在当今数据驱动的开发环境中,业务人员往往难以编写复杂的SQL查询,而开发人员手写的SQL又可能因索引缺失或全表扫描导致性能瓶颈。本教程将带你从零到一打造一个基于DeepSeek V4的智能SQL生成与优化引擎,只需输入中文需求,即可自动生成SQL并基于真实执行计划给出优化建议。技术栈涵盖Java 21、Spring Boot 3,核心AI能力由DeepSeek V4提供,前端则是一个简洁的H5页面,支持多数据库方言。
一、项目功能与架构概览
本项目的核心目标是实现“自然语言 → SQL → 执行计划 → 优化建议”的自动化闭环。具体功能如下:
- 自然语言转SQL:用户输入中文业务需求(如“查询近30天每个品类的销售额排行,排除退货订单”),DeepSeek V4 Pro模型自动生成对应的SQL语句。
- 智能优化分析:生成SQL后,系统自动执行
EXPLAIN命令,获取真实执行计划,并交由DeepSeek V4 Flash模型分析,生成索引DDL和SQL改写建议。 - 多方言支持:支持MySQL、PostgreSQL、SQL Server等主流数据库方言,用户可自由选择。
- 开箱即用:单页H5前端 + Spring Boot后端,一键启动即可体验。
项目结构清晰,核心模块包括:数据库元数据采集、DeepSeek API调用、执行计划解析、优化建议生成。以下表格展示了技术栈详情:
| 模块 | 功能描述 |
|---|---|
| 自然语言 → SQL | 输入中文需求,DeepSeek V4 生成对应方言的 SQL |
| SQL 执行与 EXPLAIN | 通过 JDBC 执行 SQL 并获取执行计划 |
| 性能分析 | 将 EXPLAIN 结果送回 V4,识别索引缺失、全表扫描等问题 |
| 优化建议 | 输出优化后的 SQL + 索引创建 DDL |
| 数据库元数据感知 | 读取表结构、现有索引,辅助 V4 生成更精准的建议 |
架构流程图如下,展示了从用户输入到最终输出的完整链路:
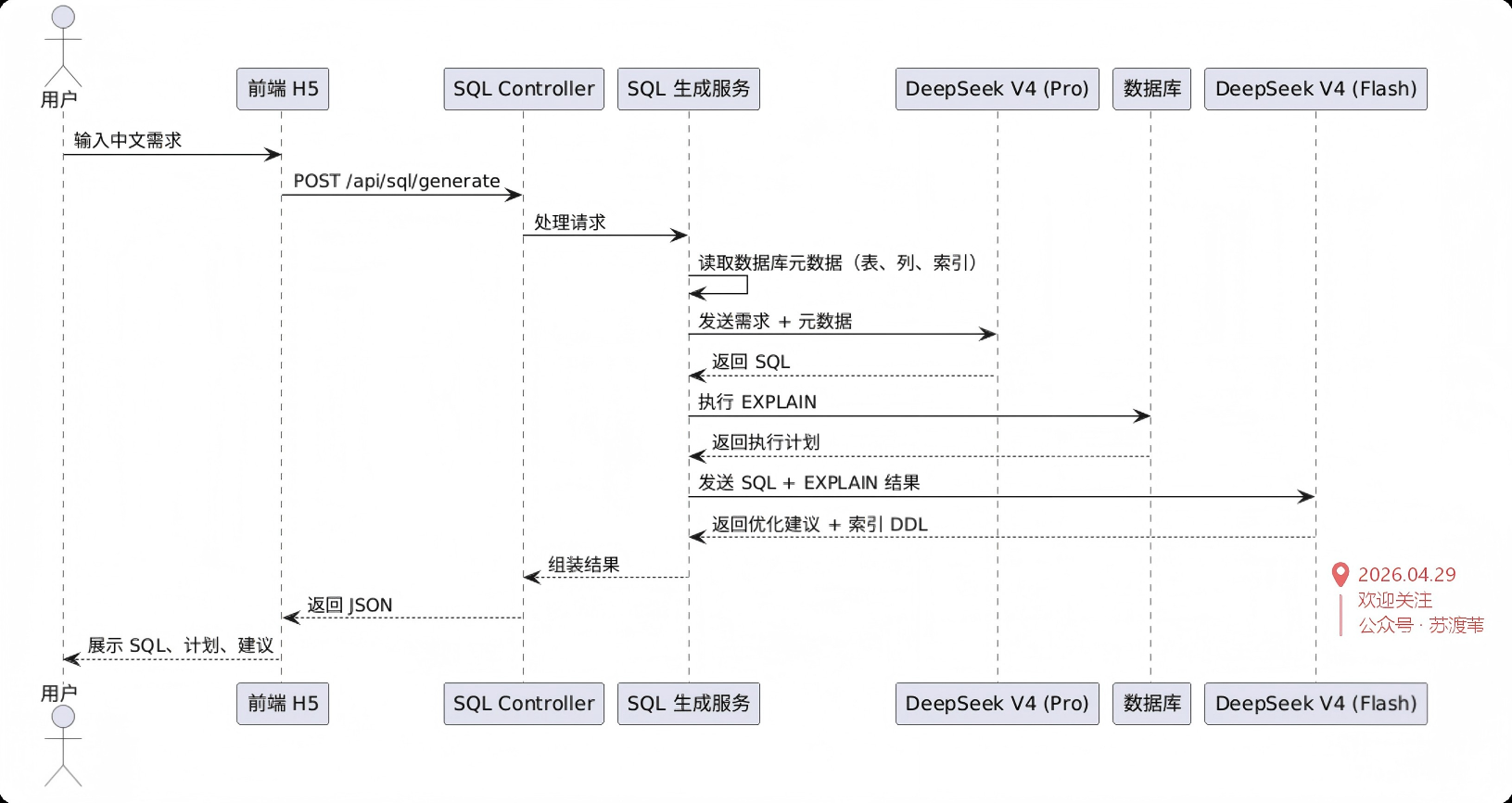
项目目录结构采用标准的Maven布局,关键代码组织如下:
deepseek-sql-optimizer/
├── pom.xml
├── src/main/java/io/github/iweidujiang/dsv4/sqloptimizer/
│ ├── SqlOptimizerApplication.java
│ ├── config/
│ │ ├── DeepSeekConfig.java
│ ├── controller/
│ │ └── SqlController.java
│ ├── service/
│ │ ├── SqlGenerateService.java
│ │ └── DatabaseMetadataService.java
│ ├── dto/
│ │ ├── SqlRequest.java
│ │ └── SqlResponse.java
│ └── util/
│ └── JdbcExecutor.java
├── src/main/resources/
│ ├── application.yml
│ ├── static/
│ │ └── index.html
│ └── db/
│ └── schema.sql二、数据库准备与元数据采集
为了让DeepSeek理解你的业务数据库,我们需要在提示词中动态注入数据库元数据。以电商场景为例,我们创建品类表和订单表:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS `demo-sql` DEFAULT CHARACTER SET utf8mb4;
USE `demo-sql`;
-- 品类表
CREATE TABLE `category` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL COMMENT '品类名称',
`parent_id` INT DEFAULT 0 COMMENT '父品类ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 订单表
CREATE TABLE `orders` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`order_no` VARCHAR(32) NOT NULL COMMENT '订单号',
`category_id` INT NOT NULL COMMENT '品类ID',
`amount` DECIMAL(10,2) NOT NULL COMMENT '订单金额',
`status` TINYINT NOT NULL DEFAULT 0 COMMENT '0-正常 1-退货',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_category` (`category_id`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;初始化少量数据用于演示,实际生产环境可扩充至百万级:
-- 品类数据
INSERT INTO `category` (`name`) VALUES ('电子产品'), ('服装'), ('家电'), ('图书');
-- 订单数据(过去30天随机生成,这里给一些示例)
INSERT INTO `orders` (`order_no`, `category_id`, `amount`, `status`, `create_time`) VALUES
('O001', 1, 299.00, 0, DATE_SUB(NOW(), INTERVAL 5 DAY)),
('O002', 1, 459.00, 0, DATE_SUB(NOW(), INTERVAL 12 DAY)),
('O003', 2, 129.00, 1, DATE_SUB(NOW(), INTERVAL 3 DAY)), -- 退货
('O004', 2, 399.00, 0, DATE_SUB(NOW(), INTERVAL 20 DAY)),
('O005', 3, 1999.00, 0, DATE_SUB(NOW(), INTERVAL 8 DAY)),
('O006', 3, 799.00, 0, DATE_SUB(NOW(), INTERVAL 15 DAY)),
('O007', 4, 55.00, 0, DATE_SUB(NOW(), INTERVAL 2 DAY)),
('O008', 4, 89.00, 0, DATE_SUB(NOW(), INTERVAL 25 DAY)),
('O009', 1, 1299.00, 0, DATE_SUB(NOW(), INTERVAL 1 DAY)),
('O010', 2, 259.00, 0, DATE_SUB(NOW(), INTERVAL 18 DAY));元数据采集的核心服务通过JDBC的DatabaseMetaData接口实现:
DatabaseMetadataService利用getTables()、getColumns()、getIndexInfo()等方法,将表名、列名、类型、索引信息拼接为结构化文本:
/**
* 获取数据库中所有表名、列信息、现有索引,用于增强提示词
*/
public String getSchemaContext() {
StringBuilder sb = new StringBuilder();
try {
// 获取所有表
List<String> tables = jdbcTemplate.queryForList(
"SHOW TABLES", String.class);
for (String table : tables) {
sb.append("表 ").append(table).append(":\n");
// 列信息
List<Map<String, Object>> columns = jdbcTemplate.queryForList(
"SHOW COLUMNS FROM " + table);
for (Map<String, Object> col : columns) {
sb.append(" 列: ").append(col.get("Field")).append(" 类型: ").append(col.get("Type"))
.append(" 是否可空: ").append(col.get("Null")).append("\n");
}
// 现有索引
List<Map<String, Object>> indexes = jdbcTemplate.queryForList(
"SHOW INDEX FROM " + table);
if (!indexes.isEmpty()) {
sb.append(" 已有索引: ");
String idxStr = indexes.stream()
.map(idx -> idx.get("Key_name").toString())
.distinct()
.collect(Collectors.joining(", "));
sb.append(idxStr).append("\n");
}
}
} catch (Exception e) {
log.warn("获取元数据失败", e);
return "无法获取数据库结构";
}
return sb.toString();
}最终发送给DeepSeek的提示词示例:
数据库结构如下:
表 category:
列: id 类型: int 是否可空: NO
列: name 类型: varchar(50) ...
已有索引: PRIMARY
表 orders:
列: id ... 列: category_id ... 列: amount ...
已有索引: PRIMARY, idx_category, idx_create_time
用户需求:查询近30天每个品类的销售额排行,排除退货订单
数据库方言:mysql
请生成 SQL。关键技巧:这种“结构即上下文”的方式让模型准确匹配真实列名,避免生成不存在的字段,同时感知已有索引,减少幻觉。
三、核心实现:生成SQL与执行计划分析
生成SQL阶段,我们使用DeepSeek V4 Pro模型,提示词设计强调两点:只输出JSON,严格遵循指定方言。System Prompt如下:
private static final String GENERATE_SQL_SYSTEM = """
你是一个资深 SQL 专家。根据用户的中文需求,生成符合指定方言的 SQL 查询语句。
输出格式必须是 JSON:{"sql": "生成的SQL语句"}
只输出 JSON,不要包含其他说明。
""";用户提示包含元数据、用户需求和方言。调用Spring AI的ChatClient只需几行代码:
ChatClient⚠️ 注意:实际调用时需传入API Key和模型参数,确保网络连接稳定。生成SQL后,通过JDBC执行EXPLAIN命令获取真实执行计划:
JdbcExecutorEXPLAIN例如MySQL返回的一行结果:
{id=1, select_type=SIMPLE, table=orders, type=ALL, possible_keys=idx_category, key=null, rows=10000, Extra=Using where}其中type: ALL表示全表扫描,key: NULL表示未使用索引,这些都是明确的优化信号。
优化分析阶段,我们将原始需求、生成的SQL以及EXPLAIN结果打包,交给DeepSeek V4 Flash模型(成本仅为Pro的1/12)。System Prompt要求输出JSON格式的优化建议:
{
"optimizedSql": "优化后的SQL语句",
"indexDdl": "CREATE INDEX ...",
"advice": "具体的优化建议文本"
}Flash模型会根据Extra字段中的Using where; Using filesort等特征,推断出需要创建哪些索引,有时还会将EXISTS改写为INNER JOIN以提升性能。
四、前端页面与运行效果
前端采用单页H5设计,所有功能通过index.html暴露,位于static目录下。用户输入需求,选择数据库方言,点击按钮即可触发后端接口。后端返回三个部分:生成的SQL、EXPLAIN结果、优化建议及索引DDL。
启动Spring Boot后,访问http://localhost:8080即可看到如下页面:
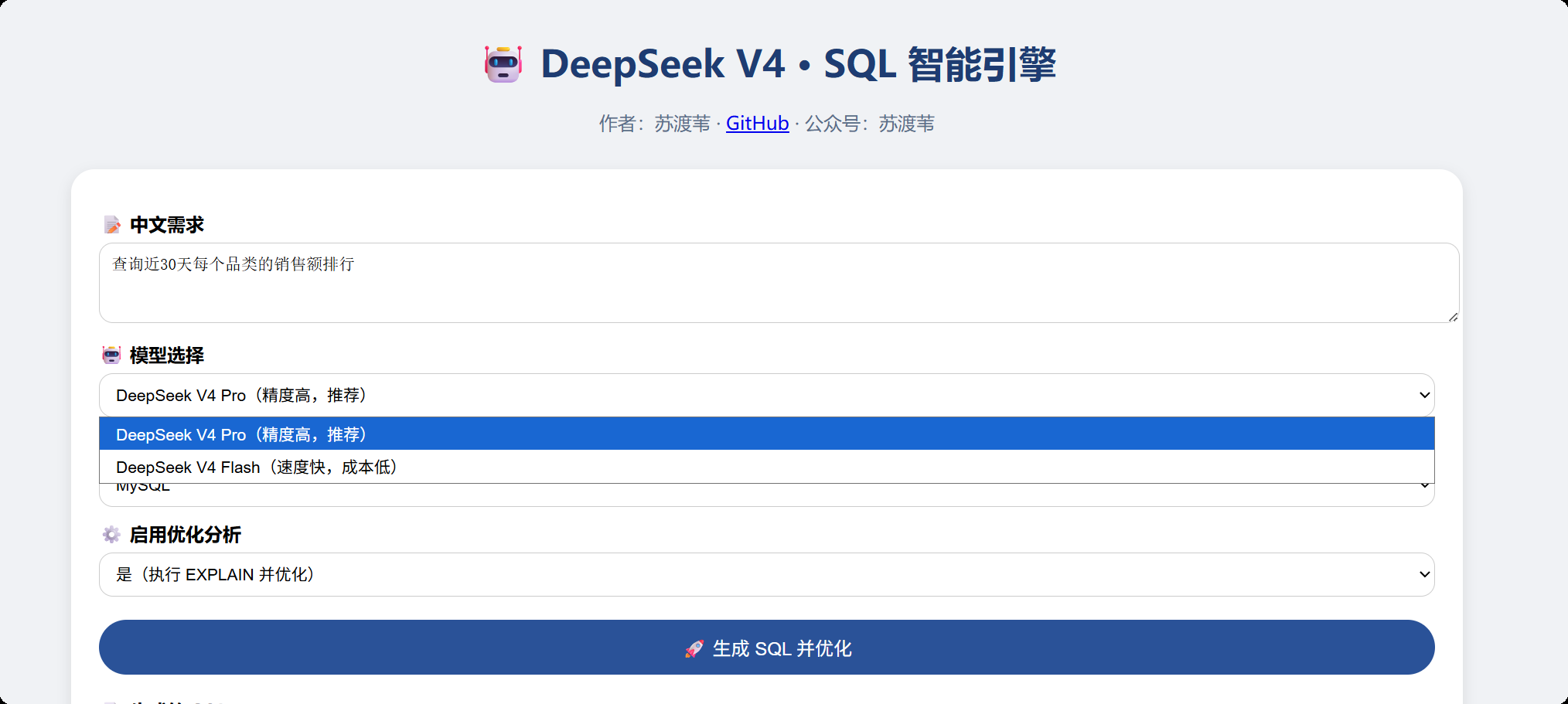
输入中文需求并选择MySQL方言,启用优化分析,点击生成:
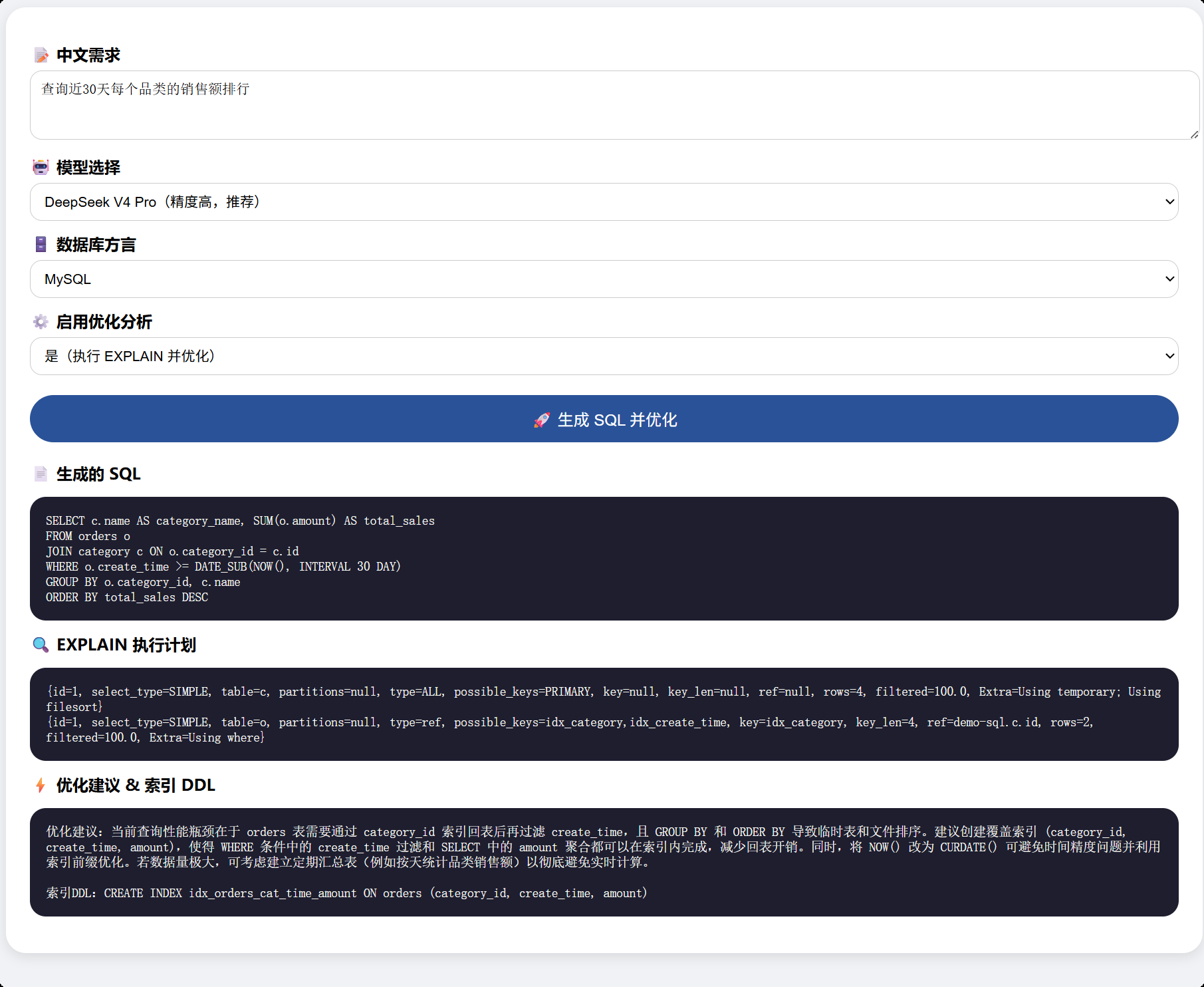
效果验证:DeepSeek V4正确理解“近30天每个品类销售额排行”并生成了包含LEFT JOIN和GROUP BY的SQL。EXPLAIN结果显示全表扫描,优化建议自动生成了针对order_date和category_id的复合索引DDL。
在实际项目中,你还可以集成JavaScript前端框架(如React或Vue)增强交互,或使用Python编写自动化测试脚本验证SQL正确性。对于多语言环境,Go和TypeScript也可作为后端或前端替代方案。
[AFFILIATE_SLOT_1]五、总结与实践建议
本文利用DeepSeek V4的推理能力,构建了一个从自然语言到SQL并自动优化的工具。核心优势包括:
- 元数据驱动:让AI“理解”你的数据库结构,减少幻觉。
- 闭环验证:基于真实EXPLAIN结果,而非理论分析。
- 成本可控:生成用Pro保证质量,优化用Flash降低成本。
- 开箱即用:H5页面 + Spring Boot,一键启动。
实践建议:
- 对于Java项目,可扩展支持更多数据库方言,如Oracle、SQLite。
- 生产环境建议增加查询超时和结果缓存机制,避免慢查询影响体验。
- 结合Python数据分析库(如Pandas)可进一步生成可视化报表。
DeepSeek V4的SQL能力正在推动一种新的开发体验:从“写SQL”到“描述业务”,AI负责翻译和打磨。项目源码已开源,欢迎访问GitHub仓库:https://github.com/iweidujiang/deepseek-v4-playground,欢迎star和贡献代码!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号