

一、数据处理
DataSet的作用:
1.获得每一个数据及其label
2.告诉我们总共有多少个数据
DateLoader的作用:为后面的网络提供不同的网络形式
下面以CIFAR10数据集来进行演示(CIFAR10数据集是包含了60000个3*32*32的有色图片,有10个类别,其中每类6000张图片。50000张训练图片和10000张测试图片)
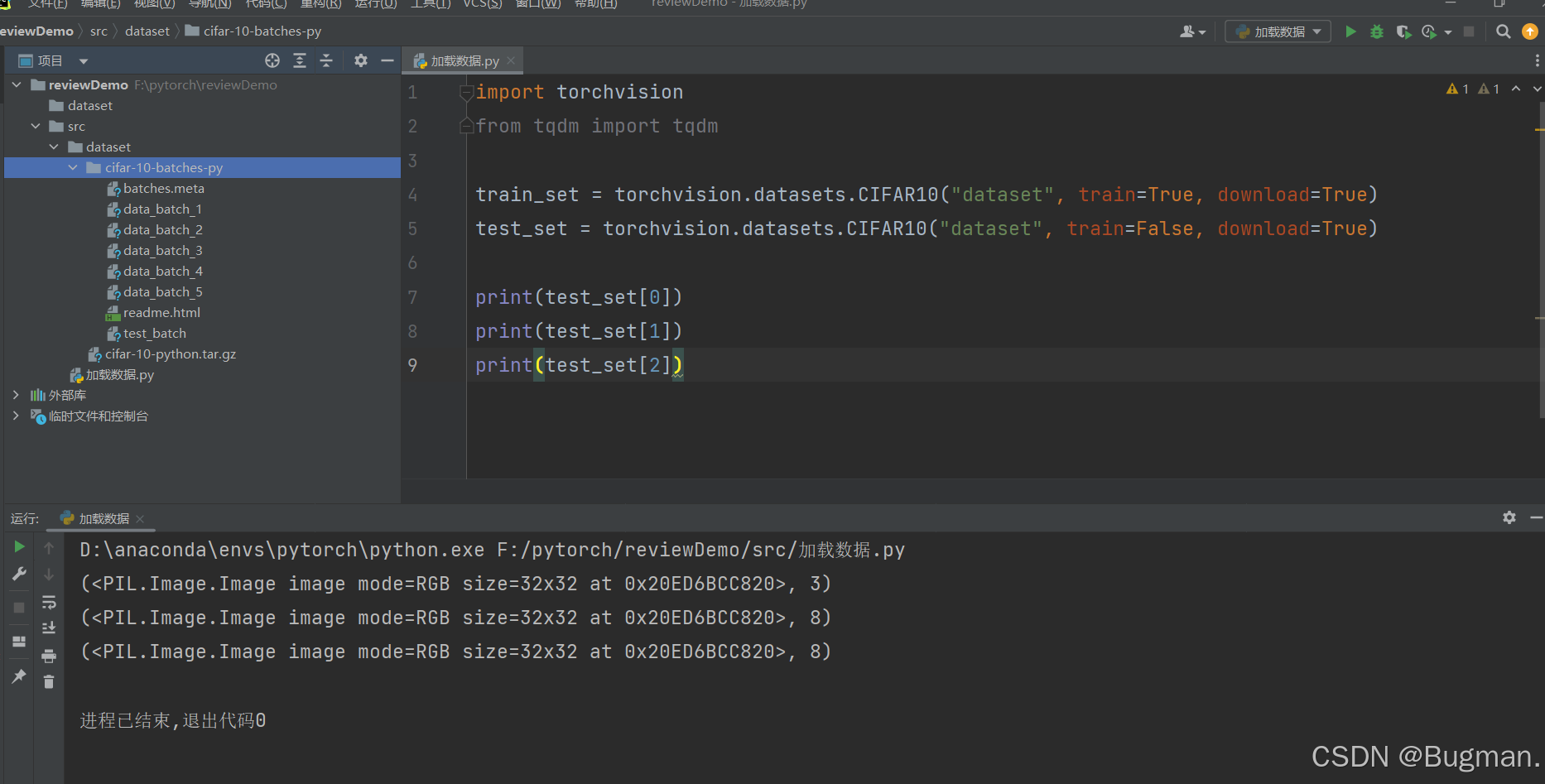
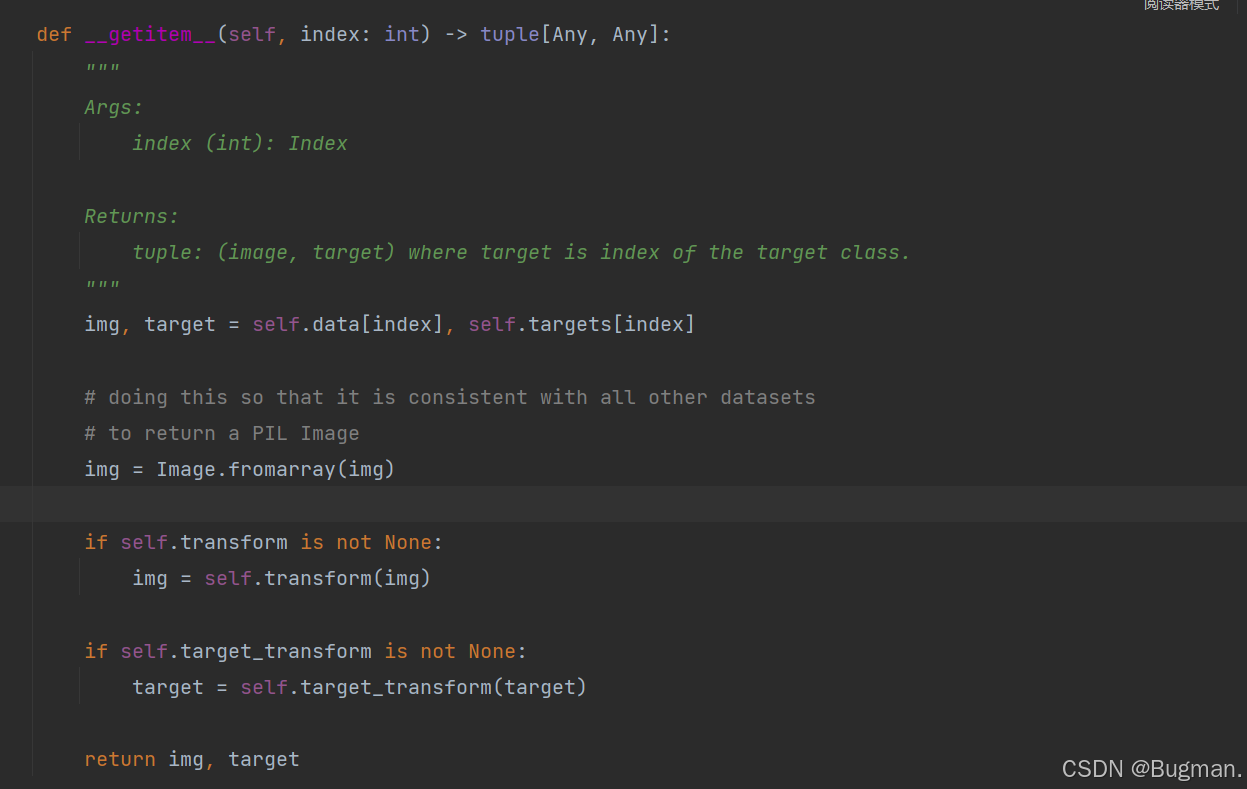
从下图可以看出,点进CIFAR10数据集类的getitem方法返回的是图片和所属的标签
import torchvision
train_set = torchvision.datasets.CIFAR10("dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10("dataset", train=False, download=True)
print(test_set[0])
print(test_set[1])
print(test_set[2])
img, target = test_set[0]
print(test_set.classes[target])
img.show()可以看到,打印出来图片是PIL类型,但是我们Pytorch中用的是图片的张量形式,所以我们可以把数据集转换成tensor形式
具体代码修改如下
import torchvision
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10("dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10("dataset", train=False, transform=dataset_transform, download=True)而DataLoader的作用是对数据集进行一个打包操作,假设batch_size设置为4,图解如下
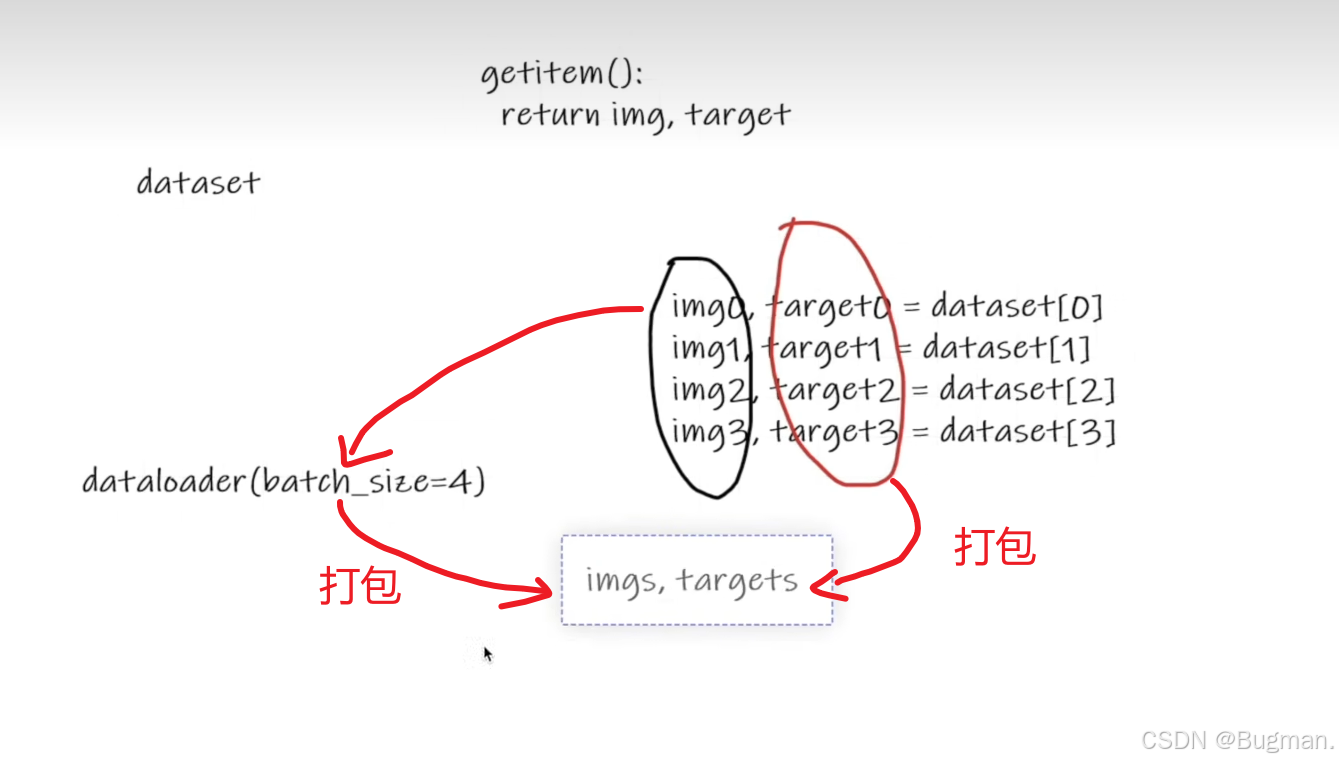
下面代码示例
import torchvision
from torch.utils.data import DataLoader
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10("dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10("dataset", train=False, transform=dataset_transform, download=True)
test_loader = DataLoader(test_set, batch_size=4, shuffle=True)
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)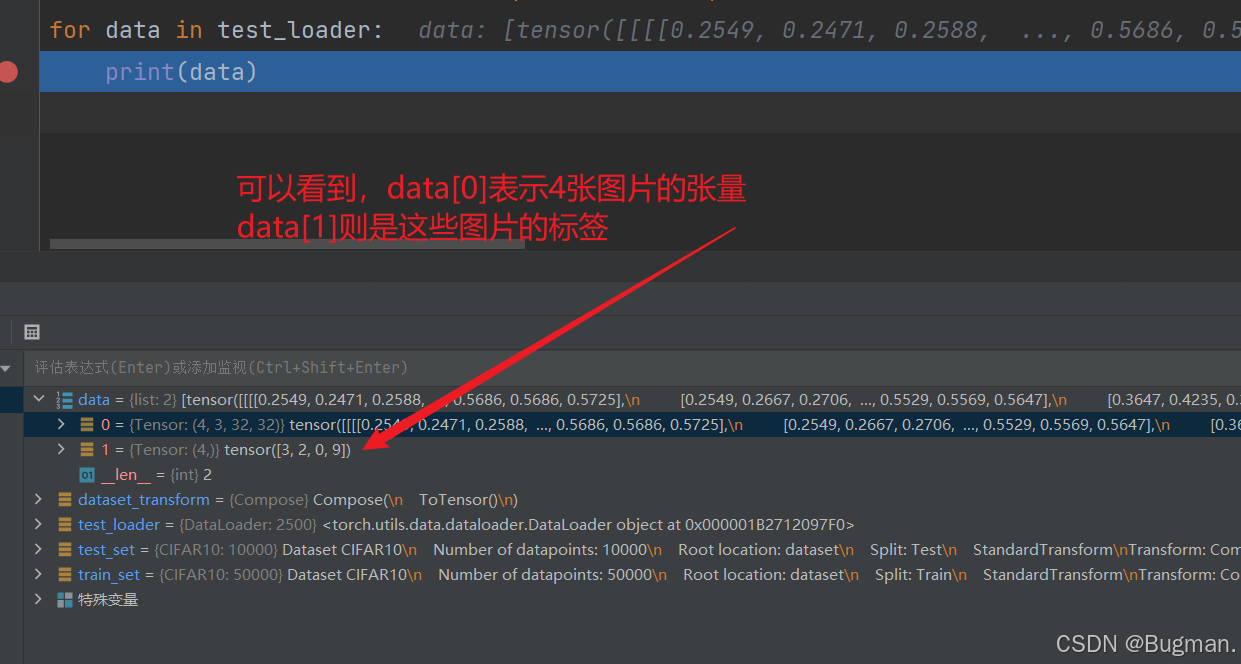
总结一下,就是dataloader只是对dataset进行一个打包操作,里面的数据量是一样的
二、神经网络模型创建
卷积层就像 "特征探测器"比如看一张猫的照片时,它不会一下子看全整张图,而是用很多小 "过滤器"(比如检测边缘、颜色块、纹理的小工具)在图片上滑动,每次只关注一小片区域。这样就能提取出图片里的关键特征,比如猫的胡须边缘、耳朵的形状、毛色的深浅变化等
池化层就像 "信息精简器"卷积层提取出的特征可能很细致但数据量太大,池化层会把相邻的信息合并一下(比如只保留一片区域里最亮的点),让特征变 "浓缩"。比如把一张大照片缩成小照片,但重要特征(像猫的眼睛位置)还能保留,这样既能减少参数量从而减少计算量,又能让特征更稳定
全连接层就像 "最终决策者"经过前面两层处理后,已经得到了很多关键特征(比如 "有胡须"" 三角形耳朵 ""毛茸茸")。全连接层会把这些特征全部连接起来做综合判断,比如把所有特征汇总后得出结论:"这张图里有 90% 的概率是一只猫"
简单说,卷积层负责 "找特征",池化层负责 "精简特征",全连接层负责 "用特征做判断"
非线性激活把非线性激活想象成给神经网络 "注入活力" 的过程。
假设没有非线性激活,不管神经网络有多少层,本质上都相当于做一次简单的线性计算(就像 y=ax+b 这样的直线关系)。这样的网络再深,也只能处理简单的线性问题,比如 "房价和面积成正比" 这种关系。
但现实世界的问题大多是复杂的非线性关系 —— 比如 "图片里是不是猫",没法用简单的直线公式来表达。
这时候非线性激活就派上用场了,它就像一个 "转换器",能把输入的数值做一番非线性处理后再输出。比如最常用的 ReLU 激活函数,它会把所有负数变成 0,正数保持不变,就像一个 "过滤器"。
有了这种非线性转换,神经网络才能学会处理复杂的曲线关系、组合特征。比如识别猫的时候,它能把 "三角形耳朵 + 毛茸茸 + 胡须" 这些特征用非线性的方式组合起来,而不是简单地把这些特征加加减减。
那么为什么需要非线性?
比如识别猫的时候:
- 卷积层可能提取出 "有胡须(x1=2)"、"耳朵是三角形(x2=3)"、"背景是草地(x3=-1)"
- 经过激活函数后,ReLU 会保留 x1=2、x2=3,过滤 x3=-1
- 这些非线性处理后的特征再传给全连接层,才能组合出 "有胡须且耳朵是三角形 = 猫" 的复杂判断
如果没有激活函数,就只能做简单的加法(2+3+(-1)=4),无法体现 "且" 这种非线性关系。
简单说:没有非线性激活,神经网络就是个 "死脑筋" 只会算直线;有了它,神经网络才能 "灵活思考",处理各种复杂问题。
接下来我们把刚才数据处理部分的batch_size改为64,用一个线性层实现一下将img分为10类。
首先展平imgs,即展平一个批次的64张图片(64*3*32*32),为(1,1,1,196608),然后通过torch提供的线性层来实现变换
import torch
import torchvision
from torch import nn
from torch.nn import Flatten, Linear
from torch.utils.data import DataLoader
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10("dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10("dataset", train=False, transform=dataset_transform, download=True)
test_loader = DataLoader(test_set, batch_size=64, shuffle=True)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = Linear(196608, 10)
def forward(self, x):
x = self.model(x)
return x
model = MyModel()
for data in test_loader:
imgs, targets = data
print(imgs.shape)
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs)
print(output.shape)
output = model(output)
print(output.shape)三、误差反向传播和优化器
创建网络(VGG16)
# 网络
class MyConvModel(nn.Module):
def __init__(self):
super(MyConvModel, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64 * 4 * 4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x定义损失函数和优化器,并且让其反向传播,保留参数梯度
import torch
import torchvision
from torch import nn
from torch.nn import Flatten, Linear, Sequential, Conv2d, MaxPool2d
from torch.utils.data import DataLoader
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10("dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10("dataset", train=False, transform=dataset_transform, download=True)
test_loader = DataLoader(test_set, batch_size=64, shuffle=True)
# 网络
class MyConvModel(nn.Module):
def __init__(self):
super(MyConvModel, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64 * 4 * 4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = MyConvModel()
# 分类任务定义交叉熵损失函数
loss = nn.CrossEntropyLoss()
# 定义学习率
learning_rate = 1e-2
# 定义优化器
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
for data in test_loader:
imgs, targets = data
output = model(imgs)
res_loss = loss(output, targets)
optim.zero_grad()
res_loss.backward()
optim.step()
print(".")其中
for data in test_loader:
imgs, targets = data
output = model(imgs)
res_loss = loss(output, targets)
res_loss.backward()
print(".")是对数据进行一轮的学习,更新参数,res_loss是对这一轮中的一批进行计算loss,然后根据本轮的loss去计算梯度(backward),再去更新参数(step)。那么本批次的更新到此结束。为了不影响下一个批次数据对模型的优化,本批次所记录的梯度需要清0。
总结:因为模型的参数在optim.step()时已经被更新了,梯度只是 “指导参数如何更新的临时计算结果”。清空梯度只是为了避免下一批数据的梯度和上一批混淆,确保每批数据都能独立地 “指导一次参数更新”。
我们可以记录下每一轮的loss总和loss_sum,然后多轮更新计算,观察loss_sum的变化情况
# 训练轮数
epoch = 20
# 定义优化器
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
for i in range(epoch):
loss_sum = 0
for data in test_loader:
imgs, targets = data
output = model(imgs)
res_loss = loss(output, targets)
optim.zero_grad()
res_loss.backward()
optim.step()
loss_sum += res_loss
print(loss_sum)四、模型的加载和保存
上面我们训练好了一个误差相对较低的模型,我们如何保存它?下一次能不能直接用它而不必重新训练
这里只推荐一种模型保存方式
# 假设你训练好的模型叫 model,优化器叫 optimizer
# 保存模型参数和训练信息(可选)
torch.save({
'model_state_dict': model.state_dict(), # 模型参数
'optimizer_state_dict': optimizer.state_dict(), # 优化器参数(如需继续训练)
'epoch': epoch, # 当前训练的轮数
'loss': loss # 最后的损失值
}, 'model_params.pth') # 保存为 .pth 文件模型的加载方式
# 1. 先创建和训练时一样的模型结构
model = YourModel() # 实例化模型
optimizer = torch.optim.Adam(model.parameters()) # 实例化优化器(如需继续训练)
# 2. 加载保存的参数
checkpoint = torch.load('model_params.pth') # 加载文件
model.load_state_dict(checkpoint['model_state_dict']) # 载入模型参数五、实战分类任务-完整模型训练
1.train和eval
在深度学习中,model.eval() 是一个非常重要的方法,用于将模型切换到评估模式(evaluation mode)。
当你训练完模型,想要用它进行预测或评估时,需要调用这个方法。它主要会影响模型中一些具有特殊行为的层,例如:
- Dropout 层:在评估模式下会停止随机丢弃神经元
- Batch Normalization 层:会使用训练过程中计算的移动平均值和方差,而不是当前批次的统计数据
# 训练阶段
model.train() # 切换到训练模式
for batch in train_loader:
# 训练代码...
# 评估阶段
model.eval() # 切换到评估模式
with torch.no_grad(): # 通常会配合关闭梯度计算以提高效率
for batch in test_loader:
# 评估/预测代码...调用 model.eval() 不会改变模型的权重,只是改变其运行时的行为,确保评估结果的一致性和准确性。完成评估后,如果需要继续训练,应调用 model.train() 切换回训练模式。
2.argmax
argmax(1)返回的是numpy在横向最大值的索引
- 这会进行逐元素比较,得到一个布尔数组
- 例如,如果模型预测为
[1, 3, 5, ...],真实标签为[1, 2, 5, ...] - 比较结果为
[True, False, True, ...] - 形状仍为
[64],True 表示预测正确,False 表示预测错误
# 假设这是一个简化的批次(批次大小=3)
outputs = torch.tensor([
[0.1, 0.8, 0.05, 0.05], # 预测为类别1
[0.7, 0.1, 0.1, 0.1], # 预测为类别0
[0.05, 0.05, 0.8, 0.1] # 预测为类别2
])
targets = torch.tensor([1, 0, 2]) # 真实标签
print(outputs.argmax(1)) # 输出: tensor([1, 0, 2])
print(outputs.argmax(1) == targets) # 输出: tensor([True, True, True])
print((outputs.argmax(1) == targets).sum()) # 输出: tensor(3)所以利用argmax可以计算出一个批次预测正确的个数,从而计算出一轮的正确率
3. 代码
# 导入必要的库
import torch # 导入PyTorch库
import torchvision.datasets # 导入torchvision中的数据集模块
from torch.utils.tensorboard import SummaryWriter # 导入TensorBoard用于可视化
from model import * # 从model模块导入所有内容(这里可能是自定义的一些工具函数)
import time # 导入时间模块,可能用于计时
# 准备数据集
from torch.utils.data import DataLoader # 导入DataLoader用于数据加载
# 加载CIFAR10训练集,保存在"./datasets"目录,train=True表示是训练集
# transform=ToTensor()将图像转换为Tensor格式,download=True表示如果本地没有就下载
train_data = torchvision.datasets.CIFAR10("./datasets",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
# 加载CIFAR10测试集,train=False表示是测试集,其他参数同训练集
test_data = torchvision.datasets.CIFAR10("./datasets",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# 获取训练集和测试集的大小
train_data_size = len(train_data)
test_data_size = len(test_data)
# 打印数据集大小
print("训练集长度{}".format(train_data_size))
print("测试集长度{}".format(test_data_size))
# 使用DataLoader加载数据集,batch_size=64表示每次加载64个样本
train_dataloader = DataLoader(train_data, 64)
test_dataloader = DataLoader(test_data, 64)
# 定义卷积神经网络模型
class MyConvModel(nn.Module): # 继承nn.Module
def __init__(self):
super(MyConvModel, self).__init__() # 调用父类构造函数
# 定义模型序列,包含卷积层、池化层和全连接层
self.model = Sequential(
Conv2d(3, 32, 5, 1, padding=2), # 卷积层:输入3通道,输出32通道,5x5卷积核,步长1,填充2
MaxPool2d(2), # 最大池化层:2x2池化核
Conv2d(32, 32, 5, 1, padding=2), # 卷积层:输入32通道,输出32通道
MaxPool2d(2), # 最大池化层
Conv2d(32, 64, 5, 1, padding=2), # 卷积层:输入32通道,输出64通道
MaxPool2d(2), # 最大池化层
Flatten(), # 展平操作,将多维张量转换为一维
Linear(64 * 4 * 4, 64), # 全连接层:输入维度64*4*4,输出64
Linear(64, 10) # 全连接层:输入64,输出10(CIFAR10有10个类别)
)
# 定义前向传播
def forward(self, x):
x = self.model(x)
return x
# 创建网络模型实例
myConvModel = MyConvModel()
# 定义损失函数,使用交叉熵损失(适用于分类任务)
lossFun = nn.CrossEntropyLoss()
# 设置学习率为0.01
learning_rate = 1e-2
# 定义优化器,使用SGD(随机梯度下降)
optim_sgd = torch.optim.SGD(myConvModel.parameters(), lr=learning_rate)
# 训练相关参数初始化
train_time = 0 # 训练次数计数器
test_time = 0 # 测试次数计数器
epoch = 20 # 训练轮数
# 创建SummaryWriter实例,用于记录日志(保存到"logs_train"目录)
writer = SummaryWriter("logs_train")
# 开始训练循环,共训练epoch轮
for i in range(epoch):
print("第{}轮训练".format(i + 1))
myConvModel.train() # 将模型切换到训练模式
# 遍历训练数据集
for data in train_dataloader:
imgs, targets = data # 获取图像和对应的标签
outputs = myConvModel(imgs) # 将图像输入模型,得到输出
loss = lossFun(outputs, targets) # 计算损失值
# 优化器更新步骤
optim_sgd.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optim_sgd.step() # 更新参数
train_time += 1 # 训练次数加1
# 每训练100次打印一次损失
if train_time % 100 == 0:
print("训练次数{}, loss值是{}".format(train_time, loss.item()))
# 将训练损失写入TensorBoard
writer.add_scalar("train_loss", loss.item(), train_time)
# 每轮训练结束后,在测试集上评估
total_test_loss = 0 # 测试集总损失
total_accuracy = 0 # 测试集总准确率
myConvModel.eval() # 将模型切换到评估模式
with torch.no_grad(): # 关闭梯度计算,节省内存和计算资源
for data in test_dataloader:
imgs, targets = data # 获取测试集图像和标签
outputs = myConvModel(imgs) # 模型预测
test_loss = lossFun(outputs, targets) # 计算测试损失
total_test_loss += test_loss.item() # 累加测试损失
# 计算准确率:预测结果中最大值的索引与标签相同的数量
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy # 累加正确预测的数量
# 打印测试集整体表现
print("整个测试集上的loss:{}".format(total_test_loss))
print("整个测试集上的正确率:{}".format(total_accuracy / test_data_size))
test_time += 1 # 测试次数加1
# 将测试损失和准确率写入TensorBoard
writer.add_scalar("test_loss", total_test_loss, test_time)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, test_time)
# 保存当前轮次的模型
torch.save(myConvModel, "myConvModel_{}.pth".format(i + 1))
print("模型已保存")
# 关闭SummaryWriter
writer.close()六、引入GPU
要将以上训练过程迁移到 GPU 上运行,需要对代码进行几处关键修改,主要涉及将模型、数据和损失函数移动到 GPU 设备上
1.设备选择
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")2.模型移动到 GPU
myConvModel = myConvModel.to(device)3.损失函数移动到GPU
lossFun = lossFun.to(device)4.数据移动到 GPU
imgs = imgs.to(device)
targets = targets.to(device)5.完整代码
import torch
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn # 补充导入nn模块
from model import *
import time
# 准备数据集
from torch.utils.data import DataLoader
# 检查是否有可用的GPU,优先使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
train_data = torchvision.datasets.CIFAR10("./datasets",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("./datasets",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练集长度{}".format(train_data_size))
print("测试集长度{}".format(test_data_size))
# DataLoader加载数据集
train_dataloader = DataLoader(train_data, 64)
test_dataloader = DataLoader(test_data, 64)
# 网络
class MyConvModel(nn.Module):
def __init__(self):
super(MyConvModel, self).__init__()
self.model = nn.Sequential( # 补充nn.前缀
nn.Conv2d(3, 32, 5, 1, padding=2), # 补充nn.前缀
nn.MaxPool2d(2), # 补充nn.前缀
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(), # 补充nn.前缀
nn.Linear(64 * 4 * 4, 64), # 补充nn.前缀
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 网络模型创建并移动到GPU
myConvModel = MyConvModel()
myConvModel = myConvModel.to(device) # 将模型移动到GPU
# 损失函数创建并移动到GPU
lossFun = nn.CrossEntropyLoss()
lossFun = lossFun.to(device) # 将损失函数移动到GPU
# 学习率
learning_rate = 1e-2
# 优化器
optim_sgd = torch.optim.SGD(myConvModel.parameters(), lr=learning_rate)
# 参数
train_time = 0
test_time = 0
epoch = 20
# 可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("第{}轮训练".format(i + 1))
myConvModel.train()
start_time = time.time() # 记录训练开始时间
for data in train_dataloader:
imgs, targets = data
# 将数据移动到GPU
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myConvModel(imgs)
loss = lossFun(outputs, targets)
optim_sgd.zero_grad()
loss.backward()
optim_sgd.step()
train_time = train_time + 1
if train_time % 100 == 0:
end_time = time.time()
print(f"训练次数{train_time}, loss值是{loss.item()}, 耗时{end_time - start_time:.2f}秒")
writer.add_scalar("train_loss", loss.item(), train_time)
# 在测试集上
total_test_loss = 0
total_accuracy = 0
myConvModel.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
# 将测试数据移动到GPU
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myConvModel(imgs)
test_loss = lossFun(outputs, targets)
total_test_loss = total_test_loss + test_loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
# 计算准确率时将结果移回CPU并转换为浮点数
print("整个测试集上的loss:{}".format(total_test_loss))
print("整个测试集上的正确率:{}".format(total_accuracy.to("cpu").item() / test_data_size))
test_time = test_time + 1
writer.add_scalar("test_loss", total_test_loss, test_time)
writer.add_scalar("test_accuracy", total_accuracy.to("cpu").item() / test_data_size, test_time)
# 保存模型
torch.save(myConvModel, "myConvModel_{}.pth".format(i + 1))
print("模型已保存")
writer.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号