




专栏:JavaEE初阶起飞计划
个人主页:手握风云
目录
一、HTTP是什么
HTTP(全称为"超⽂本传输协议")是⼀种应用非常⼴泛的应用层协议。超文本,文本中包含了一些更复杂的内容,如图片、 视频、音频、特殊字体、链接。HTTP诞生于1991年,目前已经发展为最主流使用的⼀种应用层协议。HTTP是应用层协议,传输层 依赖TCP来进行实现。HTTP1.0、HTTP1.1、HTTP2.0均为TCP,HTTP3.0基于UDP。
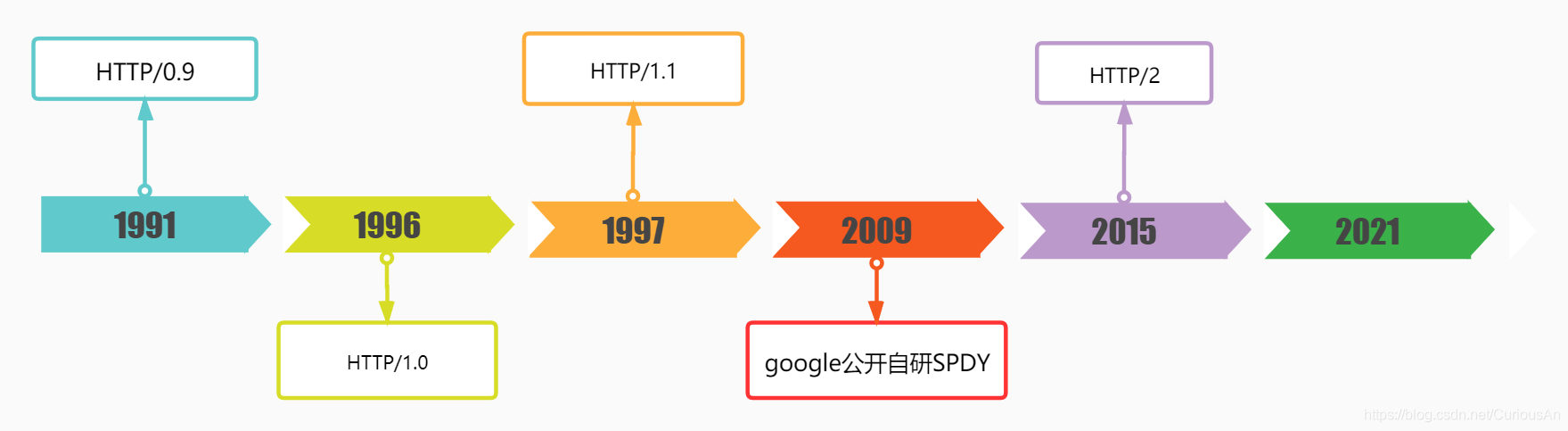
HTTP是一个经典的“一问一答”模型。关心 HTTP 交互过程的时候,需要关心 HTTP 请求是什么样子的,以及HTTP 响应是什么样子的。我们需要使用抓包软件来观察HTTP的协议格式,抓包程序,本质上是一个“代码程序”。比如我想买一瓶可乐,可以给正在超市购物的朋友发消息,让他给我买,回来再给他钱,那么此时我的朋友就起到了代理的作用。代理分为两类:正向代理,替代客户端干活;反向代理,替代服务器干活。
二、抓包工具
2.1. 抓包工具的使用
电脑上安装了抓包软件之后,抓包软件就可以监听电脑上网卡通过的数据了。本来是客户端通过网卡,把数据发给目标服务器。有了抓包软件,客户端把数据通过网卡,先发给抓包软件,抓包软件把数据再通过网卡发给目标服务器;服务器返回的数据,也是先到达抓包软件,再返回到你的客户端。我们这里使用Fiddler进行抓包。
Fiddler下载地址:https://www.telerik.com/fiddler/fiddler-classic
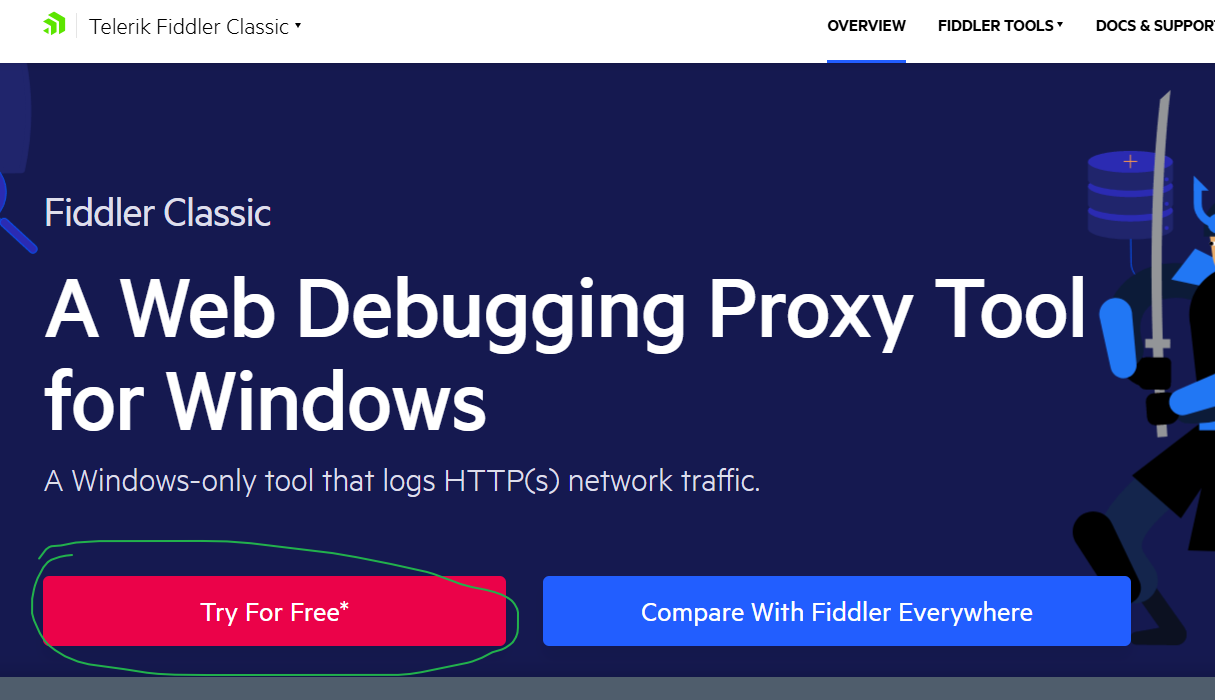
下载好了之后打开,会发现里面什么也没有,我们需要点击右上角的Tools,再点击Options,把HTTPS里的选项都勾选上,因为当前网络环境还是HTTPS居多,另外我们还需要把浏览器上的插件关掉,以免影响Fiddler的代理。
左侧是HTTP列表,右侧上方是HTTP请求的详情,右侧下方是HTTP响应的详情,这些我们只关心Raw标签页(HTTP的原始数据)。
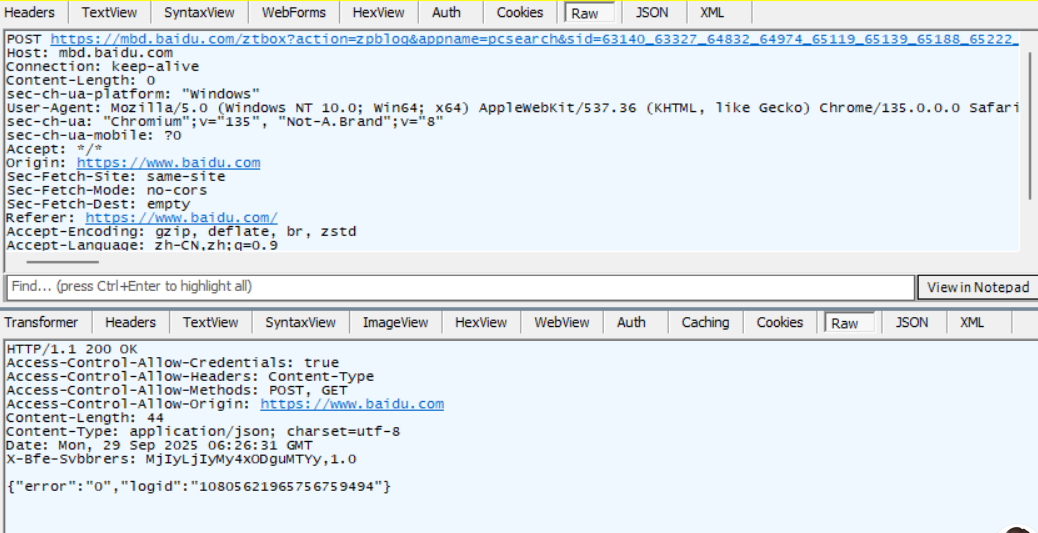
2.2. 抓包结果
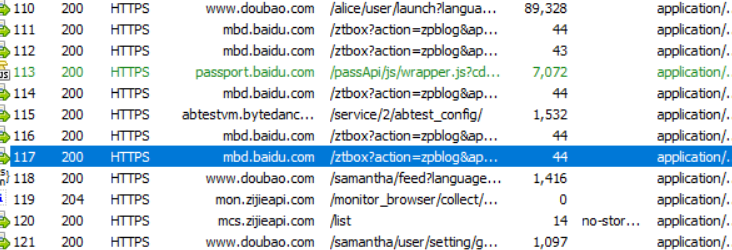
在Fiddler抓取“请求/列表”中,要找到咱们主动触发的这个请求响应,比如我现在打开百度的网址,就会产生浏览器和百度服务器的一组HTTP请求。在 fiddler 抓取到的"请求/响应"列表中需要找到咱们主动触发的这个请求响应。我们可以看域名,也可以看颜色,蓝色的表示百度主页的HTML页面。

浏览器和服务器之间,就会存在多次这样的HTTP交互。其中有的 HTTP 交互会获取到 HTML,有的会获取到CSS,还有的会获取到JavaScript,还有的会获取到一些依赖的资源,比如图片、音频、视频等。我们先刷新下百度主页,很可能是看不到获取CSS/JavaScript这样的 HTTP 交互的,这是因为浏览器是带有缓存的。一般网络访问存储设备的速度是最慢的,百度主页要想能够正确的显示,就需要把 HTMLCSS JS 这些内容都加载出来,页面才能正确显示,为了优化上述的加载速度,引入了浏览器缓存。第一次访问百度,会把上述所有资源都加载(CSS,JS,图片…保存到浏览器所在机器的硬盘上),后序再访问百度的时候,只从服务器获取htmI即可,CSS/JS 直接用上次获取过的。我们也可以通过ctrl+F5刷新触发"全量获取数据”,忽略本地的缓存,从服务器获取到完整的数据。
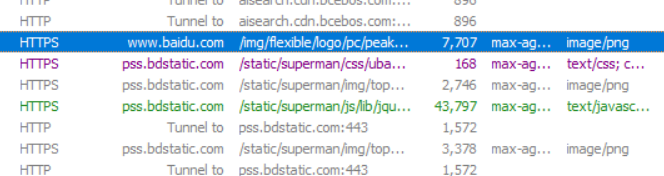
上图中紫色的就属于CSS,绿色的就属于JavaScript。
2.3. HTTP请求与响应
- HTTP请求
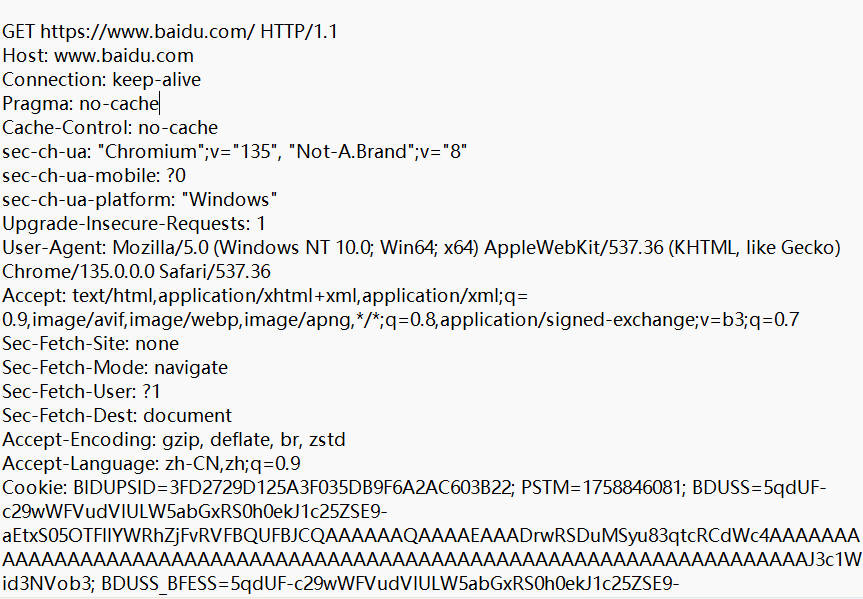
HTTP请求是一个行文本格式,第一行是首行(GET方法+URL+版本)。从第二行开始到文本最后是请求头header,请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空行表⽰header部分结束。还有剩下的一些空行,作为请求头的结束标记。
- HTTP响应
HTTP响应会出现乱码,里面会有一些二进制内容,原因是里面的文本内容被压缩成了二进制内容,网络通信过程中,最贵的硬件资源就是网络带宽。直接把原始数据进行传输,消耗的网络带宽就比较多。解决方法:可以把数据进行压缩,压缩之后数据就变少了,通过网络传输的内容也少了,数据到了对端再通过 cpu 来进行解压缩。
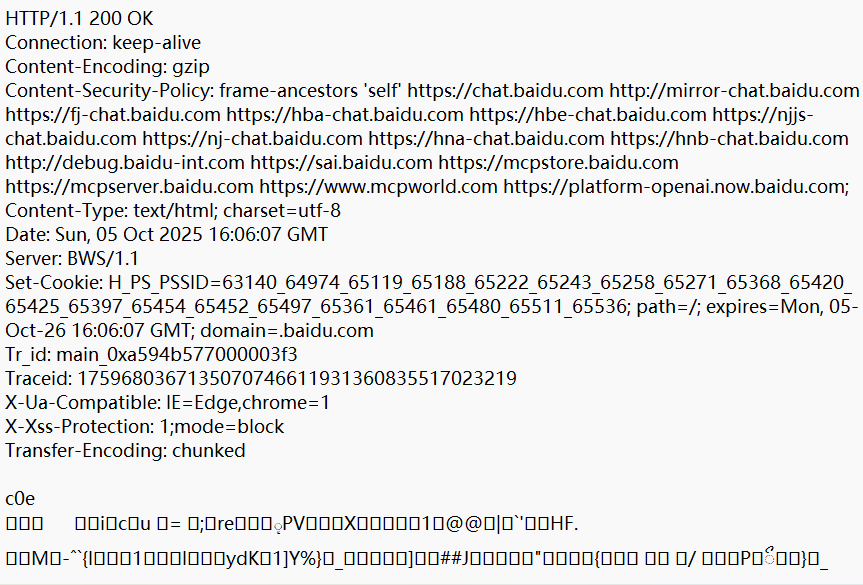
当我们点击黄色的条形框之后就可以解压缩,再次以记事本打开,就不会乱码。
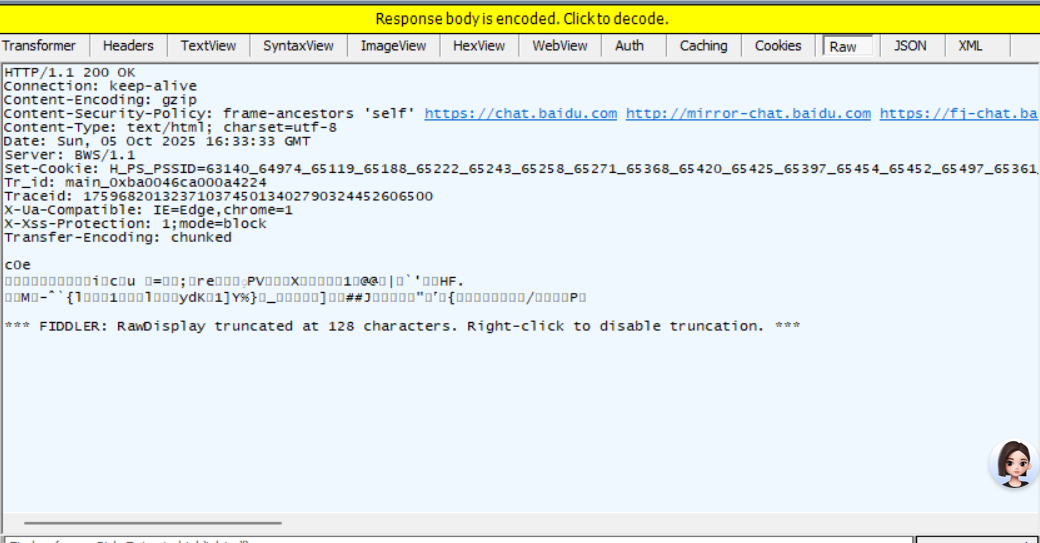

第一行照样是首行,版本号+状态码+状态码解释。第二行开始到“Content-Length”是响应头,中间是空行。因为服务器返回了一个HTML页面,那么HTML页面就是正文部分。
三、HTTP协议格式
HTTP是一个文本格式的协议。
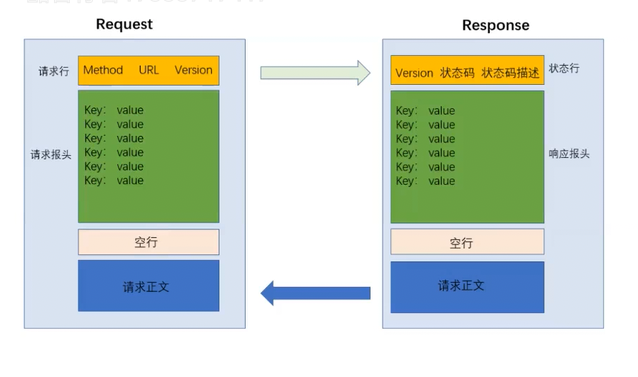
3.1. HTTP请求
1. 认识URL
https://www.baidu.com/
URL,唯一资源定位符,描述了网络上的某个资源的具体位置。
- 协议方案名:
http,指定客户端与服务器通信的协议(此处为超文本传输协议),决定了数据传输的规则。 - 登录信息(认证):
user:pass,包含用户名(user)和密码(pass),用于对服务器资源进行身份认证(因安全问题,现在较少在 URL 中明文传递)。 - 服务器地址:
www.example.jp,通过域名标识要访问的服务器(可通过 DNS 解析为 IP 地址),也可以通过ping命令查看域名解析的结果。 - 服务器端口号:
:80,指定服务器上的通信端口(HTTP 默认端口为 80,若用默认端口,该部分可省略)。 - 带层次的文件路径:
/dir/index.htm,表示服务器上资源的 “目录 - 文件” 层次路径,指向dir目录下的index.htm文件。 - 查询字符串:
?uid=1,以?开头,通过键值对(如uid=1)向服务器传递额外参数(可用于数据查询、功能触发等,多参数用&连接)。 - 片段标识符:
#ch1,以#开头,用于指定资源内部的片段位置(如 HTML 页面内的锚点),仅在客户端生效(不会发送到服务器)。
2. query string
https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD&rsv_spt=1&rsv_iqid=0xdb1c87c700002165&issp=1
&f=8
&rsv_bp=1
&rsv_idx=2
&ie=utf-8&tn=baiduhome_pg
&rsv_enter=1
&rsv_dl=tb&rsv_sug3=6&rsv_sug1=8
&rsv_sug7=101&rsv_btype=i
&prefixsug=%25E4%25BD%25A0%25E5%25A5%25BD
&rsp=6
&inputT=3164&rsv_sug4=4247
&rsv_sug=1作用:携带客户端参数(如搜索关键词、分页信息等),作为 HTTP 请求的一部分发送给服务器。
查询字符串由键值对组成,格式为参数名=值,多个参数用&分隔,位于 URL 路径后、片段标识符。查询字符串中的键值对的含义,都是程序员自定义的,我们可以通过这样的方式来自定制传输我们需要的信息给服务器。
3. URL 中的可省略部分
URL的设计允许省略多个冗余部分,浏览器或服务器会根据上下文自动补全。比如:可直接省略http://或https://,默认补全http://。服务器端口号,HTTP协议下默认端口80,HTTPS协议下默认端口443,省略后自动补全。带层次的文件路径,省略路径时,默认指向服务器根目录(/),通常映射到index.html或default.htm等默认文件。登录信息,URL 中user:pass@部分几乎完全省略,现代网站通过Cookie或Token认证,而非URL明文传输密码。查询字符串,无参数时可省略?及后续内容。片段标识符,无需页面内跳转时可省略#及后续锚点。
4. URL encode
https://www.baidu.com/s?ie=UTF-8&wd=%E4%BD%A0%E5%A5%BD 当我们在百度界面搜索一些内容时,当我们复制网址时,URL中的查询字符串中的value部分可能需要进行转义。因为URL仅支持ASCII 字符,但实际场景中常包含特殊字符(如空格、?、&)和非 ASCII 字符。这些字符若直接传输,可能导致解析歧义等问题。URL Encode(百分号编码)通过将字符转换为 %XX 格式(XX 为字符 ASCII 或 UTF-8 编码的十六进制),确保 URL 标准化传输。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号