2026年五一杯数学建模B题“多工序协同作业问题”并非简单的工序排序,它融合了设备运输、资源互斥与同步完工等复杂约束。本文将从工程实现角度,解析如何构建调度模型、设计启发式算法,并输出可验证的甘特图与结果表。
\n\n这道题的真正难点
\n题目要求安排A、B、C、D、E五个车间的整修任务,但远非“排个顺序”那么简单。它同时包含:固定工序链、设备类型需求、设备移动速度、班组初始位置、车间距离,以及“某些工序需要两类设备共同完成”的同步完工规则。
\n最容易低估的是运输时间和同步约束。设备在同一车间连续作业时运输时间可忽略,但跨车间移动必须计入;一道工序若需要两类设备,不能只看先完成的那台,而要等所有参与设备都完成对应工程量后,后续工序才可释放。
\n因此,最终将其抽象为带运输时间、资源互斥和同步完工约束的资源受限调度问题。第1问可解析化简,第2问进入多车间资源竞争,第3问则加入双班组设备池。
\n\n从题目到调度模型
\n题目附件 B-附件.xlsx
- \n
工序流程表\n班组配置表\n车间距离表\n
业务上可理解为:每个车间是一条固定工序链,每道工序可能需要一台或多台设备;设备需从当前位置移动至目标车间才能开工,同一设备不能同时服务两道工序。
\n第3问的全局设备调度甘特图直观展示了“设备池 + 车间链 + 时间轴”的结构: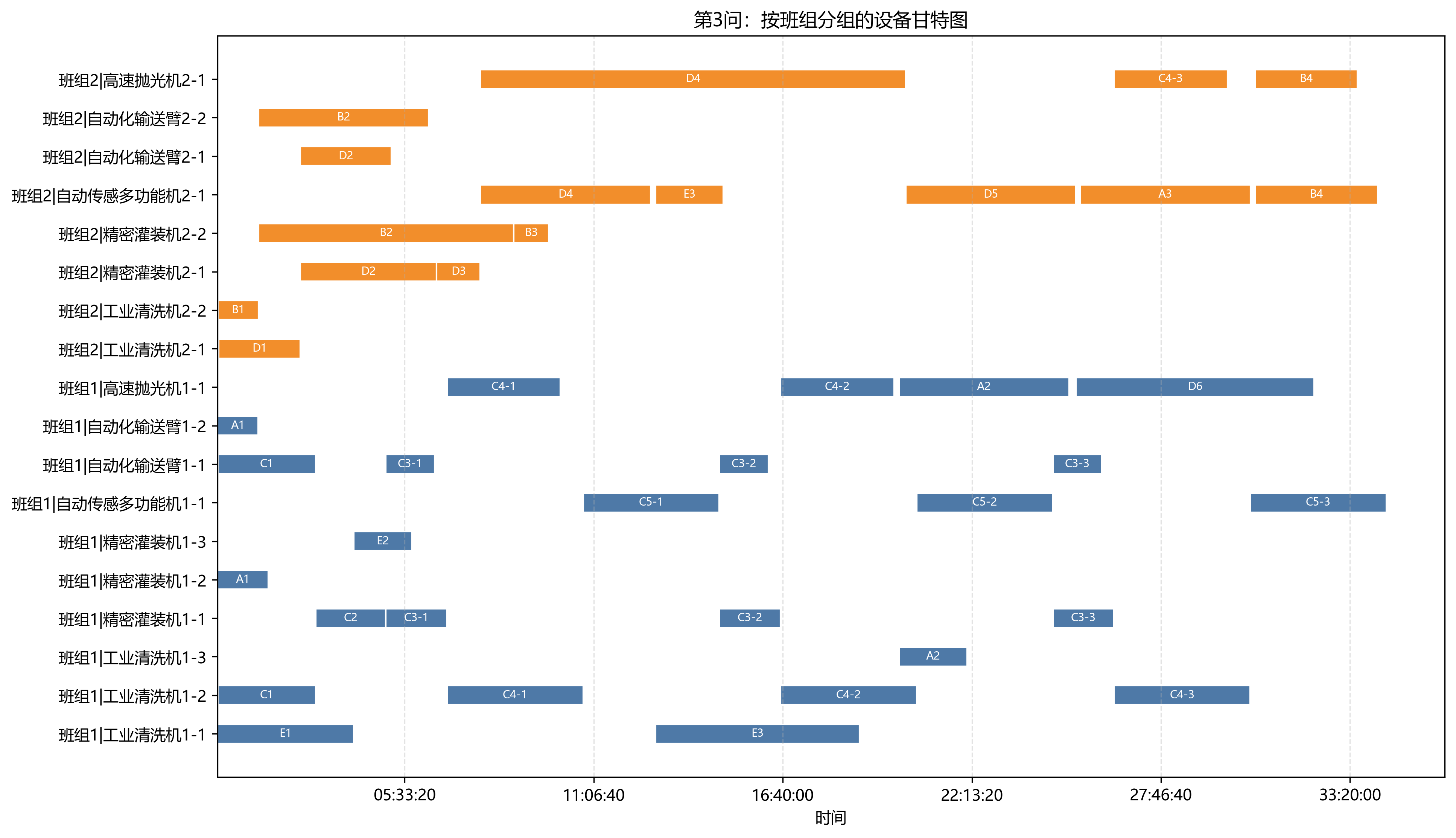
图中每一行是一台设备,横向条块代表设备在某工序的工作区间,颜色对应不同车间。相比只输出总工期,甘特图更易暴露设备瓶颈、车间等待与跨车间切换带来的空档。
⚙️ 模型逐层升级
\n本项目完成了前3问的求解与输出。第4问涉及设备购置决策,当前目录中无 result_question4/
| 阶段 | 问题抽象 | 项目中的处理方式 |
|---|---|---|
| 第 1 问 | 班组 1 独立完成 A 车间,工序链为 | 固定顺序下最早开工,得到解析最优调度 |
| 第 2 问 | 班组 1 完成 A-E 五个车间,存在设备竞争和跨车间运输 | 贪心构造 + 随机扰动 + 局部搜索 |
| 第 3 问 | 班组 1、2 共同完成 A-E 五个车间,设备池扩大且初始位置不同 | 双班组 GA + 贪心解码 + 局部搜索 |
| 第 4 问 | 预算约束下的设备购置 + 调度联合优化 | 当前目录未发现结果文件,本文不写具体数值 |
第2问和第3问均未声明“已证明全局最优”,输出的是当前最好可行解。博客中只按“启发式当前最好可行解”表述。
\n\n数学模型设计
\n设车间集合为 W = {A, B, C, D, E},车间 w 内有序工序集合为 Iw。设备集合为 E,设备类型集合为 K。若工序 i 需要设备类型 k,则记 k ∈ Ki。第3问中还需班组集合 G = {1, 2},设备 e 属于班组 g(e)。
\n关键参数包括:工程量 qi、效率 vik、距离 duv、设备速度 se。加工时间按“精确到秒且向上取整”处理:pik = ⌈ qi / vik × 3600 ⌉
运输时间同理:τeuv = ⌈ duv / se ⌉
这两个公式对应代码中的 compute_processing_time()compute_travel_time()
决策变量:工序开始时间 Si、同步完工时间 Ci、设备分配 xie、设备顺序 yije、总工期 Cmax。若做启发式求解,编码层面不直接搜索所有变量,而是搜索“车间释放序列”,解码器根据序列逐步选择下一道可排工序并分配设备。
\n目标函数:最小化所有车间最后一道工序的最大完工时间:min Cmax
在实现中,makespan
关键约束:
\n- \n
- 车间内工序顺序固定:
Sir+1 ≥ Cir\n - 每道工序必须选择一台对应类型设备:
∑e∈Ek xie = 1\n - 设备唯一占用与跨车间运输:若设备 e 先做工序 i 再做 j,则
Sj ≥ Cie + τe,w(i),w(j)\n - 多设备同步完工:
Ci = maxk∈Ki, e∈Ek: xie=1 {Si + pik}\n
代码工程结构
\n第1、2问在根目录下分别有 question1_solver.pyquestion2_solver.py
question3_project/
├─ main.py
├─ config.py
├─ data_loader.py
├─ entities.py
├─ preprocess.py
├─ time_utils.py
├─ decoder.py
├─ exact_solver.py
├─ heuristic_solver.py
├─ local_search.py
├─ validator.py
├─ reporter.py
├─ visualization.py
├─ io_utils.py
├─ logger_utils.py
├─ requirements.txt
└─ README.md各模块职责清晰:
\n- \n
data_loader.py\npreprocess.py\ndecoder.py\nheuristic_solver.pylocal_search.py\nvalidator.py\nvisualization.py\nreporter.py\n
这种拆分的好处是:调度逻辑、结果校验和图表输出互不缠绕。后续做第4问购置决策时,只需在设备池生成阶段加入新增设备变量,无需重写可视化和校验链路。
\n\n关键代码片段解析
\n6.1 时间计算:统一成秒
\n来自 question3_project/time_utils.py
def compute_processing_time(quantity: float, efficiency: float) -> int:
if efficiency <= 0:
raise ValueError(f"设备效率必须为正数,当前为:{efficiency}")
return int(math.ceil(quantity / efficiency * 3600))
def compute_travel_time(distance_m: float, speed_mps: float) -> int:
if speed_mps <= 0:
raise ValueError(f"设备移动速度必须为正数,当前为:{speed_mps}")
return int(math.ceil(distance_m / speed_mps))这段代码对应题目“小时、米、秒”和“向上取整”的要求,所有后续调度只处理秒,避免单位换算。\n\n
6.2 构建设备池与候选映射
\n来自 question3_project/preprocess.py
def build_devices(team_df: pd.DataFrame) -> tuple[dict[str, Device], dict[str, list[str]]]:
devices: dict[str, Device] = {}
candidates_by_type: dict[str, list[str]] = {}
for _, row in team_df.iterrows():
device = Device(
device_id=str(row["设备编号"]),
equipment_type=str(row["设备类型"]),
team=str(row["班组"]),
speed_mps=float(row["移动速度(m/s)"]),
unit_price=float(row["设备单价(元/台)"]),
)
devices[device.device_id] = device
candidates_by_type.setdefault(device.equipment_type, []).append(device.device_id)
for key in candidates_by_type:
candidates_by_type[key] = sorted(candidates_by_type[key])
return devices, candidates_by_type第3问设备来自两个班组,代码将设备编号、类型、所属班组和速度统一封装成
Device6.3 展开重复工序与多设备需求
\n来自 question3_project/preprocess.py
for _, row in group.iterrows():
equipment_type = str(row["设备类型"])
if equipment_type not in candidates_by_type:
raise ValueError(f"两个班组中均没有工序 {base_process_id} 所需设备类型:{equipment_type}")
requirements.append(
Requirement(
equipment_type=equipment_type,
efficiency=float(row["效率(m3/h)"]),
duration_s=int(row["加工时长(s)"]),
)
)附件中一道工序可能对应多种设备类型,代码将其统一变成
Requirement6.4 设备分配:枚举候选组合
\n来自 question3_project/decoder.py
candidate_lists = [candidates_by_type[req.equipment_type] for req in op.requirements]
evaluated = []
for combo in product(*candidate_lists):
if len(set(combo)) < len(combo):
continue
assignments = []
ready_times = []
total_travel = 0
for req, device_id in zip(op.requirements, combo):
device = devices[device_id]
from_pos = device_location[device_id]
travel_s = travel_for_device(device, from_pos, op.workshop, distance_df)
ready_s = device_available[device_id] + travel_s
ready_times.append(ready_s)
total_travel += travel_s
assignments.append(
{
"requirement": req,
"device_id": device_id,
"team": device.team,
"from_pos": from_pos,
"to_pos": op.workshop,
"travel_s": int(travel_s),
"ready_s": int(ready_s),
}
)
start_s = max([workshop_ready] + ready_times)
completion_s = max(start_s + item["requirement"].duration_s for item in assignments)
team_balance = len(set(item["team"] for item in assignments))
evaluated.append((completion_s, start_s, total_travel, -team_balance, combo, assignments))这是解码器的核心:对工序所需设备类型做笛卡尔积,枚举候选组合;计算每台设备从当前位置到目标车间的运输时间;用最晚就绪时间作为工序开始时间,用最大结束时间作为同步完工时间。排序关键字包含
completion_sstart_stotal_travelteam_balance6.5 解码序列:车间释放顺序
\n来自 question3_project/decoder.py
workshop_ready = {w: 0 for w in operations_by_workshop}
device_available = {device_id: 0 for device_id in devices}
device_location = {device_id: initial_location(device) for device_id, device in devices.items()}
next_index = {w: 0 for w in operations_by_workshop}
def schedule_next(workshop: str) -> bool:
if workshop not in operations_by_workshop or next_index[workshop] >= len(operations_by_workshop[workshop]):
return False
op = operations_by_workshop[workshop][next_index[workshop]]
start_s, completion_s, assignments = select_assignment(
op, workshop_ready[workshop], device_available, device_location,
candidates_by_type, devices, distance_df, random_tie=random_tie
)
commit_operation(
op, start_s, completion_s, assignments, workshop_ready, device_available,
device_location, records, process_records, routes, operation_times, devices
)
next_index[workshop] += 1
return True编码层只关心“下一次尝试释放哪个车间的一道工序”,真正的开始时间、设备选择、运输时间和同步完工都在解码器中算出。搜索空间比直接枚举设备排序小得多。\n\n
6.6 局部搜索:扰动序列
\n来自 question3_project/local_search.py
def mutate_sequence(sequence: list[str], rng: random.Random) -> list[str]:
candidate = sequence[:]
if len(candidate) < 2:
return candidate
op = rng.choice(["swap", "insert", "reverse"])
i, j = sorted(rng.sample(range(len(candidate)), 2))
if op == "swap":
candidate[i], candidate[j] = candidate[j], candidate[i]
elif op == "insert":
item = candidate.pop(j)
candidate.insert(i, item)
else:
candidate[i : j + 1] = reversed(candidate[i : j + 1])
return candidate局部搜索不直接修改设备开始时间(易破坏可行性),只扰动车间序列,再交给解码器重新生成调度。可行性压力集中在解码器和校验器,搜索逻辑更轻。\n\n
6.7 自动校验
\n来自 question3_project/validator.py
for device_id, group in raw.sort_values(["设备编号", "起始秒"]).groupby("设备编号"):
device = devices[device_id]
prev = None
for _, row in group.iterrows():
if prev is None:
required_travel = travel_for_device(device, device.team, row["所属车间"], distance_df)
if int(row["起始秒"]) < required_travel:
errors.append(f"设备 {device_id} 首次从{device.team}到{row['所属车间']}的运输时间未计入。")
else:
required_travel = travel_for_device(device, prev["所属车间"], row["所属车间"], distance_df)
if int(row["起始秒"]) < int(prev["结束秒"]) + required_travel:
errors.append(f"设备 {device_id} 从{prev['所属车间']}到{row['所属车间']}运输时间不足。")
prev = row检查同一设备连续作业间是否留足运输时间。调度题最怕“结果看起来排满,但设备瞬移了”。项目将校验报告作为正式输出,三问日志均显示校验通过。\n\n
6.8 可视化:甘特图
\n来自 question3_project/visualization.py
def plot_gantt_global(result: SolutionSummary) -> plt.Figure:
setup_chinese_font()
df = pd.DataFrame(result.records).sort_values(["设备编号", "起始秒"])
devices = list(df["设备编号"].drop_duplicates())
y_map = {device: idx for idx, device in enumerate(devices)}
fig, ax = plt.subplots(figsize=(13, max(5, 0.32 * len(devices) + 1.8)))
for _, row in df.iterrows():
y = y_map[row["设备编号"]]
ax.barh(y, row["持续工作时间(s)"], left=row["起始秒"], height=0.5,
color=WORKSHOP_COLORS.get(row["所属车间"], "#999999"), edgecolor="white", label=row["所属车间"])
ax.text(row["起始秒"] + row["持续工作时间(s)"] / 2, y, row["工序编号"], ha="center", va="center", fontsize=7, color="white")甘特图不仅是美化工具,更是诊断工具,用于反查瓶颈设备、空闲间隙、车间完工顺序和异常等待。\n\n
结果图表复盘
\n7.1 第1问:单车间固定链
\n



第1问只有A车间,工序链固定为 A1 -> A2 -> A341600 s = 11:33:2001:33:2006:33:2011:33:20高速抛光机1-1自动传感多功能机1-143.27%
7.2 第2问:单班组多车间
\n






第2问只使用班组1设备完成五个车间。最终总工期为 170970 s = 47:29:30高速抛光机1-1135000 s78.96%自动传感多功能机1-1117360 s68.64%9210 s5.39%C -> BD -> C班组1 -> D961229040 s170970 s58070 s25.35%
7.3 第3问:双班组协同
\n






%%PROTECTED
A1 -> A2 -> A3


 浙公网安备 33010602011771号
浙公网安备 33010602011771号