在计算机系统的核心,一个精妙的设计平衡着速度、容量与成本——存储器层次结构。它不仅是硬件工程师的杰作,更是每一位追求极致性能的程序员必须理解的核心架构。尤其在云原生和分布式计算时代,理解数据如何在从CPU寄存器到远程云存储的漫长路径中流动,对于设计高性能、可扩展的应用至关重要。本文将带你深入这一“存储金字塔”,揭示其工作原理及对现代软件开发的深远影响。
一、 存储金字塔:速度、容量与成本的精妙权衡
计算机存储并非简单的设备堆砌,而是一个层次分明、协同工作的有机体系,常被形象地称为“存储金字塔”。这个体系的核心矛盾在于:我们既需要闪电般的访问速度(如CPU运算),又需要海量的数据存储空间(如保存大量文件),同时还要控制成本。单一的存储技术无法同时满足这三个要求。
于是,工程师们采用了分层策略:将不同特性的存储设备组织成一个层次结构。越靠近金字塔顶端的设备,速度越快,但每字节的成本越高,容量也越小;反之,越靠近底层的设备,速度越慢,但成本越低,容量近乎无限。这种设计在系统层面实现了成本与性能的最佳平衡。
让我们通过下面这张经典的层次结构图来直观感受这一变化趋势:
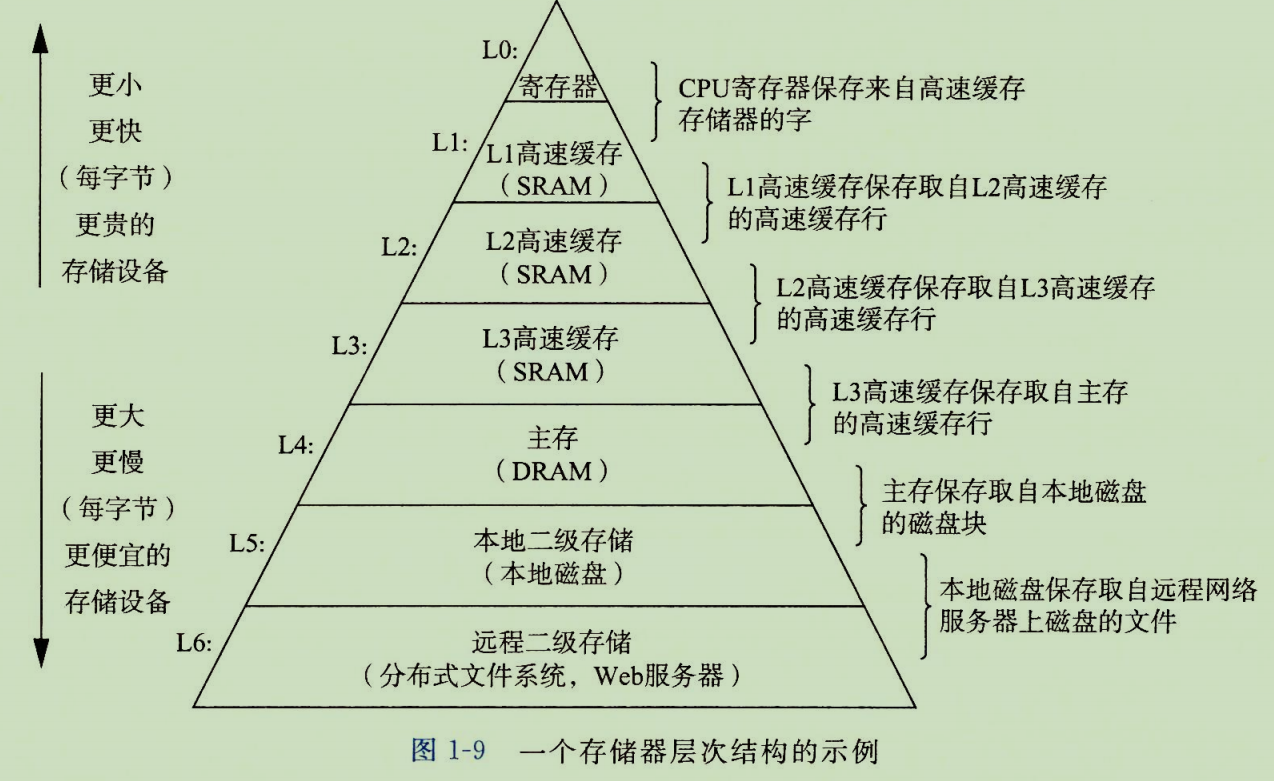
如图所示,一个典型的现代存储层次结构包含以下关键层级:
- L0 - 寄存器:位于CPU内部,速度极快(纳秒级),容量极小(通常为KB级),用于存储当前正在执行的指令和操作数。
- L1-L3 - 高速缓存:由静态随机存取存储器构成,位于CPU芯片上或紧邻芯片。L1缓存速度最快,容量最小;L3缓存容量较大(可达数十MB),是核心间共享的缓存。
- L4 - 主存:即我们常说的内存,由动态随机存取存储器构成。速度比缓存慢一个数量级,但容量大得多(现代计算机通常为GB到TB级),是程序运行的主要舞台。
- L5 - 本地二级存储:主要指机械硬盘或固态硬盘。速度远慢于内存,但提供持久化的大容量存储(TB级),用于存放操作系统、应用程序和用户文件。
- L6 - 远程二级存储:在当今的云时代,这一层变得无比重要。它包括网络附加存储、分布式文件系统(如HDFS)以及各类对象存储服务(如AWS S3)。其访问速度受网络延迟支配,但理论上容量可以无限扩展。
理解这个金字塔,是进行任何系统性能调优或云架构设计的起点。[AFFILIATE_SLOT_1]
二、 缓存思想:层次结构高效运转的核心引擎
如果层次结构只是设备的简单堆叠,那它毫无意义。其真正的魔力在于贯穿始终的缓存思想。简单来说,上一层的存储设备充当下一层设备的高速缓存。缓存的目标是让最常用的数据尽可能停留在更快、更靠近CPU的层级。
数据在这个金字塔中并非静止不动,而是根据访问频率动态流动:
- 向上复制:当CPU需要某个数据时,系统会尝试从最高层(寄存器)开始查找。如果未命中,则逐层向下查找,最终找到数据后,会将其复制到更高层,以备下次快速访问。
- ⚠️ 向下驱逐:高层存储空间有限。当空间不足时,最近最少使用的数据会被“驱逐”到下一层,为更活跃的数据腾出空间。
这就形成了一条清晰的缓存链:
- 寄存器 → L1高速缓存的缓存
- L1高速缓存 → L2高速缓存的缓存
- L2高速缓存 → L3高速缓存的缓存
- L3高速缓存 → 主存的缓存
- 主存 → 本地磁盘的缓存
- (在云/网络系统中)本地磁盘 → 远程云存储的缓存
最后一点在云原生应用中尤为关键。在进行云迁移或设计云原生应用时,我们可以将本地SSD视为云对象存储的缓存,从而在享受云端无限存储容量的同时,通过本地缓存保障热点数据的访问性能。
三、 程序员的必修课:利用局部性原理榨干硬件性能
为什么程序员需要深入理解存储层次结构?答案很简单:性能差距是数量级的。从寄存器读取数据比从内存快100倍,比从磁盘快1000万倍!程序的运行效率不仅取决于算法复杂度,更取决于数据在层次结构中的移动效率。
优化的核心在于遵循数据局部性原理:
- 时间局部性:如果某个数据被访问,那么它在不久的将来很可能再次被访问。循环变量就是典型例子。
- 空间局部性:如果某个存储位置被访问,那么它附近的位置也可能很快被访问。顺序访问数组元素体现了这一点。
编写具有良好局部性的代码,能让CPU和缓存预测你的数据访问模式,从而让所需数据长期驻留在高速缓存中。例如,遍历二维数组时,按“行优先”顺序(在C/C++、Python中)访问比“列优先”顺序能更好地利用空间局部性,因为相邻行元素在内存中是连续存储的。
在云平台上进行云部署时,这一原理同样适用。设计微服务时,应考虑将频繁交互的数据和服务部署在同一个可用区,甚至同一台物理主机附近,以减少网络跳转,这本质上是将“空间局部性”思想扩展到了网络层面。
四、 从本地到云端:现代存储架构的演进与实践建议
传统的存储金字塔在云计算时代得到了延伸和重塑。本地磁盘的角色发生了变化,它不仅是主存的缓存,在许多场景下,更是整个云端数据湖或数据库的高速缓存层。
例如,在大数据分析中,计算节点通常会配备本地NVMe SSD。这些SSD用于缓存从远端HDFS或S3读取的热点数据块,当任务需要重复读取相同数据时,就能从本地SSD快速获取,避免了昂贵的网络传输和远程存储的I/O延迟。这种“计算存储分离+本地缓存”的架构,是当今主流云服务(如AWS EMR, Databricks)实现高性能分析的基础。
对于开发者,以下实践建议可以帮助你更好地驾驭存储层次结构:
- 量化性能差距:使用性能分析工具,了解你的程序在L1缓存命中、缓存未命中、缺页异常(访问磁盘)等不同情况下的耗时差异。
- 优化数据结构与算法:选择缓存友好的数据结构和访问模式。例如,在可能的情况下使用数组而非链表,因为数组具有更好的空间局部性。
- 利用云服务的缓存特性:在选用云平台的存储云服务时,了解其提供的缓存机制。例如,使用CDN缓存静态资源,利用Redis或Memcached作为数据库的缓存层。
- 预取与异步I/O:在需要从低速存储读取数据时,使用异步I/O和预取技术,让CPU在等待I/O时能处理其他任务,掩盖访问延迟。
五、 总结与展望
存储器层次结构是计算机系统中一个优雅而强大的抽象,它通过缓存机制巧妙地弥合了处理器高速与存储大容量、低成本之间的鸿沟。从CPU寄存器到全球分布的云存储,每一层都扮演着不可替代的角色。
对程序员而言,深入理解这一结构不再是可选技能,而是编写高性能、高效率代码的必备基础。无论是优化单机程序的缓存命中率,还是设计跨数据中心的分布式云原生应用,其底层逻辑都是相通的:让数据离计算更近,让热点数据流动得更快。随着非易失性内存、计算存储一体化等新技术的发展,存储金字塔的形态可能会继续演变,但其核心思想——在速度、容量和成本间寻求动态平衡——将始终是计算机系统设计的基石。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号