python博客园信息爬取--word篇
按照建民老师要求需要以上一篇博客爬取出来的excel作为目录,每一条信息独立成一个文档。
此操作可分为两部分,第一部分是对doct文件的处理,第二部分是对代码的处理
首先介绍doct文件的处理,doct文件为
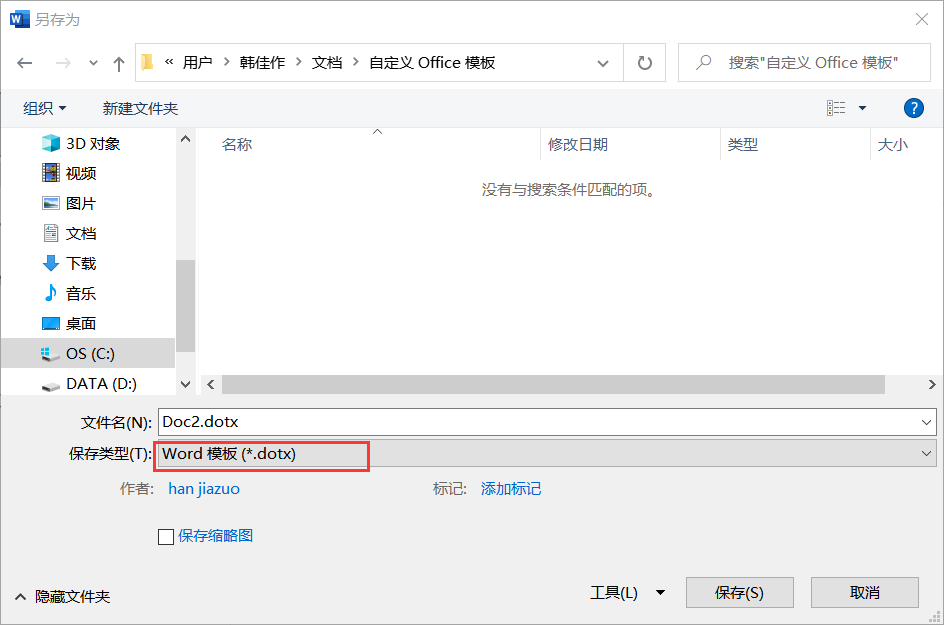
建立完文件后要对dotx文件进行编辑并加上书签。
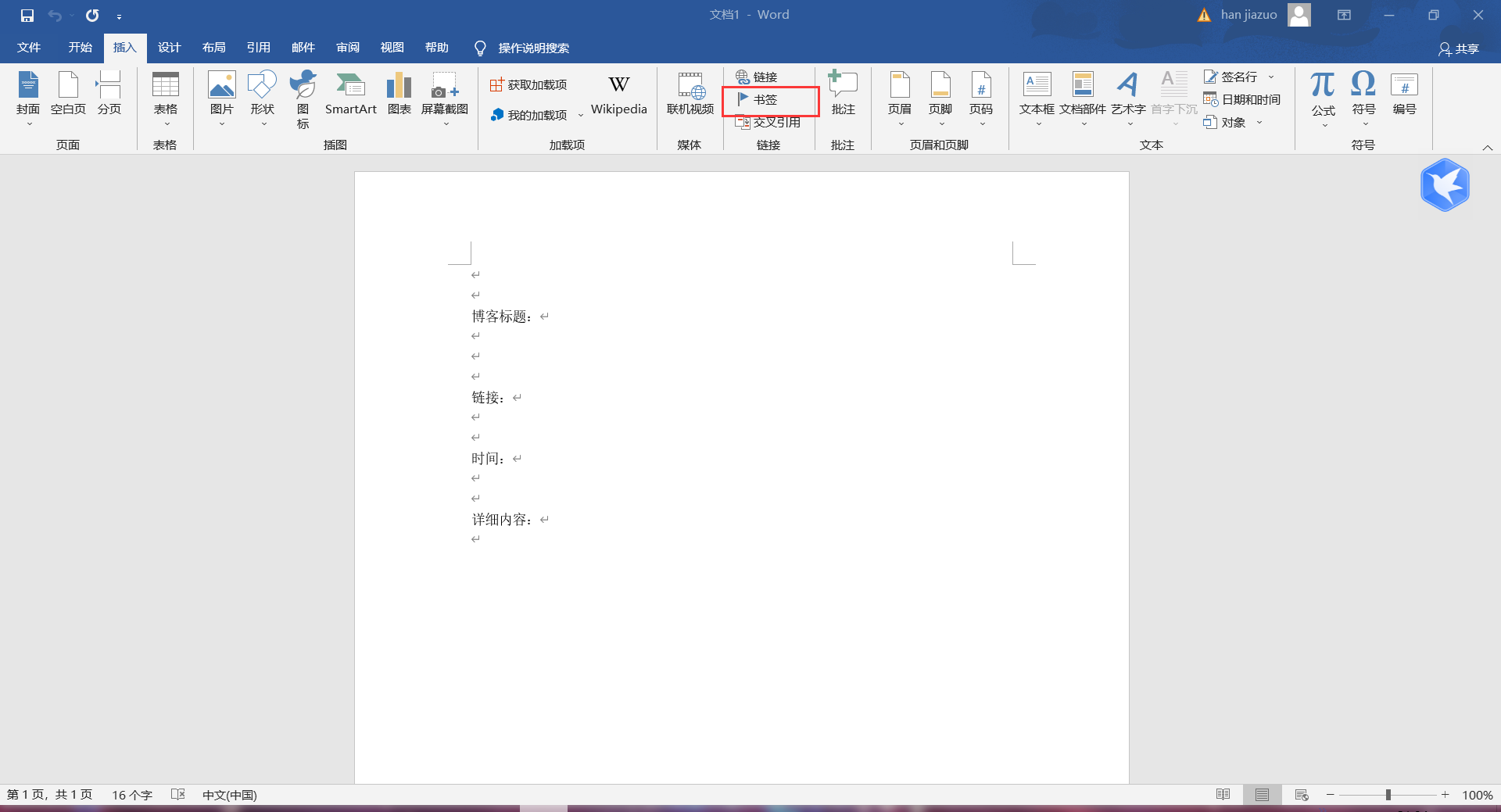
一定要记住标签的命名!!!!!!!大家这两天给我反馈的报错主要就是大家的标签名和代码里的不一致。
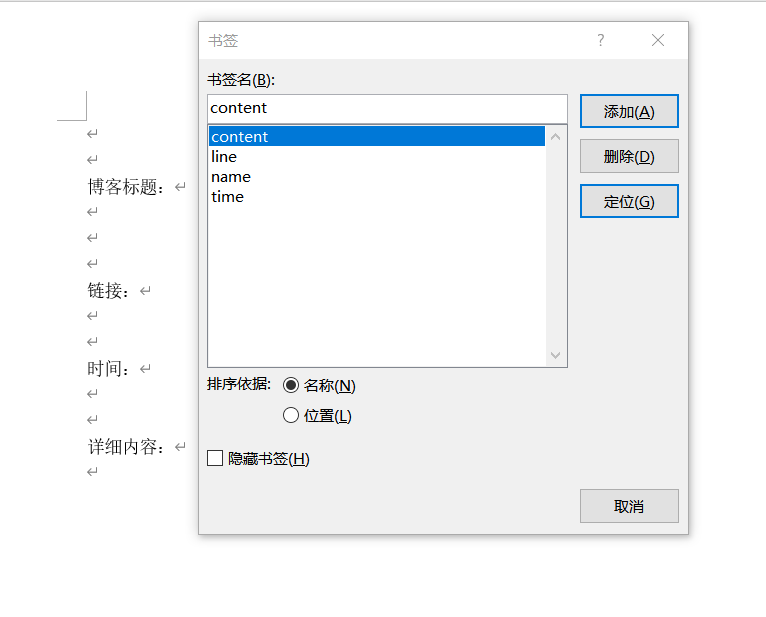
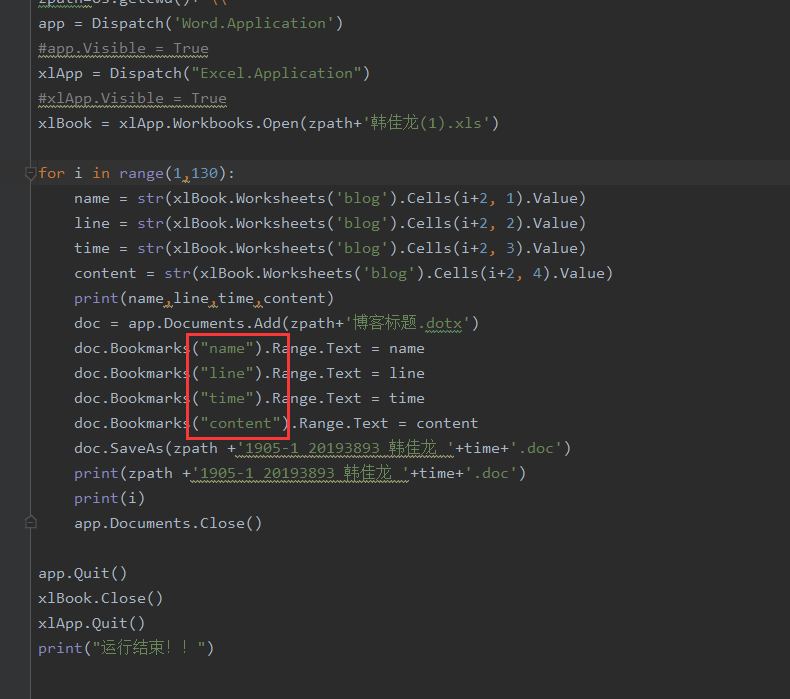
之后为python部分
from win32com.client import Dispatch
from datetime import datetime
import os
zpath=os.getcwd()+'\\'
app = Dispatch('Word.Application')
#app.Visible = True
xlApp = Dispatch("Excel.Application")
#xlApp.Visible = True
xlBook = xlApp.Workbooks.Open(zpath+'blog_list13.xlsx')
for i in range(5):
name = xlBook.Worksheets('blog').Cells(i+2, 1).Value
line = str(xlBook.Worksheets('blog').Cells(i+2, 2).Value)
time = str(xlBook.Worksheets('blog').Cells(i+2, 3).Value)
content = str(xlBook.Worksheets('blog').Cells(i+2, 4).Value)
print(name,line,time,content)
doc = app.Documents.Add(zpath+'博客标题.dotx')
doc.Bookmarks("name").Range.Text = name
doc.Bookmarks("line").Range.Text = line
doc.Bookmarks("time").Range.Text = time
doc.Bookmarks("content").Range.Text = content
doc.SaveAs(zpath +'1905-2 20194157 韩佳作 '+time+'.doc')
print(zpath +'1905-2 20194157 '+time+'.doc')
print(i)
app.Documents.Close() app.Quit() xlBook.Close() xlApp.Quit() print("运行结束!!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号