爬取福建人口分布与福建天气气候的关系
一、选题背景
除经济和地理位置的影响,天气气候对人口的影响可体现在对人口数量和人的性格、生活习性等的影响,气候条件恶劣的地方,不利于人类生存,这些地区的人口密度就小,反之,温和的天气气候环境适合人类居住,人口就密集。因此通过爬取福建省人口数据和福建省天气数据可以反映出此类关系。(人类室外气候舒适温度一般在13~14度为最佳适宜温度)
二、主题式网络爬虫设计方案
三、主题页面的结构特征分析
一、主题页面的结构与特征分析:通过分析我们可以发现我们所需要的天气数据和人口数据都在“tr”标签里
二、页面解析:

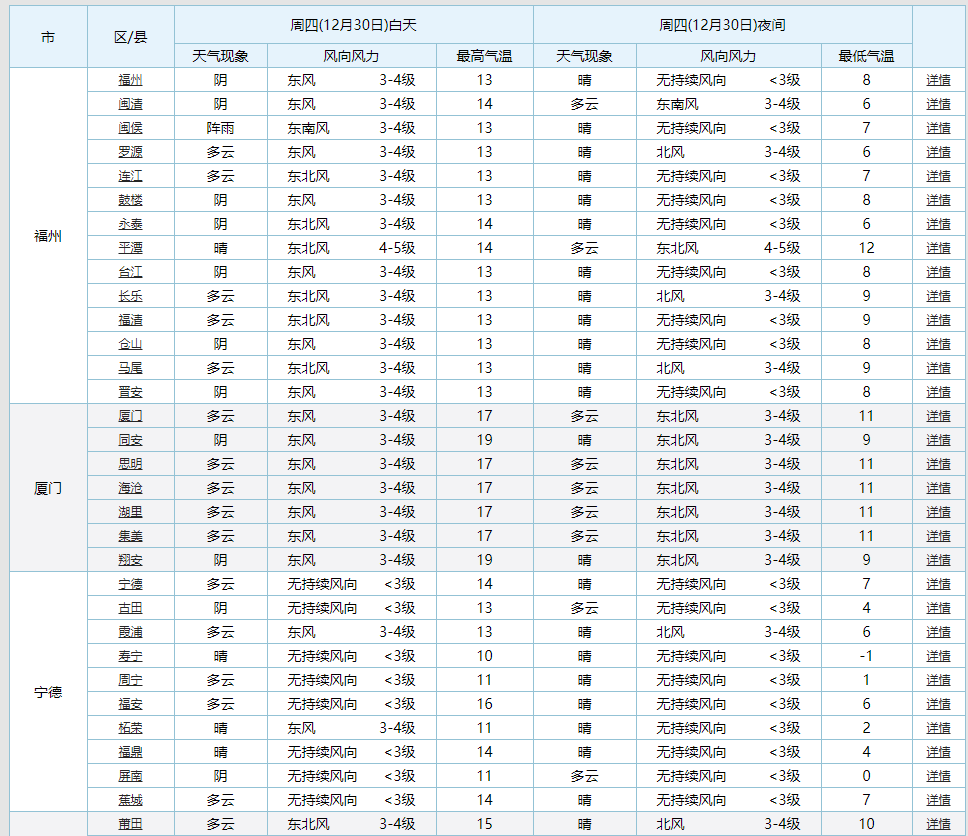

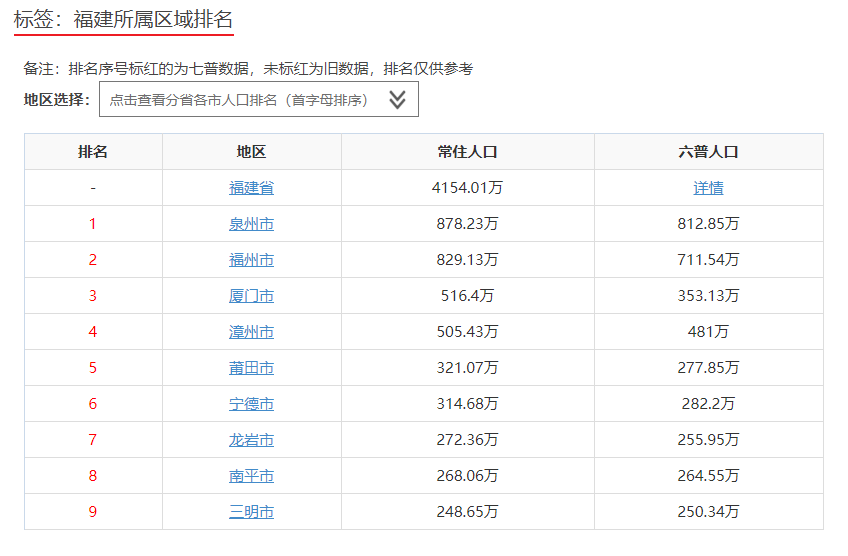
三、1.逐个提取标签保存到相同路径excel文件中
1 from bs4 import BeautifulSoup 2 import requests 3 import pandas as pd 4 def request_cqputure(url): 5 #尝试爬取网站返回文本形式 6 try: 7 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/\ 8 537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"} 9 r=requests.get(url,headers=headers) 10 #抓取页面数据时间30秒 11 r.raise_for_status() 12 #如果状态不是200引发异常 13 r.encoding = r.apparent_encoding 14 #更改编码为utf-8 15 return r.text 16 except: 17 return "false" 18 19 #1.调用函数爬取并解析 20 url="https://www.hongheiku.com/tag/%E7%A6%8F%E5%BB%BA" 21 a=request_cqputure(url) 22 soup=BeautifulSoup(a) 23 #对爬取数据进行选取存入列表规范化 24 bb=[] 25 for i in soup.find_all("tr")[4:]: 26 dd=0 27 aa=[] 28 for a in i.find_all("td"): 29 if dd==0: 30 aa.append(a.string) 31 elif dd==1: 32 aa.append(a.string) 33 elif dd==2: 34 aa.append(a.string) 35 elif dd==3: 36 aa.append(a.string) 37 #elif dd==4: 38 # aa.append(a.string) 39 dd=dd+1 40 bb.append(aa) 41 #将爬取的数据进行换行整理并输出数据 42 for m in bb: 43 print(m) 44 import csv 45 with open("D:\\人口.csv","w",encoding="utf-8") as fi: 46 writer=csv.writer(fi) 47 #给每列的数据列名 48 writer.writerow(["排名","城市","常住人口数","六普人口数"]) 49 for d in bb: 50 writer.writerow(d) 51 fi.close() 52 53 54 import requests 55 from bs4 import BeautifulSoup 56 import matplotlib.pyplot as plt 57 import seaborn as sns 58 59 ALL_DATA = [] 60 kkkk=[] 61 #网页的解析函数 62 def parse_page(url): 63 headers = { 64 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 65 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36' 66 } 67 response = requests.get(url,headers=headers) 68 text = response.content.decode('utf-8') 69 soup = BeautifulSoup(text,'html5lib') 70 #由于html5lib容错性较好因此用它不用lxml 71 conMidtab = soup.find('div',class_ = 'conMidtab') 72 tables = conMidtab.find_all('table') 73 #查看是否拿到了每个城市的天气 74 for table in tables: 75 trs = table.find_all('tr')[2:] 76 ccc=[] 77 for index,tr in enumerate(trs): 78 tds = tr.find_all('td') 79 city_td = tds[0] 80 if index == 0: 81 city_td = tds[1] 82 city = list(city_td.stripped_strings)[0] 83 #获取标签里面的字符串属性返回一个生成器,因此要转化为一个列表 84 temp_td = tds[-2] 85 min_temp = list(temp_td.stripped_strings)[0] 86 #----------------------------------------------------------------------------------- 87 kk1 = tds[-4] 88 gg1 = list(kk1.stripped_strings)[0] 89 #print(gg1) 90 #--------------------->风向 91 kk2 = tds[2] 92 gg2 = list(kk2.stripped_strings)[0] 93 #print(gg2) 94 #----------------------->风级 95 #以上风向与风级两数据存在一些问题需要用循环去去除不需要的数据 96 97 ttt_td=tds[-3] 98 ttt1=list(ttt_td.stripped_strings)[1] 99 #将数据中风级拿出 100 101 #将拿出所有数据进行整理 102 ALL_DATA.append([city,int(min_temp)]) 103 kkkk.append([gg2,ttt1,gg1]) 104 #将数据添加到列表当作 105 106 107 url= 'http://www.weather.com.cn/textFC/fujian.shtml' 108 109 parse_page(url) 110 #创立一个空集合 111 aaa=[] 112 for i in range(len(kkkk)): 113 aaa.append([kkkk[i][0],kkkk[i][1],kkkk[i][2],ALL_DATA[i][0],ALL_DATA[i][1]]) 114 aaa.sort(key=lambda aaa:aaa[0:][4],reverse=True) 115 for i in range(len(kkkk)): 116 aaa.append([kkkk[i][0],kkkk[i][1],kkkk[i][2],ALL_DATA[i][0],ALL_DATA[i][1]]) 117 for m in aaa: 118 print(m) 119 #创建一个文件来存储爬取的数据 120 import csv 121 with open("D:\\天气.csv","w",encoding="utf_8_sig") as fi: 122 writer=csv.writer(fi) 123 writer.writerow(["风向","风级","天气","城市","温度"]) 124 #给每列的数据列名 125 for d in aaa: 126 writer.writerow(d) 127 fi.close()
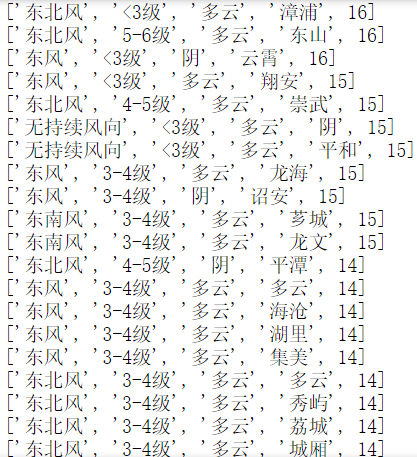
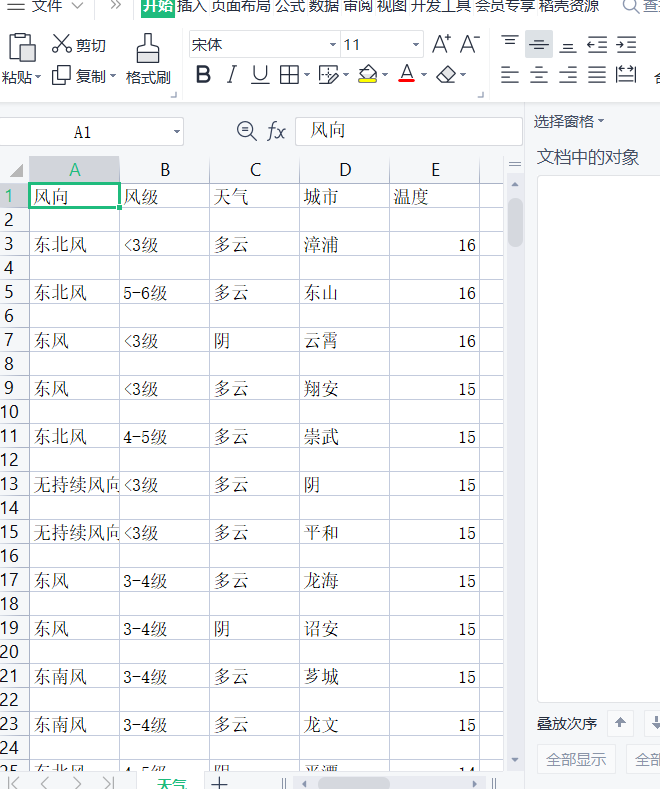


2.将excel表中的数据导出
1 #将数据导出 2 import csv 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 from sklearn import metrics 6 import warnings 7 warnings.filterwarnings("ignore") 8 df=pd.read_csv("D:\\天气.csv") 9 df 10 #将数据导出 11 import csv 12 import pandas as pd 13 import matplotlib.pyplot as plt 14 from sklearn import metrics 15 import warnings 16 warnings.filterwarnings("ignore") 17 df=pd.read_csv("D:\\人口.csv") 18 df
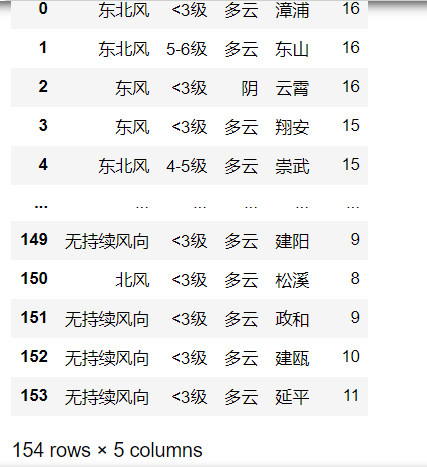
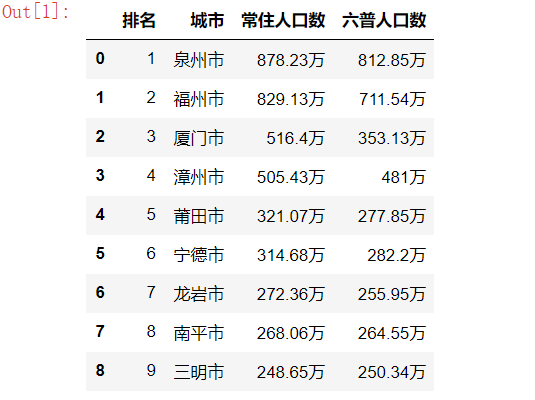
3.进行数据清洗
1 #检查是否有空值 2 print(rank['推荐数'].isnull().value_counts())
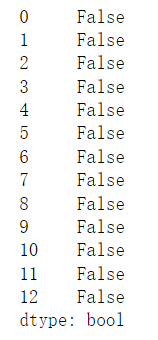
四、进行数据可视化
天气数据:
1 #显示中文标签,处理中文乱码问题 2 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 3 #画出前10个城市与温度的折线图 4 plt.plot(df[1:11]["城市"],df[1:11]["温度"]) 5 plt.xlabel("城市") 6 plt.ylabel("温度") 7 plt.show() 8 #画出前10个城市与温度的柱状图 9 plt.bar(df[1:11]["城市"],df[1:11]["温度"]) 10 plt.xlabel("城市") 11 plt.ylabel("温度") 12 plt.show() 13 #画出后10个城市与温度的折线图 14 plt.plot(df[-10:]["城市"],df[-10:]["温度"]) 15 plt.xlabel("城市") 16 plt.ylabel("温度") 17 plt.show() 18 #画出后10个城市与温度的柱形图 19 plt.bar(df[-10:]["城市"],df[-10:]["温度"]) 20 plt.xlabel("城市") 21 plt.ylabel("温度") 22 plt.show()
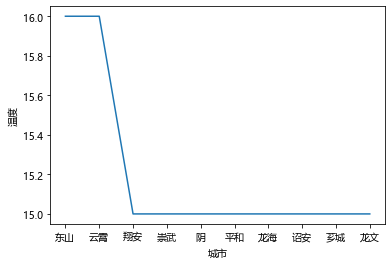
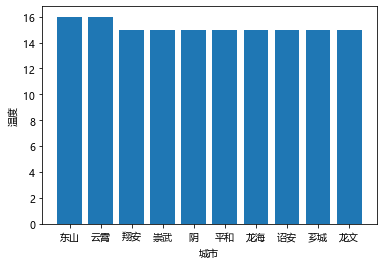
可以看温度前十个地区的温度
1 #画出后10个城市与温度的折线图 2 plt.plot(df[-10:]["城市"],df[-10:]["温度"]) 3 plt.xlabel("城市") 4 plt.ylabel("温度") 5 plt.show() 6 #画出后10个城市与温度的柱形图 7 plt.bar(df[-10:]["城市"],df[-10:]["温度"]) 8 plt.xlabel("城市") 9 plt.ylabel("温度") 10 plt.show()
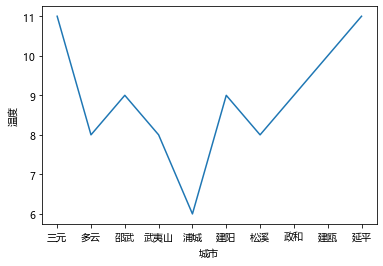
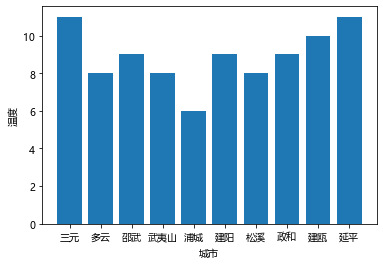
温度后十地区的温度
1 #画出温度在地区当中出现的次数 2 a=range(len(df["风级"])) 3 for iii in a: 4 df.loc[iii,"风级"]=int(df.loc[iii,"风级"][-2]) 5 hig=df.sort_values(by="温度", 6 axis=0, 7 ascending=False,) 8 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 9 #显示中文标签,处理中文乱码问题 10 plt.rcParams['axes.unicode_minus']=False 11 sns.distplot(df["温度"], 12 bins=20, 13 hist=True, 14 kde=True, 15 rug=True, 16 fit=None, 17 hist_kws=None, 18 kde_kws=None, 19 rug_kws=None, 20 fit_kws=None, 21 color="r", 22 vertical=False, 23 norm_hist=False, 24 axlabel=None, 25 label="温度", 26 ax=None) 27 plt.title=("温度排名") 28 plt.xlabel=("数量") 29 plt.ylabel=("温度") 30 #画出福建城市当中温度出现的次数 31 plt.grid() 32 plt.legend() 33 plt.show()
1 #画出城市与温度的散点图 2 plt.scatter(df[10:28]["城市"],df[10:28]["温度"]) 3 plt.show()
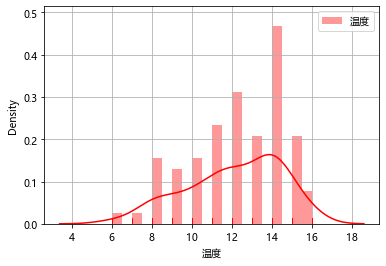

通过此图可以看出温度出现最频繁的次数和出现的所在城市和地区
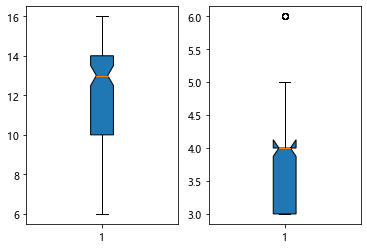
1 for it in range(len(df['风级'])): 2 df.loc[it,"风级"]=int(str(df.loc[it,"风级"])[-2]) 3 4 plt.subplot(1,2,1) 5 plt.boxplot(df["温度"], 6 notch=True, 7 sym=None, 8 vert=None, 9 whis=None, 10 positions=None, 11 widths=None, 12 patch_artist=True, 13 meanline=None, 14 showmeans=None, 15 showcaps=None, 16 showbox=None, 17 showfliers=None, 18 boxprops=None, 19 labels=None, 20 flierprops=None, 21 medianprops=None, 22 meanprops=None, 23 capprops=None, 24 whiskerprops=None) 25 plt.title("温度") 26 plt.ylabel("数量") 27 plt.subplot(1,2,2) 28 plt.boxplot(df["风级"], 29 notch=True, 30 sym=None, 31 vert=None, 32 whis=None, 33 positions=None, 34 widths=None, 35 patch_artist=True, 36 meanline=None, 37 showmeans=None, 38 showcaps=None, 39 showbox=None, 40 showfliers=None, 41 boxprops=None, 42 labels=None, 43 flierprops=None, 44 medianprops=None, 45 meanprops=None, 46 capprops=None, 47 whiskerprops=None) 48 plt.show()
人口数据:
1 #画出城市与人口的柱状图 2 plt.bar(df["城市"],df["常住人口数"]) 3 plt.xlabel("城市") 4 plt.ylabel("人口常住数(万人)")
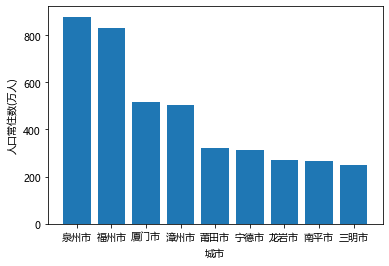
此图可以看出福建省各地区人口数量排名数据
1 #画出关于人口盒图 2 import seaborn as sns 3 sns.boxplot(df["常住人口数"])
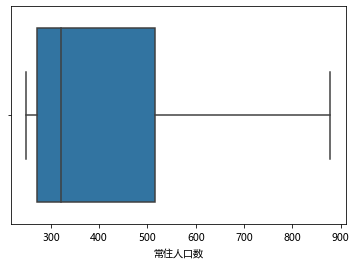
可以看出福建省平均各地区人口数
1 #画出城市与人口的饼图 2 for tj in range(len(df["常住人口数"])): 3 df.loc[tj,"常住人口数"]=float(df.loc[tj,"常住人口数"].split("万")[0]) 4 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 5 plt.rcParams['axes.unicode_minus']=False 6 #构造数据 7 labels = ["0-25%", "25-50%", "50-75%", "75-100%"] 8 colors = ['#CE0000', '#ff9999', '#4F4F4F', '#CABEFF'] 9 plt.pie(df["常住人口数"], #绘图数据 10 labels=["泉州","福州","厦门","漳州","莆田","宁德","龙岩","南平","三明"], 11 autopct='%.2f%%', 12 pctdistance=0.8, 13 labeldistance=1.1, 14 startangle=180, 15 radius=2.5, 16 counterclock=False, 17 wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, 18 textprops={'fontsize':10, 'color':'black'}, 19 ) 20 #添加图标题 21 plt.title('福建省人口城市分布') 22 #显示图形 23 plt.show()
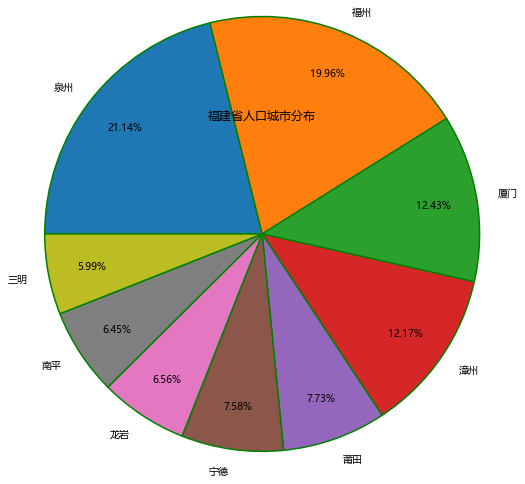
得出城市人口占比数据
五、结论:
通过两图我们可以知道处于14°c左右的地区大部分来自泉州和福州还有厦门也对应了饼图中的城市人口占比
六、完整代码
1 import requests 2 from bs4 import BeautifulSoup 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 6 ALL_DATA = [] 7 kkkk=[] 8 #网页的解析函数 9 def parse_page(url): 10 headers = { 11 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 12 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36' 13 } 14 response = requests.get(url,headers=headers) 15 text = response.content.decode('utf-8') 16 soup = BeautifulSoup(text,'html5lib') 17 #由于html5lib容错性较好因此用它不用lxml 18 conMidtab = soup.find('div',class_ = 'conMidtab') 19 tables = conMidtab.find_all('table') 20 #查看是否拿到了每个城市的天气 21 for table in tables: 22 trs = table.find_all('tr')[2:] 23 ccc=[] 24 for index,tr in enumerate(trs): 25 tds = tr.find_all('td') 26 city_td = tds[0] 27 if index == 0: 28 city_td = tds[1] 29 city = list(city_td.stripped_strings)[0] 30 #获取标签里面的字符串属性返回一个生成器,因此要转化为一个列表 31 temp_td = tds[-2] 32 min_temp = list(temp_td.stripped_strings)[0] 33 #----------------------------------------------------------------------------------- 34 kk1 = tds[-4] 35 gg1 = list(kk1.stripped_strings)[0] 36 #print(gg1) 37 #--------------------->风向 38 kk2 = tds[2] 39 gg2 = list(kk2.stripped_strings)[0] 40 #print(gg2) 41 #----------------------->风级 42 #以上风向与风级两数据存在一些问题需要用循环去去除不需要的数据 43 44 ttt_td=tds[-3] 45 ttt1=list(ttt_td.stripped_strings)[1] 46 #将数据中风级拿出 47 48 #将拿出所有数据进行整理 49 ALL_DATA.append([city,int(min_temp)]) 50 kkkk.append([gg2,ttt1,gg1]) 51 #将数据添加到列表当作 52 53 54 url= 'http://www.weather.com.cn/textFC/fujian.shtml' 55 56 parse_page(url) 57 #创立一个空集合 58 aaa=[] 59 for i in range(len(kkkk)): 60 aaa.append([kkkk[i][0],kkkk[i][1],kkkk[i][2],ALL_DATA[i][0],ALL_DATA[i][1]]) 61 aaa.sort(key=lambda aaa:aaa[0:][4],reverse=True) 62 for i in range(len(kkkk)): 63 aaa.append([kkkk[i][0],kkkk[i][1],kkkk[i][2],ALL_DATA[i][0],ALL_DATA[i][1]]) 64 for m in aaa: 65 print(m) 66 #创建一个文件来存储爬取的数据 67 import csv 68 with open("D:\\天气.csv","w",encoding="utf_8_sig") as fi: 69 writer=csv.writer(fi) 70 writer.writerow(["风向","风级","天气","城市","温度"]) 71 #给每列的数据列名 72 for d in aaa: 73 writer.writerow(d) 74 fi.close() 75 #将数据导出 76 import csv 77 import pandas as pd 78 import matplotlib.pyplot as plt 79 from sklearn import metrics 80 import warnings 81 warnings.filterwarnings("ignore") 82 df=pd.read_csv("D:\\天气.csv") 83 df 84 85 #显示中文标签,处理中文乱码问题 86 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 87 #画出前10个城市与温度的折线图 88 plt.plot(df[1:11]["城市"],df[1:11]["温度"]) 89 plt.xlabel("城市") 90 plt.ylabel("温度") 91 plt.show() 92 #画出前10个城市与温度的柱状图 93 plt.bar(df[1:11]["城市"],df[1:11]["温度"]) 94 plt.xlabel("城市") 95 plt.ylabel("温度") 96 plt.show() 97 #画出后10个城市与温度的折线图 98 plt.plot(df[-10:]["城市"],df[-10:]["温度"]) 99 plt.xlabel("城市") 100 plt.ylabel("温度") 101 plt.show() 102 #画出后10个城市与温度的柱形图 103 plt.bar(df[-10:]["城市"],df[-10:]["温度"]) 104 plt.xlabel("城市") 105 plt.ylabel("温度") 106 plt.show() 107 108 #画出城市与温度的散点图 109 plt.scatter(df[10:28]["城市"],df[10:28]["温度"]) 110 plt.show() 111 112 import requests 113 from bs4 import BeautifulSoup 114 import matplotlib.pyplot as plt 115 import seaborn as sns 116 import pandas as pd 117 df=pd.read_csv("D:\\天气.csv") 118 df 119 #画出温度在地区当中出现的次数 120 a=range(len(df["风级"])) 121 for iii in a: 122 df.loc[iii,"风级"]=int(df.loc[iii,"风级"][-2]) 123 hig=df.sort_values(by="温度", 124 axis=0, 125 ascending=False,) 126 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 127 #显示中文标签,处理中文乱码问题 128 plt.rcParams['axes.unicode_minus']=False 129 sns.distplot(df["温度"], 130 bins=20, 131 hist=True, 132 kde=True, 133 rug=True, 134 fit=None, 135 hist_kws=None, 136 kde_kws=None, 137 rug_kws=None, 138 fit_kws=None, 139 color="r", 140 vertical=False, 141 norm_hist=False, 142 axlabel=None, 143 label="温度", 144 ax=None) 145 plt.title=("温度排名") 146 plt.xlabel=("数量") 147 plt.ylabel=("温度") 148 #画出福建城市当中温度出现的次数 149 plt.grid() 150 plt.legend() 151 plt.show() 152 153 for it in range(len(df['风级'])): 154 df.loc[it,"风级"]=int(str(df.loc[it,"风级"])[-2]) 155 plt.subplot(1,2,1) 156 plt.boxplot(df["温度"], 157 notch=True, 158 sym=None, 159 vert=None, 160 whis=None, 161 positions=None, 162 widths=None, 163 patch_artist=True, 164 meanline=None, 165 showmeans=None, 166 showcaps=None, 167 showbox=None, 168 showfliers=None, 169 boxprops=None, 170 labels=None, 171 flierprops=None, 172 medianprops=None, 173 meanprops=None, 174 capprops=None, 175 whiskerprops=None) 176 177 plt.subplot(1,2,2) 178 plt.boxplot(df["风级"], 179 notch=True, 180 sym=None, 181 vert=None, 182 whis=None, 183 positions=None, 184 widths=None, 185 patch_artist=True, 186 meanline=None, 187 showmeans=None, 188 showcaps=None, 189 showbox=None, 190 showfliers=None, 191 boxprops=None, 192 labels=None, 193 flierprops=None, 194 medianprops=None, 195 meanprops=None, 196 capprops=None, 197 whiskerprops=None) 198 plt.show() 199 200 from bs4 import BeautifulSoup 201 import requests 202 import pandas as pd 203 def request_cqputure(url): 204 #尝试爬取网站返回文本形式 205 try: 206 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/\ 207 537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"} 208 r=requests.get(url,headers=headers) 209 #抓取页面数据时间30秒 210 r.raise_for_status() 211 #如果状态不是200引发异常 212 r.encoding = r.apparent_encoding 213 #更改编码为utf-8 214 return r.text 215 except: 216 return "false" 217 218 #1.调用函数爬取并解析 219 url="https://www.hongheiku.com/tag/%E7%A6%8F%E5%BB%BA" 220 a=request_cqputure(url) 221 soup=BeautifulSoup(a) 222 #对爬取数据进行选取存入列表规范化 223 bb=[] 224 for i in soup.find_all("tr")[4:]: 225 dd=0 226 aa=[] 227 for a in i.find_all("td"): 228 if dd==0: 229 aa.append(a.string) 230 elif dd==1: 231 aa.append(a.string) 232 elif dd==2: 233 aa.append(a.string) 234 elif dd==3: 235 aa.append(a.string) 236 #elif dd==4: 237 # aa.append(a.string) 238 dd=dd+1 239 bb.append(aa) 240 #将爬取的数据进行换行整理并输出数据 241 for m in bb: 242 print(m) 243 import csv 244 with open("D:\\人口.csv","w",encoding="utf-8") as fi: 245 writer=csv.writer(fi) 246 #给每列的数据列名 247 writer.writerow(["排名","城市","常住人口数","六普人口数"]) 248 for d in bb: 249 writer.writerow(d) 250 fi.close() 251 #将数据导出 252 import csv 253 import pandas as pd 254 import matplotlib.pyplot as plt 255 from sklearn import metrics 256 import warnings 257 warnings.filterwarnings("ignore") 258 df=pd.read_csv("D:\\人口.csv") 259 df 260 261 #画出城市与人口的饼图 262 for tj in range(len(df["常住人口数"])): 263 df.loc[tj,"常住人口数"]=float(df.loc[tj,"常住人口数"].split("万")[0]) 264 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 265 plt.rcParams['axes.unicode_minus']=False 266 #构造数据 267 labels = ["0-25%", "25-50%", "50-75%", "75-100%"] 268 colors = ['#CE0000', '#ff9999', '#4F4F4F', '#CABEFF'] 269 plt.pie(df["常住人口数"], #绘图数据 270 labels=["泉州","福州","厦门","漳州","莆田","宁德","龙岩","南平","三明"], 271 autopct='%.2f%%', 272 pctdistance=0.8, 273 labeldistance=1.1, 274 startangle=180, 275 radius=2.5, 276 counterclock=False, 277 wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, 278 textprops={'fontsize':10, 'color':'black'}, 279 ) 280 #添加图标题 281 plt.title('福建省人口城市分布') 282 #显示图形 283 plt.show() 284 285 #画出城市与人口的柱状图 286 plt.bar(df["城市"],df["常住人口数"]) 287 plt.xlabel("城市") 288 plt.ylabel("人口常住数(万人)") 289 290 #画出关于人口盒图 291 import seaborn as sns 292 sns.boxplot(df["常住人口数"])
七、总结:
这次数据爬虫,一开始感觉并没有什么头绪,不知道怎么开始,爬什么东西。但是在看了其他学姐学长的博客后,对于自己的爬虫有了大致的方向,知道了课题设计的主要流程和具体操作;对于自己有些不懂的地方也及时上网搜了资料去看了一些专门讲解此类的博客和视频。
一开始的时候爬取网站时,有些网站不能爬或是进行加密导致一开始的时候进度受阻,后来找了很久的网页后找到了适合自己的主题也可以爬取的网站,进度就快了许多!这次课题设计不仅让我了解到了不知道的东西,也让我在运用爬虫代码等操作更加流畅更加娴熟!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号