

学习框架、算法和模型的关系

在训练数据上很完美,在没见过的数据上表现很差的现象,叫做过拟合
在没见过的数据上的表现能力叫做泛化能力
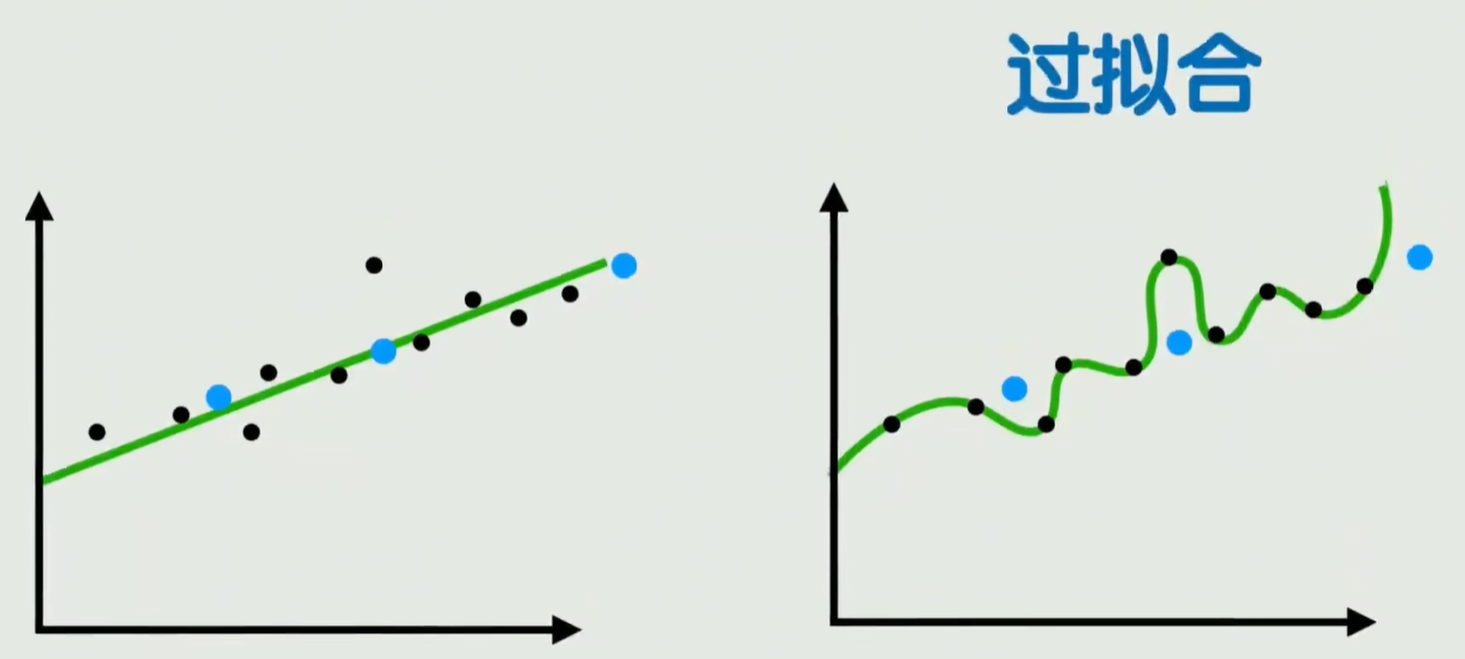
过拟合可能缘于,模型太复杂了,把噪声何随机波动也学会了,该时候就需要简化模型复杂度,与之相对的是增加模型训练数据的量
十分类为例学习:
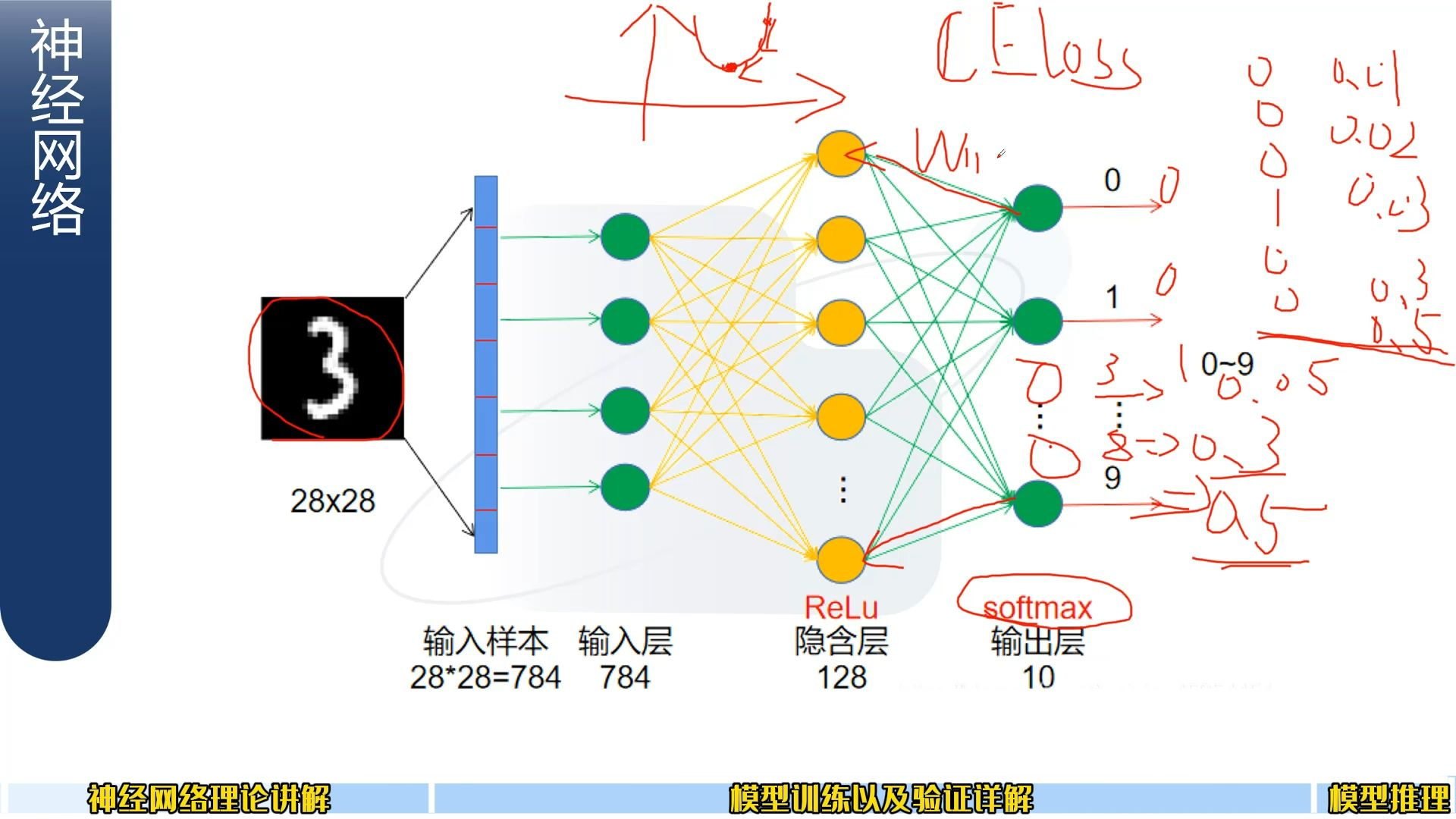
(神经元之间是 权重、相乘、相加)
最后有10个输出的神经元
深度学习模型训练的核心流程
用交叉熵损失衡量误差→通过反向传播找到参数对误差的影响(梯度)→用梯度下降不断调整参数,最终让误差降到最低(找到最优解)的完整优化逻辑~
损失值(LOSS)——图中的那个函数
“LOSS” 就是 “损失函数(Loss Function)” 的简称,在训练中通常用 “损失值(Loss Value)” 来指代损失函数的计算结果。
U 型,它的形态取决于模型结构、数据分布和任务类型,差异很大。就是波形不一定
反向传播:
利用损失函数(CELOSS交叉熵损失,计算他们的误差),波形图中的点(不好),想要优化一下,使梯度下降,让他不断下降,随后求到一个极值(最优解)
CELOSS是分类任务中常用的损失函数,它的核心作用是量化模型预测结果与真实标签之间的误差。
反向传播是实现 “误差回传” 的算法:
- 当模型输出的预测结果误差较大(即损失函数值高,对应你说的 “波形图中的点(不好)”),反向传播会从损失函数出发,沿着网络层反向计算每个参数(权重、偏置)对损失的 “贡献度”(即梯度)。
- 简单说,就是找到 “哪些参数导致了误差” 以及 “影响程度有多大”
得到参数的梯度后,就允许用梯度下降法进行优化:
通过反向传播找到参数对误差的影响是(梯度)
梯度的方向指示了 “损失函数上升最快的方向”,因此我们会沿着梯度的反方向更新参数(即 “梯度下降”),从而让损失函数值不断减小。
把(神经元之间 权重)参数Wx更新,最后得到一个最优的参数,使得损失最小——前面这个管理是通过模型训练得到的
末了会得到一个概率值,就是大家要的。
隐藏层:
让模型拟合一些非线性(为模型引入非线性),增加模型的表达能力,来拟合更多的情况
通过“增加非线性以提升表达能力” 是最核心的作用,具体能够拆分为两点:
- 引入非线性:深度学习模型的基础是线性变换(如
y = wx + b),单纯叠加线性层无法拟合复杂的非线性数据(比如图像、语音)。ReLu 通过 “截断负数值” 的操作,让模型整体具备了非线性拟合能力。- 缓解梯度消失:在传统激活函数(如 Sigmoid)中,输入值过大或过小时梯度会趋近于 0,导致深层模型训练困难。ReLu 在 x>0 时梯度恒为 1,能有效缓解深层网络的梯度消失问题,让深层模型得以训练。
这里用的是分类中常用的ReLu函数:
当x<0:全为0
当x>0:y=x。
部分复杂的不太好表达,所以用非线性函数,


激活函数来把线性函数盘活,变成了变化能力更强的非线性关系
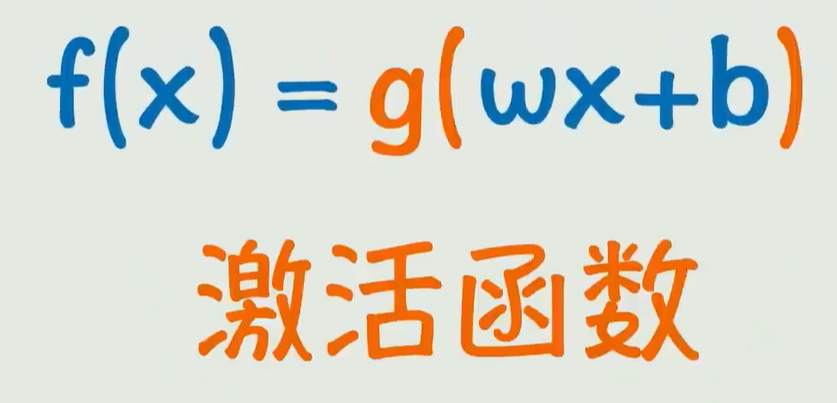
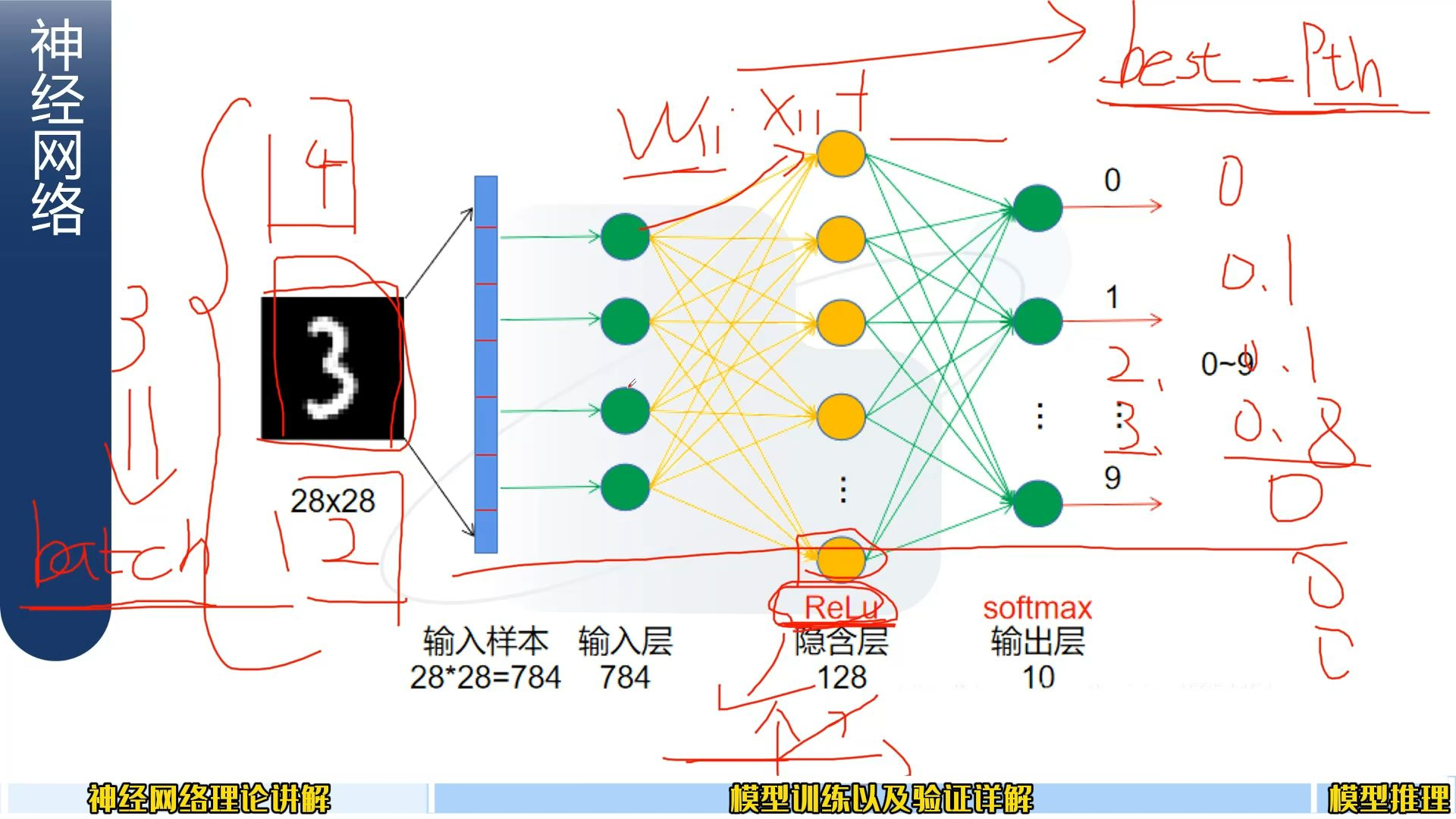
前面取batch:
批处理机制:让模型一次能够塞多个图片进行操作,batch=3;,一次加3个。
将多张图片组成一个 “批次(batch)” 一起输入。就是深度学习中,为了提高计算效率(利用 GPU 并行计算能力)和稳定训练过程,通常不会单张图片输入模型,而
best Pth:
终于存储最佳的权重参数 ,然后大家可以用权重参数进行推理。参数加载到模型后,输入图片,用模型推理出图片属于哪个类别。
模型权重的保存与推理流程。
“best Pth” 指训练过程中保存的 “最佳权重文件”(通常以
.pth为后缀,是 PyTorch 等框架常用的权重格式)。训练时会根据验证集性能(如准确率)选择表现最好的一轮权重保存,避免过拟合的权重被保留。
学习率(用符号
lr表示)(0.1)过高,每次的步子大,会导致收敛过头。本质上是这些参数在更新时由于步长太大而偏离了最优范围。

小一点合适点

什么是模型参数?
以简单的神经网络为例:
- 权重(
weight):连接不同神经元的 “系数”,比如输入层到隐藏层的连接强度,类似线性方程y = wx + b中的w。- 偏置(
bias):每个神经元的 “偏移量”,类似上述方程中的b。随机赋值的,随后会在训练过程中通过反向向传播和梯度下降不断更新,最终收敛到能最小化损失的值。就是这些参数在模型初始化时
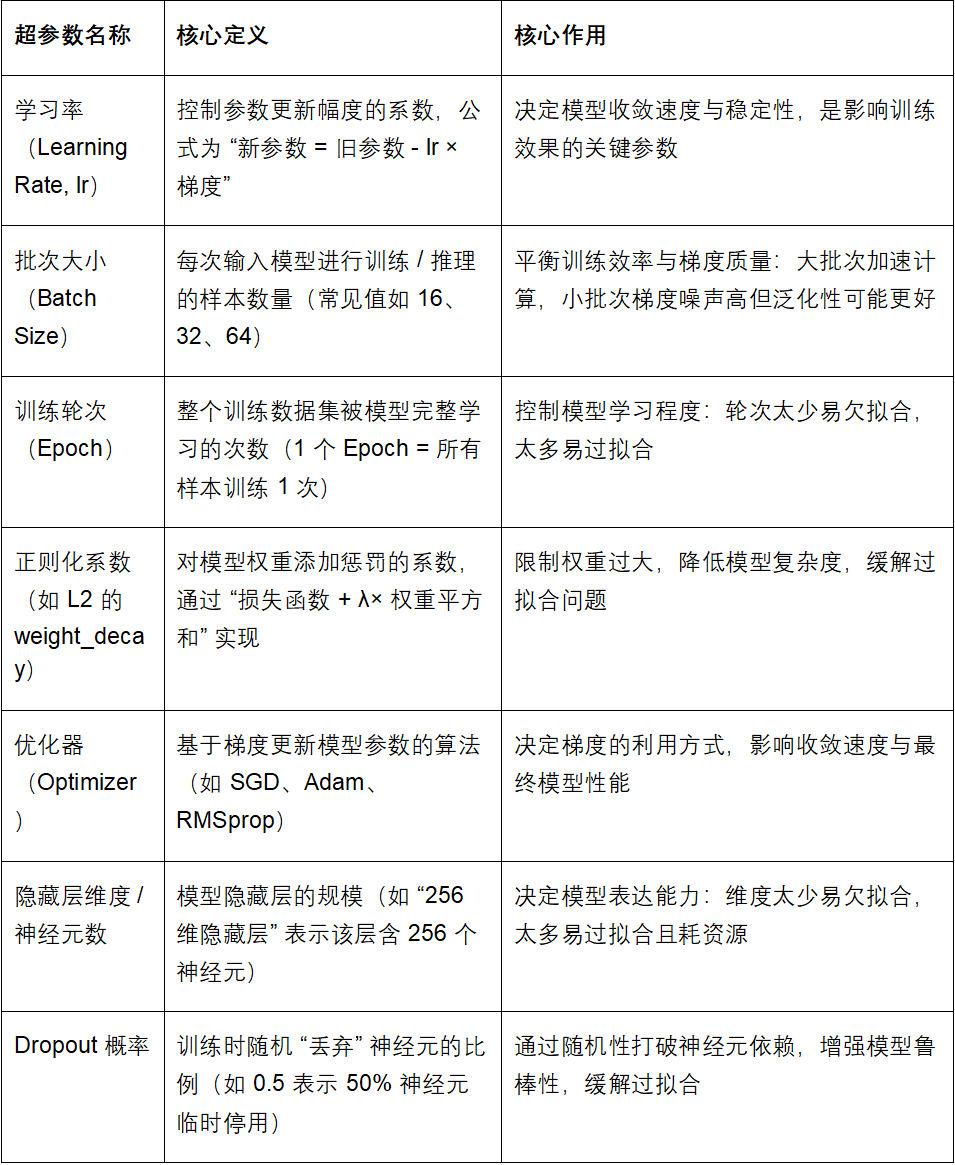
常见参数总结:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号