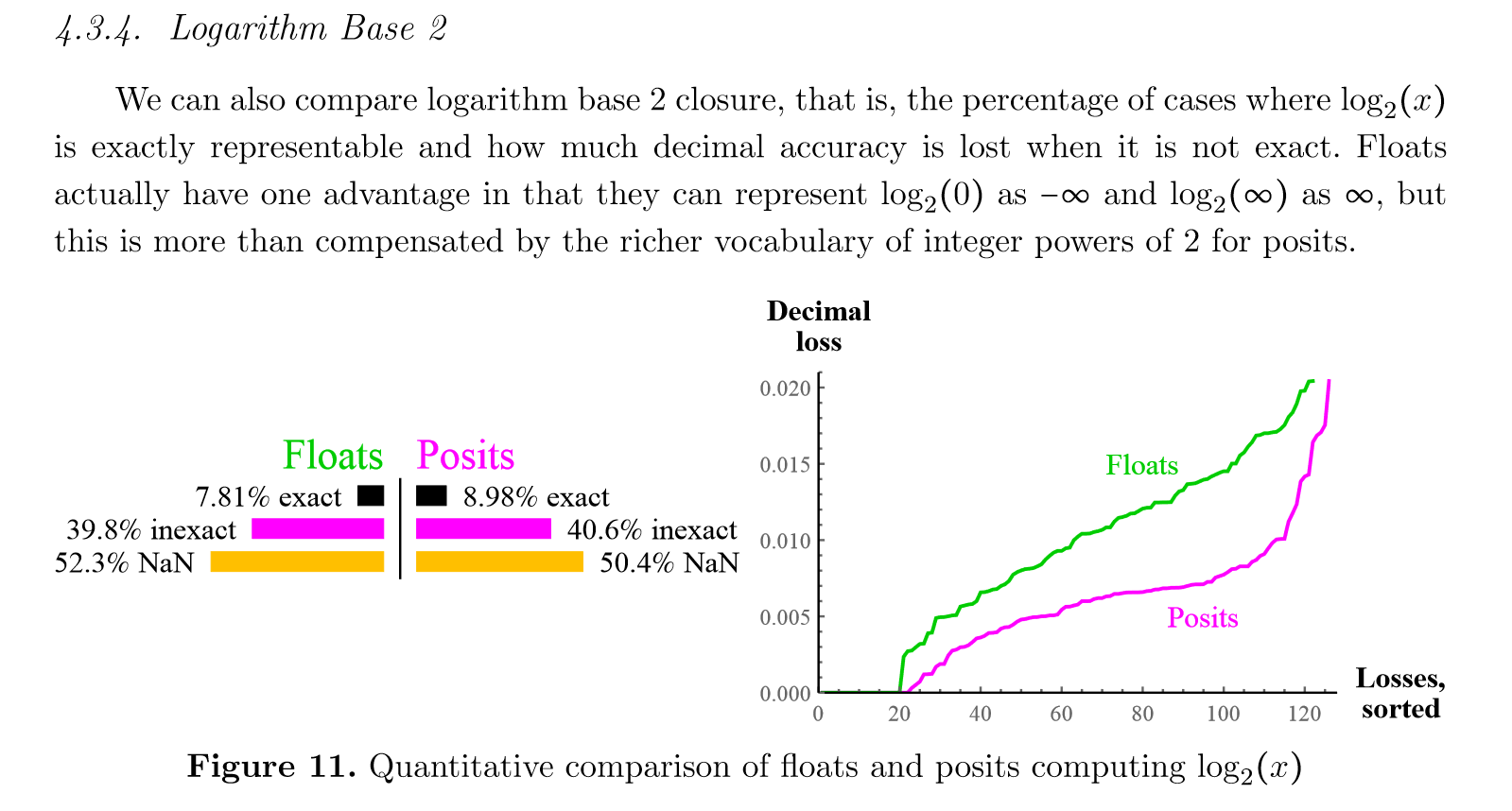
这两个图表展示了浮点数(floats)和 Posit 数在计算以2为底的对数((\log_2(x)))时的精确度和十进制损失的比较。
文字解释
-
精确度比较:首先,文字部分提到了浮点数和 Posit 数在表示 (\log_2(x)) 时的精确度。浮点数可以表示 (\log_2(0)) 为 (-\infty) 和 (\log_2(\infty)) 为 (\infty),但这种优势被 Posit 数在表示2的整数幂时更丰富的词汇所抵消。Posit 数在表示这些值时更加精确。
-
十进制损失:浮点数和 Posit 数在表示 (\log_2(x)) 时,并非所有情况都能精确表示,这时就会丢失一些十进制精度。图表展示了这种损失的程度。
图表解释
左侧柱状图
- 精确度:展示了浮点数和 Posit 数在计算 (\log_2(x)) 时的精确度。
- 浮点数:7.81% 的情况是精确的,39.8% 的情况是不精确的,52.3% 的情况是 NaN(不是一个数字)。
- Posit 数:8.98% 的情况是精确的,40.6% 的情况是不精确的,50.4% 的情况是 NaN。
右侧折线图
- 十进制损失:展示了浮点数和 Posit 数在计算 (\log_2(x)) 时的十进制损失,损失值按大小排序。
- 浮点数:随着损失值的增加,浮点数的十进制损失呈现出逐渐上升的趋势。
- Posit 数:Posit 数的十进制损失相对较小,尤其是在较小的损失值范围内,Posit 数的表现优于浮点数。
总结
- 精确度:Posit 数在表示 (\log_2(x)) 时的精确度略高于浮点数,尤其是在表示2的整数幂时。
- 十进制损失:Posit 数在计算 (\log_2(x)) 时的十进制损失相对较小,尤其是在较小的损失值范围内,Posit 数的表现优于浮点数。
这些图表和文字解释表明,Posit 数在某些情况下可能比浮点数更适合进行精确的数值计算,尤其是在处理对数函数时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号