

1、项目环境安装
项目拉取:
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git模型文件拉取:
# 安装相关依赖
pip install modelscope
# 拉取模型文件
modelscope download --model deepseek-ai/DeepSeek-OCR README.md --local_dir ./dir环境要求:
本项目要求cuda版本是11.8,否则在编译安装 flash-attn时会出现异常报错
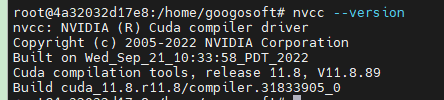
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocrpip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==2.7.3 --no-build-isolation本文采用的vllm推理框架加载模型,版本是v0.8.5版本,需要事先下载官网提供的whl安装包:
https://github.com/vllm-project/vllm/releases/tag/v0.8.5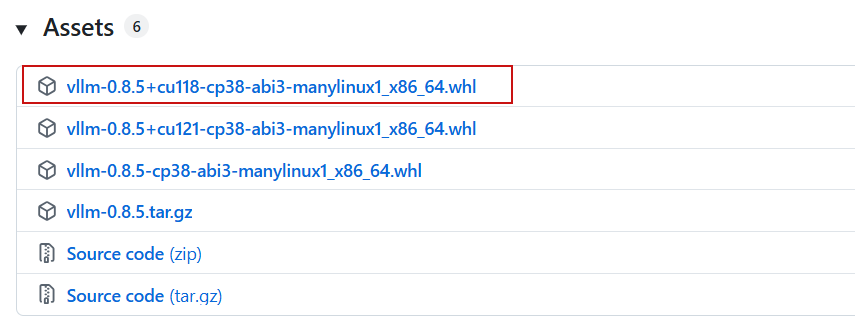
安装vllm:
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl# DeepSeek-OCR
pip install -r requirements.txt安装过程中会出现如下报错,不用管,不会影响正常运行
2 、运行项目
进入到DeepSeek-OCR-master/DeepSeek-OCR-vll目录
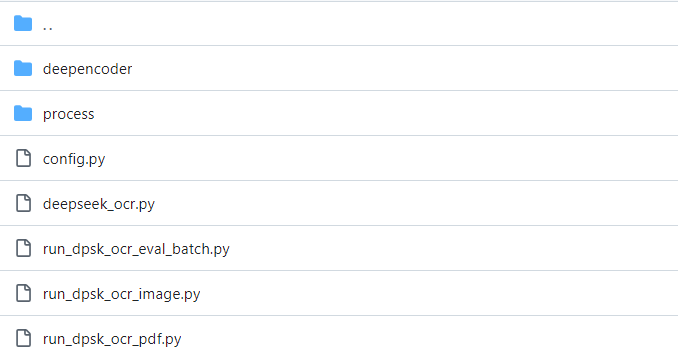
图片ocr
在进行图片OCR之前,需要首先修改下config.py配置文件
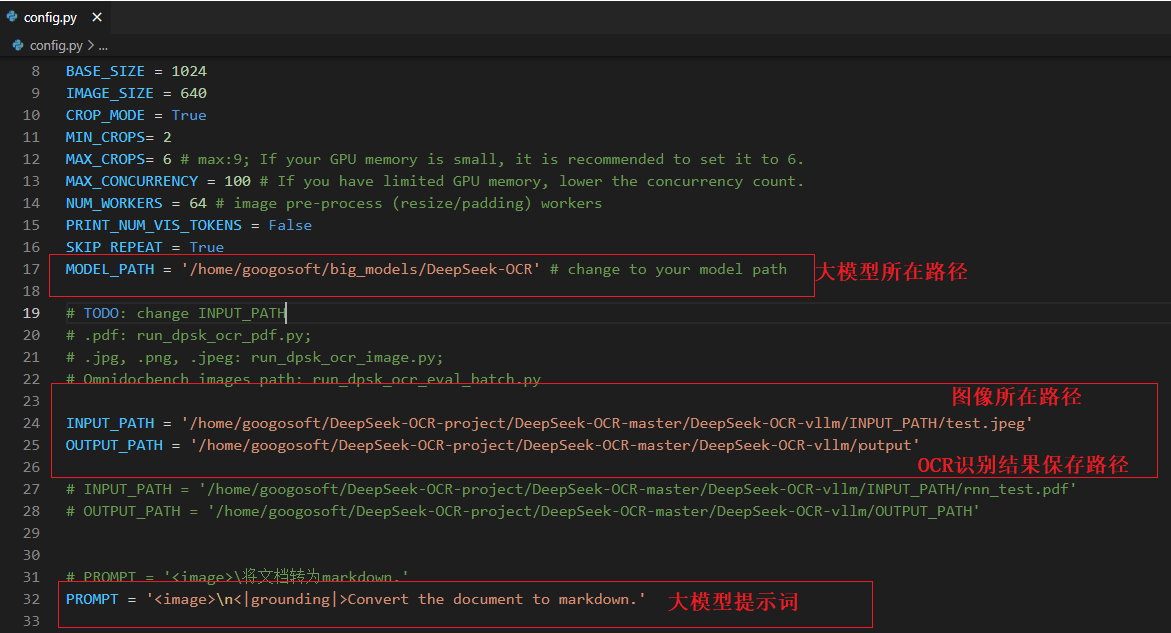
然后修改run_dpsk_ocr_image.py文件
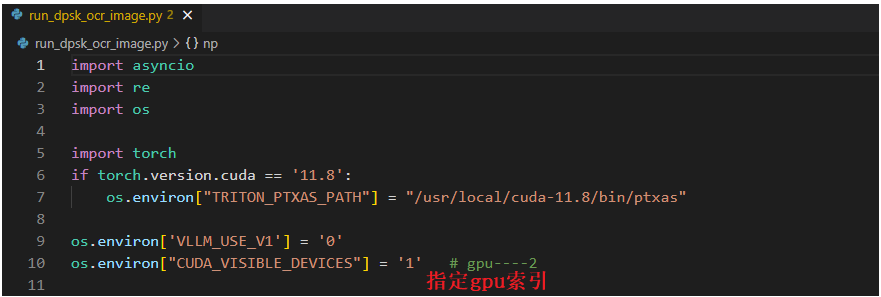
运行指令:
python run_dpsk_ocr_image.pyPDF文件OCR
在进行pdf文件OCR之前,需要首先修改下config.py配置文件
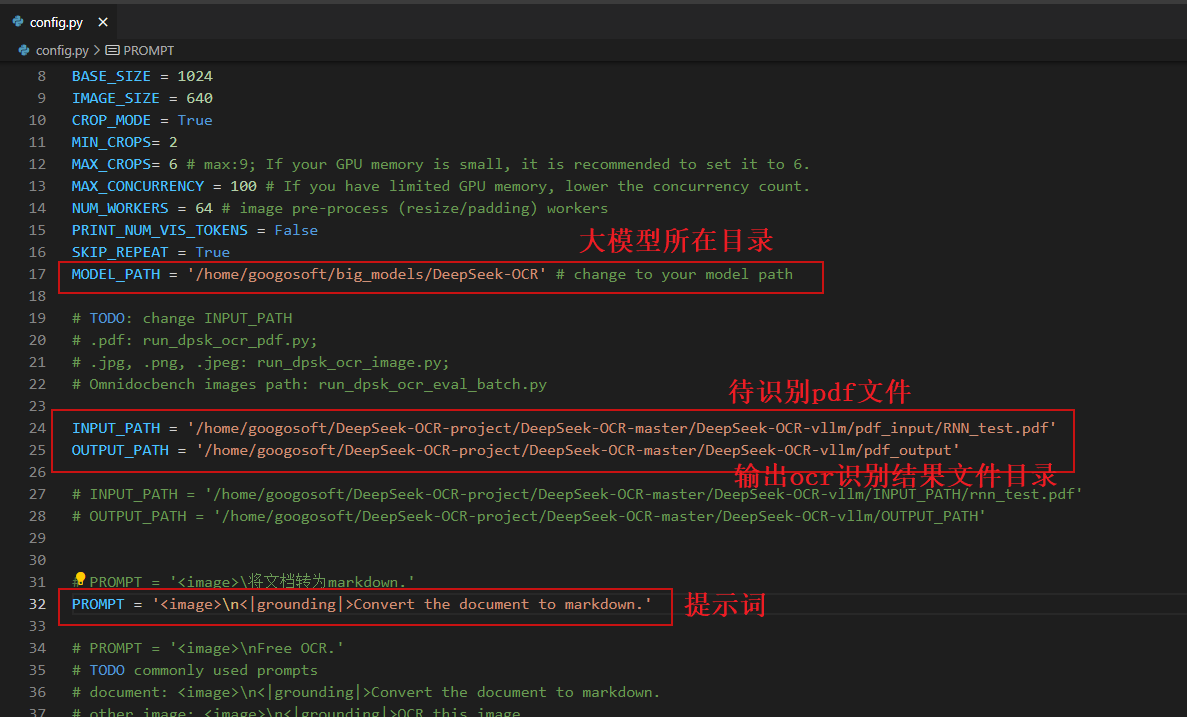
然后修改run_dpsk_ocr_pdf.py文件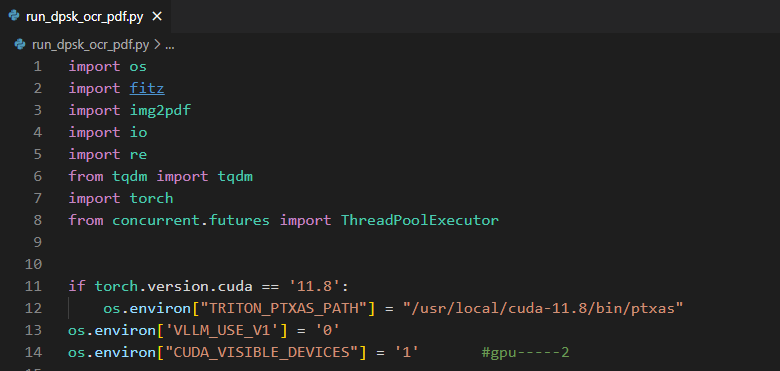
运行指令:
python run_dpsk_ocr_pdf.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号