

目录
1. 方案1:使用原脚本src/convert_annotations.py
2.1 convert_annotations_logodet3k_parquet.py 代码(原convert_annotations.py)
2. 方案2:prepare_data_logodet3k.py(convert_annotations_logodet3k_parquet.py后续)
2.2 prepare_data_logodet3k.py(原prepare_data.py)
2. 更新logo_data.yaml(基于convert_annotations_logodet3k_parquet.py)
1. src/convert_annotations.py详细注释
1.2. src/convert_annotations.py代码详细解析
3. RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
yolov7-logo-detection项目概述
项目围绕基于 YOLOv7 的自然场景 Logo 检测展开。基于先进的YOLOv7架构,在充足的高质量数据上训练(Flickr27与LogoDet-3K),对已知类别的Logo可以达到非常高的检测精度和召回率。YOLO是著名的单阶段、端到端检测模型,推理速度极快,非常适合需要实时检测的场景。本文涵盖yolov7-logo-detection项目基本实现,基于LogoDet-3K的进阶实现,以及Debug。
https://github.com/nuwandda/yolov7-logo-detection(github地址)
一、项目目标与核心概念界定
1. 核心目标
训练一个能在自然场景图像(in the wild) 中检测 Logo 的模型,通过对比两个不同规模数据集的适配性,验证 YOLOv7 在 Logo 检测任务中的有效性。
2. 关键概念区分
项目首先明确了目标检测(Object Detection) 与图像识别(Image Recognition) 的核心差异,这是理解项目技术定位的基础。
| 对比维度 | 图像识别(Image Recognition) | 目标检测(Object Detection) |
|---|---|---|
| 核心输出 | 仅为图像整体标签(如 “狗”) | 标签 + 边界框(如 “狗 1(x1,y1,x2,y2)”“狗 2(x3,y3,x4,y4)”) |
| 核心能力 | 分类图像 “是什么” | 定位 + 分类:“是什么” 且 “在哪里” |
| 项目适配场景 | 无法满足 Logo 检测(需定位单个 / 多个 Logo) | 完全适配(需标注 Logo 位置并分类品牌) |
二、技术架构:为何选择 YOLOv7?
项目选用 YOLOv7 作为基础架构,核心原因是其在速度与精度的平衡上具备行业领先性,且架构设计适配 Logo 检测的 “细粒度目标 + 复杂背景” 需求。
1. YOLOv7 的核心优势
- 性能天花板:在 GPU V100 上,是所有实时目标检测器中(30 FPS 及以上)精度最高的,AP(平均精度)达 56.8%;
- 速度覆盖广:支持 5 FPS ~ 160 FPS 的速度范围,可适配不同硬件资源(从低端 GPU 到高端 GPU)。
2. YOLOv7 的三大核心组件
YOLOv7 基于全连接神经网络(FCNN) 构建,部分版本引入 Transformer,核心分为三部分,各司其职:
- Backbone(骨干网络):核心功能是提取图像关键特征(如 Logo 的边缘、纹理、颜色分布),为后续检测提供 “特征原料”;
- Neck(颈部网络):对 Backbone 输出的特征图进行整合,构建特征金字塔—— 解决 “小 Logo 漏检” 问题(不同层级特征图适配不同尺寸的 Logo);
- Head(头部网络):输出层,最终生成 Logo 的边界框坐标和类别标签,完成检测任务。
3. YOLOv7 的关键改进
项目特别提及 YOLOv7 论文中的两大核心改进,这是其超越前代 YOLO 模型的关键:
(1)架构优化(提升特征提取效率)
- E-ELAN(扩展高效层聚合网络):通过更灵活的特征聚合方式,增强模型对复杂场景(如 Logo 被遮挡、光照变化)的适应性;
- 基于拼接的模型缩放(Model Scaling for Concatenation-based Models):在扩大模型规模时,避免特征冗余,平衡精度与计算成本(适配 Logo 检测的 “轻量部署需求”)。
(2)可训练 BoF(Bag of Freebies,无额外计算成本的精度提升)
- 规划化重参数化卷积(Planned re-parameterized convolution):训练时用复杂卷积提升精度,推理时简化为普通卷积,不增加推理耗时;
- 粗细损失策略(Coarse for auxiliary, Fine for lead loss):辅助分支用 “粗粒度标签” 快速收敛,主分支用 “细粒度标签” 提升精度,适配 Logo 类间差异小(如 Nike 与 Puma)的特点。
三、数据集:从小规模验证到大规模扩展
项目采用 “双数据集” 设计,兼顾快速验证与未来扩展,解决了 “小数据训练快但泛化弱,大数据泛化强但训练耗时” 的矛盾。
1. 两个数据集的核心参数对比
| 数据集名称 | 规模级别 | 类别数 | 标注对象数 | 图像总数 | 标注类型 | 项目用途 |
|---|---|---|---|---|---|---|
| Flickr Logos 27 | 小规模 | 27 | 810 个(每类 30 张) | 810 张 | 边界框(Bounding Box) | 核心训练集(耗时短,快速验证模型) |
| LogoDet-3K | 大规模 | 3000 | ~20 万个 | 158,652 张 | 边界框 | 扩展支持(暂未训练,待补充步骤) |
2. 核心训练集(Flickr Logos 27)细节
- 覆盖品牌:含 Adidas、Apple、Coca Cola、Nike、Starbucks 等 27 个主流品牌,场景多样(如广告、包装、门店);
- 数据质量:全手动标注边界框,无标注噪声,适合作为 “模型 baseline 验证集”。
四、本地部署与训练:全流程可复现
文档提供了 ** step-by-step 的实操命令 **,降低了复现门槛,核心流程分为 “环境准备→数据处理→模型训练→推理测试” 四步。
1. 环境与数据准备(前置步骤)
| 步骤 | 核心操作 | 目的 |
|---|---|---|
| 1. 下载数据集 | 项目根目录下,运行 sh getFlickr.sh,数据自动存入 data 文件夹 | 获取 Flickr Logos 27 的标注图像,无需手动下载 |
| 2. 下载基础模型 | 下载 3 个预训练权重:- yolov7_training.pt(基础版)- yolov7-tiny.pt(轻量版)- yolov7-e6e_training.pt(高精度版) | 基于预训练权重 “微调”,减少训练迭代次数,提升收敛速度 |
| 3. 安装依赖 | 运行 git submodule update --init(装子模块)pip install -r src/requirements.txt(装 Python 包) | 解决依赖冲突,确保代码可运行 |
| 4. 标注格式转换 | 运行 python src/convert_annotations.py --dataset flickr27 | 将 Flickr 的原始标注格式转为 YOLOv7 要求的 “图像 + txt 标签” 格式(txt 含类别 ID + 边界框归一化坐标) |
| 5. 数据集划分 | 运行 python src/prepare_data.py --dataset flickr27 | 按 8:1:1 划分为训练集(train)、验证集(val)、测试集(test),符合机器学习标准流程 |
2. 模型训练:参数与资源适配
(1)核心训练参数(基于 NVIDIA RTX 3060 Laptop GPU)
| 参数 | 取值 | 选择理由 |
|---|---|---|
| Epoch(迭代轮次) | 300 | 小数据集(810 张)需足够轮次让模型收敛,避免欠拟合 |
| Batch Size(批次大小) | 2 | 笔记本 GPU 显存有限(RTX 3060 Laptop 通常 6GB),批次过大会导致显存溢出 |
| Image Size(图像尺寸) | 640x640 | 平衡精度与速度:640 是 YOLO 系列最优尺寸,可覆盖多数 Logo 大小,320 则精度下降 |
(2)显存不足的解决方案
- 降低 Batch Size(如从 2→1);
- 改用轻量模型(yolov7-tiny.pt,计算量仅为基础版的 1/3);
- 缩小图像尺寸(如 640→320,精度会降低,但显存占用减少 50%+)。
(3)训练命令与扩展支持
- 基础命令:
python src/yolov7/train.py --img-size 640 --cfg src/cfg/training/yolov7.yaml --hyp data/hyp.scratch.yaml --batch 2 --epoch 300 --data data/logo_data_flickr.yaml --weights src/yolov7_training.pt --workers 2 --name yolo_logo_det --device 0- 云环境支持:提供 Google Colab 链接,无需本地 GPU 即可复现训练(降低硬件门槛)。
3. 推理测试(验证模型效果)
通过一下命令实现:
python src/yolov7/detect.py --source data/Sample/test --weights runs/train/yolo_logo_det/weights/best.pt --conf 0.25 --name yolo_logo_det--source:指定测试图像路径;--weights:加载训练好的最优模型(best.pt);--conf 0.25:置信度阈值设为 0.25(过滤低置信度预测,平衡漏检与误检)。
五、结果评估:可视化与模型获取
项目未提供具体的 AP、Precision、Recall 数值,但通过关键评估图表展示了模型性能,且提供了训练好的模型供直接使用。
1. 核心评估图表
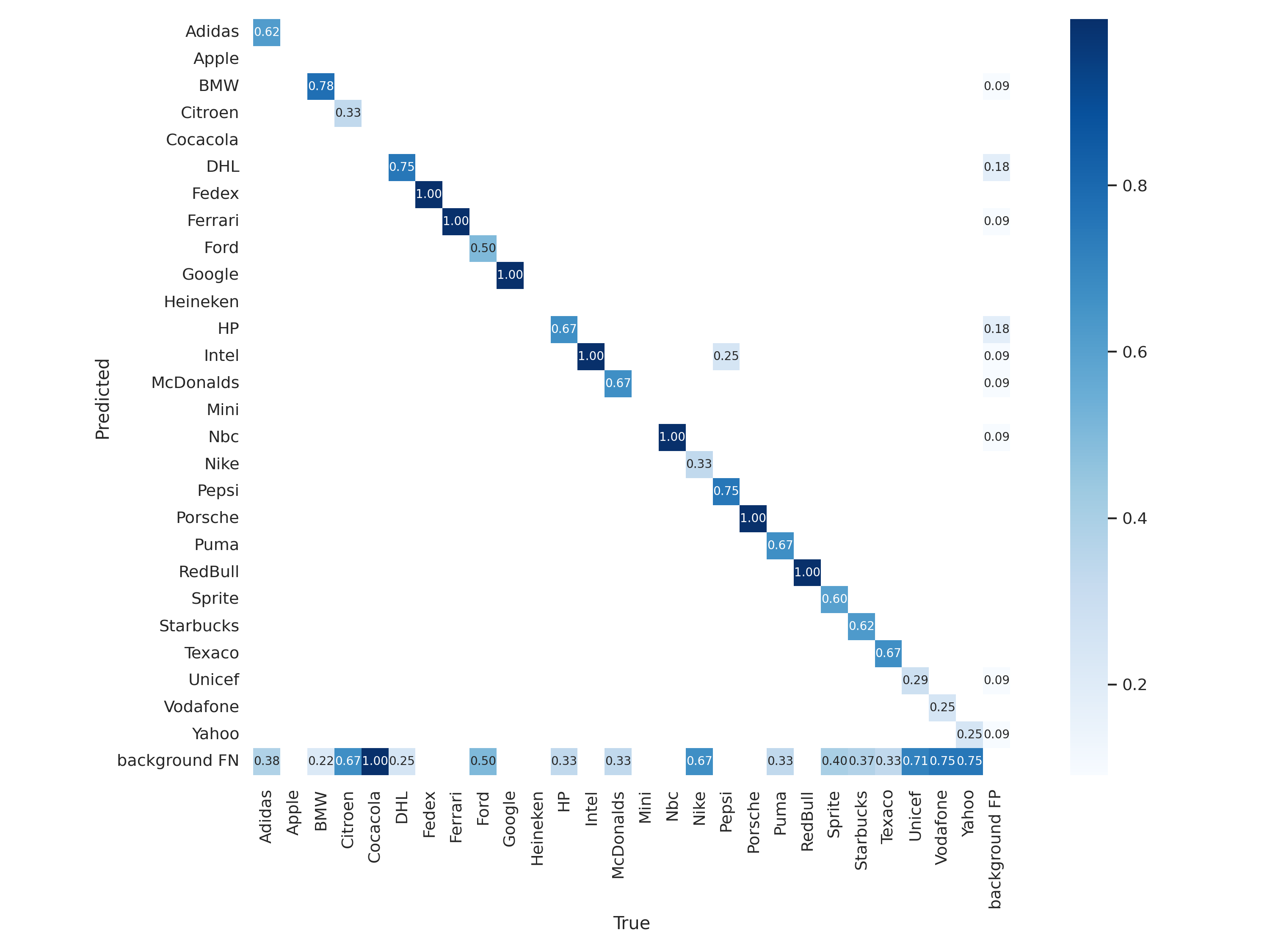
混淆矩阵(Confusion Matrix):
- 作用:展示 27 个 Logo 类别的 “真实标签” 与 “预测标签” 对应关系,可直观发现 “易混淆品牌”(如 Puma 与 Adidas,因 Logo 均含条纹元素);
- 理想状态:对角线数值高(预测正确),非对角线数值低(误判少)。
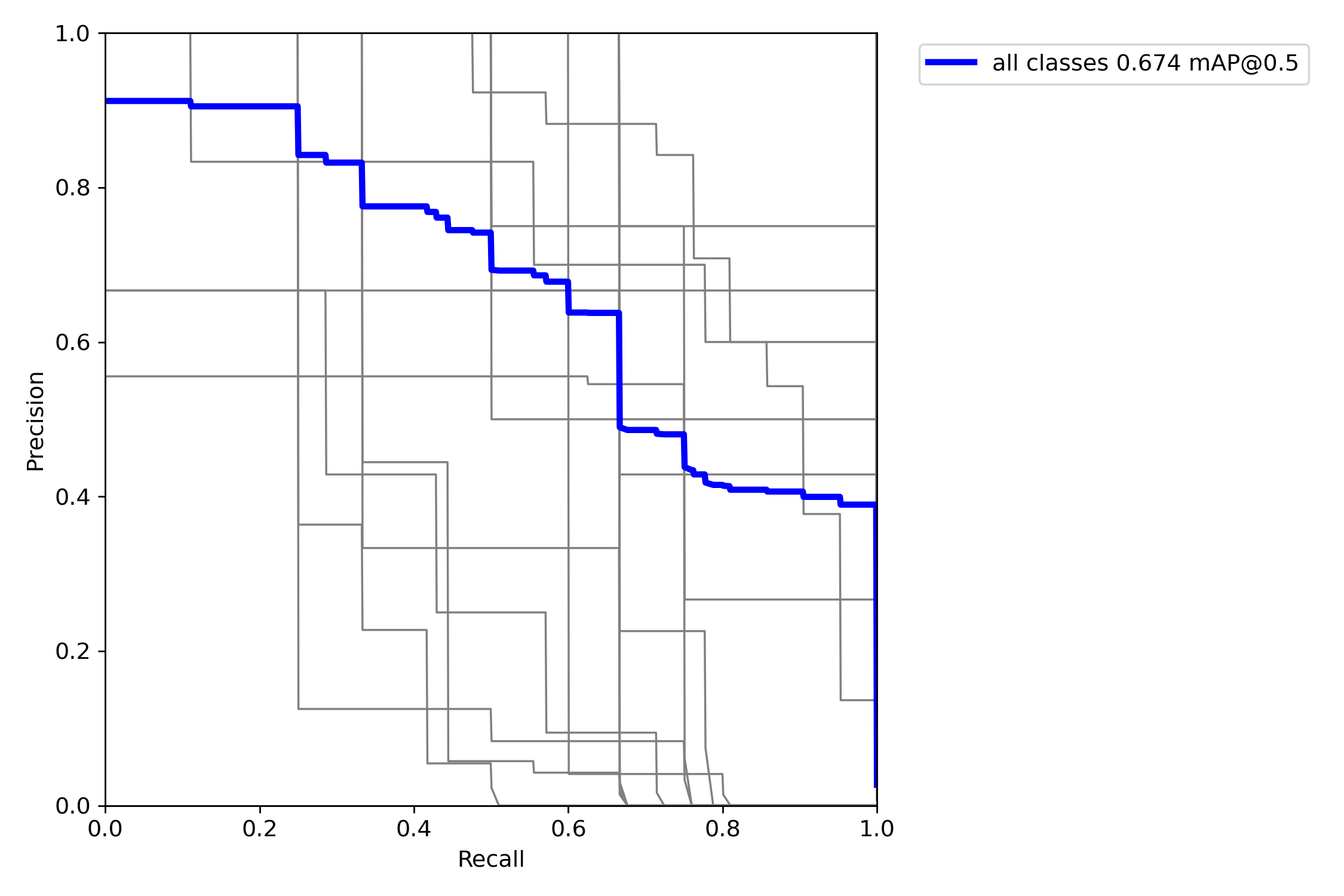
PR 曲线(Precision-Recall Curve):
- 作用:展示 “精确率(Precision)” 与 “召回率(Recall)” 的权衡关系(精确率高→误检少,召回率高→漏检少);
- 评估标准:曲线下面积(AUC)越大,模型整体性能越好,尤其适合 “类别不平衡” 的 Logo 检测场景(部分品牌样本少)。
2. 模型获取
提供训练好的模型下载链接,可直接用于 Logo 检测推理,无需重复训练,降低应用门槛。
但链接显示不存在。
六、项目特点与潜在优化方向
1. 项目优势
- 可复现性强:从数据下载到推理的每一步均提供具体命令,且支持 Colab,新手友好;
- 架构适配性高:选用 YOLOv7 平衡速度与精度,适合实际场景部署(如摄像头实时 Logo 检测);
- 扩展性好:预留 LogoDet-3K 数据集的适配空间,未来可支持 3000 类 Logo 检测,泛化性大幅提升。
2. 潜在优化方向
- 补充 LogoDet-3K 训练步骤:当前仅用小数据集训练,大规模数据集的训练参数(如学习率调整、显存优化)需进一步明确;
- 增加量化评估指标:需补充具体的 AP@0.5、AP@0.5:0.95、FPS 等数值,更精准衡量模型性能;
- 数据增强策略:针对 Logo 检测的 “遮挡、变形、光照变化” 问题,可增加随机遮挡、透视变换、亮度调整等数据增强,提升模型鲁棒性。
小结
该项目是一个 “从理论到实操” 完整的 Logo 检测方案 ,通过 YOLOv7 的高效架构、清晰的数据集设计、可复现的流程,为 “自然场景 Logo 检测” 提供了可靠的技术路径。其核心价值在于:既适合新手学习目标检测与 YOLOv7 的应用,也可作为实际项目的 baseline(直接使用训练好的模型或扩展到大规模数据集)。
补充 LogoDet-3K 训练步骤
要在该项目中扩充使用 LogoDet-3K 数据集,核心思路是复用项目已有的训练框架,但需要针对 LogoDet-3K 的数据格式和规模,补充 / 调整 数据准备阶段的步骤(标注转换、数据集划分),并微调训练参数。
该项目的 train.py 是基于 YOLOv7 通用训练逻辑编写的,其训练逻辑不绑定特定数据集(Flickr Logos 27 或 LogoDet-3K),仅依赖 符合 YOLOv7 格式的数据集目录结构 和 数据集配置文件(.yaml)。只要保证 LogoDet-3K 最终处理后的数据格式与 Flickr Logos 27 一致(即 YOLOv7 要求的格式),train.py 即可直接复用,无需修改训练函数本身。
src/convert_annotations.py和src/prepare_data.py,预留了将logodet3k转化为yolov7格式训练数据的接口。(详情见附录代码详细分析)
因此,基于项目预留的接口和现有代码逻辑,要切换到 LogoDet-3K 训练,核心是处理数据冲突 + 确保配置对齐 + 微调训练参数,无需大幅修改核心脚本。
一、第一步:处理「旧数据冲突」
由于我已经训练过Flickr Logos 27,data/ 目录下已存在 images/ 和 annotations/(对应 27 类数据)。如果直接运行 LogoDet-3K 的数据划分,新旧数据会混合覆盖,导致训练出错。因此必须先清理 / 备份旧数据:
备份旧数据(推荐,后续可回退)
# 备份 Flickr 27 的数据
mkdir -p data/backup_flickr27
mv data/images data/backup_flickr27/
mv data/annotations data/backup_flickr27/
mv data/labels data/backup_flickr27/ # labels 是 annotations 的副本,也需备份二、第二步:确认「LogoDet-3K 标注转换」正确
1. 方案1:使用原脚本src/convert_annotations.py
项目预留了 --dataset logodet3k 接口,但需先验证 标注转换结果是否正确(否则训练会出现「类别不匹配」或「无目标检测」问题):
1.1. 执行标注转换命令
将 LogoDet-3K 原始数据(图片 + 标注)按项目预期路径存放,即data/LogoDet-3k,运行:
# 转换 LogoDet-3K 标注为 YOLOv7 格式(.txt)
python src/convert_annotations.py --dataset logodet3k
# 可选:可视化验证(随机抽查10张图,确认边界框和类别是否正确)
python src/convert_annotations.py --dataset logodet3k --plot1.2. 关键检查点
标注文件格式:检查 data/logodet3k/annotations/ 下是否生成了与图片同名的 .txt 文件,内容是否符合 YOLO 格式
5 0.32 0.45 0.18 0.22 # [类别ID] [x_center] [y_center] [宽] [高](均归一化)
12 0.65 0.78 0.21 0.19类别 ID 映射:确保 .txt 中的「类别 ID」与你 logo_data.yaml 中「names 列表的顺序」完全一致(例如:ID=0 对应 names [0] = "tachipirina",ID=1 对应 names [1] = "thomapyrin",以此类推)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号