

摘要:我们提出了核心注意力解耦(Core Attention Disaggregation,CAD)技术,该技术借助将核心注意力计算(即softmax(QK^T)V)从模型其余部分解耦出来,并在独立的设备池上执行,从而改进长上下文大型语言模型的训练。在现有系统中,核心注意力计算与其他层共置;当处理长上下文时,与其他组件的近乎线性计算增长相比,其计算量呈二次方增长,这会导致内容并行组和流水线并行组中出现负载不均衡和“拖尾”问题。CAD的实现得益于两个观察结果。最初,核心注意力计算是无状态的:它没有可训练参数,且仅涉及极少的瞬态数据,因此负载均衡问题可简化为计算密集型任务的调度挑战。其次,它是可组合的:现代注意力计算内核在处理任意长度的词元级分片融合批次时,仍能保持高效。CAD将核心注意力计算划分为词元级任务,并将其分配给专用的注意力计算服务器,这些服务器动态地对任务进行重新分批,以在保持内核效率的同时均衡计算负载。我们在名为DistCA的系统中实现了CAD,该系统采用乒乓执行方案,使通信与计算完全重叠,并在注意力计算服务器上执行原地计算以减少内存采用。在512块H200 GPU上,处理上下文长度高达512k词元的任务时,DistCA将端到端训练吞吐量提高了最高达1.35倍,消除了数据并行和流水线并行中的“拖尾”问题,并实现了近乎完美的计算和内存负载均衡。Huggingface链接:Paper page,论文链接:2510.18121
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理任务中的广泛应用,处理长上下文的需求日益增长。
例如,推理任务需要生成长链的思考过程以得出准确答案,而编码代理则需要在多文件存储库上操作。为了支持这些用例,LLMs需要在推理时能够处理100K到1M个标记的上下文。然而,现有的长上下文训练方法面临两大挑战:
计算负载不均衡:在长上下文训练中,自注意力机制的计算量随序列长度的平方增长,而其他部分的计算量近似线性增长。
这种不均衡导致在数据并行和流水线并行中,不同设备上的负载差异显著,形成“拖后腿”问题,影响整体训练效率。内存与通信开销:在长上下文训练中,KV缓存(Key-Value Cache)的大小随序列长度线性增长,导致内存使用不均衡。
同时,现有的上下文并行办法需要在不同设备间传输KV状态,增加了通信开销,进一步降低了训练效率。
研究目的:
本研究旨在解决长上下文LLMs训练中的计算负载不均衡和内存与通信开销问题,提出一种称为核心注意力解聚(Core Attention Disaggregation, CAD)的技术。
具体研究目的包括:
- 改进长上下文LLMs训练效率:通过解聚核心注意力计算,减少计算负载不均衡,提高整体训练吞吐量。
- 降低内存与通信开销:借助优化KV缓存管理和通信模式,减少内存使用不均衡和通信开销。
- 实现可扩展的长上下文训练:帮助在更大规模和更长上下文的场景下进行高效训练,推动LLMs在更多复杂任务中的应用。
研究方法
1. 核心注意力解聚(CAD):
CAD技术依据将核心注意力计算(即无参数的softmax(QK⊤)V计算)从模型的其他部分解聚出来,并安排在一个独立的资源池中进行计算。
这一方法基于两个关键观察:
- 无状态性:核心注意力计算不具备可训练参数,且瞬态状态最小,因此负载均衡问题简化为调度计算密集型任务。
- 可组合性:现代注意力内核能够在任意长度的标记级分片上维持高利用率,支持动态地将核心注意力计算划分为标记级任务,并分发给注意力服务器进行计算。
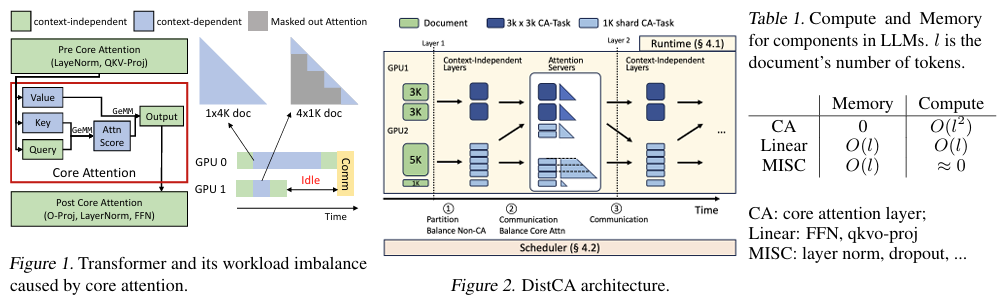
2. 系统实现(DistCA):
为了实现CAD,本研究开发了一个名为DistCA的系统,囊括以下关键组件:
- 运行时系统:负责协调上下文无关层和核心注意力的计算,通过交替执行这两部分计算,并插入必要的通信操作,实现计算与通信的完全重叠。
- 工作负载调度器:根据文档长度和计算负载,动态地将核心注意力任务分配给注意力服务器,确保负载均衡。调度器应用贪心算法,结合通信感知的调度策略,最小化通信开销。
- 内存优化:通过时间共享GPU资源,同时执行上下文无关层和注意力服务器的计算,提高内存利用率。
3. 通信优化:
为了减少通信开销,DistCA采用了以下优化策略:
- 乒乓执行方案:通过交替处理两个纳米批次(nano-batches),达成计算与通信的完全重叠。
- 通信感知的贪心调度:在分配核心注意力任务时,考虑通信开销,优先将任务分配给通信开销较小的注意力服务器。
研究结果
1. 吞吐量提升:
在512块H200 GPU和512K上下文长度的实验条件下,DistCA相比现有平台(如WLB-LLM)达成了高达1.35倍的端到端训练吞吐量提升。
具体来说:
- 3D并行(无流水线并行):在Pretrain素材集上,DistCA完成了1.07到1.20倍的加速;在ProLong数据集上,实现了1.05到1.12倍的加速。
- 4D并行(含流水线并行):在Pretrain数据集上,DistCA对8B模型搭建了1.15到1.30倍的加速,对34B模型建立了1.15倍的加速;在ProLong数据集上,对8B模型实现了1.10到1.35倍的加速,对34B模型实现了1.25倍的加速。
2. 负载均衡:
DistCA通过动态调度核心注意力任务,实现了近乎完美的负载均衡。
实验结果显示,在不同规模的GPU集群和上下文长度下,DistCA均能保持各注意力服务器间的负载均衡,避免了因计算负载不均衡导致的性能下降。
3. 通信开销隐藏:
通过乒乓执行方案和通信感知的贪心调度策略,DistCA成功地将通信开销完全隐藏在计算过程中。
实验结果显示,在大多数情况下,通信开销对整体训练时间的影响可能忽略不计。
研究局限
1. 内存碎片化:
在34B模型的4D并行实验中,由于核心注意力处理不同形状的请求,导致内存分配器反复创建和释放不同大小的内存块,引发内存碎片化问题。这增加了CPU开销,延迟了GPU内核启动,影响了整体性能。
2. 调度器容忍度因子选择:
调度器中的容忍度因子用于在负载均衡和通信开销之间进行权衡。
然而,实验结果显示,容忍度因子的选择对性能有一定影响。在某些情况下,不恰当的容忍度因子选择可能导致负载不均衡或通信开销增加。
3. 任务分片灵活性:
当前搭建中,每个核心注意力任务(CA-task)被定义为查询分片及其上下文键值分片的计算。
然而,这种定义限制了任务的灵活性。允许CA-task运用查询分片的一个子范围及其对应的键值分片,可能会进一步提高调度的灵活性和性能。
未来研究方向
1. 静态内存分配与CUDA图:
针对内存碎片化问题,未来工作行考虑使用静态内存分配和CUDA图来优化内存使用,减少CPU开销,提高GPU内核启动效率。
2. 更精确的通信成本建模:
当前调度器在估计通信成本时,假设所有标记都需要传输,并忽略了目标设备上已存在的KV状态。未来工作可能开发更精确的通信成本模型,考虑KV状态的局部性,进一步优化任务分配策略。
3. 更灵活的任务分片策略:
探索更灵活的任务分片策略,允许CA-task使用查询分片的一个子范围及其对应的键值分片。
这可能会提高调度的灵活性和性能,尤其是在处理长文档时。
4. 扩展至其他模型架构:
虽然本研究关键关注Transformer架构的LLMs,但CAD工艺具有通用性,允许扩展至其他模型架构(如混合专家模型MoE)。
未来工作可以探索CAD在不同模型架构中的应用,进一步验证其有效性和可扩展性。
5. 集成至推理系统:
虽然本研究主要关注训练阶段,但CAD技术也可以应用于推理阶段,尤其是长上下文推理任务。
通过未来工作能够考虑将CAD集成至推理平台,提高长上下文推理的效率和性能。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号