在语音识别、声纹分析和工业异音检测等领域,MFCC(梅尔频率倒谱系数) 是应用最广泛的特征提取方法之一。它并非简单的频谱变换,而是一套融合了听觉感知模型与统计压缩思想的谱包络表达技术。本文将从工程实践出发,系统梳理 MFCC 的完整数学流程、每一步的物理意义,并通过 Python 仿真展示其在真实场景中的效果。
一、为什么不能直接使用频谱?
设离散时间信号为:,其 N 点离散傅里叶变换为:
,功率谱为:
。频谱虽然包含完整的频率信息,但在工程建模中面临几个关键问题:
- 维度爆炸:原始频谱维度高,直接作为特征会引入大量冗余信息,增加计算开销。
- 强相关性:相邻频率分量高度相关,不利于后续分类器或神经网络的学习。
- 动态范围大:信号能量在不同频段差异显著,直接使用会掩盖细微结构。
- 不符合听觉特性:线性频率刻度与人耳的非线性感知不匹配,低频细节容易被淹没。
因此,我们需要对频谱进行结构化压缩,MFCC 正是为此而生。在 Python、Java、C++ 等编程语言中,MFCC 提取库均有成熟实现,例如 Python 的 librosa 和 Java 的 TarsosDSP,方便开发者快速集成。
二、短时分帧与窗函数
语音或机械声信号在短时间内近似平稳,因此采用短时分析。对信号分帧:,其中 m 为帧索引,R 为帧移,w[n] 为窗函数。常用 Hann 窗:
。
实践建议:帧长通常设为 20-30ms,帧移为 10ms。在 Go 或 Rust 等高性能语言中实现时,需注意窗函数的预计算缓存,避免重复运算。
三、短时功率谱计算
对每一帧信号分别计算 FFT:,得到该帧的功率谱:
。这里得到的是每帧的 periodogram,它不同于 Welch 方法中的多帧平均 PSD:
。其中 N 是每段 FFT 点数,fs 是采样率,U 是窗函数功率归一化因子,M 是分段数。MFCC 不做跨帧平均,因为它本身就是短时特征。
四、Mel 频率尺度与滤波器组
人耳对频率的感知是非线性的。Mel 频率定义为:,反变换为:
。该变换在低频保持较高分辨率,在高频逐渐压缩。构造 M 个三角滤波器:
,对功率谱做带通积分:
。这一步将频谱压缩为若干频带能量。
⚠️ 注意:在 JavaScript 或 TypeScript 的前端音频处理中,可以使用 Web Audio API 的 BiquadFilterNode 模拟 Mel 滤波器组,但精度有限,建议后端处理。
五、对数压缩与 DCT 变换
对频带能量取对数:。对数的作用:
- 模拟响度感知
- 压缩动态范围
- 将乘性关系转为加性关系
接着对 log-Mel 能量做 DCT:。DCT 是正交变换,其矩阵满足:
。作用包括去相关、能量集中、维度降低。通常只保留前 12~13 个系数。
DCT 通过把平滑的频带能量曲线分解为一组余弦模式,使特征在新坐标系中更加独立且能量集中于低阶系数,从而既近似去相关,又为后续截断降维提供依据。
之所以可以这样做,是因为 log-Mel 频带能量之间通常存在强烈的局部相关性(因为三角滤波器是重叠的,相邻频带能量非常接近),其协方差矩阵往往近似只与频带间“距离”有关,呈现近似 Toeplitz 结构;而这类矩阵的特征向量在理论上接近正弦/余弦基函数,因此用固定的 DCT 基函数即可近似完成协方差的对角化,而无需显式计算协方差矩阵或做 PCA。
MFCC 的整体表达式为:。
六、实际工程中的使用方式
每一帧得到一个 MFCC 向量:,一段信号形成特征矩阵:
。不同任务的处理方式:
- 序列建模(HMM、RNN、Transformer):使用完整 MFCC 时间序列
- CNN 方法:将 MFCC 矩阵视为二维特征图
- 传统分类(SVM 等):对序列做统计汇总
七、仿真展示:Python 实现
为了直观展示 MFCC 的特征形态,下面使用 Python 进行仿真。构造一段合成信号,使其具备一定的复杂度。随后计算其 Mel 频谱与 MFCC,并通过可视化观察特征随时间的变化。
代码中主要步骤包括:构造仿真信号、计算 Mel 频谱(频带能量表示)、计算 MFCC(倒谱形状参数)、绘制波形、Mel 频谱和 MFCC 结果。
import numpy as np
import matplotlib.pyplot as plt
import librosa
import librosa.display
from scipy.signal import butter, lfilter
# 1) 构造信号
fs = 16000
dur = 3.0
t = np.linspace(0, dur, int(fs*dur), endpoint=False)
# (1) 基频 + 谐波
f0 = 150
harmonics = sum((1/k)*np.sin(2*np.pi*f0*k*t) for k in range(1,6))
# (2) 共振峰
def bandpass(sig, low, high, fs):
b,a = butter(4, [low/(fs/2), high/(fs/2)], btype='band')
return lfilter(b,a,sig)
res1 = bandpass(np.random.randn(len(t)), 400, 800, fs)
res2 = bandpass(np.random.randn(len(t)), 1500, 2500, fs)
# (3) 调幅
am = 0.6*(1 + 0.8*np.sin(2*np.pi*3*t))
harmonics = harmonics * am
# (4) 宽带噪声
noise = 0.05*np.random.randn(len(t))
# (5) 瞬态冲击
impulse = np.zeros_like(t)
impulse[int(fs*1.5)] = 3
# 合成
x = harmonics + 0.5*res1 + 0.3*res2 + noise + impulse
# 归一化
x = x / np.max(np.abs(x))
# 2) 参数
n_fft = 1024
hop = 256
n_mels = 64
n_mfcc = 20
# 3) 计算 Mel & MFCC
mel = librosa.feature.melspectrogram(
y=x, sr=fs, n_fft=n_fft,
hop_length=hop, n_mels=n_mels
)
mel_db = librosa.power_to_db(mel, ref=np.max)
mfcc = librosa.feature.mfcc(
y=x, sr=fs, n_mfcc=n_mfcc,
n_fft=n_fft, hop_length=hop,
n_mels=n_mels
)
# 4) 可视化
plt.figure()
plt.plot(np.arange(len(x))/fs, x)
plt.title("Waveform (Complex Synthetic Signal)")
plt.xlabel("Time (s)")
plt.tight_layout()
plt.show()
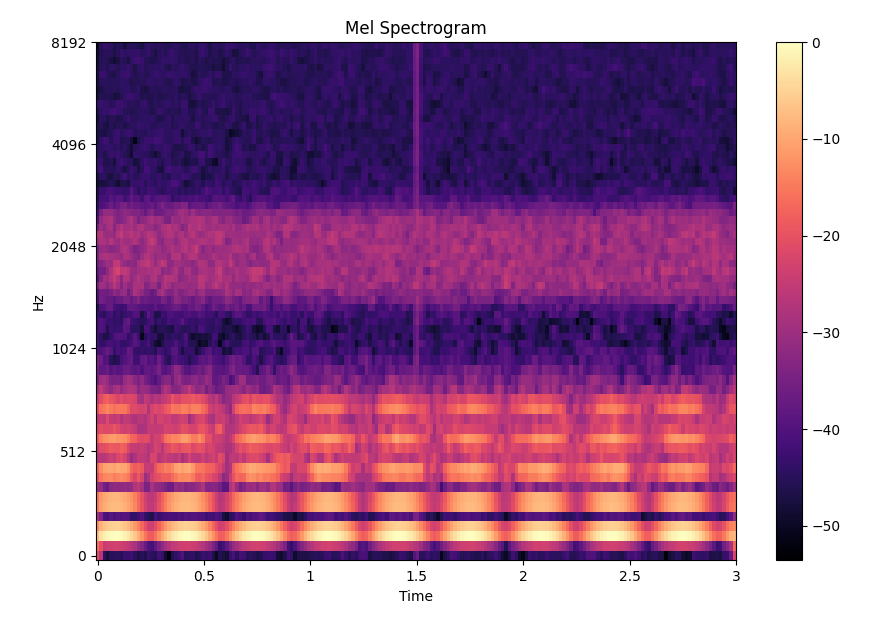
plt.figure()
librosa.display.specshow(mel_db, sr=fs,
hop_length=hop,
x_axis='time',
y_axis='mel')
plt.title("Mel Spectrogram")
plt.colorbar()
plt.tight_layout()
plt.show()
plt.figure()
librosa.display.specshow(
mfcc,
sr=fs,
hop_length=hop,
x_axis='time'
)
plt.title("MFCC")
plt.colorbar()
plt.tight_layout()
plt.show()结果展示: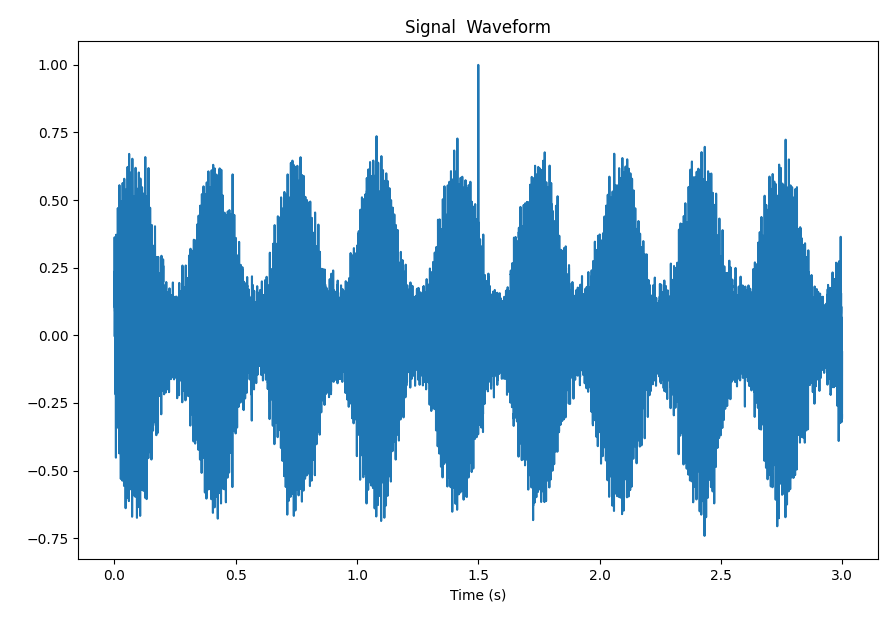
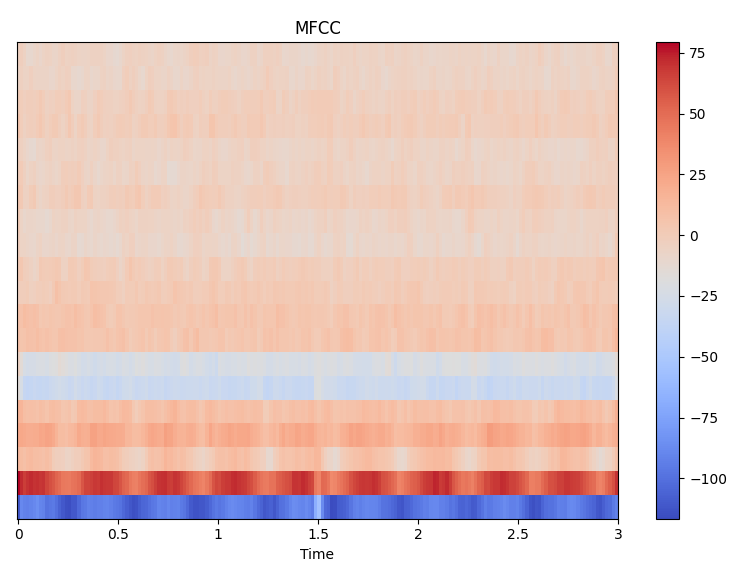
延伸思考:在 C++ 或 Go 中实现时,建议使用 fftw 或 go-dsp 库,并注意 Mel 滤波器组矩阵的预计算,可提升 5-10 倍性能。
八、总结
MFCC 实际完成了四个核心操作:频率轴非线性压缩、幅值对数压缩、正交去相关、维度降低。在语音识别中效果稳定;在机械声纹分析中也可使用,但需要根据频率范围调整 Mel 滤波器数量与参数。
本文从短时频谱到 Mel 频带压缩,再到对数变换与 DCT 展开,系统介绍了 MFCC 的基本原理和处理流程。它并不是简单的频率特征,而是一组描述谱形状的倒谱系数,能够在保留主要结构信息的同时有效降低维度。在后续内容中,我将基于真实声纹数据提取 MFCC 特征,并构建一个简单的声纹识别分析流程,看看它在实际场景中的效果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号