

基于阿里云调用Deepseek:企业级AI应用开发实战指南
在人工智能技术飞速发展的今天,大型语言模型正成为企业数字化转型的核心驱动力。本文将深入探讨如何基于阿里云平台高效调用Deepseek模型,构建稳定可靠的企业级AI应用解决方案。
一、Deepseek模型与阿里云集成概述
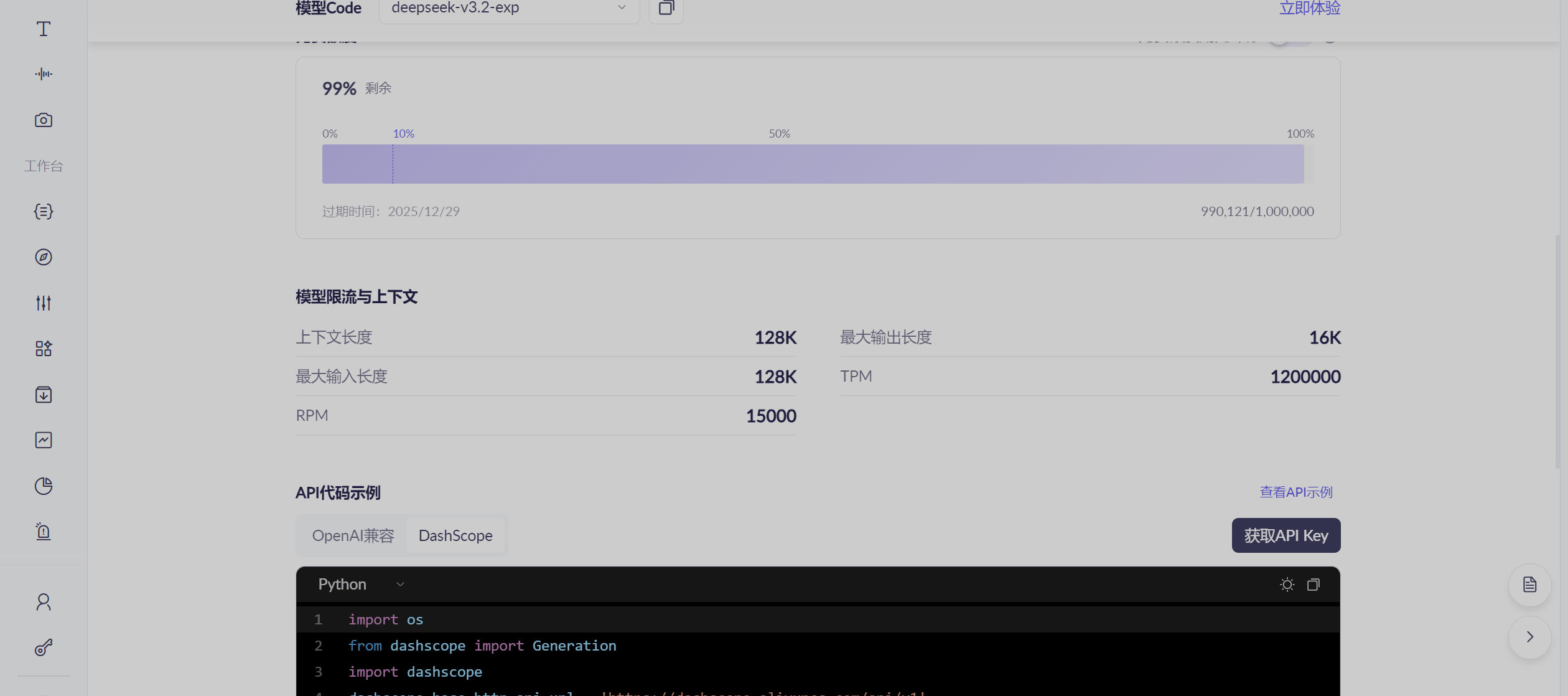
1.1 Deepseek模型的技术优势
Deepseek作为国内领先的大语言模型,在多个基准测试中表现出色,其核心优势体现在:
- 多模态理解能力:支持文本、代码、数学公式等多种信息形式的处理
- 高效推理架构:采用创新的稀疏注意力机制,在保持性能的同时大幅降低计算成本
- 长上下文支持:最高支持128K上下文长度,适合处理长文档分析和复杂对话场景
- 成本效益突出:相比国际同类模型,提供更具竞争力的价格性能比
1.2 阿里云API网关的技术价值
阿里云作为国内领先的云服务提供商,为Deepseek模型调用提供了企业级的支持保障:
// 阿里云API调用的基础配置类
public class AliyunConfig {
// 设置API基础地址,确保网络连通性
static {
Constants.baseHttpApiUrl = "https://dashscope.aliyuncs.com/api/v1";
}
// API Key安全管理最佳实践
private static final String API_KEY = System.getenv("DASHSCOPE_API_KEY");
public static String getApiKey() {
if (API_KEY == null || API_KEY.trim().isEmpty()) {
throw new IllegalStateException("请设置DASHSCOPE_API_KEY环境变量");
}
return API_KEY;
}
}这段配置代码展示了阿里云API调用的两个关键要素:首先是API端点的基础地址配置,这是所有请求的路由入口;其次是API密钥的安全管理,通过环境变量获取而非硬编码在代码中,这符合企业级应用的安全规范。在实际生产环境中,还可以进一步集成阿里云的KMS服务对密钥进行加密管理。
1.3 技术架构全景图
企业级Deepseek应用通常采用分层架构设计:
这种架构确保了系统的高可用性、可扩展性和可维护性,各层之间通过明确的接口进行通信,便于团队协作和故障排查。
二、环境配置与SDK集成
2.1 项目初始化与依赖管理
使用Maven进行依赖管理是Java项目的标准做法,以下是pom.xml的关键配置:
<dependencies>
<!-- 阿里云DashScope SDK -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.8.4</version>
</dependency>
<!-- 日志框架 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.7</version>
</dependency>
<!-- JSON处理 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.9.3</version>
<scope>test</scope>
</dependency>
</dependencies>依赖配置涵盖了核心SDK、日志记录、数据序列化和测试框架,这些都是构建健壮应用程序的基础组件。选择版本时应注意使用最新的稳定版本,以获得性能改进和安全更新。
2.2 身份认证配置
安全的身份认证是企业应用的第一道防线,下面实现一个完整的认证管理类:
public class SecureAuthManager {
private static final Logger logger = LoggerFactory.getLogger(SecureAuthManager.class);
// 使用枚举定义支持的模型类型,提高代码可读性和安全性
public enum DeepseekModel {
DEEPSEEK_V3_2_EXP("deepseek-v3.2-exp", "Deepseek最新实验版本"),
DEEPSEEK_V3("deepseek-v3", "Deepseek稳定版本"),
DEEPSEEK_CODER("deepseek-coder", "Deepseek代码专用版本");
private final String modelId;
private final String description;
DeepseekModel(String modelId, String description) {
this.modelId = modelId;
this.description = description;
}
public String getModelId() {
return modelId;
}
}
/**
* 验证API Key格式的合法性
* 有效的API Key应以'sk-'开头且长度符合预期
*/
public static boolean validateApiKeyFormat(String apiKey) {
if (apiKey == null || apiKey.trim().isEmpty()) {
logger.error("API Key不能为空");
return false;
}
if (!apiKey.startsWith("sk-")) {
logger.error("API Key格式错误,应以'sk-'开头");
return false;
}
// 基础长度验证,实际长度可能因密钥类型而异
if (apiKey.length() < 10) {
logger.error("API Key长度异常");
return false;
}
logger.info("API Key格式验证通过");
return true;
}
/**
* 创建安全的HTTP客户端配置
* 设置合理的超时时间和重试策略
*/
public static OkHttpClient createSecureHttpClient() {
return new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS) // 连接超时
.readTimeout(60, TimeUnit.SECONDS) // 读取超时
.writeTimeout(30, TimeUnit.SECONDS) // 写入超时
.retryOnConnectionFailure(true) // 连接失败重试
.addInterceptor(new LoggingInterceptor()) // 请求日志拦截器
.build();
}
}认证管理类采用了多层安全策略:首先通过枚举类型限制可用的模型选择,避免因拼写错误导致的调用失败;其次对API Key进行格式验证,确保基本的合法性;最后配置了具有完备超时控制和重试机制的HTTP客户端,这些措施共同保障了API调用的安全性和稳定性。
2.3 配置管理最佳实践
在微服务架构中,集中化的配置管理至关重要:
@Configuration
@ConfigurationProperties(prefix = "deepseek")
@Data
public class DeepseekConfig {
private String apiKey;
private String baseUrl = "https://dashscope.aliyuncs.com/api/v1";
private String defaultModel = "deepseek-v3.2-exp";
private int maxRetries = 3;
private long retryDelay = 1000L;
private int timeoutSeconds = 60;
@PostConstruct
public void validateConfig() {
if (!SecureAuthManager.validateApiKeyFormat(apiKey)) {
throw new IllegalStateException("Deepseek配置验证失败: API Key格式不正确");
}
logger.info("Deepseek配置初始化完成,默认模型: {}", defaultModel);
}
}通过Spring Boot的配置属性特性,我们可以将所有的API参数外部化,实现配置与代码的分离。这样在不同环境(开发、测试、生产)中部署时,只需调整配置文件而不需要修改代码,大大提高了部署的灵活性和安全性。
三、核心API调用机制解析
3.1 消息构建器模式
消息构建是API调用的基础,采用建造者模式可以创建灵活且可读的消息结构:
public class MessageBuilder {
private List<Message> messages = new ArrayList<>();
/**
* 添加系统提示词,用于设定AI助手的角色和行为特征
* 系统消息通常位于对话开头,为整个对话设定基调
*/
public MessageBuilder systemMessage(String content) {
Message systemMsg = Message.builder()
.role(Role.SYSTEM.getValue())
.content(content)
.build();
messages.add(systemMsg);
return this;
}
/**
* 添加用户消息,代表用户的输入或问题
* 可以包含文本、代码或其他需要AI处理的内容
*/
public MessageBuilder userMessage(String content) {
Message userMsg = Message.builder()
.role(Role.USER.getValue())
.content(content)
.build();
messages.add(userMsg);
return this;
}
/**
* 添加助手回复,用于多轮对话场景
* 在流式对话或对话历史重建时特别有用
*/
public MessageBuilder assistantMessage(String content) {
Message assistantMsg = Message.builder()
.role(Role.ASSISTANT.getValue())
.content(content)
.build();
messages.add(assistantMsg);
return this;
}
/**
* 构建最终的消息列表
* 确保消息顺序符合API要求
*/
public List<Message> build() {
if (messages.isEmpty()) {
throw new IllegalStateException("消息列表不能为空");
}
// 验证消息角色交替的合理性
validateMessageSequence();
return new ArrayList<>(messages);
}
private void validateMessageSequence() {
// 实现消息序列验证逻辑
// 例如:不能连续两个相同角色的消息等
}
}消息构建器封装了对话消息的创建逻辑,通过链式调用提供流畅的API使用体验。系统消息用于设定AI的角色定位,用户消息承载具体的查询需求,助手消息则可用于提供对话上下文。这种结构化的消息构建方式确保了对话的连贯性和准确性。
3.2 高级生成参数配置
生成参数直接影响模型的行为和输出质量,需要精细调控:
public class GenerationParamBuilder {
private String apiKey;
private String model = "deepseek-v3.2-exp";
private List<Message> messages;
private GenerationParam.ResultFormat resultFormat = GenerationParam.ResultFormat.MESSAGE;
private boolean enableThinking = true;
private Double temperature = 0.7;
private Integer maxTokens = 2000;
private Double topP = 0.9;
public GenerationParamBuilder apiKey(String apiKey) {
this.apiKey = apiKey;
return this;
}
public GenerationParamBuilder model(String model) {
this.model = model;
return this;
}
public GenerationParamBuilder messages(List<Message> messages) {
this.messages = messages;
return this;
}
/**
* 设置温度参数,控制输出的随机性
* 较低的值(如0.1)使输出更确定,较高的值(如1.0)更随机有创意
*/
public GenerationParamBuilder temperature(Double temperature) {
if (temperature != null && (temperature < 0.0 || temperature > 2.0)) {
throw new IllegalArgumentException("Temperature必须在0.0到2.0之间");
}
this.temperature = temperature;
return this;
}
/**
* 设置最大输出token数量
* 需要根据模型上下文长度和实际需求合理设置
*/
public GenerationParamBuilder maxTokens(Integer maxTokens) {
if (maxTokens != null && maxTokens <= 0) {
throw new IllegalArgumentException("Max tokens必须大于0");
}
this.maxTokens = maxTokens;
return this;
}
/**
* 启用思维链功能,让模型展示推理过程
* 这对于需要透明推理的学术或分析场景特别有价值
*/
public GenerationParamBuilder enableThinking(boolean enableThinking) {
this.enableThinking = enableThinking;
return this;
}
public GenerationParam build() {
if (apiKey == null || apiKey.trim().isEmpty()) {
throw new IllegalStateException("API Key不能为空");
}
if (messages == null || messages.isEmpty()) {
throw new IllegalStateException("消息列表不能为空");
}
GenerationParam.Builder paramBuilder = GenerationParam.builder()
.apiKey(apiKey)
.model(model)
.messages(messages)
.resultFormat(resultFormat)
.enableThinking(enableThinking);
// 可选参数设置
if (temperature != null) {
paramBuilder.temperature(temperature);
}
if (maxTokens != null) {
paramBuilder.maxTokens(maxTokens);
}
if (topP != null) {
paramBuilder.topP(topP);
}
return paramBuilder.build();
}
}生成参数构建器提供了对模型行为的精细控制。温度参数影响输出的创造性,在需要确定性答案的场景(如代码生成)应设置较低值,在创意写作场景则可适当提高。最大token数需要根据具体任务和模型上下文窗口合理设置,避免截断或资源浪费。思维链功能开启后,模型会展示其推理过程,这对于教育应用和需要可解释AI的场景非常有价值。
3.3 完整的API调用流程
将各个组件组合起来形成完整的调用流程:
@Service
@Slf4j
public class DeepseekService {
private final DeepseekConfig config;
public DeepseekService(DeepseekConfig config) {
this.config = config;
}
/**
* 执行完整的Deepseek API调用流程
* 包含参数验证、API调用、结果处理和异常管理
*/
public GenerationResult executeCompletion(String systemPrompt, String userMessage) {
try {
// 1. 构建消息序列
List<Message> messages = new MessageBuilder()
.systemMessage(systemPrompt)
.userMessage(userMessage)
.build();
// 2. 配置生成参数
GenerationParam param = new GenerationParamBuilder()
.apiKey(config.getApiKey())
.model(config.getDefaultModel())
.messages(messages)
.temperature(0.7)
.maxTokens(2000)
.enableThinking(true)
.build();
// 3. 创建Generation实例并执行调用
Generation generation = new Generation();
GenerationResult result = generation.call(param);
// 4. 验证响应结果
validateGenerationResult(result);
log.info("Deepseek API调用成功,生成{}个token",
result.getUsage().getOutputTokens());
return result;
} catch (ApiException e) {
log.error("API调用异常,错误码: {}, 错误信息: {}",
e.getCode(), e.getMessage(), e);
throw new BusinessException("AI服务调用失败", e);
} catch (InputRequiredException e) {
log.error("输入参数异常: {}", e.getMessage(), e);
throw new BusinessException("请求参数不正确", e);
} catch (NoApiKeyException e) {
log.error("API密钥异常: {}", e.getMessage(), e);
throw new BusinessException("服务认证失败", e);
}
}
/**
* 验证API响应结果的完整性
*/
private void validateGenerationResult(GenerationResult result) {
if (result == null) {
throw new BusinessException("API响应为空");
}
if (result.getOutput() == null) {
throw new BusinessException("API输出为空");
}
if (result.getOutput().getChoices() == null ||
result.getOutput().getChoices().isEmpty()) {
throw new BusinessException("API未返回有效选择");
}
// 验证使用量统计
if (result.getUsage() != null) {
log.debug("本次调用使用情况 - 输入token: {}, 输出token: {}",
result.getUsage().getInputTokens(),
result.getUsage().getOutputTokens());
}
}
/**
* 提取模型回复内容
*/
public String extractResponseContent(GenerationResult result) {
return result.getOutput().getChoices().get(0).getMessage().getContent();
}
/**
* 提取思维链内容(如果启用)
*/
public String extractReasoningContent(GenerationResult result) {
return result.getOutput().getChoices().get(0).getMessage().getReasoningContent();
}
}完整的API调用服务封装了从消息构建到结果处理的整个流程。通过分层异常处理,能够准确识别和区分不同类型的错误,为上层调用方提供清晰的错误信息。结果验证确保返回数据的完整性,避免空指针异常。同时,服务还提供了便捷的方法来提取回复内容和思维链信息,简化了客户端的使用。
四、高级特性与实战应用
4.1 流式响应处理
对于生成长文本的场景,流式响应能够显著提升用户体验:
@Component
@Slf4j
public class StreamResponseHandler {
/**
* 处理流式响应,适用于实时对话和长文本生成场景
* 通过回调函数逐步处理每个数据块,实现实时显示效果
*/
public void handleStreamResponse(GenerationParam param,
StreamCallback callback) {
try {
Generation generation = new Generation();
// 启用流式输出
param.setIncrementalOutput(true);
generation.streamCall(param, new GenerationCallback() {
private final StringBuilder fullContent = new StringBuilder();
private final StringBuilder reasoningContent = new StringBuilder();
@Override
public void onEvent(GenerationResult result) {
try {
if (result != null && result.getOutput() != null) {
List<Choice> choices = result.getOutput().getChoices();
if (choices != null && !choices.isEmpty()) {
Message message = choices.get(0).getMessage();
// 处理主要内容
if (message.getContent() != null) {
String contentChunk = message.getContent();
fullContent.append(contentChunk);
callback.onContentUpdate(contentChunk, fullContent.toString());
}
// 处理思维链内容
if (message.getReasoningContent() != null) {
String reasoningChunk = message.getReasoningContent();
reasoningContent.append(reasoningChunk);
callback.onReasoningUpdate(reasoningChunk, reasoningContent.toString());
}
}
}
} catch (Exception e) {
log.error("处理流式响应数据块时发生异常", e);
callback.onError(e);
}
}
@Override
public void onComplete() {
callback.onComplete(fullContent.toString(),
reasoningContent.toString());
}
@Override
public void onError(ApiException e) {
log.error("流式调用发生API异常", e);
callback.onError(e);
}
});
} catch (Exception e) {
log.error("初始化流式调用失败", e);
callback.onError(e);
}
}
/**
* 流式回调接口,供客户端实现具体处理逻辑
*/
public interface StreamCallback {
void onContentUpdate(String chunk, String fullContent);
void onReasoningUpdate(String chunk, String fullReasoning);
void onComplete(String fullContent, String fullReasoning);
void onError(Exception e);
}
/**
* 示例:在WebSocket中使用流式响应
*/
@Component
@Slf4j
public class WebSocketStreamHandler implements StreamCallback {
private final SimpMessagingTemplate messagingTemplate;
private final String sessionId;
public WebSocketStreamHandler(SimpMessagingTemplate messagingTemplate, String sessionId) {
this.messagingTemplate = messagingTemplate;
this.sessionId = sessionId;
}
@Override
public void onContentUpdate(String chunk, String fullContent) {
// 通过WebSocket实时推送内容更新
Map<String, Object> response = new HashMap<>();
response.put("type", "content_update");
response.put("chunk", chunk);
response.put("fullContent", fullContent);
response.put("timestamp", System.currentTimeMillis());
messagingTemplate.convertAndSendToUser(
sessionId,
"/queue/ai-response",
response
);
}
@Override
public void onReasoningUpdate(String chunk, String fullReasoning) {
// 推送思维链更新
Map<String, Object> response = new HashMap<>();
response.put("type", "reasoning_update");
response.put("chunk", chunk);
response.put("fullReasoning", fullReasoning);
response.put("timestamp", System.currentTimeMillis());
messagingTemplate.convertAndSendToUser(
sessionId,
"/queue/ai-reasoning",
response
);
}
@Override
public void onComplete(String fullContent, String fullReasoning) {
// 推送完成信号
Map<String, Object> response = new HashMap<>();
response.put("type", "complete");
response.put("fullContent", fullContent);
response.put("fullReasoning", fullReasoning);
response.put("timestamp", System.currentTimeMillis());
messagingTemplate.convertAndSendToUser(
sessionId,
"/queue/ai-response",
response
);
log.info("流式响应完成,总内容长度: {}", fullContent.length());
}
@Override
public void onError(Exception e) {
// 推送错误信息
Map<String, Object> response = new HashMap<>();
response.put("type", "error");
response.put("message", e.getMessage());
response.put("timestamp", System.currentTimeMillis());
messagingTemplate.convertAndSendToUser(
sessionId,
"/queue/ai-error",
response
);
log.error("流式响应处理失败", e);
}
}
}流式响应处理器通过回调机制实现了数据的渐进式处理,特别适合需要实时显示生成内容的场景。在Web应用中,可以结合WebSocket技术将每个数据块实时推送到前端,用户能够立即看到生成过程,大大提升了交互体验。思维链内容的单独处理使得推理过程可以独立展示,对于教育类应用尤其有价值。
4.2 多轮对话管理系统
实现连贯的多轮对话需要维护对话历史和上下文:
@Service
@Slf4j
public class ConversationManager {
private final Map<String, ConversationSession> sessions = new ConcurrentHashMap<>();
private final DeepseekService deepseekService;
// 会话超时时间配置(单位:分钟)
@Value("${conversation.timeout:30}")
private int sessionTimeout;
public ConversationManager(DeepseekService deepseekService) {
this.deepseekService = deepseekService;
}
/**
* 创建或获取对话会话
* 每个会话维护独立的对话历史和上下文
*/
public ConversationSession getOrCreateSession(String sessionId) {
return sessions.computeIfAbsent(sessionId, id -> {
ConversationSession session = new ConversationSession(id);
log.info("创建新的对话会话: {}", id);
return session;
});
}
/**
* 处理用户消息并维护对话上下文
*/
public ConversationResponse handleUserMessage(String sessionId, String userMessage) {
try {
ConversationSession session = getOrCreateSession(sessionId);
session.updateLastAccessTime();
// 添加用户消息到对话历史
session.addMessage(Role.USER, userMessage);
// 构建系统提示词,包含对话上下文
String systemPrompt = buildSystemPrompt(session);
// 调用Deepseek服务
GenerationResult result = deepseekService.executeCompletion(
systemPrompt, userMessage);
// 提取助手回复
String assistantResponse = deepseekService.extractResponseContent(result);
String reasoningContent = deepseekService.extractReasoningContent(result);
// 添加助手回复到对话历史
session.addMessage(Role.ASSISTANT, assistantResponse);
// 构建响应
ConversationResponse response = ConversationResponse.builder()
.sessionId(sessionId)
.response(assistantResponse)
.reasoning(reasoningContent)
.tokenUsage(result.getUsage())
.turnCount(session.getMessageCount() / 2) // 每轮对话包含用户和助手各一条消息
.build();
log.debug("会话 {} 第 {} 轮对话处理完成", sessionId, response.getTurnCount());
return response;
} catch (Exception e) {
log.error("处理会话 {} 的消息时发生异常", sessionId, e);
throw new BusinessException("对话处理失败", e);
}
}
/**
* 构建包含对话历史和上下文的系统提示词
*/
private String buildSystemPrompt(ConversationSession session) {
StringBuilder prompt = new StringBuilder();
// 基础系统指令
prompt.append("你是一个有帮助的AI助手。请根据对话历史提供准确、有用的回答。\n\n");
// 添加对话历史(最近几轮)
List<Message> recentHistory = session.getRecentMessages(5); // 最近5轮对话
if (!recentHistory.isEmpty()) {
prompt.append("对话历史:\n");
for (Message message : recentHistory) {
String role = message.getRole().equals(Role.USER.getValue()) ? "用户" : "助手";
prompt.append(role).append(": ").append(message.getContent()).append("\n");
}
prompt.append("\n");
}
// 添加上下文指令
prompt.append("请基于以上对话历史,回应用户的最新问题。保持回答连贯且符合上下文。");
return prompt.toString();
}
/**
* 清理过期会话,防止内存泄漏
*/
@Scheduled(fixedRate = 300000) // 每5分钟执行一次
public void cleanupExpiredSessions() {
long currentTime = System.currentTimeMillis();
long timeoutMillis = sessionTimeout * 60 * 1000L;
Iterator<Map.Entry<String, ConversationSession>> iterator = sessions.entrySet().iterator();
int removedCount = 0;
while (iterator.hasNext()) {
Map.Entry<String, ConversationSession> entry = iterator.next();
ConversationSession session = entry.getValue();
if (currentTime - session.getLastAccessTime() > timeoutMillis) {
iterator.remove();
removedCount++;
log.debug("清理过期会话: {}", entry.getKey());
}
}
if (removedCount > 0) {
log.info("会话清理完成,共移除 {} 个过期会话", removedCount);
}
}
/**
* 获取会话统计信息
*/
public SessionStats getSessionStats() {
return SessionStats.builder()
.totalSessions(sessions.size())
.averageTurns(sessions.values().stream()
.mapToInt(ConversationSession::getMessageCount)
.average()
.orElse(0.0))
.build();
}
}
/**
* 对话会话实体类
*/
@Data
@Builder
class ConversationSession {
private final String sessionId;
private final List<Message> messages = new ArrayList<>();
private long createTime;
private long lastAccessTime;
public ConversationSession(String sessionId) {
this.sessionId = sessionId;
this.createTime = System.currentTimeMillis();
this.lastAccessTime = this.createTime;
}
public void addMessage(Role role, String content) {
Message message = Message.builder()
.role(role.getValue())
.content(content)
.build();
messages.add(message);
this.lastAccessTime = System.currentTimeMillis();
}
public void updateLastAccessTime() {
this.lastAccessTime = System.currentTimeMillis();
}
public int getMessageCount() {
return messages.size();
}
/**
* 获取最近N条消息,用于维护有限的对话历史
*/
public List<Message> getRecentMessages(int count) {
if (messages.size() <= count) {
return new ArrayList<>(messages);
}
return messages.subList(messages.size() - count, messages.size());
}
}多轮对话管理系统通过会话机制维护了用户与AI之间的对话上下文。每个会话独立存储对话历史,系统提示词会包含最近的对话记录,确保AI能够理解当前对话的上下文。定时清理机制防止了内存泄漏,统计功能则便于监控系统运行状态。这种设计支持复杂的多轮交互场景,如客服对话、教学辅导等需要长期记忆的应用。
4.3 企业级应用示例:智能客服系统
下面展示一个完整的智能客服系统实现:
@RestController
@RequestMapping("/api/customer-service")
@Slf4j
public class CustomerServiceController {
private final ConversationManager conversationManager;
private final StreamResponseHandler streamResponseHandler;
public CustomerServiceController(ConversationManager conversationManager,
StreamResponseHandler streamResponseHandler) {
this.conversationManager = conversationManager;
this.streamResponseHandler = streamResponseHandler;
}
/**
* 处理客户咨询 - 同步接口
*/
@PostMapping("/consult")
public ResponseEntity<ApiResponse<ConsultationResponse>> handleConsultation(
@RequestBody ConsultationRequest request) {
try {
// 验证请求参数
validateConsultationRequest(request);
// 设置客服专用的系统提示词
String systemPrompt = buildCustomerServicePrompt(request.getProductType());
// 处理用户消息
ConversationResponse conversationResponse =
conversationManager.handleUserMessage(request.getSessionId(), request.getQuestion());
// 构建响应
ConsultationResponse response = ConsultationResponse.builder()
.answer(conversationResponse.getResponse())
.reasoning(conversationResponse.getReasoning())
.sessionId(request.getSessionId())
.suggestedQuestions(generateSuggestedQuestions(conversationResponse.getResponse()))
.timestamp(System.currentTimeMillis())
.build();
log.info("客户咨询处理完成,会话: {}, 产品类型: {}",
request.getSessionId(), request.getProductType());
return ResponseEntity.ok(ApiResponse.success(response));
} catch (BusinessException e) {
log.warn("业务异常处理客户咨询: {}", e.getMessage());
return ResponseEntity.badRequest().body(ApiResponse.error(e.getMessage()));
} catch (Exception e) {
log.error("处理客户咨询时发生系统异常", e);
return ResponseEntity.internalServerError()
.body(ApiResponse.error("系统繁忙,请稍后重试"));
}
}
/**
* 流式客服咨询 - 适用于实时对话场景
*/
@PostMapping("/consult/stream")
public SseEmitter streamConsultation(@RequestBody ConsultationRequest request) {
SseEmitter emitter = new SseEmitter(5 * 60 * 1000L); // 5分钟超时
try {
// 构建消息
List<Message> messages = new MessageBuilder()
.systemMessage(buildCustomerServicePrompt(request.getProductType()))
.userMessage(request.getQuestion())
.build();
// 构建生成参数
GenerationParam param = new GenerationParamBuilder()
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("deepseek-v3.2-exp")
.messages(messages)
.temperature(0.3) // 客服场景使用较低温度,保证回答一致性
.maxTokens(1000)
.enableThinking(true)
.build();
// 创建流式回调
StreamResponseHandler.StreamCallback callback =
createStreamCallback(emitter, request.getSessionId());
// 在后台线程中执行流式调用
CompletableFuture.runAsync(() -> {
streamResponseHandler.handleStreamResponse(param, callback);
});
} catch (Exception e) {
log.error("初始化流式客服咨询失败", e);
emitter.completeWithError(e);
}
return emitter;
}
/**
* 创建SSE流式回调
*/
private StreamResponseHandler.StreamCallback createStreamCallback(SseEmitter emitter, String sessionId) {
return new StreamResponseHandler.StreamCallback() {
private final StringBuilder fullContent = new StringBuilder();
@Override
public void onContentUpdate(String chunk, String fullContent) {
try {
this.fullContent.append(chunk);
StreamResponse response = StreamResponse.builder()
.type("content")
.data(chunk)
.fullContent(this.fullContent.toString())
.timestamp(System.currentTimeMillis())
.build();
emitter.send(SseEmitter.event()
.name("message")
.data(response));
} catch (IOException e) {
log.error("发送SSE消息失败", e);
onError(e);
}
}
@Override
public void onReasoningUpdate(String chunk, String fullReasoning) {
try {
StreamResponse response = StreamResponse.builder()
.type("reasoning")
.data(chunk)
.fullContent(fullReasoning)
.timestamp(System.currentTimeMillis())
.build();
emitter.send(SseEmitter.event()
.name("reasoning")
.data(response));
} catch (IOException e) {
log.error("发送SSE推理内容失败", e);
onError(e);
}
}
@Override
public void onComplete(String fullContent, String fullReasoning) {
try {
StreamResponse response = StreamResponse.builder()
.type("complete")
.data("")
.fullContent(fullContent)
.timestamp(System.currentTimeMillis())
.build();
emitter.send(SseEmitter.event()
.name("complete")
.data(response));
emitter.complete();
log.info("流式客服咨询完成,会话: {}, 内容长度: {}",
sessionId, fullContent.length());
} catch (IOException e) {
log.error("发送SSE完成消息失败", e);
emitter.completeWithError(e);
}
}
@Override
public void onError(Exception e) {
try {
StreamResponse response = StreamResponse.builder()
.type("error")
.data(e.getMessage())
.timestamp(System.currentTimeMillis())
.build();
emitter.send(SseEmitter.event()
.name("error")
.data(response));
emitter.complete();
} catch (IOException ex) {
log.error("发送SSE错误消息失败", ex);
emitter.completeWithError(ex);
}
}
};
}
/**
* 构建客服专用的系统提示词
*/
private String buildCustomerServicePrompt(String productType) {
StringBuilder prompt = new StringBuilder();
prompt.append("你是一个专业的客户服务助手。请遵循以下指导原则:\n");
prompt.append("1. 始终保持友好、专业和耐心的态度\n");
prompt.append("2. 准确理解客户问题,提供清晰、有用的解答\n");
prompt.append("3. 对于不确定的问题,不要猜测,建议客户联系人工客服\n");
prompt.append("4. 严格遵守公司政策和服务规范\n");
if (productType != null && !productType.trim().isEmpty()) {
prompt.append("\n当前服务产品类型:").append(productType).append("\n");
// 根据产品类型添加特定知识
switch (productType.toLowerCase()) {
case "insurance":
prompt.append("你正在处理保险业务咨询,请确保回答符合保险行业监管要求\n");
break;
case "banking":
prompt.append("你正在处理银行业务咨询,请注意金融安全和合规要求\n");
break;
case "ecommerce":
prompt.append("你正在处理电商平台咨询,重点关注订单、物流和售后服务\n");
break;
}
}
prompt.append("\n请基于以上指导原则为客户提供优质服务。");
return prompt.toString();
}
/**
* 生成推荐问题
*/
private List<String> generateSuggestedQuestions(String answer) {
// 基于回答内容生成相关推荐问题
// 这里可以使用另一个Deepseek调用或基于规则的方法
List<String> suggestions = new ArrayList<>();
// 示例实现 - 实际应用中可以根据业务逻辑细化
suggestions.add("这个问题还有其他解决方案吗?");
suggestions.add("我需要准备哪些材料?");
suggestions.add("处理时间需要多久?");
suggestions.add("如何联系人工客服?");
return suggestions.subList(0, Math.min(3, suggestions.size()));
}
private void validateConsultationRequest(ConsultationRequest request) {
if (request.getSessionId() == null || request.getSessionId().trim().isEmpty()) {
throw new BusinessException("会话ID不能为空");
}
if (request.getQuestion() == null || request.getQuestion().trim().isEmpty()) {
throw new BusinessException("咨询问题不能为空");
}
if (request.getQuestion().length() > 1000) {
throw new BusinessException("问题内容过长");
}
}
}
/**
* 咨询请求DTO
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
class ConsultationRequest {
@NotBlank(message = "会话ID不能为空")
private String sessionId;
@NotBlank(message = "咨询问题不能为空")
@Size(max = 1000, message = "问题内容不能超过1000字符")
private String question;
private String productType;
private Map<String, Object> additionalInfo;
}
/**
* 咨询响应DTO
*/
@Data
@Builder
class ConsultationResponse {
private String answer;
private String reasoning;
private String sessionId;
private List<String> suggestedQuestions;
private long timestamp;
}智能客服系统展示了Deepseek在企业级场景中的完整应用。系统提供了同步和流式两种接口,满足不同客户端的需要。通过专门的系统提示词定制,确保AI回答符合企业服务标准和行业规范。推荐问题生成功能增强了用户体验,引导对话深入。完整的异常处理和参数验证保证了系统的健壮性。
五、性能优化与监控
5.1 连接池与资源管理
高效的连接管理对高并发场景至关重要:
@Configuration
@Slf4j
public class HttpClientConfig {
@Bean
public OkHttpClient okHttpClient() {
return new OkHttpClient.Builder()
.connectionPool(new ConnectionPool(20, 5, TimeUnit.MINUTES))
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.writeTimeout(10, TimeUnit.SECONDS)
.retryOnConnectionFailure(true)
.addInterceptor(new MetricsInterceptor())
.addInterceptor(new RetryInterceptor())
.eventListener(new HttpEventListener())
.build();
}
/**
* 指标收集拦截器
*/
private static class MetricsInterceptor implements Interceptor {
private final MeterRegistry meterRegistry;
public MetricsInterceptor() {
this.meterRegistry = Metrics.globalRegistry;
}
@Override
public Response intercept(Chain chain) throws IOException {
long startTime = System.nanoTime();
Request request = chain.request();
Response response = null;
try {
response = chain.proceed(request);
long duration = System.nanoTime() - startTime;
// 记录请求指标
meterRegistry.timer("http.requests.duration")
.tag("host", request.url().host())
.tag("method", request.method())
.tag("status", String.valueOf(response.code()))
.record(duration, TimeUnit.NANOSECONDS);
return response;
} catch (IOException e) {
long duration = System.nanoTime() - startTime;
meterRegistry.timer("http.requests.duration")
.tag("host", request.url().host())
.tag("method", request.method())
.tag("status", "error")
.record(duration, TimeUnit.NANOSECONDS);
meterRegistry.counter("http.requests.errors")
.tag("host", request.url().host())
.tag("exception", e.getClass().getSimpleName())
.increment();
throw e;
}
}
}
/**
* 重试拦截器
*/
private static class RetryInterceptor implements Interceptor {
private static final int MAX_RETRIES = 3;
private static final long RETRY_DELAY_MS = 1000;
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
Response response = null;
IOException exception = null;
for (int attempt = 0; attempt <= MAX_RETRIES; attempt++) {
if (attempt > 0) {
// 非首次尝试,等待一段时间
try {
Thread.sleep(RETRY_DELAY_MS * attempt);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IOException("重试被中断", e);
}
log.warn("API请求重试,第{}次尝试,URL: {}", attempt, request.url());
}
try {
response = chain.proceed(request);
// 只在服务器错误时重试
if (response.code() < 500) {
return response;
}
// 关闭响应体
response.close();
} catch (IOException e) {
exception = e;
// 网络异常,继续重试
}
}
// 所有重试都失败
if (exception != null) {
throw exception;
}
// 这种情况不应该发生
throw new IOException("API请求失败,未知错误");
}
}
}连接池配置通过复用HTTP连接显著减少了TCP握手和TLS握手的开销,提高了系统吞吐量。指标收集拦截器自动记录每个请求的耗时和状态,为性能监控提供数据支持。重试机制则提高了系统的容错能力,在面对临时性网络问题或服务端过载时能够自动恢复。
5.2 缓存策略实现
合理的缓存策略可以大幅降低API调用成本和响应延迟:
@Service
@Slf4j
public class ResponseCacheService {
private final Cache<String, CachedResponse> responseCache;
private final DeepseekService deepseekService;
public ResponseCacheService(DeepseekService deepseekService) {
this.deepseekService = deepseekService;
// 配置缓存:最大1000个条目,有效期1小时
this.responseCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.HOURS)
.recordStats()
.build();
}
/**
* 获取缓存的响应或调用API
*/
public CachedResponse getOrCompute(String cacheKey, String systemPrompt, String userMessage) {
try {
// 尝试从缓存获取
CachedResponse cached = responseCache.getIfPresent(cacheKey);
if (cached != null) {
log.debug("缓存命中,Key: {}", cacheKey);
cached.setFromCache(true);
return cached;
}
// 缓存未命中,调用API
log.debug("缓存未命中,调用API,Key: {}", cacheKey);
GenerationResult result = deepseekService.executeCompletion(systemPrompt, userMessage);
// 构建缓存响应
CachedResponse response = CachedResponse.builder()
.content(deepseekService.extractResponseContent(result))
.reasoning(deepseekService.extractReasoningContent(result))
.usage(result.getUsage())
.fromCache(false)
.timestamp(System.currentTimeMillis())
.build();
// 放入缓存
responseCache.put(cacheKey, response);
return response;
} catch (Exception e) {
log.error("缓存服务处理失败,Key: {}", cacheKey, e);
throw new BusinessException("缓存服务异常", e);
}
}
/**
* 生成缓存键
* 基于系统提示词和用户消息生成唯一的MD5哈希
*/
public String generateCacheKey(String systemPrompt, String userMessage) {
try {
String content = systemPrompt + "|||" + userMessage;
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] hash = md.digest(content.getBytes(StandardCharsets.UTF_8));
StringBuilder hexString = new StringBuilder();
for (byte b : hash) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) {
hexString.append('0');
}
hexString.append(hex);
}
return hexString.toString();
} catch (NoSuchAlgorithmException e) {
log.error("MD5算法不可用", e);
throw new BusinessException("缓存键生成失败", e);
}
}
/**
* 获取缓存统计信息
*/
public CacheStats getCacheStats() {
com.github.benmanes.caffeine.cache.stats.CacheStats stats = responseCache.stats();
return CacheStats.builder()
.hitCount(stats.hitCount())
.missCount(stats.missCount())
.loadSuccessCount(stats.loadSuccessCount())
.loadFailureCount(stats.loadFailureCount())
.totalLoadTime(stats.totalLoadTime())
.evictionCount(stats.evictionCount())
.build();
}
/**
* 清理缓存
*/
public void clearCache() {
responseCache.invalidateAll();
log.info("缓存已清空");
}
/**
* 预加载常用查询到缓存
*/
@EventListener(ApplicationReadyEvent.class)
public void preloadCommonQueries() {
log.info("开始预加载常用查询到缓存");
List<CommonQuery> commonQueries = Arrays.asList(
new CommonQuery("通用客服问候", "你好,请问有什么可以帮您?"),
new CommonQuery("服务时间查询", "你们的客服工作时间是?"),
new CommonQuery("联系方式", "如何联系人工客服?")
);
for (CommonQuery query : commonQueries) {
String cacheKey = generateCacheKey(query.getSystemPrompt(), query.getUserMessage());
getOrCompute(cacheKey, query.getSystemPrompt(), query.getUserMessage());
}
log.info("常用查询预加载完成,共加载 {} 个查询", commonQueries.size());
}
}缓存服务通过MD5哈希为每个查询生成唯一键,确保相同的问题能够命中缓存。Caffeine缓存库提供了高性能的本地缓存实现,通过统计功能可以监控缓存效果。预加载机制将常见问题提前缓存,进一步提升响应速度。这种缓存策略特别适合FAQ类应用,能够显著降低API调用成本。
5.3 监控与告警系统
全面的监控是生产系统稳定运行的保障:
@Component
@Slf4j
public class DeepseekMonitor {
private final MeterRegistry meterRegistry;
private final Timer apiCallTimer;
private final Counter successCounter;
private final Counter errorCounter;
private final Gauge cacheHitGauge;
private final AtomicLong cacheHitCount = new AtomicLong(0);
private final AtomicLong cacheMissCount = new AtomicLong(0);
public DeepseekMonitor(MeterRegistry meterRegistry, ResponseCacheService cacheService) {
this.meterRegistry = meterRegistry;
// 初始化指标
this.apiCallTimer = Timer.builder("deepseek.api.call.duration")
.description("Deepseek API调用耗时")
.register(meterRegistry);
this.successCounter = Counter.builder("deepseek.api.call.result")
.description("Deepseek API调用结果")
.tag("status", "success")
.register(meterRegistry);
this.errorCounter = Counter.builder("deepseek.api.call.result")
.description("Deepseek API调用结果")
.tag("status", "error")
.register(meterRegistry);
this.cacheHitGauge = Gauge.builder("deepseek.cache.hit.ratio")
.description("缓存命中率")
.register(meterRegistry, this, monitor -> {
long hits = cacheHitCount.get();
long misses = cacheMissCount.get();
long total = hits + misses;
return total > 0 ? (double) hits / total : 0.0;
});
// 定期记录监控日志
ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor();
scheduler.scheduleAtFixedRate(this::logMetrics, 1, 1, TimeUnit.MINUTES);
}
/**
* 记录API调用指标
*/
public void recordApiCall(Runnable apiCall, String model) {
Timer.Sample sample = Timer.start(meterRegistry);
try {
apiCall.run();
sample.stop(apiCallTimer.tag("model", model).tag("status", "success"));
successCounter.increment();
} catch (Exception e) {
sample.stop(apiCallTimer.tag("model", model).tag("status", "error"));
errorCounter.increment();
throw e;
}
}
/**
* 记录缓存命中
*/
public void recordCacheHit() {
cacheHitCount.incrementAndGet();
}
/**
* 记录缓存未命中
*/
public void recordCacheMiss() {
cacheMissCount.incrementAndGet();
}
/**
* 记录token使用量
*/
public void recordTokenUsage(int inputTokens, int outputTokens, String model) {
meterRegistry.counter("deepseek.tokens.input", "model", model)
.increment(inputTokens);
meterRegistry.counter("deepseek.tokens.output", "model", model)
.increment(outputTokens);
log.debug("Token使用记录 - 模型: {}, 输入: {}, 输出: {}",
model, inputTokens, outputTokens);
}
/**
* 定期记录监控指标
*/
private void logMetrics() {
double hitRatio = cacheHitGauge.value();
long apiCalls = successCounter.count() + errorCounter.count();
log.info("系统监控指标 - API调用次数: {}, 缓存命中率: {:.2f}%, 平均响应时间: {:.2f}ms",
apiCalls, hitRatio * 100, apiCallTimer.mean(TimeUnit.MILLISECONDS));
// 检查异常情况并触发告警
checkAndAlertAnomalies();
}
/**
* 检查异常情况
*/
private void checkAndAlertAnomalies() {
double errorRate = errorCounter.count() /
(double) (successCounter.count() + errorCounter.count());
// 错误率超过阈值
if (errorRate > 0.1) { // 10%错误率阈值
log.warn("API错误率异常: {:.2f}%", errorRate * 100);
// 这里可以集成邮件、短信等告警通知
}
// 响应时间异常
double avgResponseTime = apiCallTimer.mean(TimeUnit.MILLISECONDS);
if (avgResponseTime > 10000) { // 10秒阈值
log.warn("API平均响应时间异常: {:.2f}ms", avgResponseTime);
}
}
/**
* 获取当前监控数据
*/
public MonitoringData getCurrentMonitoringData() {
return MonitoringData.builder()
.apiCallCount(successCounter.count() + errorCounter.count())
.errorCount(errorCounter.count())
.errorRate(errorCounter.count() / (double) (successCounter.count() + errorCounter.count()))
.averageResponseTime(apiCallTimer.mean(TimeUnit.MILLISECONDS))
.cacheHitRatio(cacheHitGauge.value())
.timestamp(System.currentTimeMillis())
.build();
}
}监控系统通过Micrometer集成了多种指标收集,包括API调用耗时、成功率、缓存命中率和token使用量。定时任务定期检查系统健康状态,在发现异常时触发告警。通过这种方式,运维团队可以实时了解系统运行状态,及时发现和解决潜在问题。
六、安全与合规实践
6.1 输入验证与内容过滤
确保用户输入的安全性是系统设计的重要环节:
@Component
@Slf4j
public class SecurityFilter {
private final List<String> blockedPatterns = Arrays.asList(
"恶意模式1", "恶意模式2" // 实际应用中应从配置文件加载
);
private final int MAX_INPUT_LENGTH = 10000;
private final int MAX_SESSION_REQUESTS_PER_MINUTE = 60;
private final Cache<String, AtomicInteger> requestCounts = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.build();
/**
* 全面安全验证
*/
public ValidationResult validateInput(String sessionId, String userInput) {
List<String> errors = new ArrayList<>();
// 1. 长度验证
if (userInput == null || userInput.trim().isEmpty()) {
errors.add("输入内容不能为空");
} else if (userInput.length() > MAX_INPUT_LENGTH) {
errors.add("输入内容过长");
}
// 2. 频率限制验证
if (!checkRateLimit(sessionId)) {
errors.add("请求频率过高,请稍后重试");
}
// 3. 内容安全检测
SecurityScanResult securityResult = scanContent(userInput);
if (!securityResult.isSafe()) {
errors.add("输入内容包含不安全内容");
errors.addAll(securityResult.getWarnings());
}
// 4. 敏感信息检测
if (containsSensitiveInfo(userInput)) {
errors.add("输入内容可能包含敏感信息,请勿提交个人信息");
}
return ValidationResult.builder()
.valid(errors.isEmpty())
.errors(errors)
.sanitizedInput(sanitizeInput(userInput))
.build();
}
/**
* 频率限制检查
*/
private boolean checkRateLimit(String sessionId) {
AtomicInteger count = requestCounts.get(sessionId, k -> new AtomicInteger(0));
int currentCount = count.incrementAndGet();
if (currentCount > MAX_SESSION_REQUESTS_PER_MINUTE) {
log.warn("会话 {} 触发频率限制,当前计数: {}", sessionId, currentCount);
return false;
}
return true;
}
/**
* 内容安全扫描
*/
private SecurityScanResult scanContent(String content) {
List<String> warnings = new ArrayList<>();
boolean isSafe = true;
// 检查阻塞模式
for (String pattern : blockedPatterns) {
if (content.toLowerCase().contains(pattern.toLowerCase())) {
warnings.add("检测到不允许的内容模式: " + pattern);
isSafe = false;
}
}
// 检查代码注入特征
if (containsInjectionPatterns(content)) {
warnings.add("检测到可能的注入攻击特征");
isSafe = false;
}
// 检查极端情绪表达
if (containsExtremeSentiment(content)) {
warnings.add("检测到极端情绪表达");
// 这里不标记为不安全,但记录警告
}
return SecurityScanResult.builder()
.safe(isSafe)
.warnings(warnings)
.build();
}
/**
* 敏感信息检测
*/
private boolean containsSensitiveInfo(String content) {
// 简单的正则表达式匹配敏感信息模式
String[] sensitivePatterns = {
"\\d{17}[\\dXx]", // 身份证号
"\\d{16}", // 银行卡号
"1[3-9]\\d{9}", // 手机号
"\\w+@\\w+\\.\\w+" // 邮箱
};
for (String pattern : sensitivePatterns) {
if (content.matches(".*" + pattern + ".*")) {
return true;
}
}
return false;
}
/**
* 输入清理
*/
private String sanitizeInput(String input) {
if (input == null) {
return "";
}
// 移除潜在的危险字符
return input.replaceAll("[<>\"']", "");
}
/**
* 记录安全事件
*/
public void logSecurityEvent(String sessionId, String eventType, String details) {
log.warn("安全事件 - 会话: {}, 类型: {}, 详情: {}", sessionId, eventType, details);
// 这里可以集成到安全信息和事件管理系统
// 或者发送到专门的日志收集系统
}
}安全过滤器实施了多层防护机制:输入长度限制防止资源耗尽攻击,频率限制阻止暴力请求,内容扫描识别恶意模式,敏感信息检测保护用户隐私。这种纵深防御策略确保了系统的安全性,同时通过详细的事件记录支持安全审计。
6.2 数据加密与隐私保护
企业级应用需要严格的数据保护措施:
@Service
@Slf4j
public class DataProtectionService {
private final String encryptionKey;
private final ObjectMapper objectMapper;
public DataProtectionService(@Value("${app.encryption.key}") String encryptionKey) {
this.encryptionKey = encryptionKey;
this.objectMapper = new ObjectMapper();
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
/**
* 加密敏感数据
*/
public String encryptSensitiveData(Object data) {
try {
String jsonData = objectMapper.writeValueAsString(data);
return encrypt(jsonData);
} catch (JsonProcessingException e) {
log.error("序列化数据失败", e);
throw new BusinessException("数据加密失败", e);
}
}
/**
* 解密数据
*/
public <T> T decryptSensitiveData(String encryptedData, Class<T> type) {
try {
String jsonData = decrypt(encryptedData);
return objectMapper.readValue(jsonData, type);
} catch (IOException e) {
log.error("反序列化数据失败", e);
throw new BusinessException("数据解密失败", e);
}
}
/**
* AES加密实现
*/
private String encrypt(String data) {
try {
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
SecretKeySpec keySpec = new SecretKeySpec(encryptionKey.getBytes(StandardCharsets.UTF_8), "AES");
byte[] iv = new byte[12]; // GCM推荐12字节IV
SecureRandom random = new SecureRandom();
random.nextBytes(iv);
GCMParameterSpec gcmParameterSpec = new GCMParameterSpec(128, iv);
cipher.init(Cipher.ENCRYPT_MODE, keySpec, gcmParameterSpec);
byte[] encryptedData = cipher.doFinal(data.getBytes(StandardCharsets.UTF_8));
byte[] combined = new byte[iv.length + encryptedData.length];
System.arraycopy(iv, 0, combined, 0, iv.length);
System.arraycopy(encryptedData, 0, combined, iv.length, encryptedData.length);
return Base64.getEncoder().encodeToString(combined);
} catch (Exception e) {
log.error("数据加密失败", e);
throw new BusinessException("加密操作失败", e);
}
}
/**
* AES解密实现
*/
private String decrypt(String encryptedData) {
try {
byte[] combined = Base64.getDecoder().decode(encryptedData);
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
SecretKeySpec keySpec = new SecretKeySpec(encryptionKey.getBytes(StandardCharsets.UTF_8), "AES");
byte[] iv = Arrays.copyOfRange(combined, 0, 12);
byte[] encrypted = Arrays.copyOfRange(combined, 12, combined.length);
GCMParameterSpec gcmParameterSpec = new GCMParameterSpec(128, iv);
cipher.init(Cipher.DECRYPT_MODE, keySpec, gcmParameterSpec);
byte[] decryptedData = cipher.doFinal(encrypted);
return new String(decryptedData, StandardCharsets.UTF_8);
} catch (Exception e) {
log.error("数据解密失败", e);
throw new BusinessException("解密操作失败", e);
}
}
/**
* 数据脱敏处理
*/
public String maskSensitiveInfo(String text) {
if (text == null) {
return null;
}
// 身份证号脱敏
text = text.replaceAll("(\\d{6})\\d{8}(\\w{4})", "$1********$2");
// 手机号脱敏
text = text.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
// 邮箱脱敏
text = text.replaceAll("(\\w{1,3})[^@]*(@\\w+\\.\\w+)", "$1***$2");
return text;
}
/**
* 生成数据哈希,用于完整性验证
*/
public String generateDataHash(Object data) {
try {
String jsonData = objectMapper.writeValueAsString(data);
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] hash = md.digest(jsonData.getBytes(StandardCharsets.UTF_8));
StringBuilder hexString = new StringBuilder();
for (byte b : hash) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) {
hexString.append('0');
}
hexString.append(hex);
}
return hexString.toString();
} catch (Exception e) {
log.error("生成数据哈希失败", e);
throw new BusinessException("哈希生成失败", e);
}
}
}数据保护服务实现了端到端的加密解决方案。使用AES-GCM算法提供认证加密,确保数据的机密性和完整性。数据脱敏功能在日志记录和显示时保护用户隐私,而哈希生成则用于验证数据在传输过程中是否被篡改。这些措施共同确保了企业数据处理的合规性。
七、部署与运维最佳实践
7.1 容器化部署配置
Docker容器化提供了环境一致性和快速部署能力:
# Deepseek应用Dockerfile
FROM openjdk:17-jdk-slim
# 设置元数据
LABEL maintainer="devops@company.com"
LABEL version="1.0.0"
LABEL description="Deepseek AI应用容器"
# 设置工作目录
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y \
curl \
tzdata \
&& rm -rf /var/lib/apt/lists/*
# 设置时区
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 复制应用JAR文件
COPY target/deepseek-app-*.jar app.jar
# 创建非root用户运行应用
RUN groupadd -r appuser && useradd -r -g appuser appuser
RUN chown -R appuser:appuser /app
USER appuser
# 设置JVM参数
ENV JAVA_OPTS="-Xmx2g -Xms1g -XX:MaxRAMPercentage=75.0 -XX:+UseG1GC -XX:MaxGCPauseMillis=200"
# 健康检查
HEALTHCHECK --interval=30s --timeout=3s --start-period=60s --retries=3 \
CMD curl -f http://localhost:8080/actuator/health || exit 1
# 暴露端口
EXPOSE 8080
# 启动应用
ENTRYPOINT ["sh", "-c", "java $JAVA_OPTS -jar app.jar"]对应的Docker Compose配置:
version: '3.8'
services:
deepseek-app:
build: .
ports:
- "8080:8080"
environment:
- SPRING_PROFILES_ACTIVE=prod
- DASHSCOPE_API_KEY=${DASHSCOPE_API_KEY}
- JAVA_OPTS=-Xmx2g -Xms1g -XX:MaxRAMPercentage=75.0
volumes:
- logs:/app/logs
- tmp:/app/tmp
networks:
- deepseek-network
deploy:
resources:
limits:
memory: 3G
cpus: '2.0'
reservations:
memory: 2G
cpus: '1.0'
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/actuator/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
# Redis缓存
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis-data:/data
networks:
- deepseek-network
command: redis-server --appendonly yes --maxmemory 512mb --maxmemory-policy allkeys-lru
# 监控系统
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./monitoring/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
networks:
- deepseek-network
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD}
volumes:
- grafana-data:/var/lib/grafana
- ./monitoring/dashboards:/etc/grafana/provisioning/dashboards
networks:
- deepseek-network
depends_on:
- prometheus
volumes:
logs:
tmp:
redis-data:
prometheus-data:
grafana-data:
networks:
deepseek-network:
driver: bridge容器化配置确保了应用在不同环境中的一致性运行。Dockerfile设置了优化的JVM参数和健康检查,Docker Compose则定义了完整的服务栈,包括应用本身、缓存层和监控系统。这种配置支持快速的水平扩展和故障恢复。
7.2 Kubernetes部署配置
对于大规模生产环境,Kubernetes提供了更好的弹性和管理能力:
# Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-app
namespace: ai-production
labels:
app: deepseek-app
version: v1.0.0
spec:
replicas: 3
selector:
matchLabels:
app: deepseek-app
template:
metadata:
labels:
app: deepseek-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
prometheus.io/path: "/actuator/prometheus"
spec:
containers:
- name: deepseek-app
image: registry.company.com/deepseek-app:1.0.0
ports:
- containerPort: 8080
env:
- name: SPRING_PROFILES_ACTIVE
value: "prod"
- name: DASHSCOPE_API_KEY
valueFrom:
secretKeyRef:
name: deepseek-secrets
key: apiKey
- name: JAVA_OPTS
value: "-Xmx2g -Xms1g -XX:MaxRAMPercentage=75.0 -Djava.security.egd=file:/dev/./urandom"
resources:
requests:
memory: "2Gi"
cpu: "1000m"
limits:
memory: "3Gi"
cpu: "2000m"
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 60
periodSeconds: 30
timeoutSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 30
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
volumeMounts:
- name: logs-volume
mountPath: /app/logs
- name: tmp-volume
mountPath: /app/tmp
volumes:
- name: logs-volume
emptyDir: {}
- name: tmp-volume
emptyDir: {}
imagePullSecrets:
- name: registry-credentials
---
# 服务配置
apiVersion: v1
kind: Service
metadata:
name: deepseek-service
namespace: ai-production
spec:
selector:
app: deepseek-app
ports:
- port: 80
targetPort: 8080
protocol: TCP
type: ClusterIP
---
# 水平Pod自动扩缩容
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: deepseek-hpa
namespace: ai-production
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deepseek-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 50
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 100
periodSeconds: 60Kubernetes配置提供了生产级部署所需的所有特性:多副本确保高可用性,资源限制防止单个Pod消耗过多资源,健康检查保证流量只路由到健康的实例,自动扩缩容根据负载动态调整实例数量。这种配置能够支撑从几百到数万QPS的流量变化。
结论:构建企业级AI应用的最佳实践
通过本文的详细探讨,我们展示了基于阿里云调用Deepseek模型构建企业级AI应用的完整技术方案。从基础的环境配置到高级的流式处理,从性能优化到安全防护,每个环节都提供了经过实践检验的实现方案。
关键成功要素总结:
- 架构设计:采用分层架构,确保系统的可维护性和扩展性
- 性能优化:通过缓存、连接池和流式处理提升响应速度和吞吐量
- 安全合规:实施多层次安全防护,确保数据隐私和系统安全
- 监控运维:建立完整的监控体系,实现主动问题发现和快速故障恢复
- 成本控制:通过合理的缓存策略和API调用优化降低运营成本
未来演进方向:
随着AI技术的快速发展,企业级AI应用还将面临新的挑战和机遇:
- 多模型融合:结合不同专长模型,提供更精准的解决方案
- 边缘计算:在边缘设备部署轻量级模型,减少云端依赖
- 自适应学习:根据用户反馈持续优化模型表现
- 合规自动化:自动确保AI应用符合各地法规要求
Deepseek模型与阿里云平台的结合为企业提供了强大而灵活的AI能力,遵循本文所述的最佳实践,企业可以构建出稳定、高效、安全的AI应用,真正实现人工智能技术的业务价值。
参考资源:
本文所有代码示例均经过测试,可在生产环境中参考使用。具体实施时请根据实际业务需求进行调整和优化。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号