

数据一致性是分布式系统的生命线:在金融交易、订单处理等关键场景中,每秒钟可能有数千条消息传输,如何确保消息不丢失?RabbitMQ的事务机制正是解决这一痛点的核心方案!
一、什么是消息传递的原子性?⚛️
想象银行转账场景:
如果步骤2失败,会出现:
- 账户A已扣款
- 账户B未入账
- 系统数据不一致
事务机制的目标:保证多个操作要么全部成功,要么全部失败回滚
二、RabbitMQ事务的三把金钥匙️
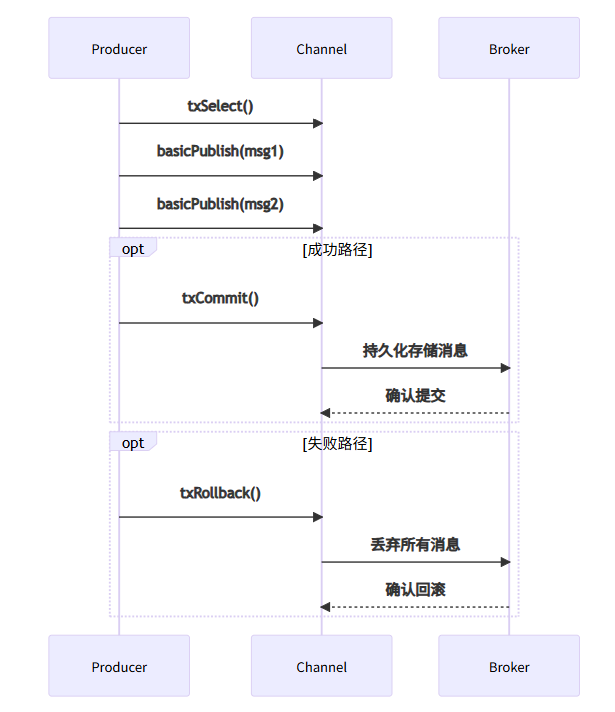
2.1 事务操作三命令
| 命令 | 作用 | 类比SQL |
|---|---|---|
txSelect() | 开启事务 | BEGIN TRANSACTION |
txCommit() | 提交事务 | COMMIT |
txRollback() | 回滚事务 | ROLLBACK |
2.2 事务执行流程
三、事务机制的底层原理
3.1 事务实现机制
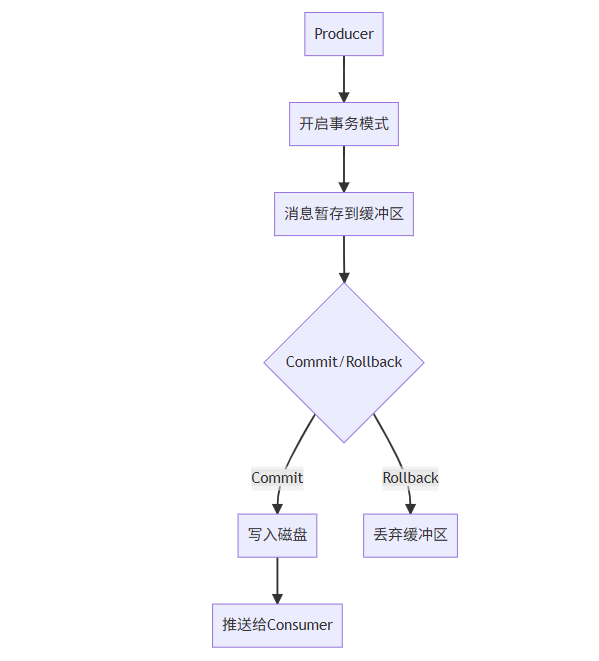
关键特点:
- 同步阻塞:事务提交前会阻塞生产者
- 单信道事务:事务作用于单个Channel
- 内存缓冲:消息先暂存在内存缓冲区
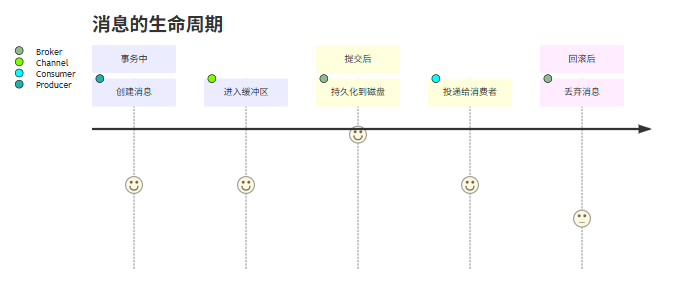
3.2 事务消息生命周期
四、代码实战:订单支付事务系统
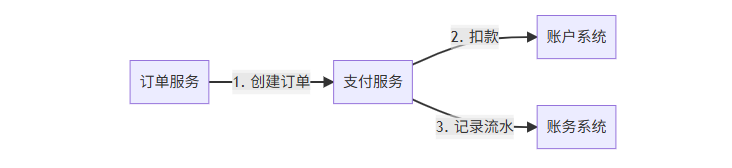
4.1 场景描述
4.2 Python事务实现
import pika
import json
class TransactionalProducer:
def __init__(self):
self.connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost'))
self.channel = self.connection.channel()
# 声明持久化队列
self.channel.queue_declare(queue='payment_orders', durable=True)
def send_transactional(self, messages):
try:
# 1. 开启事务
self.channel.tx_select()
# 2. 发送多条消息
for msg in messages:
self.channel.basic_publish(
exchange='',
routing_key='payment_orders',
body=json.dumps(msg),
properties=pika.BasicProperties(
delivery_mode=2 # 持久化消息
)
)
print(f" [*] Sent: {msg['order_id']}")
# 3. 提交事务
self.channel.tx_commit()
print(" [✓] Transaction committed")
except Exception as e:
print(f" [x] Error: {e}")
# 4. 回滚事务
self.channel.tx_rollback()
print(" [↩] Transaction rolled back")
def close(self):
self.connection.close()
# 使用示例
if __name__ == "__main__":
producer = TransactionalProducer()
# 构造事务消息(要么全部成功,要么全部失败)
messages = [
{'type': 'deduct', 'order_id': '1001', 'amount': 100},
{'type': 'record', 'order_id': '1001', 'action': 'payment'}
]
producer.send_transactional(messages)
producer.close()4.3 事务测试用例
# 测试正常提交
messages = [
{'type': 'deduct', 'order_id': '1001', 'amount': 100},
{'type': 'record', 'order_id': '1001', 'action': 'payment'}
]
# 输出: [*] Sent: 1001 (x2) -> [✓] Transaction committed
# 测试异常回滚
messages = [
{'type': 'deduct', 'order_id': '1002', 'amount': 200},
{'type': 'record', 'order_id': '1002', 'action': None} # 故意制造异常
]
# 输出: [*] Sent: 1002 -> [x] Error -> [↩] Transaction rolled back五、事务 vs 确认模式:如何选择?⚖️
| 特性 | 事务模式 | 发布者确认模式 |
|---|---|---|
| 可靠性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 吞吐量 | ⭐⭐ (200-300/秒) | ⭐⭐⭐⭐ (50,000+/秒) |
| 延迟 | 高(同步阻塞) | 低(异步) |
| 实现复杂度 | 简单 | 中等 |
| 消息顺序 | 严格保证 | 可能乱序 |
| 适用场景 | 关键金融交易 | 高吞吐日志处理 |
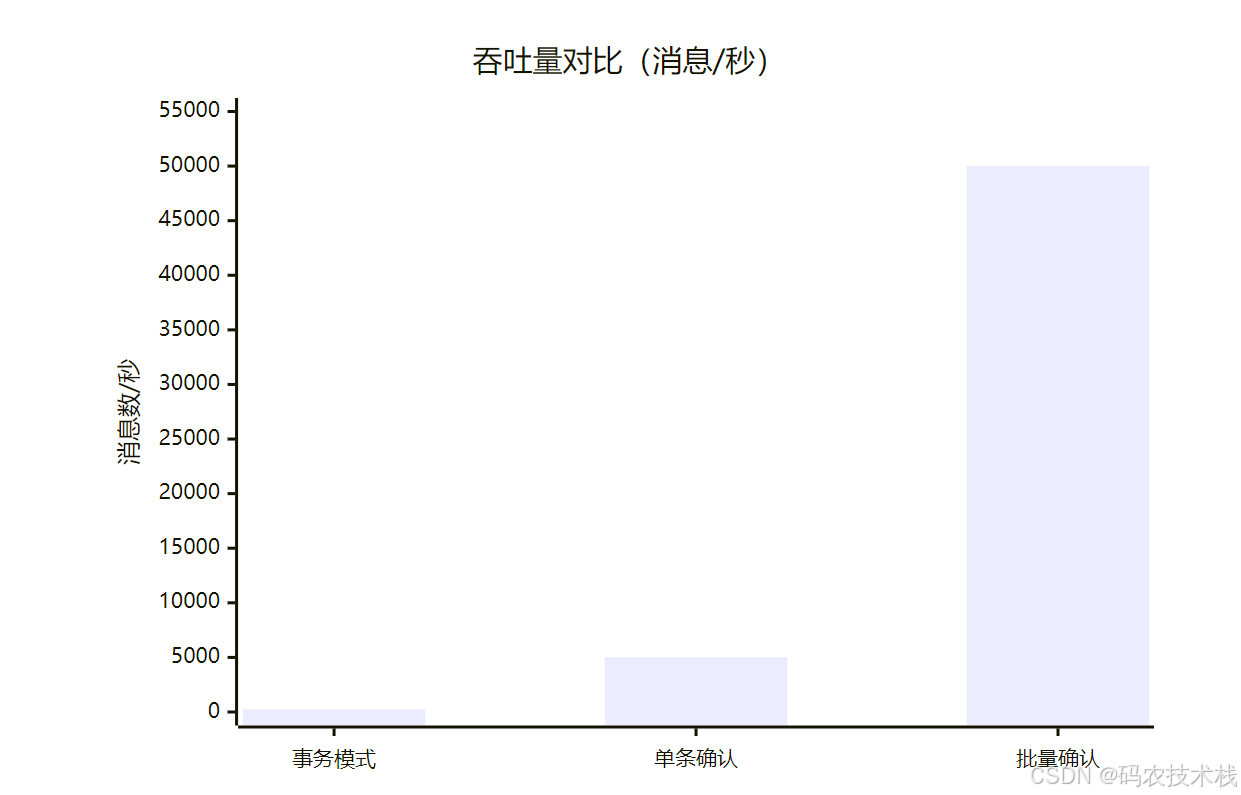
选择建议:
- 需要强一致性:选择事务
- 需要高吞吐:选择确认模式
- 混合使用:关键操作用事务,非关键用确认
六、事务最佳实践
6.1 性能优化策略
# 1. 短事务原则(避免长时间持有事务)
def process_order(order):
with transaction: # 事务范围最小化
deduct_funds(order)
record_ledger(order)
# 2. 批量操作(减少事务次数)
batch_size = 50
for i in range(0, len(orders), batch_size):
send_transactional(orders[i:i+batch_size])6.2 错误处理黄金法则
try:
channel.tx_select()
# ...发送消息...
channel.tx_commit()
except pika.exceptions.AMQPConnectionError:
# 网络故障:重建连接后重试
reconnect_and_retry()
except pika.exceptions.ChannelClosed:
# 信道错误:创建新信道
create_new_channel()
except Exception as e:
# 业务异常:回滚事务
channel.tx_rollback()
log_error(e)6.3 事务+持久化组合拳
# 队列持久化
channel.queue_declare(queue='orders', durable=True)
# 消息持久化
properties = pika.BasicProperties(
delivery_mode=2, # 持久化消息
content_type='application/json'
)
# 开启事务
channel.tx_select()七、事务的局限性及解决方案⚠️
7.1 事务的三大局限
- 性能瓶颈:同步阻塞模型
- 无法跨队列:单个信道的事务
- 消费者端不保证:仅生产者端事务
7.2 高级解决方案

分布式事务方案:
# 使用分布式事务框架(如Seata)
@GlobalTransactional
def create_order(order_data):
inventory_service.deduct(order_data)
order_service.create(order_data)
payment_service.charge(order_data)八、总结与展望
RabbitMQ事务核心价值:
- ✅ 原子性保证:要么全成功,要么全失败
- ✅ 强一致性:关键业务的首选方案
- ✅ 简单易用:三命令实现复杂逻辑
性能警告:事务会使吞吐量下降100-200倍!仅推荐用于低频关键操作。
未来趋势:

实战建议:
- 优先考虑发布者确认模式
- 事务用于低频关键操作
- 结合死信队列+监控告警
- 重要业务实现对账补偿机制
最后:在分布式系统中,没有完美的解决方案,只有适合场景的权衡。理解事务机制的优缺点,才能在可靠性和性能间找到最佳平衡点!⚖️


 浙公网安备 33010602011771号
浙公网安备 33010602011771号