大语言模型(LLM)虽强大,却天生受限于知识截止与幻觉现象两大痛点。检索增强生成(RAG)通过引入外部知识源,让LLM在生成答案前能“翻阅参考书”,从而大幅提升回答的准确性与可靠性。本文带你系统梳理RAG从Naive到Agentic的演进历程,并剖析其在服务端与后端架构中的实践价值。
为什么需要RAG?
LLM的训练过程是离线的,其知识范围被限制在训练数据的时间与内容边界内——这就是知识截止。例如,模型无法回答训练完成后才发生的新闻事件。更棘手的是幻觉现象:LLM本质上是基于条件概率逐词生成的,即使逻辑上“通顺”,也可能输出毫无事实依据的内容。你可以把LLM想象成一位只啃过旧教材的考生,遇到超纲题要么交白卷,要么凭模糊记忆编答案。RAG正是为这位考生配备的“参考书”或“第二个大脑”,让它在生成前先检索外部知识库,从而有效缓解上述问题。
RAG的核心架构
一个标准的RAG系统由两大组件构成:
- 检索(Retrieval):从外部数据源(如知识库、向量数据库、搜索引擎API)中查找与用户查询相关的信息。常见方法包括全文检索、向量检索、图检索等。
- 生成(Generation):将检索到的上下文与原始查询拼接,交给LLM生成最终回答。
这种“先查后答”的机制,在服务端与后端架构中表现为:数据库存储文档向量,中间件负责检索与排序,API对外暴露RAG服务,最终由LLM完成响应。RAG的成本远低于微调,却能显著提升输出的时效性与准确性,是当前最实用的LLM增强方案之一。
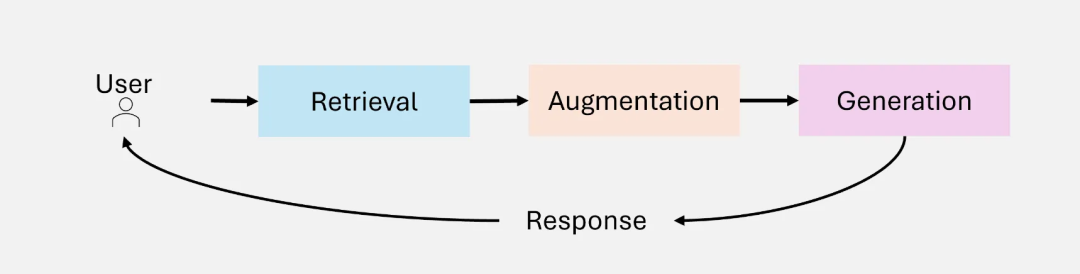
RAG的演进史:从Naive到Agentic
RAG技术并非一蹴而就。从最基础的Naive RAG,到如今具备智能决策能力的Agentic RAG,其发展大致经历了五个阶段。每个阶段都针对前一代的局限性进行了关键优化。
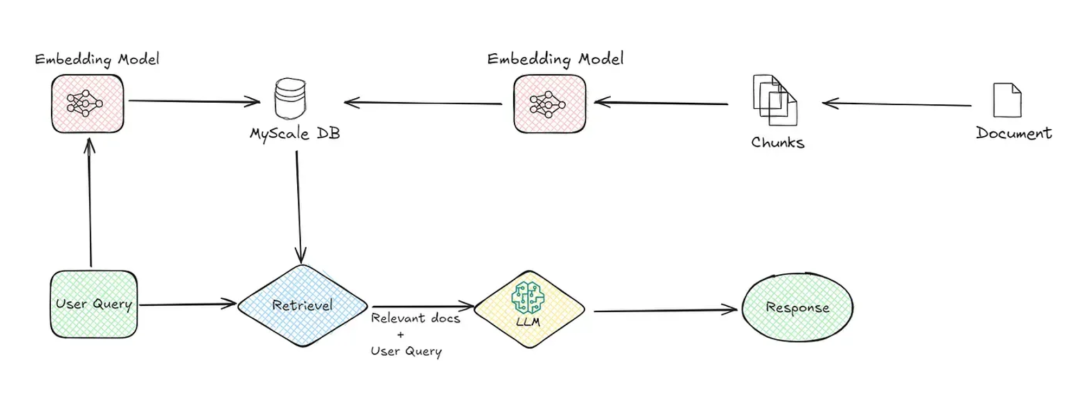
1. Naive RAG:最朴素的实现
Naive RAG是RAG的“Hello World”。它使用单一的全文检索或向量检索,从文档集合中召回与查询相关的片段,直接喂给LLM。然而,这种简单方案存在明显短板:
- ❌ 缺乏语义理解:词汇匹配无法捕捉查询与文档之间的深层关联。
- ❌ 输出效果不稳定:召回的文档可能信息过少或过多,导致回答宽泛甚至偏离。
- ❌ 优化空间有限:整个系统过度依赖单一检索技术,很难通过调整检索前/后处理来提升效果。
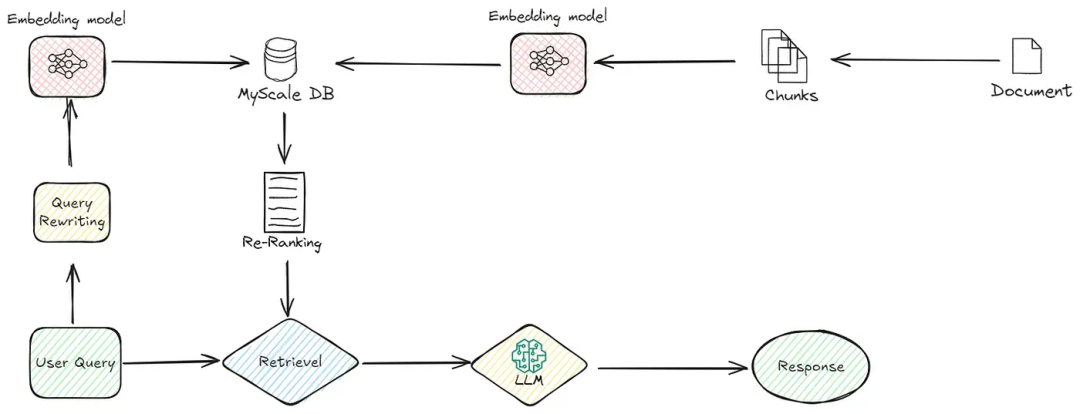
2. Advanced RAG:三阶段精细化优化
Advanced RAG在Naive的基础上,对检索前、检索、检索后三个阶段分别进行了增强:
- 检索前:优化文档质量(如改善章节结构、增强标题)、改进索引粒度(调整chunk size)、丰富索引信息(对chunk做摘要或关键词提取),并对用户查询进行改写。
- 检索:使用领域内数据对embedding模型进行微调,或采用基于LLM的embedding模型,生成更贴合上下文语义的向量。
- 检索后:引入重排序(Reranking)提升召回文档的相关性,并增加上下文压缩(Context Compression),确保喂给LLM的信息既精准又精简。
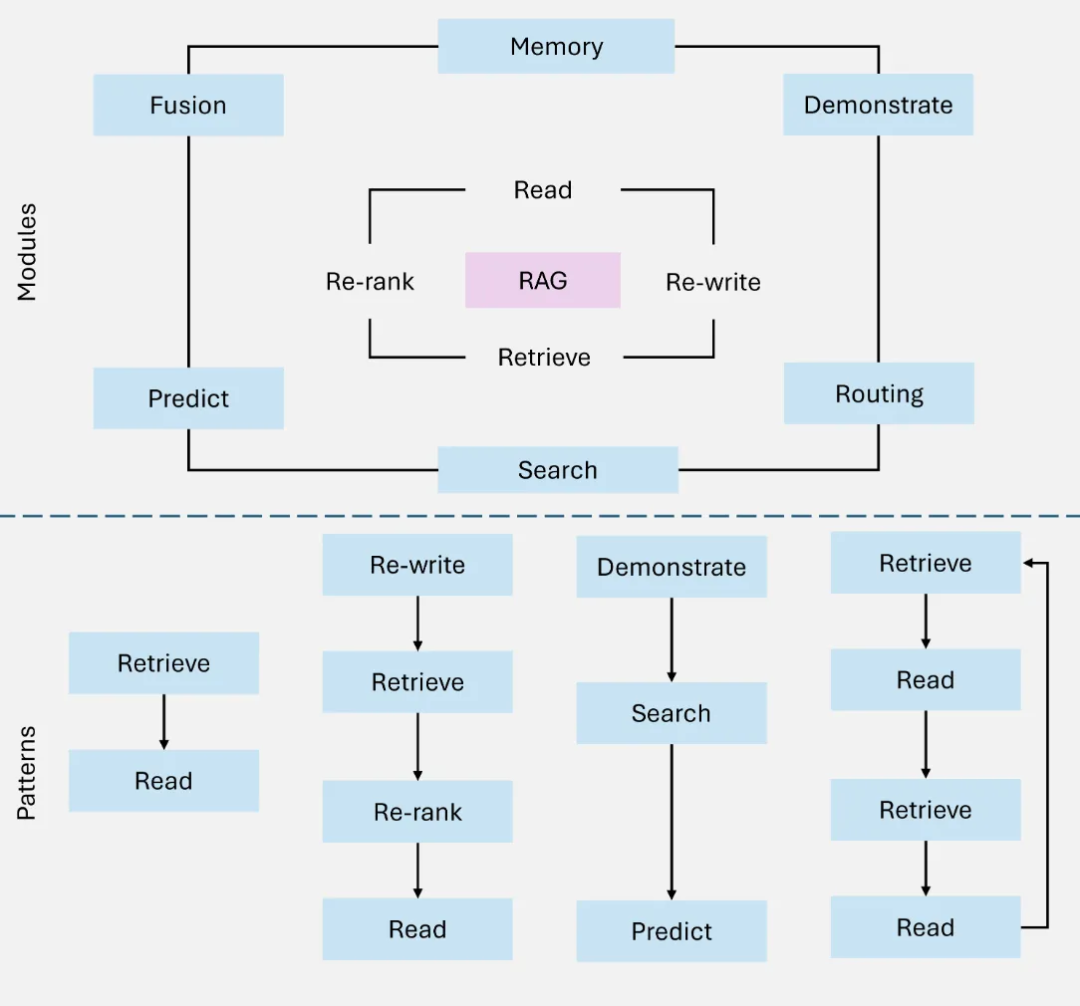
3. Modular RAG:组件化与复用
Modular RAG是当前后端架构中最主流的设计范式。它将检索、生成、路由、重排等功能拆解为独立可复用的模块,允许开发者根据具体场景灵活组合。例如,可以同时启用全文检索+向量检索的混合检索策略,再通过一个路由模块决定优先使用哪种结果。这种模块化设计不仅降低了系统耦合度,也使得针对特定API或数据库的优化变得更加容易。
4. Graph RAG:引入图结构增强推理
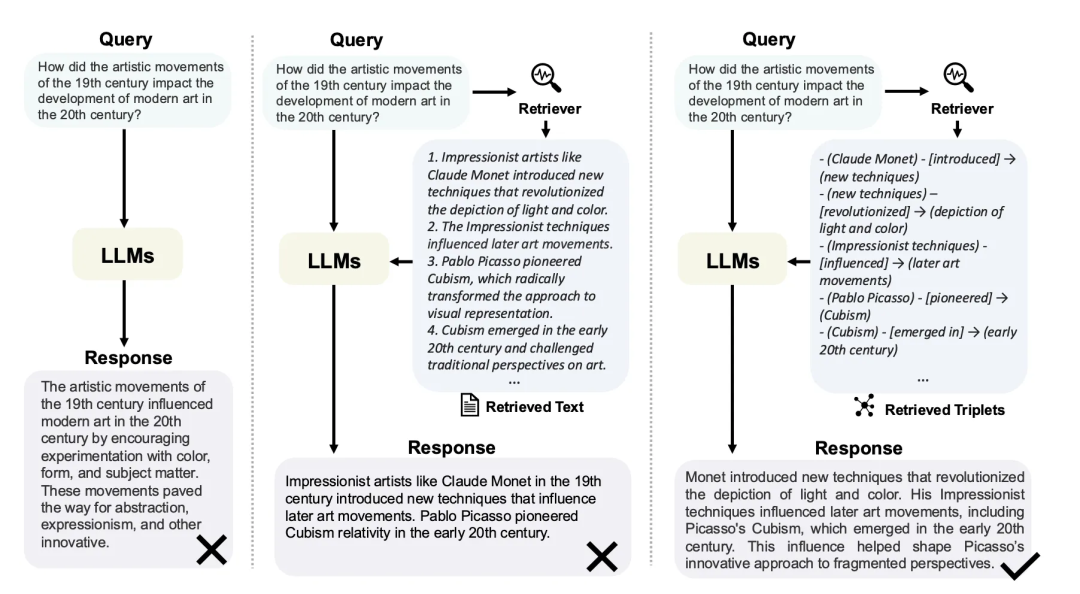
Graph RAG使用图结构来扩展传统RAG,通过实体与关系的显式建模,增强多跳推理(Multi-hop Reasoning)和上下文丰富度。例如,在回答“某公司的CEO与另一公司的创始人是什么关系”这类需要跨越多个文档的问题时,图检索能直接沿着关系路径查找,比纯向量检索更高效。但Graph RAG也有其局限性:
- ⚠️ 高质量图数据依赖:从非结构化文本中自动构建知识图谱,质量难以保证。
- ⚠️ 系统复杂性增加:同时管理非结构化数据与图数据,对中间件和服务端架构提出了更高要求。
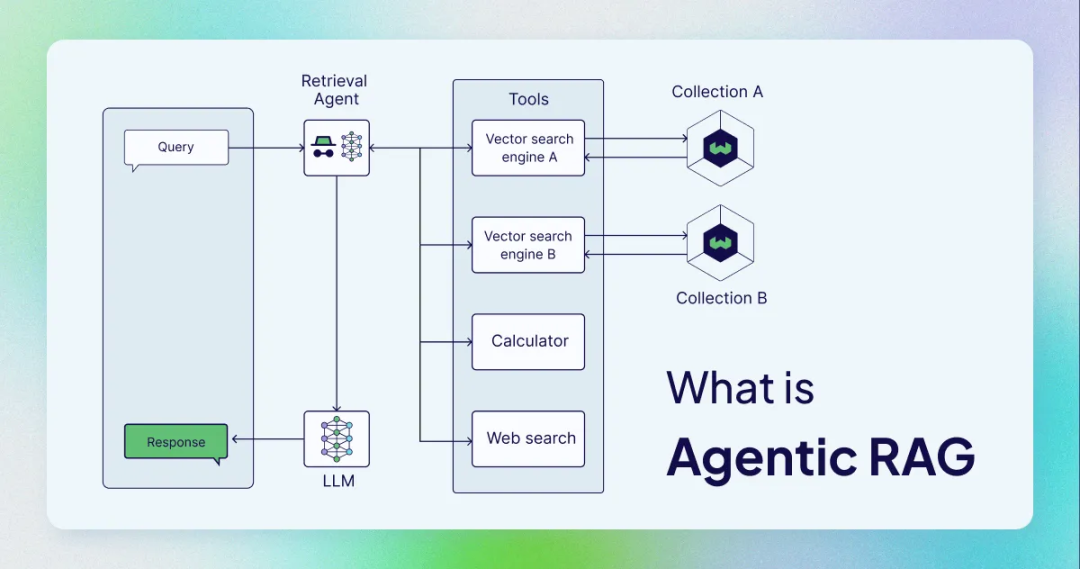
5. Agentic RAG:让RAG学会“思考”
Agentic RAG是RAG智能化的最新方向。它不再是一个静态的检索-生成流水线,而是引入了一个基于LLM的智能体(Agent),能够动态决策:
- 是否检索:对于简单查询,Agent可能直接生成答案,跳过检索环节。
- 用什么工具检索:Agent可以调用搜索引擎、计算器、数据库查询等多种API,而非仅限于预设的向量库。
- 是否需要继续检索:Agent会评估已检索到的上下文是否充分,若不满足则主动发起新一轮检索。
这种“思考-行动-观察”的循环,让RAG系统具备了前所未有的灵活性与鲁棒性。
各阶段对比总结
下表直观展示了五种RAG类型在核心能力与适用场景上的差异:
| RAG | 特点 | 优点 |
|---|---|---|
| Naive RAG | - 单一索引,如TF-IDF、BM25、向量检索 | - 简单,易于实现 - 缓解模型幻觉 |
| Advanced RAG | - 文档增强 - 索引优化 - query重写 - reranking | - 更准确的检索 - 增强检索相关性 |
| Modular RAG | - 混合检索 - 工具、API集成 - 模块化、工程化的实现 | - 更强的灵活性 - 适应更多元的场景 |
| Graph RAG | - 图结构索引 - multi-hop推理 - 基于图节点的上下文内容增强 | - 关系推理能力 - 适合结构化数据 |
| Agentic RAG | - 使用LLM-based agents - 动态决策、检索 - 自动流程优化 | - 更高的检索准确性 - 适合更复杂、更多域的任务 |
RAG的未来趋势
从RAG的发展脉络中,我们可以窥见几个明确的方向:
- 智能化:Agentic RAG只是一个起点。未来的RAG系统将具备更复杂的推理与规划能力,成为LLM真正的“大脑搭档”。
- 数据多元化:如何将文本、图数据、代码、图片、音频等异构数据统一纳入同一个RAG系统,实现高效的索引、检索与排序,将是后端架构与数据库技术面临的重大挑战。
- 端到端优化:从检索到生成的全链路联合优化,将使得RAG系统在延迟、准确率与成本之间达到更好的平衡。
总结
RAG技术已从简单的“文档灌入”演进为智能化的检索增强体系。无论是Naive RAG的快速验证,还是Advanced/Modular RAG的工程化实践,再到Graph/Agentic RAG的突破性探索,每一步都指向同一个目标:让LLM在真实世界中更可靠、更实用。对于后端开发者而言,理解RAG的演进逻辑,掌握其核心组件(检索器、重排序器、Agent)的设计与集成,将是构建下一代智能应用的关键能力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号