相克军_Oracle体系_随堂笔记003-体系概述
2014-07-03 20:49 AlfredZhao 阅读(2582) 评论(0) 收藏 举报1.进程结构图
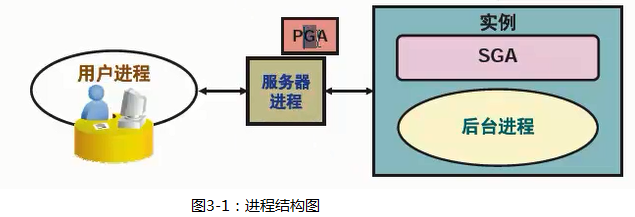
对Oracle生产库来讲,服务器进程(可以简单理解是前台进程)的数量远远大于后台进程。因为一个用户进程对应了一个服务器进程。
而且后台进程一般出问题几率不大,所以学习重点也是服务器进程和PGA的关系(容易出问题)。
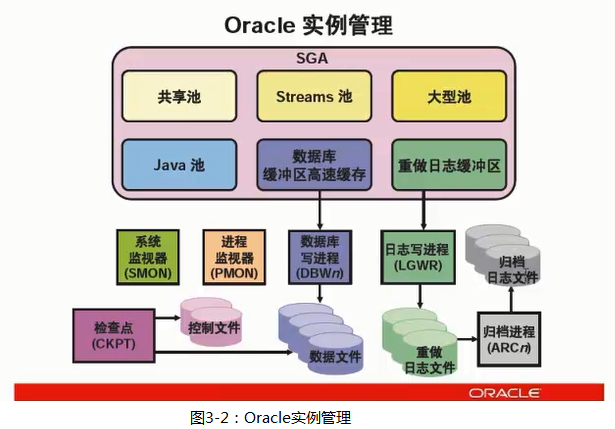
2.Oracle 实例管理
6大共享池,5大后台进程,3大文件
控制文件:记录了各文件存放的位置以及当前的运行状态;
数据文件:存放数据;
重做日志文件:对数据文件所有的修改记录;
补充知识点:
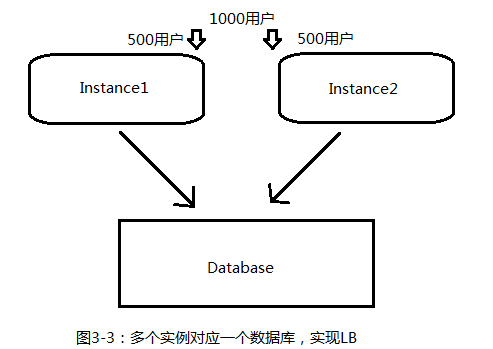
(1)实际生产环境中可以多个实例(一般是2个,4个,8个)对应一个数据库。
例如RAC技术,在日常情况下2个实例实现负载均衡(LB),在一个实例出故障的时候也能继续单实例运转。
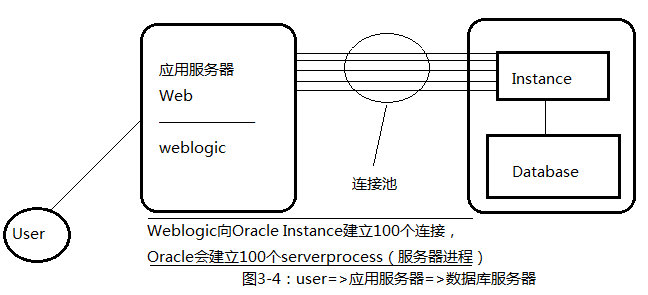
(2)实际生产库环境,user=>应用服务器=>数据库服务器;
客户端输入SQL语句,SQL语句通过网络到达,数据库实例,server process接受SQL语句。
3.SQL语句执行过程剖析
(1)sql语句读取数据:
解析(parse)=>执行(execute)=>获取数据(fetch)
解析简单划分可以分为:硬解析和软解析。(实际还有软软解析)
硬解析过程中:会判断sql语法,查询的表是否存在,是否有权限,判断如何执行(挑出最优的执行计划作为执行计划,最费时间,耗费CPU,I/O资源);
软解析是在shared pool中library cache中找到了缓存的sql语句和执行计划,这样就不会再挑选执行计划,节约了大部分时间。
sql语句读取这块还引入了一个L I/O和 P I/O的概念:
L I/O 逻辑读(内存读)
P I/O 物理读(硬盘读)
Database buffer cache:用来缓存dbf的数据块。如果用户查询的数据块没有在这里找到,会从数据文件中取数据先放在buffer cache中,再返回给用户。
有关缓存的地方都涉及一个命中率的概念,实际上,命中率低一定有问题,命中率高不一定没问题,还要关注此时系统每秒钟的物理读是多少。
#vmstat 1 10
#iostat 1 10
(2)sql语句修改数据:
只是修改buffer cache中的数据,这样效率高。
注:server process不负责写,由background process负责写(DBWn,LGWR)。这实际上是Oracle设计的一个小技巧,把用户不关心的事情交给后台进程来做,把跟用户关心的才交给server process来做,后期优化也主要就针对server process进行优化。
4.shared pool、sql共享、绑定变量
a、shared pool的组成
3块区域:free、library cache、row cache
b、硬解析
硬解析步骤、软解析步骤
讲解shared pool内存块组成结构
两个概念:chain、chunk
ora-4031错误
软硬解析的具体情况
c、SQL共享,绑定变量
SQL语句组成,动态部分、静态部分
cursor_sharing
3块区域:free、library cache、row cache
select * from v$sgastat a where a.name = 'library cache';
select * from v$sgastat a where a.pool = 'shared pool' and a.name = 'free memory';
select * from v$sgastat a where a.name = 'row cache';
简述数据字典
硬解析步骤、软解析步骤
讲解shared pool内存块组成结构
两个概念:chain、chunk
ora-4031错误
select count(*) from x$ksmsp;
select count(*) from dba_objects;
alter system flush shared_pool;
select name, value from v$sysstat where name like 'parse%';
SQL语句组成,动态部分、静态部分
cursor_sharing
delare
v1 varchar2(10);
n1 int;
begin
n1:=1;
select salary into v1 from test where id=n1;
end;
AlfredZhao©版权所有「从Oracle起航,领略精彩的IT技术。」
转载请注明原文链接:https://www.cnblogs.com/jyzhao/p/3819367.html

转载请注明原文链接:https://www.cnblogs.com/jyzhao/p/3819367.html
👋 感谢阅读,欢迎关注我的公众号 「赵靖宇」

 浙公网安备 33010602011771号
浙公网安备 33010602011771号