在分布式系统中,最可怕的事情不是单点故障,而是故障像雪崩一样蔓延——一个实例过载,导致负载转移给其他实例,后者随即也过载,最终整个服务瘫痪。这就是连锁故障(Cascading Failure)。本文将拆解其本质、触发原因,并给出Google SRE的实战防御策略。
作者: andylin02
学习章节:第22章 应对连锁故障(Addressing Cascading Failures)
关键词:连锁故障、正反馈循环、资源耗尽、重试风暴、GC死亡螺旋、负载测试、优雅降级、指数退避、羊群效应
一、连锁故障的本质:正反馈循环
“任何工程实践都无法消除所有故障,但SRE的设计原则是:当一个服务失效时,其影响不会级联到整个系统。”——Betsy Beyer
连锁故障的核心机制是正反馈循环:一个小问题通过系统自身的响应被放大,最终导致全局崩溃。经典场景如下:
- 某个服务实例因过载崩溃
- 负载均衡器将请求重定向到其他健康实例
- 其他实例负载升高,逐渐也过载、崩溃
- 整个过程在数分钟内完成,因为负载均衡器和任务编排系统的响应速度极快
如果说第21章讨论的是“如何在过载中求生”,那么本章探讨的就是“如何在系统崩溃前,防止一个局部问题引爆整个组织”。可靠性不是不出问题,而是避免出现问题导致整个系统崩溃。
核心观点:系统过载不是异常,而是必然。关键在于系统如何优雅地拒绝或延迟请求。系统的目标从来不是“永不失败”,而是“在失败时仍能保持可控与优雅”。
二、核心观点速览
| 维度 | 核心要点 |
|---|---|
| 连锁故障的本质 | 由正反馈循环导致,一个小故障会引发系统其他部分也出现故障 |
| 两大触发原因 | ①服务器过载;②资源耗尽(CPU、内存、线程、文件描述符等) |
| CPU过载的副作用链 | 请求变慢→处理中请求数上升→队列过长→RPC超时→客户端重试→进一步过载 |
| 内存耗尽的连锁反应 | 内存不足→任务崩溃→缓存命中率下降→向后端发送更多请求→后端过载 |
| GC死亡螺旋 | CPU不足→请求变慢→内存上升→GC次数增加→CPU更少→恶性循环 |
| 核心防御策略 | 负载测试、优雅降级、上游限流、智能队列、重试预算 |
| 负载测试关键指标 | ①性能退化曲线;②请求延迟分布;③资源耗尽点;④过度重试行为 |
| 优雅降级三原则 | 区分请求优先级、负载感知队列、提前拒绝(防止排队积压) |
| 上游限流的原则 | 限流责任应当分布式,而非集中式——每个调用者都应自我限制 |
| 重试风暴的核心解法 | 指数退避+随机抖动+全局重试预算,三者缺一不可 |
三、两大触发原因:服务器过载与资源耗尽
“连锁故障是由于正反馈循环导致的不断扩大规模的故障。”
3.1 服务器过载
服务器过载是连锁故障最常见的前兆。当某个集群过载导致实例崩溃后,负载均衡器会将流量重定向到其他集群,使那些集群也过载,最终造成整个服务崩溃。
3.2 资源耗尽的四种维度
当负载不断上升到过载时,不同种类的资源耗尽会产生不同影响:
① CPU资源耗尽
CPU不足时,所有请求都会变慢,引发一系列副作用:
| 副作用 | 说明 |
|---|---|
| 正在处理(in-flight)的请求数量上升 | 请求处理速度变慢,积压越来越多 |
| 队列过长 | 延迟上升,同时队列会使用更多的内存 |
| 线程卡住 | 线程因等待资源而无法释放 |
| CPU 死锁或请求卡住 | 极端情况下请求永久阻塞 |
| RPC 超时 | 客户端设置的超时被触发,服务器实际处理被浪费 |
| 客户端重试 | 超时后客户端重试,造成更严重的过载 |
| CPU 缓存效率下降 | 处理更多的上下文切换,效率进一步降低 |
这是一个典型的正反馈循环:CPU不足→处理变慢→队列积压→内存上升→GC压力增加→CPU更不足。
② 内存耗尽
同时处理的请求数量升高会消耗更多内存。内存耗尽的影响链条包括:
- 任务崩溃:超过资源限制后被容器管理器驱逐
- GC死亡螺旋:CPU资源减少→请求处理变慢→内存使用率上升→触发GC次数增多→CPU资源进一步减少
- 缓存命中率下降:可用内存减少导致缓存命中率降低,向后端发送更多RPC,可能导致后端任务过载
GC死亡螺旋是Java服务过载时的典型恶性循环,一旦开始就很难逆转。
③ 线程资源耗尽
线程不足可能导致错误或健康检查失败。如果服务器为此增加更多线程,这些线程可能会占用更多内存。极端情况下,线程不足可能导致进程ID数不足(Linux的进程ID数是有限的)。
④ 文件描述符耗尽
文件描述符不足可能会导致无法建立网络连接,进而导致健康检查失败。
四、教科书级案例:从CPU不足到健康检查失败的10步连锁
实践启示:仅凭事后分析难以揭示这种跨越多个团队边界的故障根源。必须通过主动的负载测试和混沌工程来提前发现这类隐藏的依赖关系。
书中通过一个Java前端服务的例子,完整演示了从CPU不足到健康检查失败的10步连锁故障链条:
- Java前端服务器GC参数没有被调优
- 在高负载(在期待范围内)情况下,由于GC问题导致CPU不足
- CPU不足导致请求处理变慢
- 同时处理的请求增多导致内存使用上升
- 内存压力上升,用于缓存的内存减少
- 缓存命中率下降
- 更多请求被发往后端进行处理
- 后端服务器CPU或线程不足
- CPU不足导致健康检查失败
- 触发了连锁故障
⚠️ 关键教训:在这个复杂情境下,发生故障时可能没有时间仔细分析因果关系。尤其是在前端和后端由不同团队运维时,判断后端崩溃是由于前端缓存命中率下降可能非常困难。
五、防止软件服务器过载的核心策略
“过载时最坏的不是请求被拒绝,而是所有请求都超时。”
5.1 负载测试——看见“悬崖”在哪里
在没有充分测试的情况下,SRE根本不知道过载什么时候会把系统“推下悬崖”。Google推荐测试关注:
- 性能退化曲线:系统在何时开始崩溃?是逐渐退化还是突然崩溃?
- 请求延迟分布:特别是长尾延迟的变化趋势
- 资源耗尽点:哪个资源(CPU、内存、线程、FD)最先被耗尽
- 过度重试行为:是否有“重试风暴”的风险
这些测试不仅要在测试环境运行,更应该在生产环境的受控范围(如金丝雀测试)验证。
5.2 优雅降级——拒绝也是一种选择
核心思想:区分请求的优先级,过载时核心功能优先保障。
| 手段 | 说明 |
|---|---|
| 优先级丢弃 | 健康检查请求、支付确认等核心业务高优先级;后台批处理任务可先被丢弃 |
| 负载感知队列 | 根据当前负载动态调整队列行为 |
| 提前拒绝 | 当系统明显无法处理更多请求时,立即拒绝新请求(快速失败),而不是让它们在队列中排队。在排队中的请求会消耗内存,同时使延迟升高 |
实践反思:在设计降级策略时,不仅要考虑“拒绝谁”,还要考虑“保谁”。SRE需要预先制定策略,哪些中间数据是可舍弃的(比如为了避免MQ服务的队列积压,非核心队列可以清空),哪些服务可以临时停止以减少对数据库或其他服务的压力。
5.3 上游限流——分布式责任
“限流责任应当分布式,而非集中式。系统的可靠性取决于调用者的克制。”
Google提倡在调用方限流,而不是只依赖被调用方的防御机制:
- 每个客户端对被调用服务的并发数、QPS做限制
- 调用失败时采用指数退避重试(Exponential Backoff)
传统思维的陷阱:许多团队只依赖网关或负载均衡器做集中式限流,但当一个客户端自身发生bug或配置错误时,它仍然可以发送海量请求压垮下游。上游限流将责任分散到每个调用者,从根源上减少请求的产生。
5.4 重试预算——防止重试风暴
“过载往往不是因为请求太多,而是因为重试太多。”——Google SRE 经验教训
重试风暴的形成机制:
- 下游服务变慢 → 请求超时 → 客户端重试
- 重试进一步加重下游负载 → 下游更慢 → 更多重试
- 形成正反馈循环,直到系统崩溃
Google SRE的核心解法:
- 指数退避:每次重试的延迟时间指数级增加(1ms → 2ms → 4ms → 8ms...),防止重试请求在短时间内集中到达
- 随机抖动:在退避时间上添加随机偏移,防止多个客户端在同一时间点同时发起重试(“羊群效应”)
- 全局重试预算:在整个系统层面限制重试的总次数。当预算耗尽时,后续失败直接返回错误,不再重试
六、其他关键机制:队列管理与健康检查
6.1 队列长度管理
原则:队列是平滑流量波动的缓冲,但过长的队列会成为定时炸弹。Google的建议是:队列长度应该与线程池大小成比例(例如50%或更少)。这样当系统无法维持传入请求的速率时,服务器会提前拒绝请求(“快速失败”),而不是让请求在队列中慢慢排队并消耗内存。
6.2 健康检查的双刃剑效应
一个值得警惕的场景:当系统过载时,健康检查请求本身也可能成为负担。如果健康检查响应变慢,负载均衡器可能错误地将节点标记为不健康,导致流量被转移到其他节点,进一步加剧过载。Google的经验是:健康检查应该使用轻量级、低成本的端点,确保即使在系统压力较大时也能快速响应。
七、方法论总结
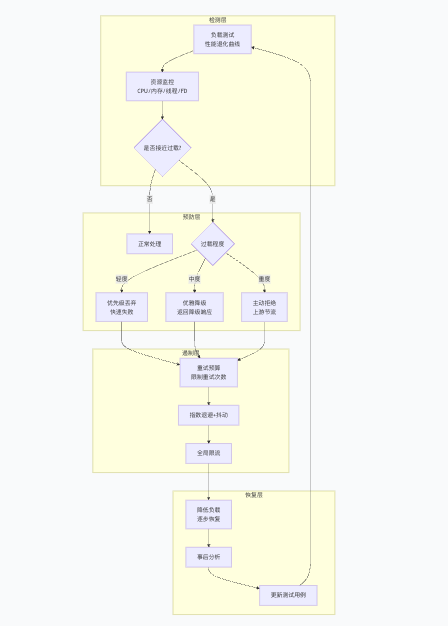
八、与其他章节的关联
| 关联章节 | 关联点 |
|---|---|
| 第13章 紧急事件响应 | 连锁故障的初期表现通常是一次紧急事件;如果处理不当,局部问题会迅速扩大为全局危机 |
| 第14章 紧急事故管理 | 当连锁故障已经发生时,第14章的事故管理流程是协调多团队响应、控制影响范围的关键 |
| 第15章 事后总结 | 每次连锁故障都需要事后总结,将“GC死亡螺旋”“重试风暴”等模式沉淀为组织的知识资产 |
| 第16章 跟踪故障 | 事后总结中识别的行动项目需要通过跟踪系统闭环管理,确保改进措施真正落实 |
| 第21章 应对过载 | 第21章讨论“过载时如何求生”(过载保护机制),本章讨论“当过载保护失效后如何防止连锁崩溃”(系统韧性机制)——两者是同一问题的“事前防御”与“事后遏制” |
| 第8章 发布工程 | 金丝雀发布和渐进式部署是防止“配置变更触发连锁故障”的第一道防线 |
| 第19-20章 负载均衡 | 负载均衡策略直接影响故障传播的速度和范围——良好的负载均衡可以“隔离”故障,糟糕的负载均衡会加速连锁反应 |
九、脑图总结
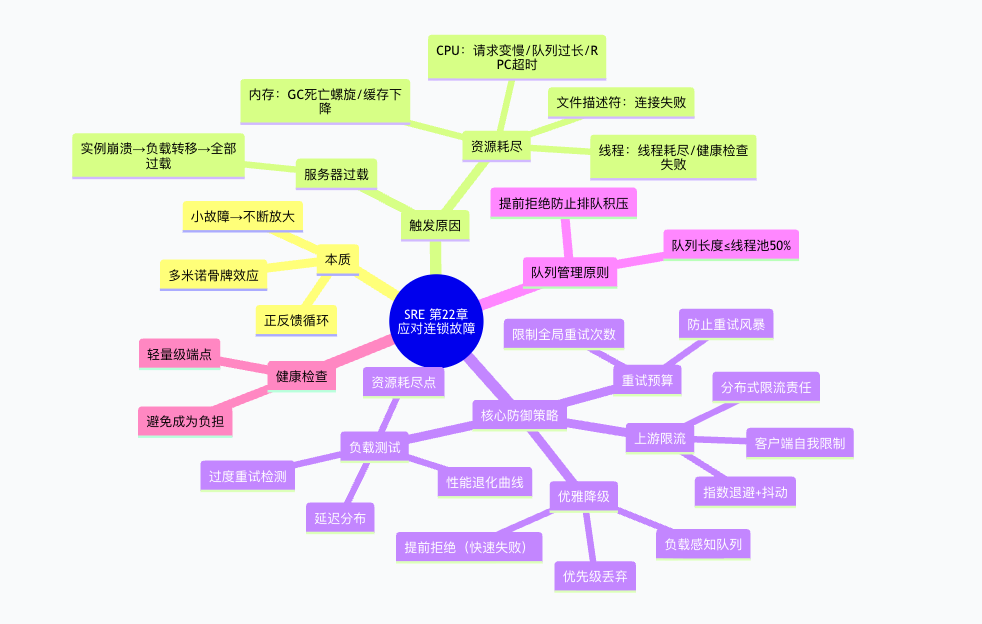
十、一句话记住本章
连锁故障 = 正反馈循环导致的小故障放大效应。应对策略 = 负载测试找悬崖 + 上游限流止源头 + 优雅降级保核心 + 重试预算断重试风暴。
| 关键点 | 一句话概括 |
|---|---|
| 连锁故障的本质 | 正反馈循环:一个小故障会通过反馈放大效应,导致系统像多米诺骨牌一样逐个崩溃 |
| 两大触发原因 | 服务器过载(流量转移)和资源耗尽(CPU/内存/线程/FD) |
| CPU过载的连锁反应 | 请求变慢 → 队列积压 → RPC超时 → 客户端重试 → 进一步过载 |
| GC死亡螺旋 | CPU不足→请求变慢→内存上升→GC增加→CPU更不足,形成恶性循环 |
| 负载测试的作用 | 在安全环境中找出系统的“崩溃悬崖”,预知资源耗尽顺序 |
| 优雅降级三原则 | 区分请求优先级、负载感知队列、提前拒绝(快速失败) |
| 上游限流的原则 | 限流责任应当分布式,每个调用者都应自我限制 |
| 重试风暴的真相 | “过载往往不是因为请求太多,而是因为重试太多” |
| 核心解法 | 指数退避+随机抖动+全局重试预算,三者缺一不可 |
| 队列管理 | 队列长度≤线程池的50%,避免排队积压导致雪崩 |
十一、高频考点自测
问题1:什么是连锁故障?它的核心机制是什么?
✅ 连锁故障是由于正反馈循环导致的不断扩大规模的故障。一个小故障会通过反馈放大效应,导致系统像多米诺骨牌一样逐个崩溃。
问题2:CPU资源耗尽时会产生哪些连锁副作用?
✅ 正在处理的请求数量上升,影响内存和线程等资源;队列过长,延迟上升并消耗更多内存;线程卡住;RPC超时,导致服务器实际处理被浪费;客户端重试,造成更严重过载;CPU缓存效率下降,处理效率进一步降低。
问题3:什么是“GC死亡螺旋”?
✅ 是Java服务在过载时的典型恶性循环:CPU资源减少→请求处理变慢→内存使用率上升→触发GC次数增多→消耗更多CPU→CPU资源进一步减少。
问题4:防止重试风暴的三个核心解法是什么?
✅ 指数退避保证单个客户端的行为合理;随机抖动保证多客户端不会同步;全局重试预算保证整体不被重试风暴击垮。三者缺一不可。
问题5:为什么负载测试在防止连锁故障中至关重要?
✅ 在没有充分测试的情况下,SRE根本不知道过载什么时候会把系统“推下悬崖”。Google推荐测试关注性能退化曲线、请求延迟分布、资源耗尽点和过度重试行为。
问题6:优雅降级包含哪三个关键手段?
✅ 优先级丢弃:区分请求优先级,过载时核心业务优先保障;负载感知队列:根据当前负载动态调整队列行为;提前拒绝:当系统无法处理更多请求时,立即拒绝新请求(快速失败)。
本文为个人学习笔记,仅用于知识分享。如有错误,欢迎指正。
点赞 + 收藏 + 分享,让更多开发者看到这篇深度解析!❤️ 如果觉得有用,请给个赞支持一下作者!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号