
用动态规划建立中文分词的语言模型
===============================================================================
如有需要可以转载,但转载请注明出处,并保留这一块信息,谢谢合作!
部分内容参考互联网,如有异议,请跟我联系!
作者:刀剑笑(Blog:http://blog.csdn.net/jyz3051)
Email:jyz3051 at yahoo dot com dot cn('at'请替换成'@','dot'请替换成'.' )
===============================================================================
关键词:中文分词,中文分词语言模型,动态规划
前面的文章中(详细请参见"中文分词的语言模型"),我们给出了能够融合三种分词算法的语言模型,该模型能够融合目前出现的所有三种分词算法,并将该语言模型用一个统一的概率模型表示出来:给出原子系列,最有可能出现的中文词语系列就是我们需要的最终分词结果,可表示如下:
W* = max P(W)/P(A) = max P(w1w2w3……wk)/P(A)
最后,我们给出了求解该模型的网络示意,中文分词就成为求解最大概率的路径,中文分词过程就变成了以下的两个过程:
两者综合的概率越大,则越有可能形成这个系列,从而越有可能成为我们的最优分词结果。
P(L) = P(w2|w1)P(w3|w1w2) P(w4|w1w2w3) ……P(wk|w1w2w3…w(k-1))
如路径L1"李/胜利/说/的/确实/在理/ E##E"中,词语系列W={李,胜利,说,的,确实,在理},则这条路径出现的概率可以表示为:
P(L1) = P(胜利|李) * P(说|李胜利) * P(的|李胜利说) * P(确实|李胜利说的)
* P(李) P(胜利) P(说) P(的) P(确实) P(在理)
P(L) = P(w2|w1) * P(w3|w2) * P(w4|w3) *……* P(wk|w(k-1))
*P(w1) * P(w2) * P(w3)…… * P(wk)
结合上面出现的"动态规划路径图"可以看出,p(wi|wi-1)表示在前一个词出现的情况下,后一个词出现的概率,即图形中"边"的权重,而P(wi)则表示某个词语出现的概率,即图中"结点"的权重。
此时,可以得到一个标注权重的"动态规划路径图",示意图如下:
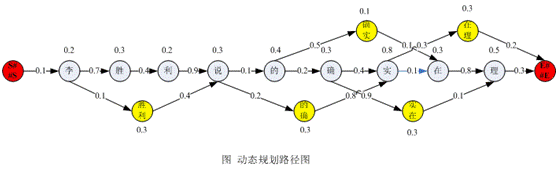
经过这个转换之后,我们就把中文分词过程(找出最大概率的词语系列)转换成了寻找一条从"S##S"到"E##E"最大可能路径的问题,很明显这是一个动态规划问题。其中:
===============================================================================
如有需要可以转载,但转载请注明出处,并保留这一块信息,谢谢合作!
部分内容参考互联网,如有异议,请跟我联系!
作者:刀剑笑(Blog:http://blog.csdn.net/jyz3051)
Email:jyz3051 at yahoo dot com dot cn(‘at’请替换成’@’,’dot’请替换成’.’ )
===============================================================================


 浙公网安备 33010602011771号
浙公网安备 33010602011771号