

命名空间
- 命名空间的作用:在内存空间中,存放着大量的函数与变量,在大量的文件合并时,极大程度上会出现重复的函数与变量,于是在编译过程中就会出现错误(详情在《程序员的自我修养》中的编译中讲到),为了能让每个文件能正常运行,于是乎就用到了命名空间这一想法,我们把每个文件给定义一个域,于是乎当前文件使用函数或者变量时,就会使用使用在这文件定义的域里的函数或者变量。
- 举例:两个班,每班各有一个张三的。我把两个班的学生合并在一个班里,二班班主任叫我去叫张三的学生,但两个班都有叫张三的,这时我叫张三出来,就会有两个出来,但是我无法确认是哪个,但我若叫二班的张三出来,那么我想找的张三就出来了。
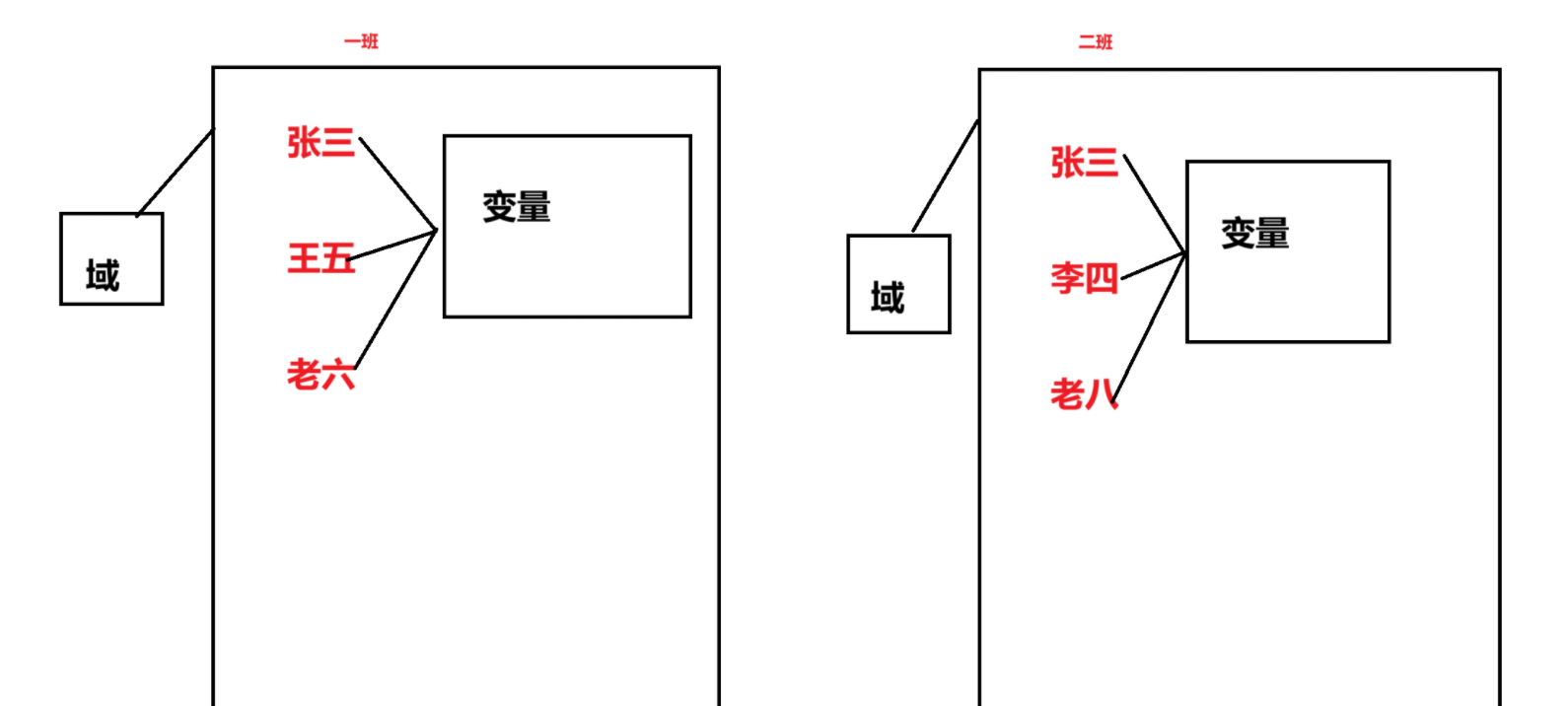
命名空间用于解决名称冲突问题,将代码逻辑分组。通过namespace关键字定义,使用时需指定作用域或使用using声明。
namespace MySpace {
int value = 42;
void foo() { /* ... */ }
}
// 使用方式
MySpace::value = 10;
using namespace MySpace; // 引入整个命名空间
foo(); // 直接调用输入输出
C++使用<iostream>库进行输入输出操作,cin和cout是标准输入输出流对象,需配合<<和>>运算符。
#include
using namespace std;
int main() {
int x;
cout << "Enter a number: ";
cin >> x;
cout << "You entered: " << x << endl;
return 0;
} 引用
引用是变量的别名,必须在声明时初始化,且不可重新绑定。通过&符号声明,常用于函数参数传递以避免拷贝。
int a = 10;
int &ref = a; // ref是a的引用
ref = 20; // 修改ref等同于修改a引用的特性:
引用必须初始化
一个变量可以有多个引用
引用一旦用了一个实体,就不能再引用其他实体
const的引用:
当我们在使用const的引用时,应当注意临时变量具有常量性质
临时变量的 “常量性质” 本质是编译器为了避免逻辑错误和确保安全性而做的约束
int main()
{
int a = 3;
int&b = a*3;//出现错误
//因为a*3会创建一个临时变量储存a*3的结果,然后返回,此时这个临时变量具有常量性质,就相当于此时b是常量a*b的别名,而b可以++,但常量不能++,就导致了冲突,于是产生了错误
const int&c = a*3;
//此时就对了,因为const就给int&c的读写权限改为读权限
return 0;
}临时对象:
临时对象就是编译器需要一个空间暂存表达式的求值结果时临时创建的一个未命名的对象,而c++会把这个未命名对象叫做临时对象
权限放大问题:
这种问题只会出现在指针和引用中;在一些场景下a*3的结果会存放在一个临时对象里,这时a*3的权限是常量的权限,而int&b给这个权限放大了,出现了错误。
指针和引用的关系:
指针是存储一个地址,需要开辟空间;引用时一个变量的别名,不需要开辟空 间。
引用必须初始化,指针不必。
引用再引用了一个对象后,就不能引用其他对象。
引用可以直接访问对象,而指针需要解引用后才能访问对象。
sizeof的含义不同,引用的sizeof是引用对象的类型大小,而指针的类型大小和指向变量地址的变量无关,只与平台有关(32位平台为四字节,64位为八字节).
引用与指针的区别:
引用是指针在一些场景上的替代,而非指针,因为引用无法改变转向(因为指 向的都是同一个实体),而指针可以。
临时对象就是编译器需要一个空间暂存表达式的求值结果时临时创建的一个未命名的对象,而c++会把这个未命名对象叫做临时对象
隐式类型转化:
在其中会创建一个临时变量存储,double b = 9.12;int a = b;a的复制过程中就会产生一个临时变量存储b并且转化类型给a
inline函数
inline关键字建议编译器将函数内联展开,以减少函数调用开销。适用于短小且频繁调用的函数。
inline int max(int a, int b) {
return (a > b) ? a : b;
}
// 调用时可能直接展开为代码
int result = max(3, 5);inline函数的特点:
提高执行效率:编译时,编译器会将inline函数代码直接嵌入到调用处, 避免了普通函数调用时的栈操作(如保存和恢复现场、压栈出栈参数等),减少函数调用开销,提升程序运行速度。
代码可读性和可维护性:以函数形式封装代码,保持了代码结构清晰,同时又能获得类似宏展开的高效执行效果,方便代码的维护与管理
总结:在编译过程中,难免会出现n个函数很少被调用的情况,这会导致时间效率降低,这时使用inline函数的话,就可以避免这种情况,为什么能达到这个目的呢,是因为这种做法类似于宏定义,当使用这个函数的时候,内存中自动的复制这个函数的代码,而非找到函数地址再跳转到函数,这样就大大时间效率。
注:inline 是编译器的建议性优化,复杂函数(如递归、大体积函数)可能被编译器忽略 inline 声明,仍按普通函数处理。
nullptr
nullptr是C++11引入的空指针常量,类型安全,替代了传统的NULL宏(通常为0)。避免与整数类型混淆。
int *ptr = nullptr; // 明确表示空指针
if (ptr == nullptr) { /* ... */ }
// 传统NULL可能引发问题
void foo(int);
void foo(char*);
foo(NULL); // 可能调用foo(int)而非预期
foo(nullptr); // 明确调用foo(char*)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号