

一、RNN介绍
(一)RNN概念
循环神经网络(Recurrent Neural Network, RNN)是一种专门处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有“循环”结构,能够处理和记住前面时间步的信息,使其特别适用于时间序列数据或有时序依赖的任务。
什么是序列数据?
时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
(二)RNN应用场景
自然语言处理(NLP):文本生成、语言建模、机器翻译、情感分析等。
时间序列预测:股市预测、气象预测、传感器数据分析等。
语音识别:将语音信号转换为文字。
音乐生成:通过学习音乐的时序模式来生成新乐曲。
(三)自然语言处理概述
自然语言处理(Nature language Processing, NLP)研究的主要是通过计算机算法来理解自然语言。
对于自然语言来说,处理的数据主要就是人类的语言,例如:汉语、英语、法语等,该类型的数据不像我们前面接触过的结构化数据、或者图像数据可以很方便的进行数值化。
NLP的目标是让机器能够“听懂”和“读懂”自然语言,并进行有效的交流和分析。
NLP涵盖了从文本到语音、从语音到文本的各个方面,它涉及多种技术,包括语法分析、语义理解、情感分析、机器翻译等。
二、词嵌入层
将输入的离散单词(通常是词汇表中的索引)转换为连续的、低维的向量表示,从而使得神经网络能够理解和处理这些词汇的语义信息。词嵌入层的作用就是将文本转换为向量,形成低维稠密向量,保持上下文语义

细节:
将文本通过jieba分词等模块进行分词
根据每个词下标值转化成向量
向量 --> 下标 --> 词
(一)词嵌入层的作用
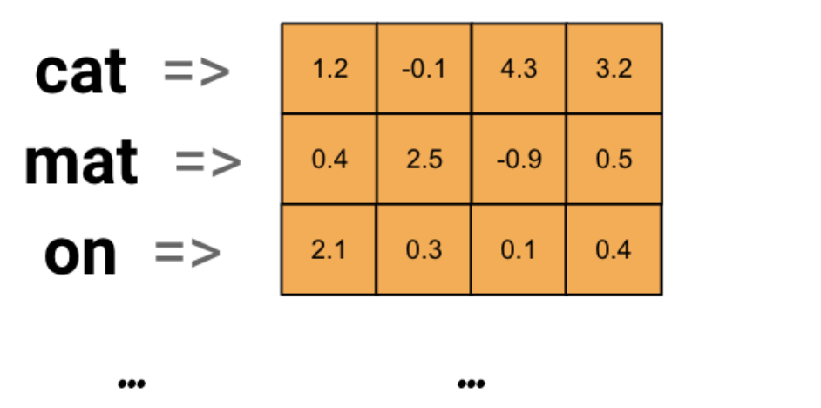
词嵌入层的主要目的是将每个词映射为一个固定长度的向量(将文本转换为向量),这些向量能够捕捉词与词之间的语义关系。
传统的文本表示方法(如one-hot编码)无法反映单词之间的相似性,因为在one-hot编码中,每个单词都被表示为一个高维稀疏向量,而词嵌入通过低维稠密向量表示单词,能够更好地捕捉词汇之间的语义相似性。
词嵌入层首先会根据输入的词的数量构建一个词向量矩阵,例如: 我们有 100 个词,每个词希望转换成 128 维度的向量,那么构建的矩阵形状即为: 100*128,输入的每个词都对应了一个该矩阵中的一个向量。
词嵌入层在RNN中的作用:
输入表示:RNN通常用于处理序列数据。在处理文本时,RNN的输入是由单词构成的序列。由于神经网络不能直接处理离散的单词标识符(如整数索引或字符),因此需要通过词嵌入层将每个单词转换为一个固定长度的稠密向量。这些向量作为RNN的输入,帮助RNN理解词语的语义。
降低维度:词嵌入层将原本高维的稀疏表示(如one-hot编码)转化为低维的稠密向量,减少了计算量,同时保持了词汇之间的语义关系。
捕捉语义相似性:通过训练,词嵌入能够学习到词语之间的关系。例如,语义相似的词(如“猫”和“狗”)在向量空间中会比较接近,而语义不相关的词(如“猫”和“汽车”)则会较为遥远。
(二)词嵌入层工作流程
初始化词向量:词嵌入层的初始词向量通常会使用随机初始化或者通过加载预训练的词向量(如Word2Vec或GloVe)进行初始化。
输入索引:每个单词在词汇表中都有一个唯一的索引。输入文本(例如一个句子)会先被分词,然后每个单词会被转换为相应的索引。
查找词向量:词嵌入层将这些单词索引映射为对应的词向量。这些词向量是一个低维稠密向量,表示该词的语义。
输入到RNN:这些词向量作为RNN的输入,RNN处理它们并根据上下文生成一个序列的输出。
(三)词嵌入使用
在PyTorch中,我们可以使用 nn.Embedding 词嵌入层来实现输入词的向量化。
"""
nn.Embedding 对象构建时,最主要有两个参数:
- num_embeddings:词的数量
- embedding_dim:用多少维的向量来表示每个词
"""
nn.Embedding(num_embeddings=10, embedding_dim=4)将词转换为词向量,其步骤如下:
先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引;
然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
# 导包
import jieba
import torch
"""
如果你希望得到一个可以直接操作的列表,推荐使用 jieba.lcut()。
如果你更关注性能或只需要遍历一次词语,可以使用 jieba.cut()。
"""
# 准备语料
text = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
# TODO 分词
word_list = jieba.lcut(text)
print(','.join(word_list)) # 北京,冬奥,的,进度条,已经,过半,,,不少,外国,运动员,在,完成,自己,的,比赛,后,踏上,归途,。
# TODO 去重
word_list = list(set(word_list))
print(len(word_list))
print('----------------------------------------------')
# TODO 构建词嵌入层
embedding = torch.nn.Embedding(num_embeddings=len(word_list), embedding_dim=4)
print(embedding)
# TODO 构建词向量矩阵
for idx, word in enumerate(word_list):
# 根据索引设置对应的词向量
word_vector = embedding(torch.tensor(idx))
print(word, idx,word_vector)结果如下:
北京,冬奥,的,进度条,已经,过半,,,不少,外国,运动员,在,完成,自己,的,比赛,后,踏上,归途,。
18
----------------------------------------------
Embedding(18, 4)
运动员 0 tensor([ 0.7287, -1.6847, 0.5564, -0.0367], grad_fn=)
比赛 1 tensor([ 0.5283, -0.8515, 0.1672, 0.5620], grad_fn=)
已经 2 tensor([ 0.0028, -0.0279, 0.8651, 0.7556], grad_fn=)
归途 3 tensor([-1.7779, -1.0001, 0.6034, -0.6074], grad_fn=)
自己 4 tensor([ 0.8524, -2.6602, 1.3813, 1.6450], grad_fn=)
完成 5 tensor([ 1.0556, -0.5360, -1.1430, 0.3038], grad_fn=)
的 6 tensor([-2.5500, -0.3222, 0.5500, -0.2184], grad_fn=)
进度条 7 tensor([ 1.3667, 1.3678, -0.3761, -0.7423], grad_fn=)
外国 8 tensor([ 1.1124, 0.1138, -0.7787, 1.5220], grad_fn=)
, 9 tensor([-1.4728, 0.3668, -0.9317, -0.0277], grad_fn=)
后 10 tensor([-0.6699, 0.0104, 0.8685, 0.0783], grad_fn=)
。 11 tensor([-1.0836, 0.0073, -1.1998, -1.4307], grad_fn=)
北京 12 tensor([-1.3150, 0.9510, -0.2884, 0.1634], grad_fn=)
在 13 tensor([ 0.4457, 0.3837, -1.5833, -0.1662], grad_fn=)
不少 14 tensor([ 1.1559, 0.6203, -0.5113, -1.2769], grad_fn=)
过半 15 tensor([-0.0445, -0.0500, 0.5016, 0.3068], grad_fn=)
冬奥 16 tensor([-1.4499, 0.2589, -0.0751, 1.6103], grad_fn=)
踏上 17 tensor([-0.1187, 0.5719, -0.1318, -0.9996], grad_fn=) 三、循环网络层
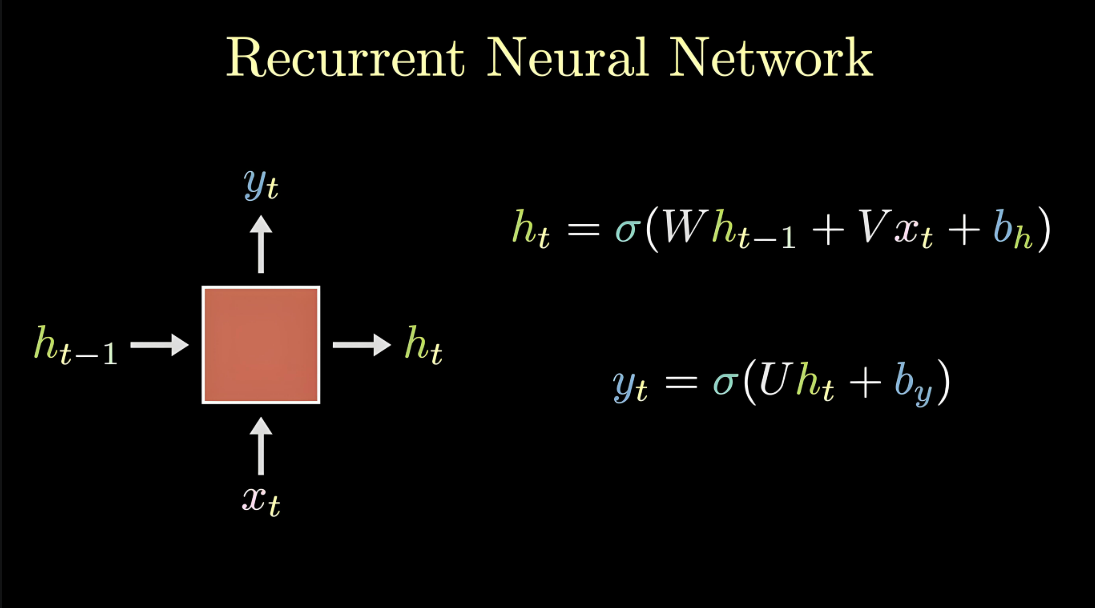
文本数据是具有序列特性的,例如: "我爱你", 这串文本就是具有序列关系的,"爱" 需要在 "我" 之后,"你" 需要在 "爱" 之后, 如果颠倒了顺序,那么可能就会表达不同的意思。为了表示出数据的序列关系,我们需要使用 RNN 来对数据进行建模,RNN 是一个具有记忆功能的网络,它作用于处理带有序列特点的样本数据。
RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
(一)网络结构
RNN单层网络结构:
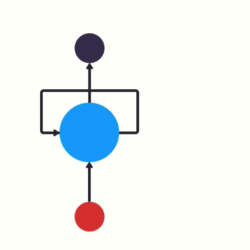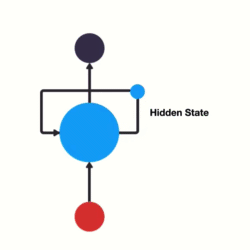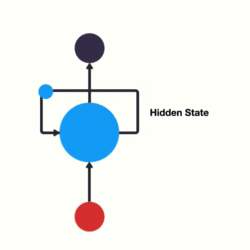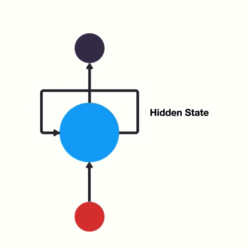
以时间步对RNN进行展开后的单层网络结构:

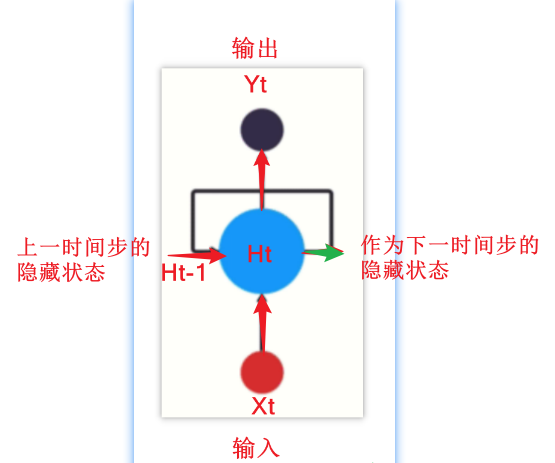
RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
(二)模型作用
具有记忆功能的网络,处理序列数据
因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等.
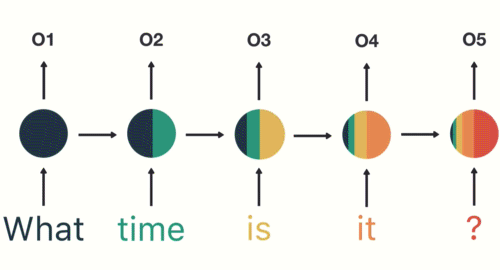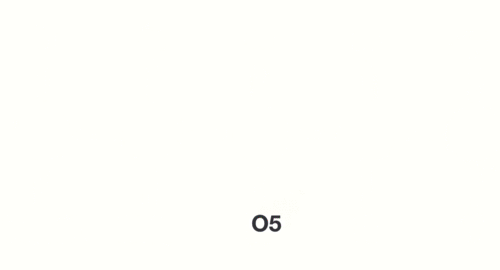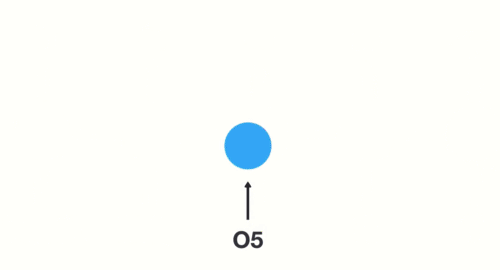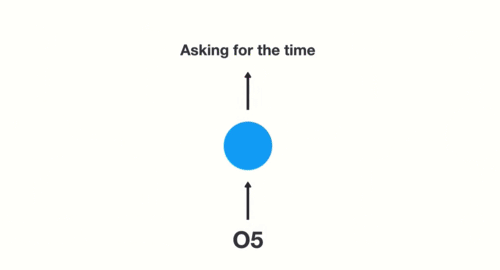
以一个用户意图识别的例子进行简单的分析:

第一步: 用户输入了"What time is it ?", 我们首先需要对它进行基本的分词, 因为RNN是按照顺序工作的, 每次只接收一个单词进行处理.

第二步: 首先将单词"What"输送给RNN, 它将产生一个输出O1.
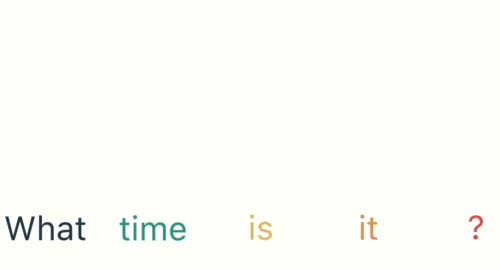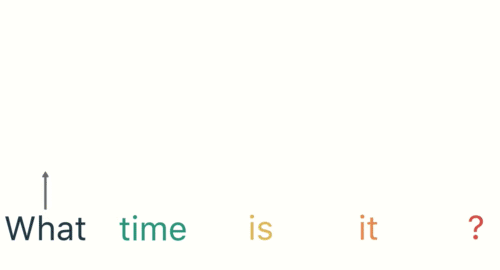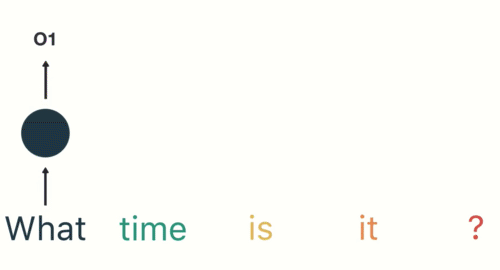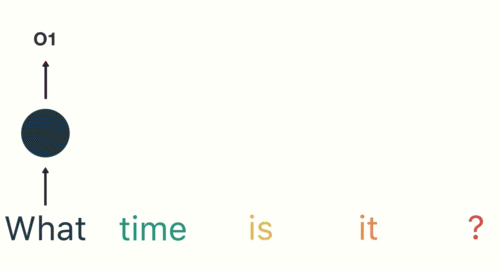
第三步: 继续将单词"time"输送给RNN, 但此时RNN不仅仅利用"time"来产生输出O2, 还会使用来自上一层隐层输出O1作为输入信息.
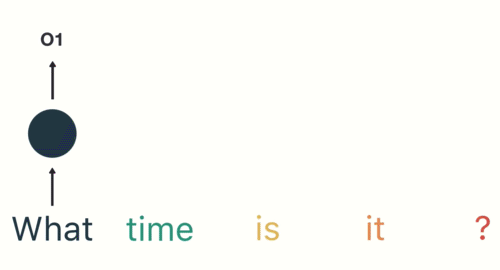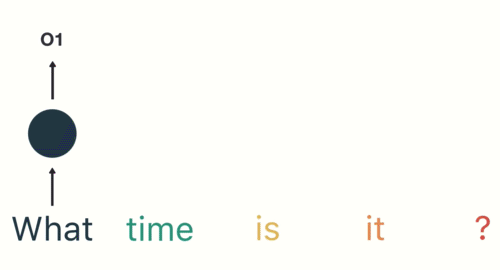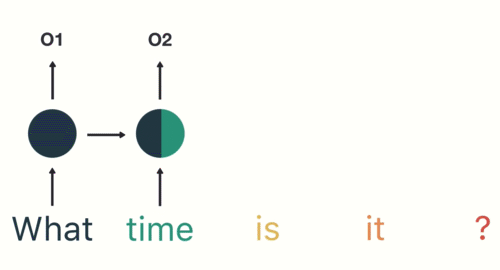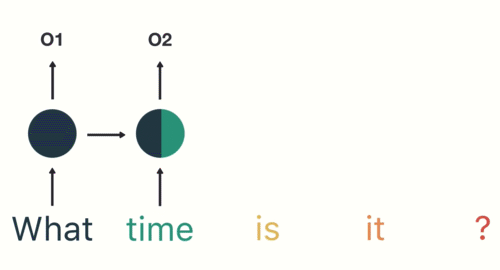
第四步: 重复这样的步骤, 直到处理完所有的单词.
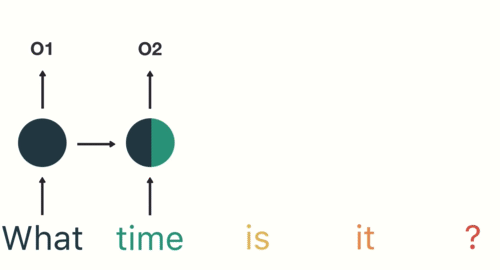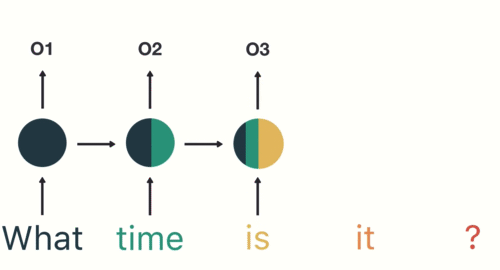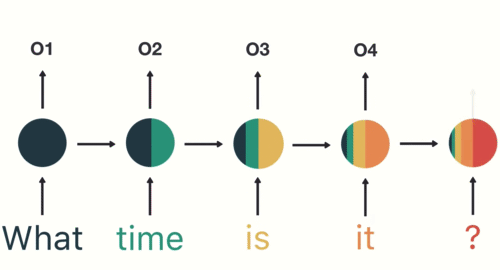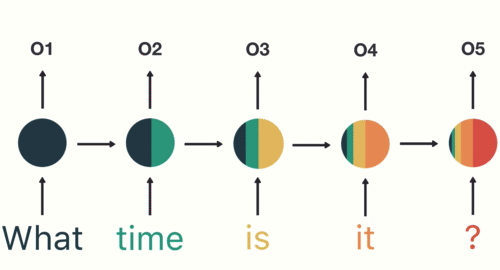
第五步: 最后,将最终的隐层输出O5进行处理来解析用户意图.
(三)RNN原理
1、当前输入x词向量和上一时间步的隐藏状态h0, 经过循环网络输出当前时间步的隐藏状态和预测结果
2、预测结果最终进入全连接神经网络, 输出词汇表中N个词的概率, 概率最大的词就是最终预测的y值
RNN神经元内部是如何计算的呢?
1. 计算隐藏状态:每个时间步的隐藏状态h_t是根据当前输入x_t和前一时刻的隐藏状态h_{t-1}计算的。
在 RNN 中,每个时间步的隐藏状态
h_t相当于网络的“记忆”,它同时依赖于:
当前输入
x_t(即当前词的词向量)上一时刻的隐藏状态
h_{t-1}(即过去的信息)这两个共同决定了当前的输出和下一个状态。
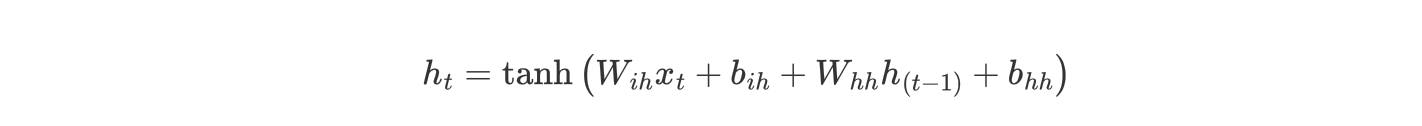
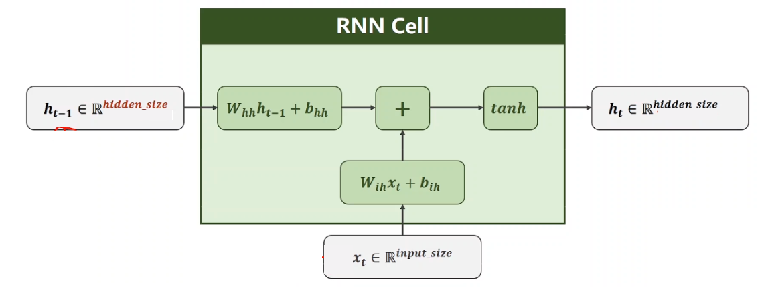
上述公式中:
W_{ih}表示输入数据的权重b_{ih}表示输入数据的偏置W_{hh}表示输入隐藏状态的权重b_{hh}表示输入隐藏状态的偏置h_{t-1}表示输入隐藏状态h_t表示输出隐藏状态
最后对输出的结果使用tanh激活函数进行计算,得到该神经元你的输出隐藏状态。
2. 计算当前时刻的输出:网络的输出y_t是当前时刻的隐藏状态经过一个线性变换得到的。
![]()
y_t是当前时刻的输出(通常是一个向量,表示当前时刻的预测值,RNN层的预测值)h_t是当前时刻的隐藏状态W_{hy}是从隐藏状态到输出的权重矩阵b_y是输出层的偏置项
3. 词汇表映射:输出y_t是一个向量,该向量经过全连接层后输出得到最终预测结果y_{pred},y_{pred}中每个元素代表当前时刻生成词汇表中某个词的得分(或概率,通过激活函数:如softmax)。
词汇表有多少个词,
y_{pred}就有多少个元素值,最大元素值对应的词就是当前时刻预测生成的词。
4.核心图解
文本生成示例:
假设我们使用RNN进行文本生成,输入是一个初始词语或一段上下文(例如,“m”)。RNN会通过隐藏状态逐步生成下一个词的概率分布,然后根据概率选择最可能的下一个词。
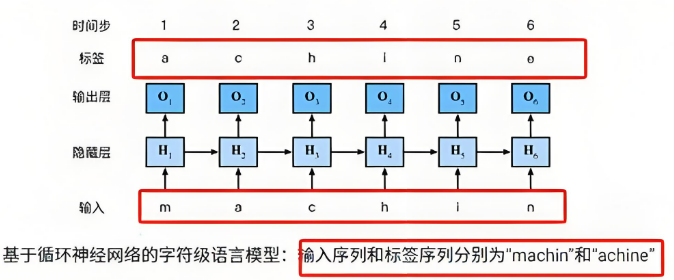
输入:“m” → 词向量输入
x_1(对应“m”)初始化隐藏状态
h_0,一般初始值为0隐藏状态更新
h_1,并计算输出y_1-->h_t是根据当前输入x_t和前一时刻的隐藏状态h_{t-1}计算的经过全连接层输出层计算输出
y_{pred},使用softmax函数将y_{pred}转换为概率分布选择概率最高的词作为输出词(例如“a”)
输入新的词“a”,继续处理下一个时间步,直到生成完整的词或句子
小结:在循环神经网络中,词与输出的对应关系通常通过以下几个步骤建立
词嵌入:将词转化为向量表示(词向量)。
RNN处理:通过RNN层逐步处理词向量,生成每个时间步的隐藏状态。
输出映射:通过线性变换将隐藏状态映射到输出,通常是一个词汇表中的词的概率分布。
(四)Pytorch RNN层的使用
1、API介绍
# input_size:输入数据的特征维度,一般设为词向量的维度
# hidden_size:隐藏层h的维度,也是当前层神经元的输出维度
# num_layers: 隐藏层h的层数,默认为1
RNN = nn.RNN(input_size, hidden_size,num_layers)2、输入数据和输出结果
将RNN实例化就可以将数据送入其中进行处理,处理的方式如下所示:
output, hn = RNN(x, h0)输入数据:主要包括词嵌入的x 、初始的隐藏层h0
x的表示形式为[seq_len, batch, input_size],即[句子的长度,batch的大小,词向量的维度]
h0的表示形式为[num_layers, batch, hidden_size],即[隐藏层的层数,batch的大小,隐藏层h的维度]
输出结果:主要包括输出结果output,最后一层的hn
output的表示形式与输入x类似,为[seq_len, batch, input_size],即[句子的长度,batch的大小,输出向量的维度]
hn的表示形式与输入h0一样,为[num_layers, batch, hidden_size],即[隐藏层的层数,batch的大,隐藏层h的维度]
3、案例演示
下一步隐藏状态计算公式:
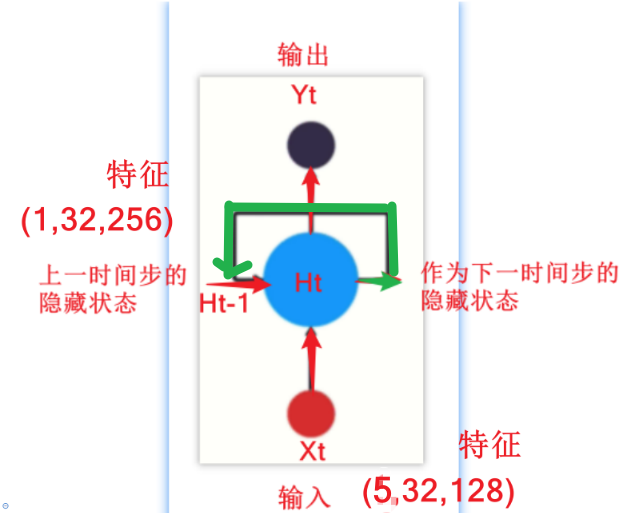
# 导包
import torch
# 准备输入Xt数据
x = torch.randn(size=[5, 32, 128])
print(x)
print('-----------------------')
# 准备上初始隐藏状态h,默认值为0
h0 = torch.zeros(size=[1, 32, 256])
print(h0)
print('-----------------------')
# TODO 创建RNN层
# input_size:输入x的特征维度,hidden_size:隐藏层维度,num_layers:RNN层数量
rnn = torch.nn.RNN(input_size=128, hidden_size=256, num_layers=1)
print(rnn)
print('-----------------------')
# TODO 传入Xt和初始隐藏状态h0,返回输出和当前时间步隐藏状态
y, h1 = rnn(x, h0) # 正向传播
print(h1)
print('-----------------------')
print(y)四、文本生成案例
(一)需求
根据输入的某个词,生成由n个词组成的句子
实际上是一个多分类问题, 词汇表中有多少词就是多少分类问题
全连接输出层输出每个词的概率,最大概率的词就是当前的预测词,依次类推一直预测出50个词
(二)原始数据集
收集周杰伦从第一张专辑《Jay》到第十张专辑《跨时代》中的歌词,来训练神经网络模型,当模型训练好后,我们就可以用这个模型来创作歌词。数据集如下:
想要有直升机
想要和你飞到宇宙去
想要和你融化在一起
融化在宇宙里
我每天每天每天在想想想想著你
这样的甜蜜
让我开始相信命运
感谢地心引力
让我碰到你
漂亮的让我面红的可爱女人
...该数据集共有 5819 行文本。
(三)整体代码框架梳理
1、构建词汇表
所谓的词表就是将语料进行分词,然后给每一个词分配一个唯一的编号,便于我们送入词嵌入层。
词汇表 唯一词的列表
歌词文本用词汇表中下标索引表示列表
词汇表中词的去重数量
词和下标索引的映射字典
def build_vocab():
# 提前构建两个列表,分别存储所有行分词列表和去重后每个分词
all_words = []
unique_words = []
# 读取周杰伦歌词文件数据
for line in open('data/jaychou_lyrics.txt', mode='r', encoding='utf-8'):
# todo 使用jieba进行分词
words = jieba.lcut(line)
# todo 添加到all_words中
all_words.append(words)
# todo 把每个分词去重后添加到unique_words中
for word in words:
if word not in unique_words:
unique_words.append(word)
# 统计去重后单词数量
unique_words_cnt = len(unique_words)
# 构建小词表: 每个单词对应一个索引
unique_word_to_idx = {word: i for i, word in enumerate(unique_words)}
# 构建存储所有数据索引的列表
all_words_idx = []
# 遍历all_words列表
for words in all_words:
# 定义临时存储一行的索引列表
temp = []
# 遍历每个分词
for word in words:
temp.append(unique_word_to_idx[word])
# todo 为了后续每行内容索引区分开,添加空格对应的索引
temp.append(unique_word_to_idx[' '])
# 把当前行的所有索引添加到all_words_idx中
all_words_idx.extend(temp)
# 代码走到此处说明所有单词索引已经构建完成
# print(all_words_idx)
# todo 返回4个结果
return unique_words, unique_words_cnt, unique_word_to_idx, all_words_idx2、构建数据集对象
在训练的时候,为了便于读取语料,并送入网络,所以我们会构建一个Dataset对象,重写DataSet类
class MyDataset(torch.utils.data.Dataset):
# 重写__init__方法
def __init__(self, all_words_idx, number_chars):
# 属性1: 所有单词索引列表
self.all_words_idx = all_words_idx
# 属性2: 每个句子的长度
self.number_chars = number_chars
# 计算所有词数量
self.all_words_idx_cnt = len(self.all_words_idx)
# 计算句子数量
self.number = self.all_words_idx_cnt // self.number_chars
# 重写__len__方法
def __len__(self):
return self.number
# 重写__getitem__方法
def __getitem__(self, index):
# 利用max()min()解决开始索引越界问题
start = min(max(0, index), self.all_words_idx_cnt - 1 - self.number_chars)
# 计算结束索引
end = start + self.number_chars
# todo 分别获取x和y
x = self.all_words_idx[start:end]
y = self.all_words_idx[start + 1:end + 1]
# todo 因为后续是张量训练,此处需要将数据转成张量
x = torch.tensor(x)
y = torch.tensor(y)
# todo 返回结果
return x, y
x是歌词文本中n个词组成的所有句子
y是x+1(x中词后一个)
1个样本中x1是由n个词向量组成的特征值,y1是由n个词向量组成的目标列
3、构建RNN网络模型
用于实现《歌词生成》的网络模型,主要包含了三个层:
词嵌入层: 用于将语料转换为词向量
循环网络层: 提取句子语义
全连接层: 输出对词典中每个词的预测概率
(1)重写__init__方法
调用父类init方法
词嵌入层
RNN层
全连接层
(2)重写forward方法
每个batch中词转换成词向量
调用rnn层输入当前的预测结果和当前时间步的隐藏状态值 -->
y, h_新 = x, h_旧rnn层预测结果经过全连接输入层得到词汇表中N个词的分值
# 重写forward方法
def forward(self, x, h):
# todo 获取嵌入层输出
ebd_x = self.embedding(x)
# todo 获取rnn层输出
# TODO ebd_x[batch_size, seq_len, input_size]->(seq_len,batch_size, hidden_size)
rnn_out, h = self.rnn(ebd_x.transpose(0, 1), h)
# todo 全连接层: 只能处理2维张量,此处需要把rnn_out转成2维张量
y_pred = self.out(rnn_out.reshape(-1, rnn_out.shape[-1]))
# todo 返回结果
return y_pred, h(3)init_hidden方法
初始化第一个时间步的隐藏状态(全0)
# 定义初始化隐藏状态方法
def init_hidden(self, batch_size):
# 创建初始隐藏状态
return torch.zeros(size=[1, batch_size, 256])4、模型训练
获取词汇表
获取数据表
封装数据加载器
创建模型对象
创建交叉熵损失函数
创建优化器对象
循环遍历训练epoch
循环遍历数据加载
循环遍历时自动调用自定义数据集对象
初始化隐藏状态
模型预测
预测y值
当前时间步的隐藏状态
计算损失值
梯度清零
梯度计算
参数更新
模型保存
5、模型预测
传入初始词
将起始词转换成下标索引
将其诗词保存到列表中
创建模型对象
加载训练模型的参数字典
初始化隐藏状态值
循环遍历句子需要的词数量
根据词对应的下标的字典将词下标列表转换成词连接成一句话进行输出,得到最终预测的句子
(四)整体代码示例
关键参数

# 导包
import time
import jieba
import torch
# TODO 1.构建词表
def build_vocab():
# 提前构建两个列表,分别存储所有行分词列表和去重后每个分词
all_words = []
unique_words = []
# 读取周杰伦歌词文件数据
for line in open('data/jaychou_lyrics.txt', mode='r', encoding='utf-8'):
# todo 使用jieba进行分词
words = jieba.lcut(line)
# todo 添加到all_words中
all_words.append(words)
# todo 把每个分词去重后添加到unique_words中
for word in words:
if word not in unique_words:
unique_words.append(word)
# 统计去重后单词数量
unique_words_cnt = len(unique_words)
# 构建小词表: 每个单词对应一个索引
unique_word_to_idx = {word: i for i, word in enumerate(unique_words)}
# 构建存储所有数据索引的列表
all_words_idx = []
# 遍历all_words列表
for words in all_words:
# 定义临时存储一行的索引列表
temp = []
# 遍历每个分词
for word in words:
temp.append(unique_word_to_idx[word])
# todo 为了后续每行内容索引区分开,添加空格对应的索引
temp.append(unique_word_to_idx[' '])
# 把当前行的所有索引添加到all_words_idx中
all_words_idx.extend(temp)
# 代码走到此处说明所有单词索引已经构建完成
# print(all_words_idx)
# todo 返回4个结果
return unique_words, unique_words_cnt, unique_word_to_idx, all_words_idx
# TODO 2.构建数据集
class MyDataset(torch.utils.data.Dataset):
# 重写__init__方法
def __init__(self, all_words_idx, number_chars):
# 属性1: 所有单词索引列表
self.all_words_idx = all_words_idx
# 属性2: 每个句子的长度
self.number_chars = number_chars
# 计算所有词数量
self.all_words_idx_cnt = len(self.all_words_idx)
# 计算句子数量
self.number = self.all_words_idx_cnt // self.number_chars
# 重写__len__方法
def __len__(self):
return self.number
# 重写__getitem__方法
def __getitem__(self, index):
# 利用max()min()解决开始索引越界问题
start = min(max(0, index), self.all_words_idx_cnt - 1 - self.number_chars)
# 计算结束索引
end = start + self.number_chars
# todo 分别获取x和y
x = self.all_words_idx[start:end]
y = self.all_words_idx[start + 1:end + 1]
# todo 因为后续是张量训练,此处需要将数据转成张量
x = torch.tensor(x)
y = torch.tensor(y)
# todo 返回结果
return x, y
# TODO 3.构建模型
class MyModel(torch.nn.Module):
# 重写__init__方法
def __init__(self, unique_words_cnt):
# 调用父类方法
super().__init__()
# todo 定义网络结构
# 创建一个嵌入层
self.embedding = torch.nn.Embedding(num_embeddings=unique_words_cnt, embedding_dim=128)
# 创建一个rnn层
self.rnn = torch.nn.RNN(input_size=128, hidden_size=256, num_layers=1)
# 创建一个全连接层
self.out = torch.nn.Linear(in_features=256, out_features=unique_words_cnt)
# 重写forward方法
def forward(self, x, h):
# todo 获取嵌入层输出
ebd_x = self.embedding(x)
# todo 获取rnn层输出
# TODO ebd_x[batch_size, seq_len, input_size]->(seq_len,batch_size, hidden_size)
rnn_out, h = self.rnn(ebd_x.transpose(0, 1), h)
# todo 全连接层: 只能处理2维张量,此处需要把rnn_out转成2维张量
y_pred = self.out(rnn_out.reshape(-1, rnn_out.shape[-1]))
# todo 返回结果
return y_pred, h
# 定义初始化隐藏状态方法
def init_hidden(self, batch_size):
# 创建初始隐藏状态
return torch.zeros(size=[1, batch_size, 256])
# TODO 4.模型训练
def train_model(train_loader, model, epochs):
# 1.获取数据(本次已经传参)
# 2.获取模型(本次已经传参)
# 3.创建损失函数对象
loss_fn = torch.nn.CrossEntropyLoss()
# 4.创建优化器对象
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
# 5.训练模型
for epoch in range(epochs):
total_loss, sample_cnt, start = 0.0, 0, time.time()
for x, y in train_loader:
# todo 正(前)向传播:从输入到输出: 预测值和损失值
# 先获取隐藏状态
h = model.init_hidden(x.size(0))
# 然后预测获取预测值和隐藏状态
y_pred, h = model(x, h)
# 计算损失值
loss = loss_fn(y_pred, y.transpose(0, 1).reshape(-1))
# 累加损失值和批次数量
total_loss += loss.item()
sample_cnt += 1
# todo 反向传播:从输出到输入: 梯度计算和参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 走到此处,说明一轮结束: 计算每轮损失值
epoch_loss = total_loss / sample_cnt
print(f"第{epoch + 1}轮,运行时间{time.time() - start:.2f}秒,损失值为:{epoch_loss:.2f}")
# 6.保存训练好的模型参数字典
torch.save(model.state_dict(), 'model/text_generator_model_dict.pth')
# TODO 5.模型评估
def eval_model(start_word, length, unique_words_cnt, unique_words, unique_word_to_idx):
# 1.获取起始词对应的索引,并封装成列表
word_idx = unique_word_to_idx[start_word]
words = [word_idx]
# 2.创建新模型
model = MyModel(unique_words_cnt)
model.load_state_dict(torch.load('model/text_generator_model_dict.pth'))
# 3.模型预测
# 提前获取隐藏状态
h = model.init_hidden(batch_size=1)
for i in range(length):
# 模型预测
ypred, h = model(torch.tensor([[word_idx]]), h)
# 获取预测值索引
word_idx = torch.argmax(ypred).item()
words.append(word_idx)
# print(words)
# 4.将索引列表转成词列表
words = [unique_words[idx] for idx in words]
print(''.join(words))
# 程序主入口
if __name__ == '__main__':
# TODO 1.构建词表
unique_words, unique_words_cnt, unique_word_to_idx, all_words_idx = build_vocab()
with open('data/词表.txt', 'w', encoding='utf-8') as f:
for word in unique_words:
f.write(word + '\n')
# TODO 2.构建数据集
number_chars = 32
dataset = MyDataset(all_words_idx, number_chars)
# print(f'数据集大小: {len(dataset)}') # 自动调用__len__方法
# print(dataset[0]) # 自动调用了__getitem__方法: (tensor([ 0, 1, 2, 3, 40]), tensor([ 1, 2, 3, 40, 0]))
batch_size = 5
train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# TODO 3.构建模型
model = MyModel(unique_words_cnt)
print(model)
# TODO 4.模型训练
epochs = 10
# train_model(train_loader, model, epochs)
# TODO 5.模型评估
# 注意: start_word必须在词表中有,否则报错
start_word = '你好'
length = 99
eval_model(start_word, length, unique_words_cnt, unique_words, unique_word_to_idx)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号