第七节 自然语言处理和BERT(自注意力机制)
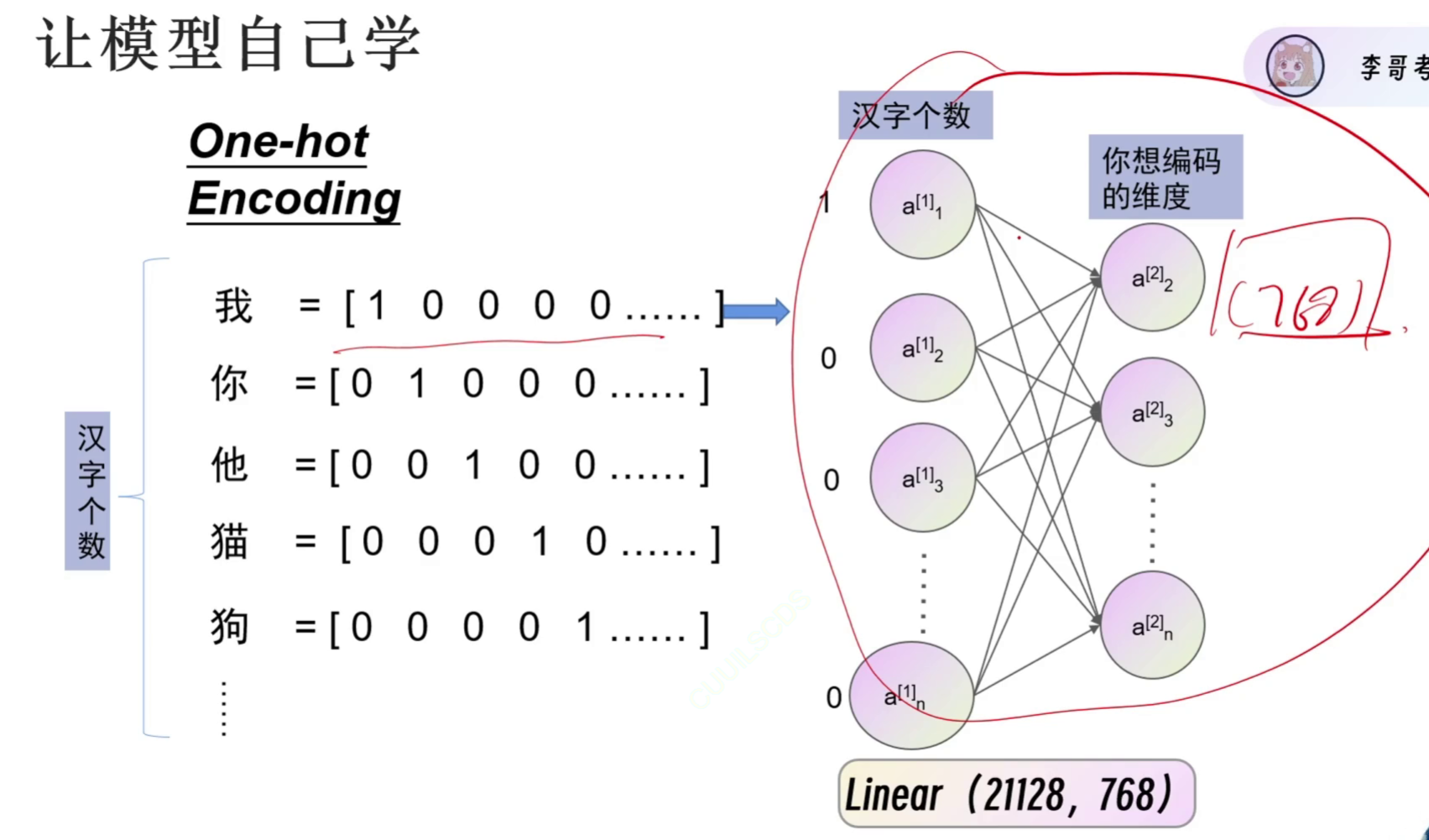
独热编码表示汉字的缺点:
- 长
- 不表示含义
word embedding让意思相近的汉字离得更近
![]()
![]()

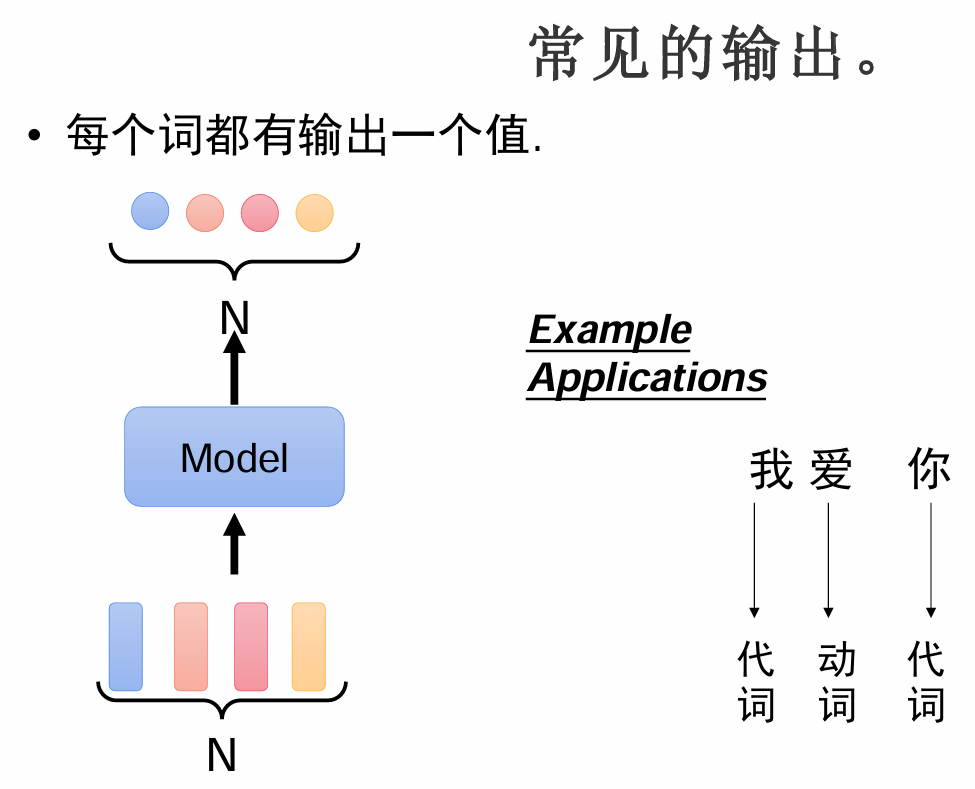
常见输入

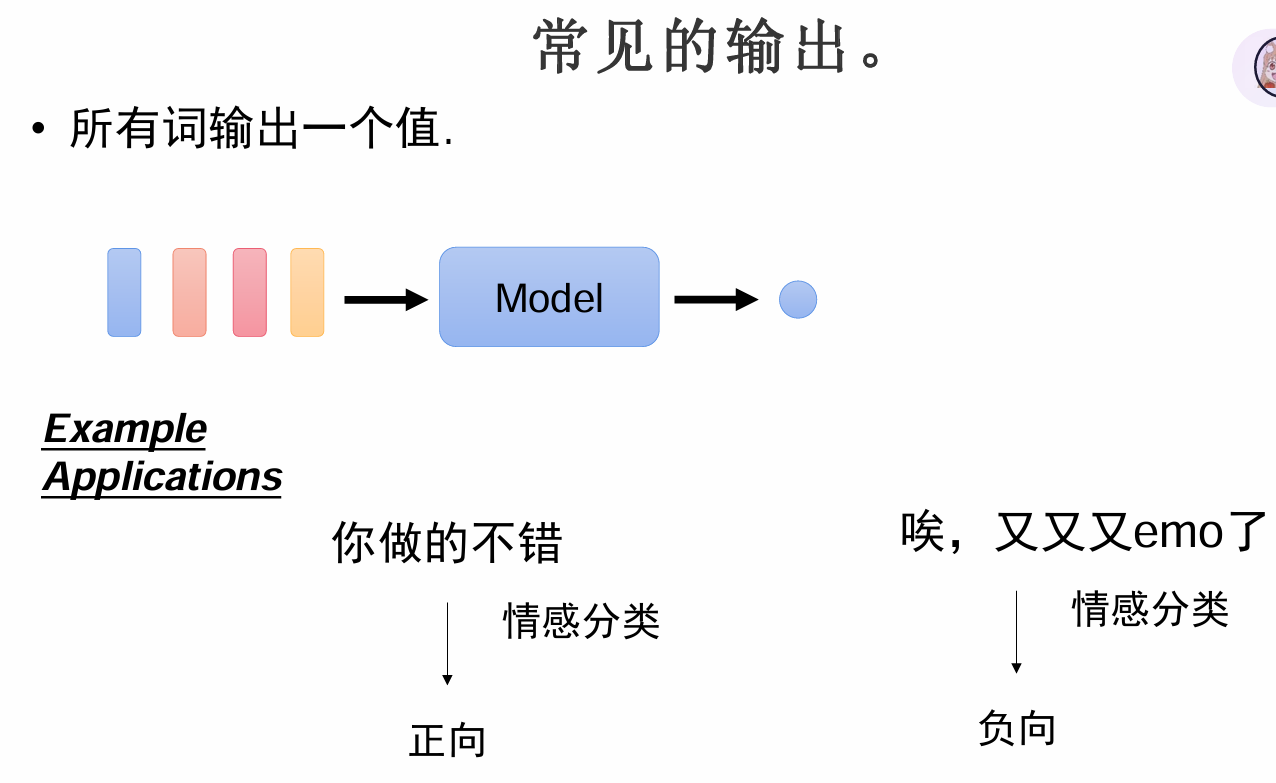
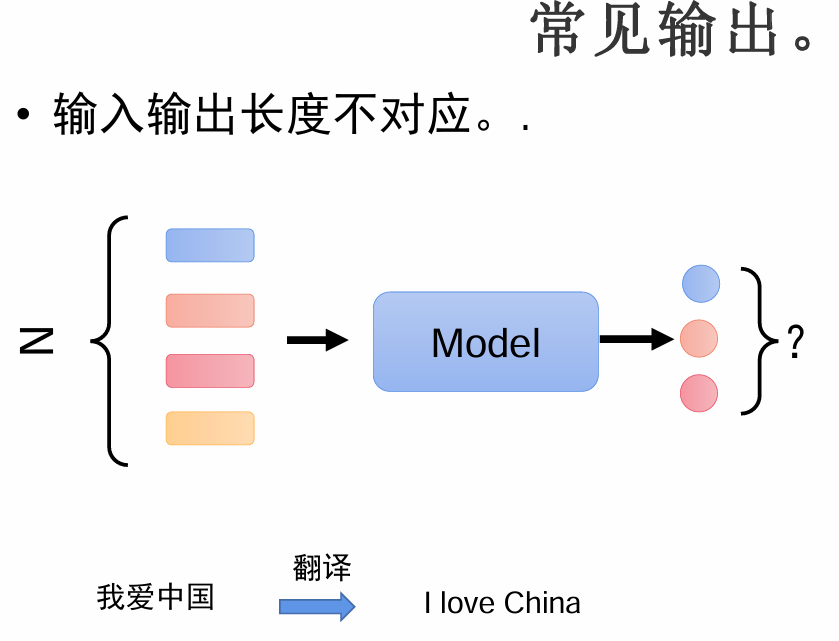
常见输出
循环神经网络(Recurrent Neural Network,RNN)
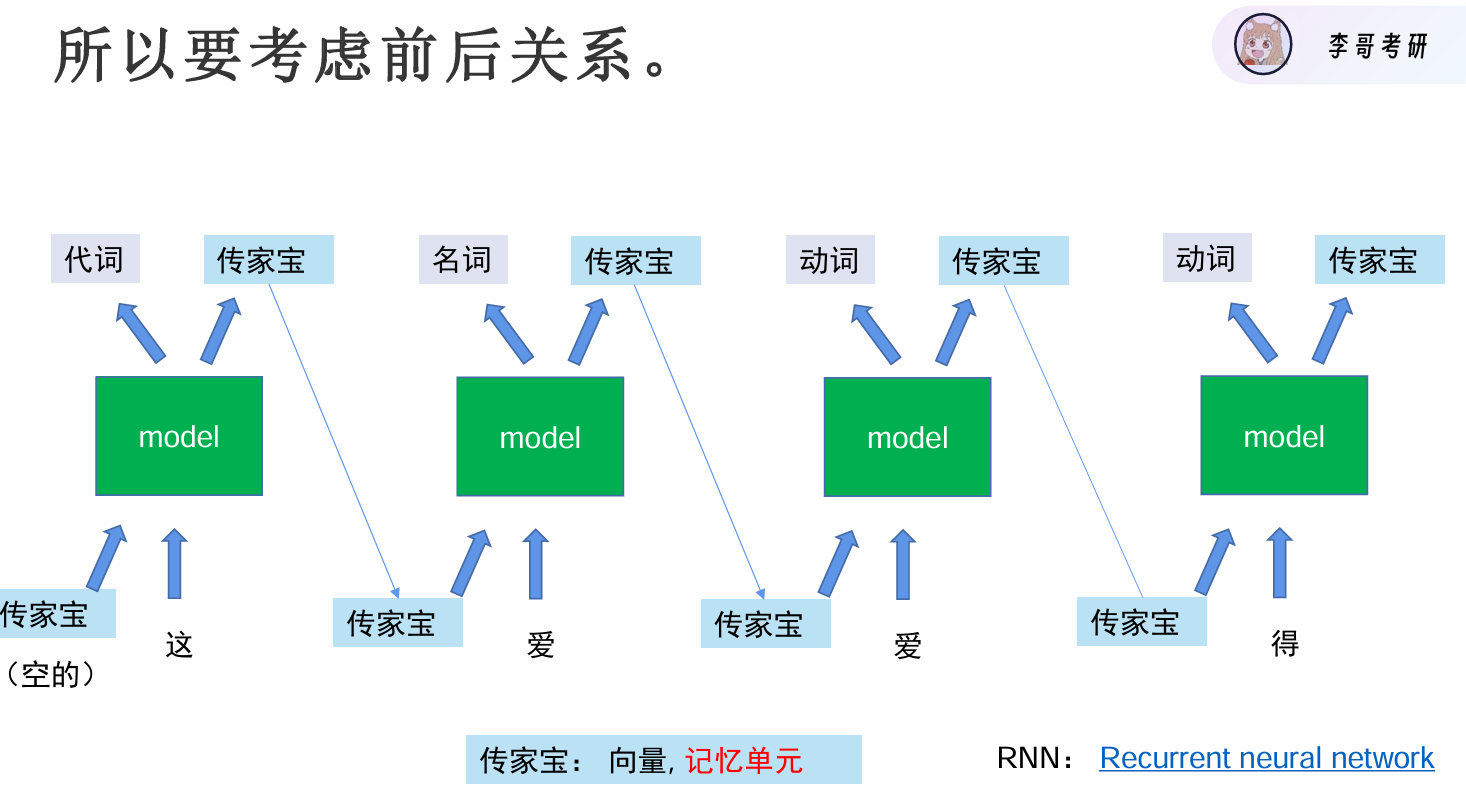
防止垃圾进入传家宝,干扰我们的选择,推出LSTM模型
长短期记忆(Long short-term memory, LSTM)
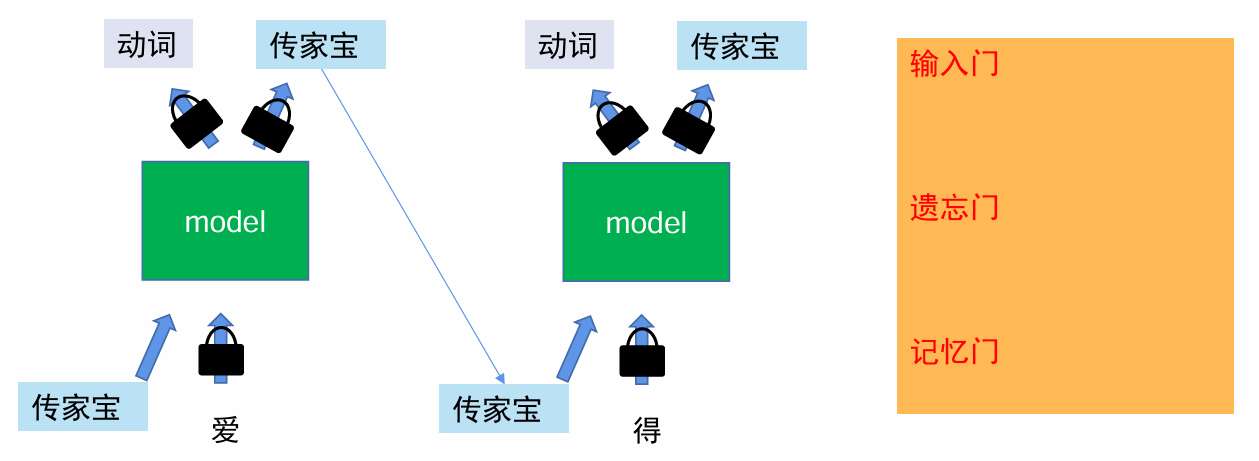
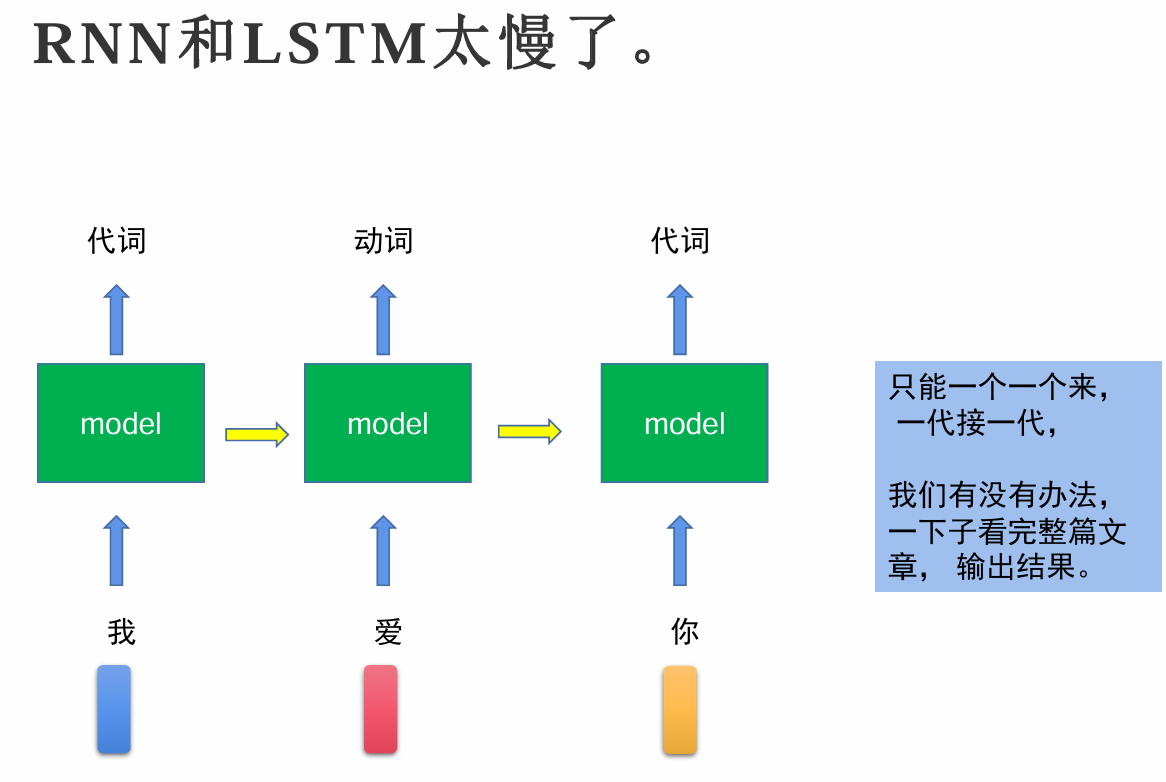
RNN和LSTM的缺点
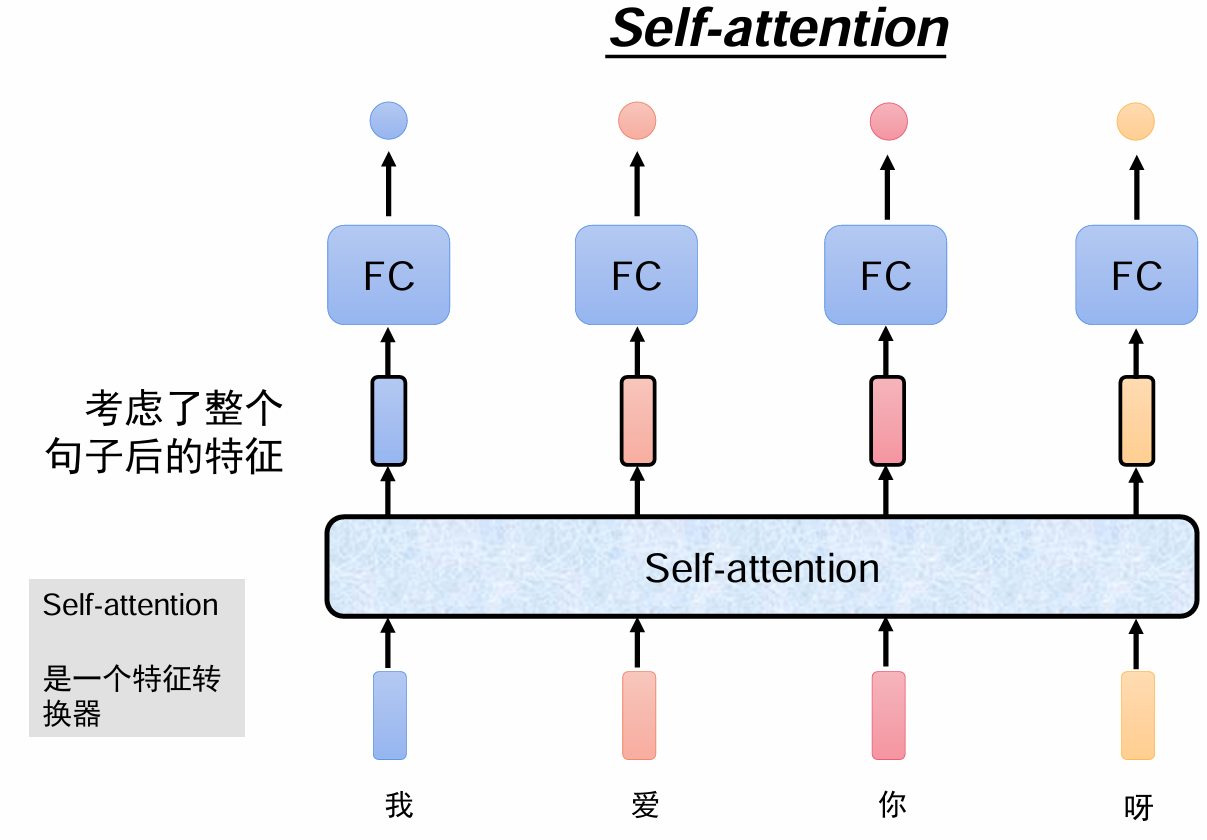
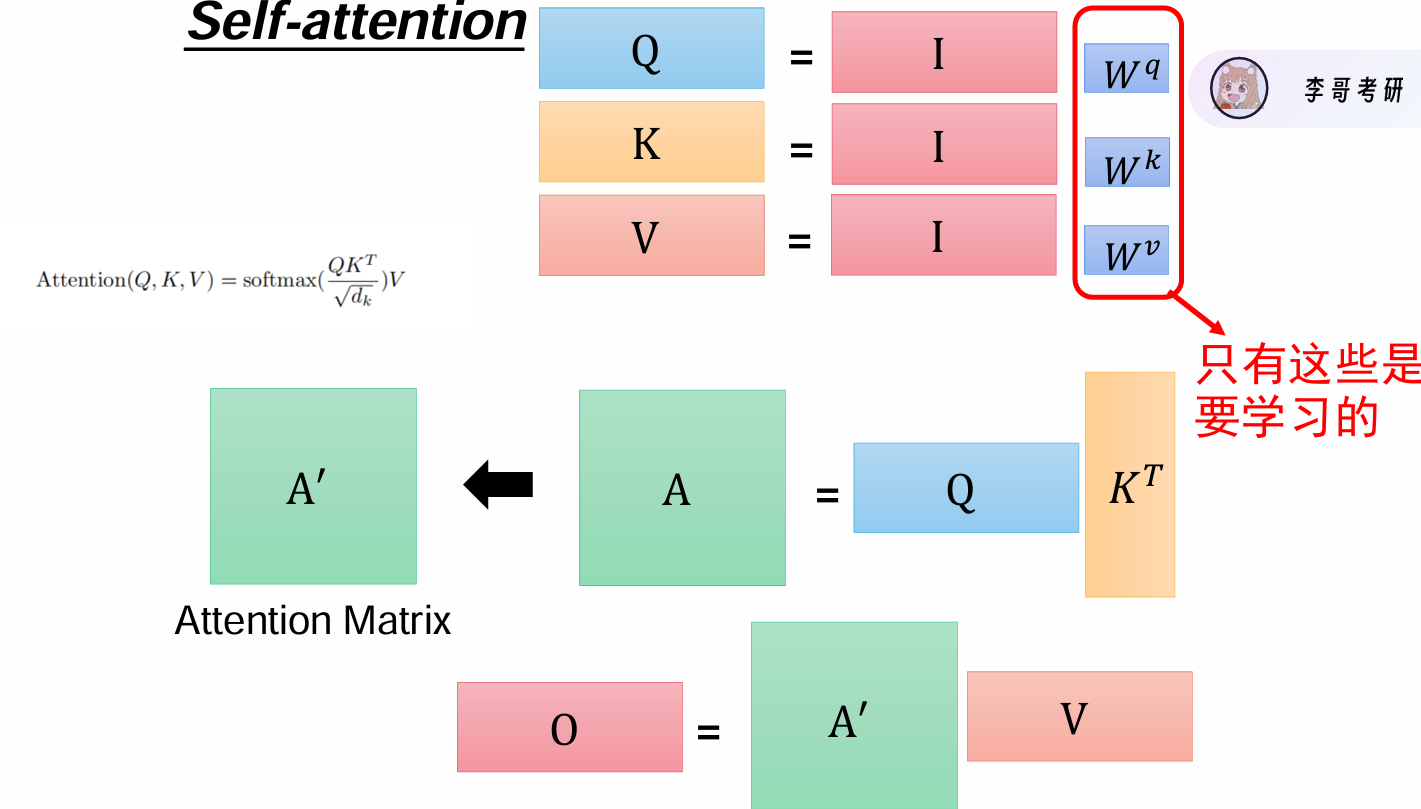
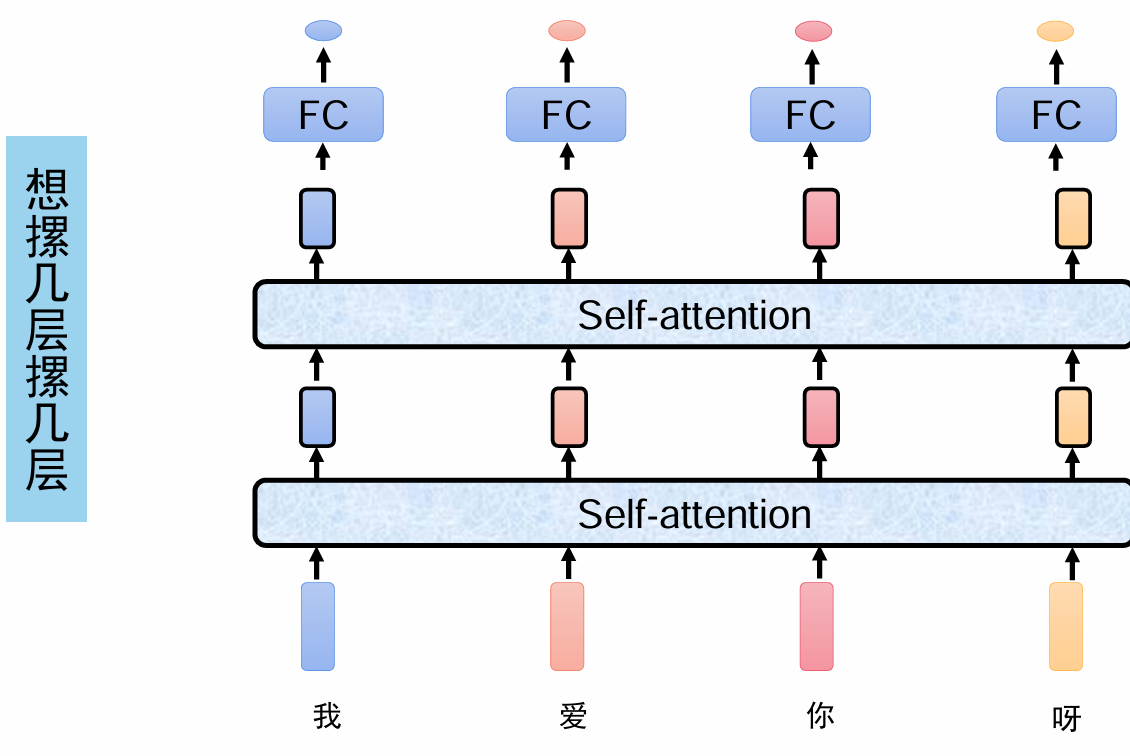
自注意力机制Self-attention
来源于右边文章,提出模型transformer
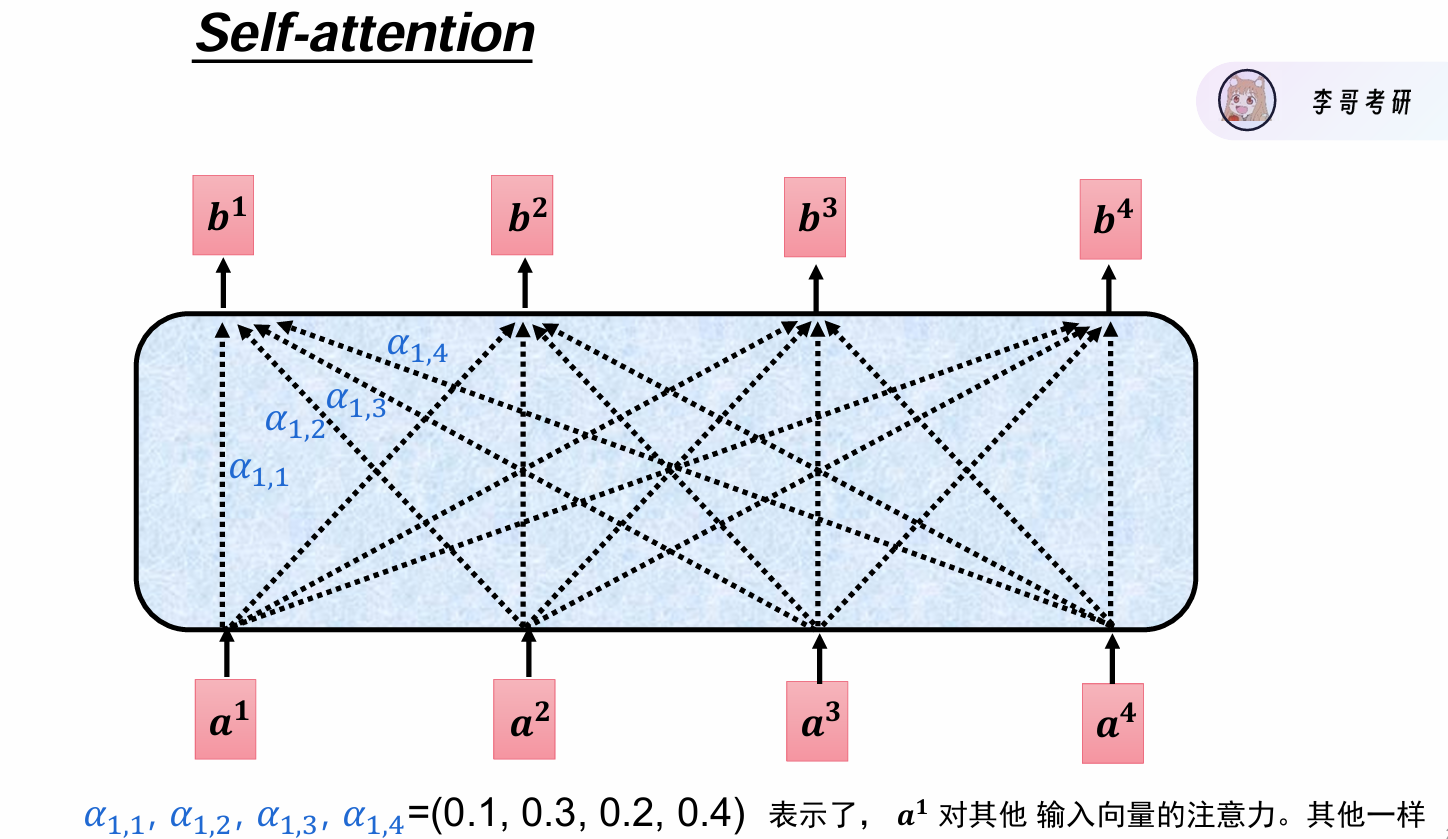
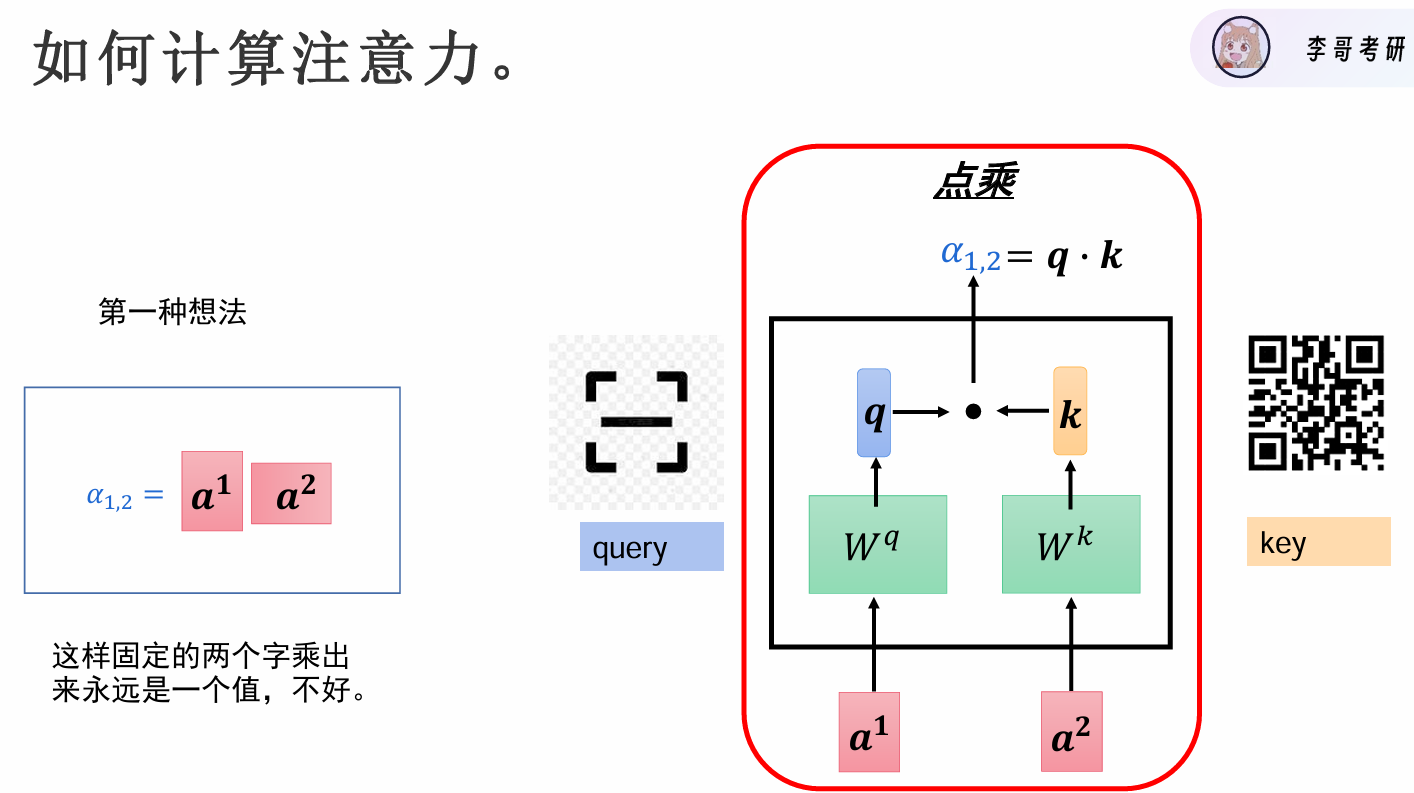
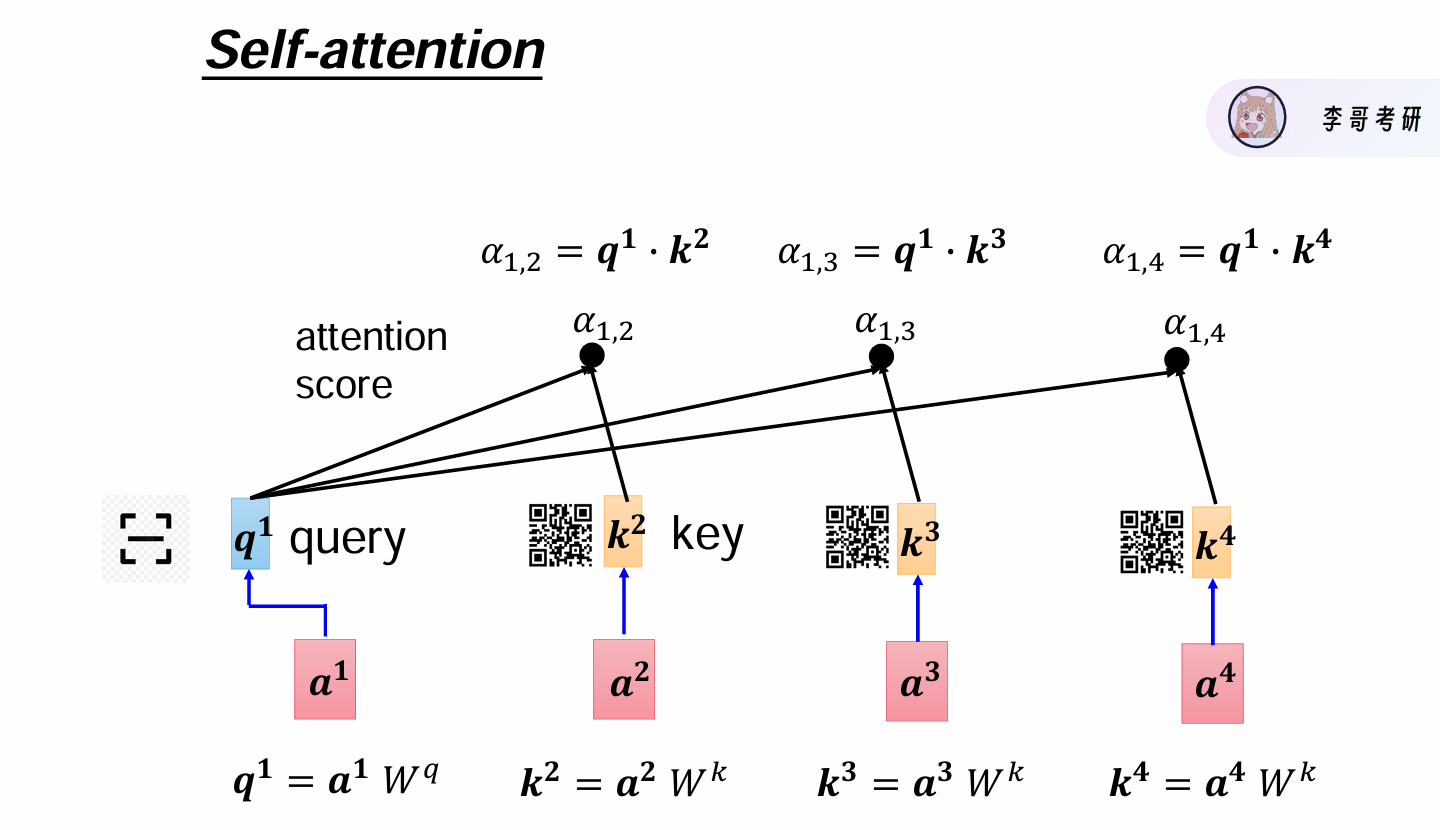
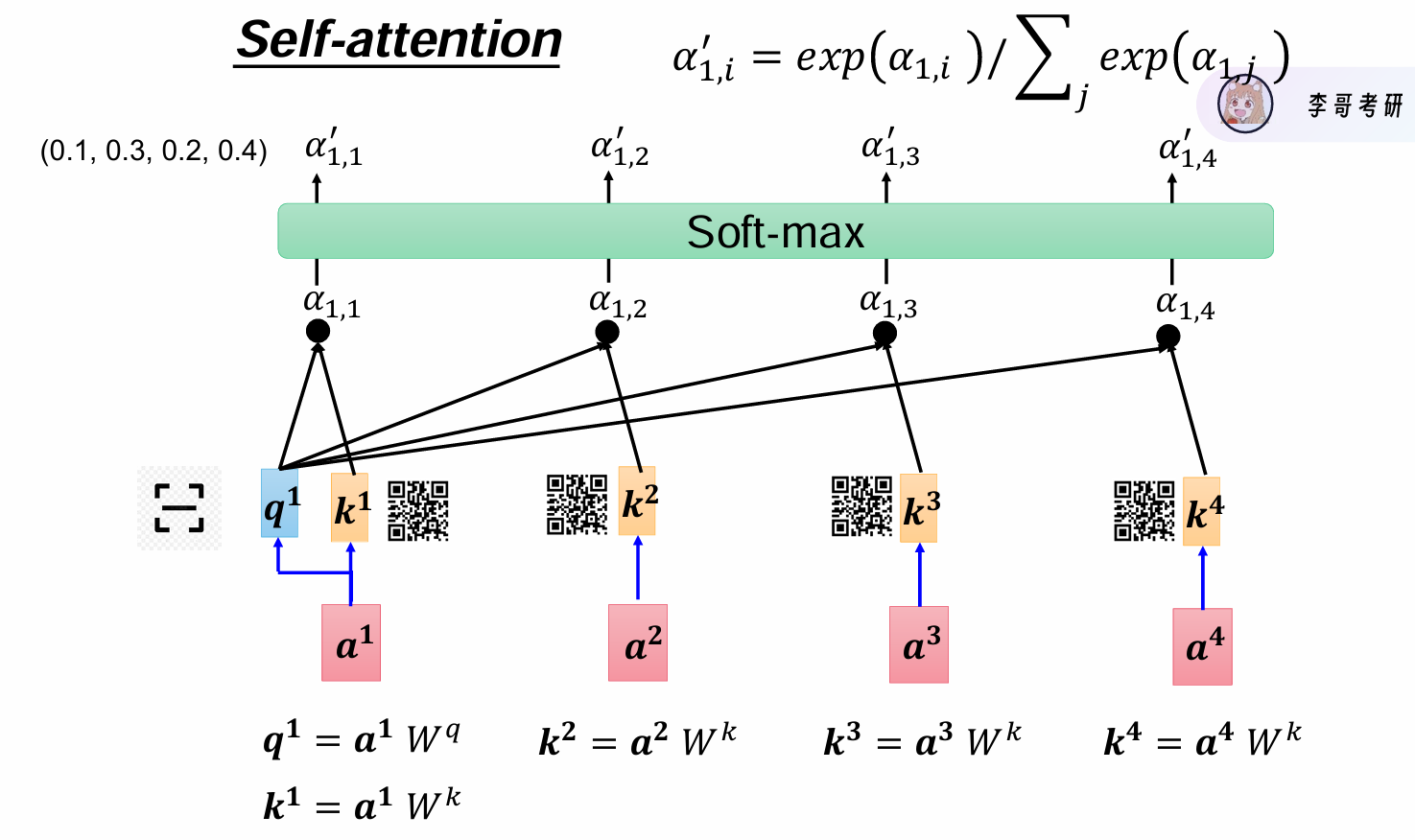
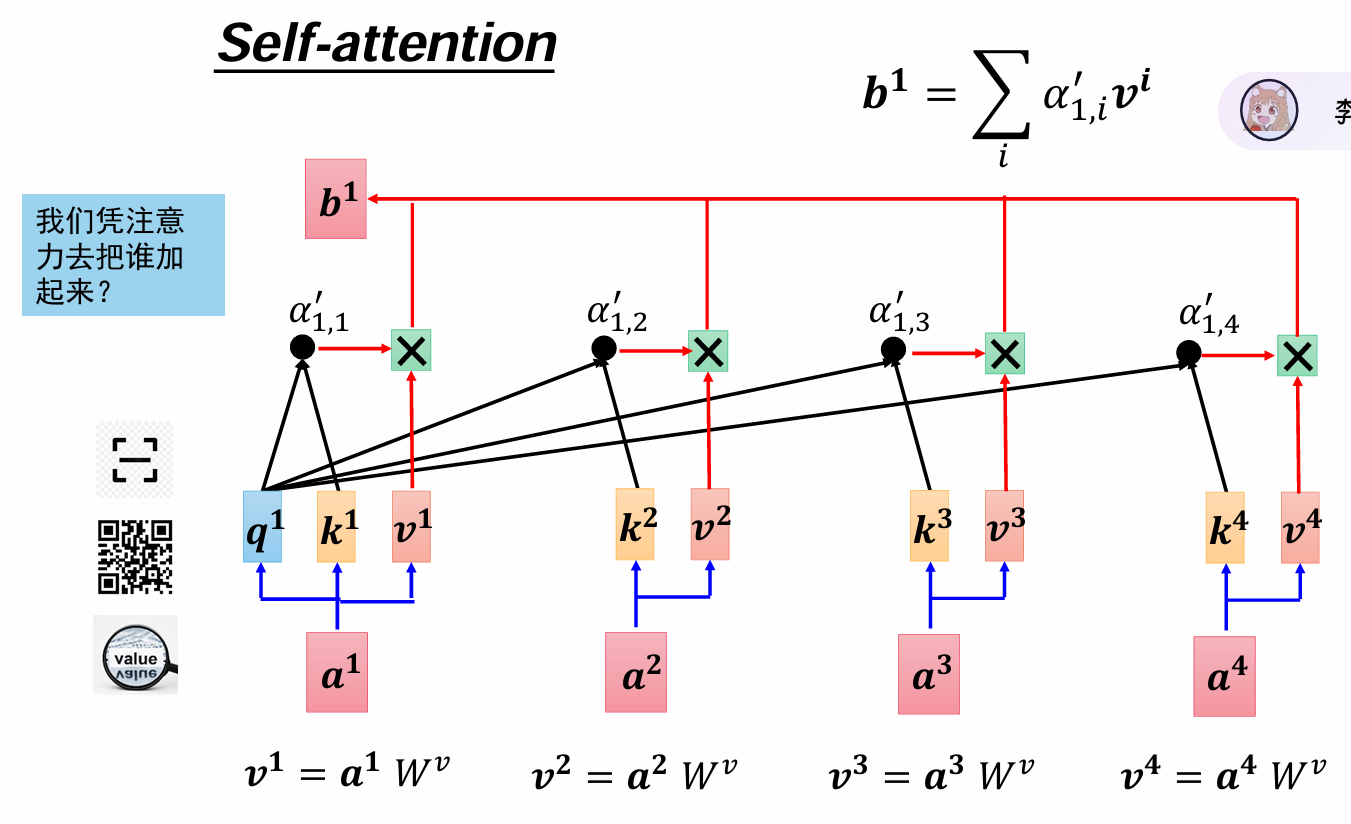
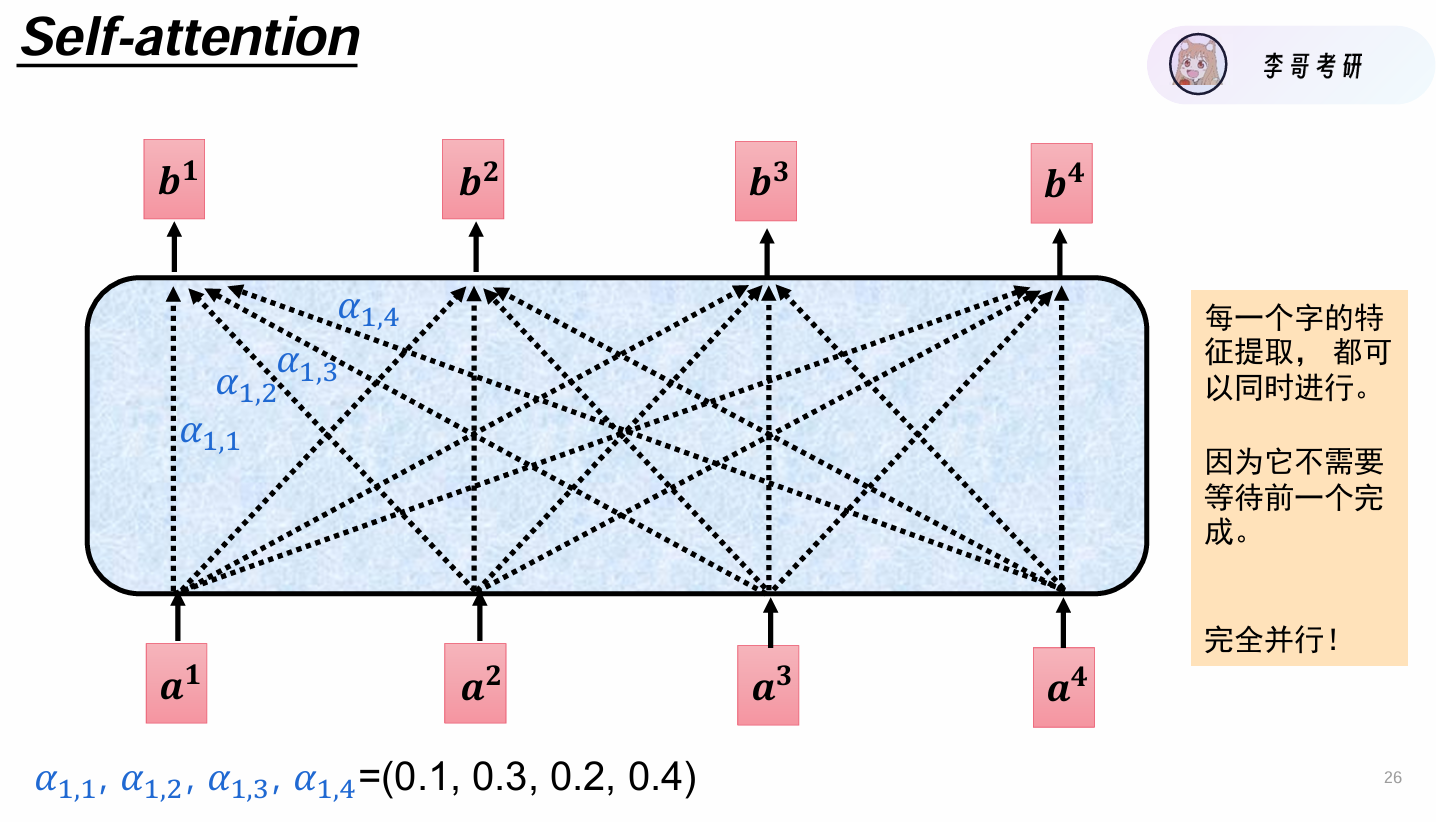
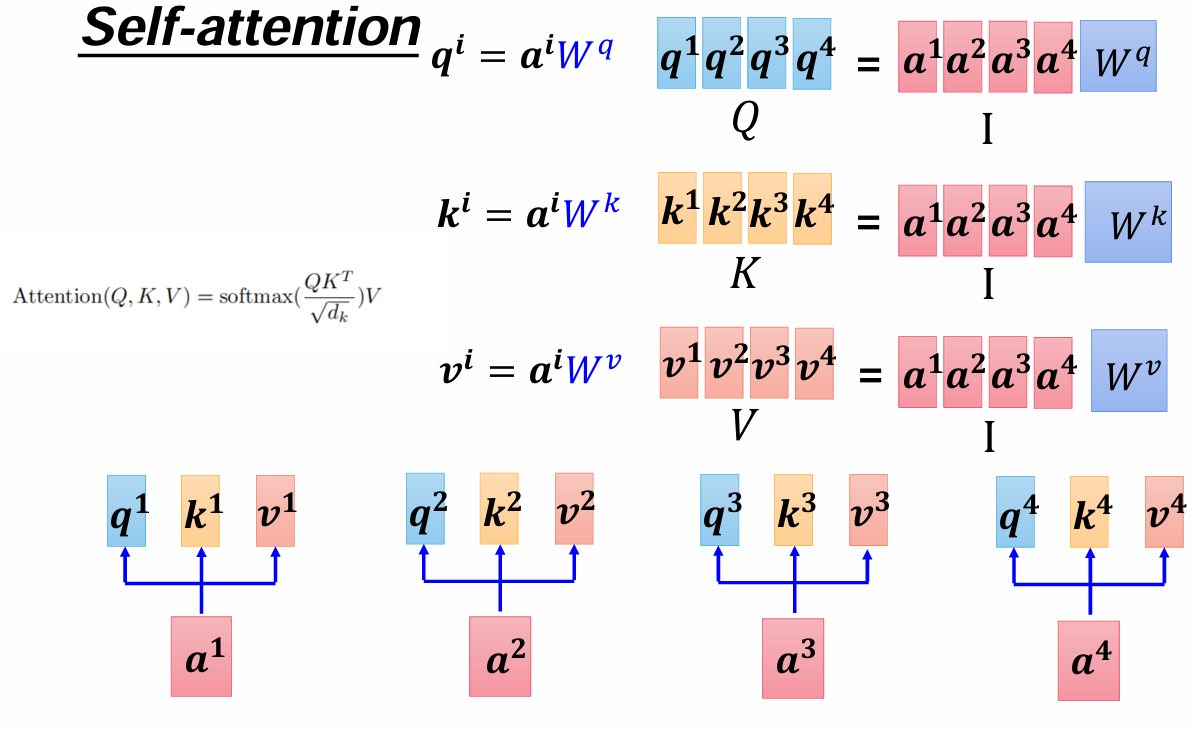
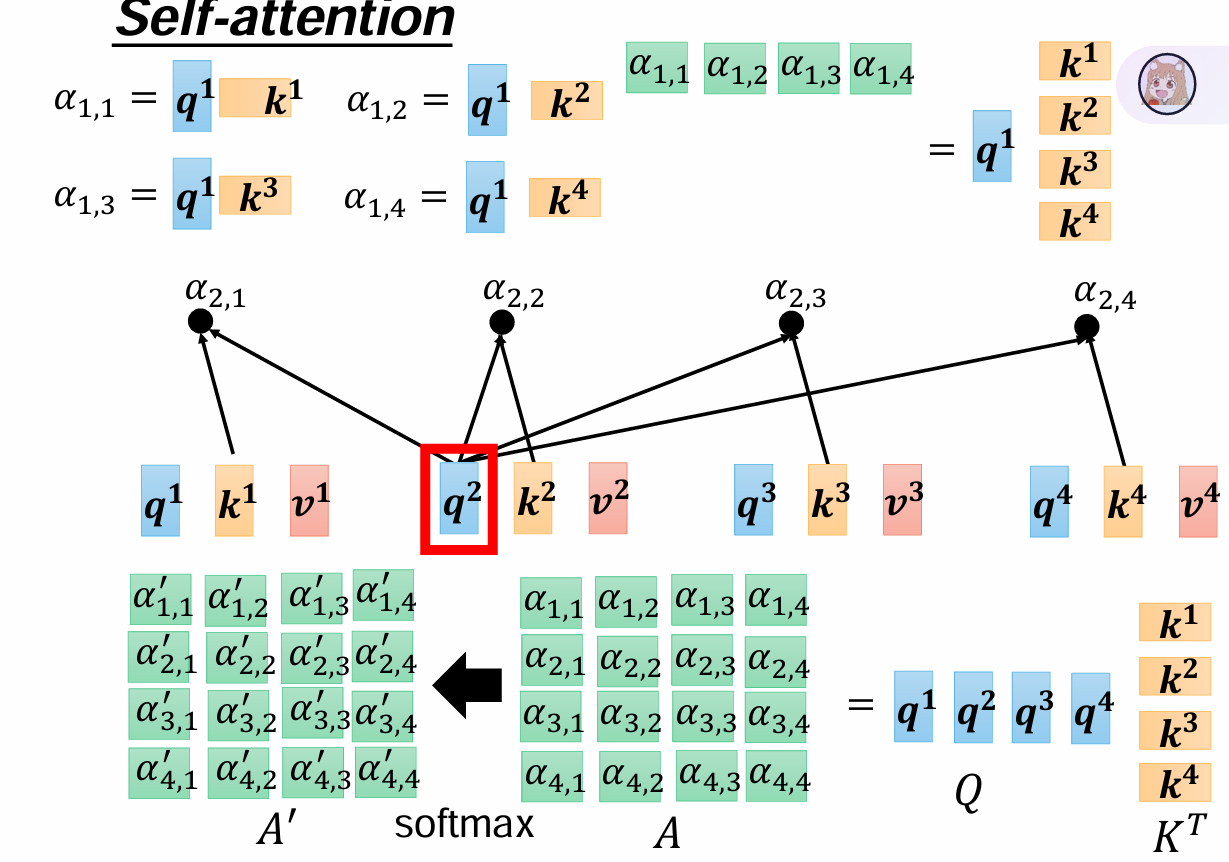
计算过程
位置信息
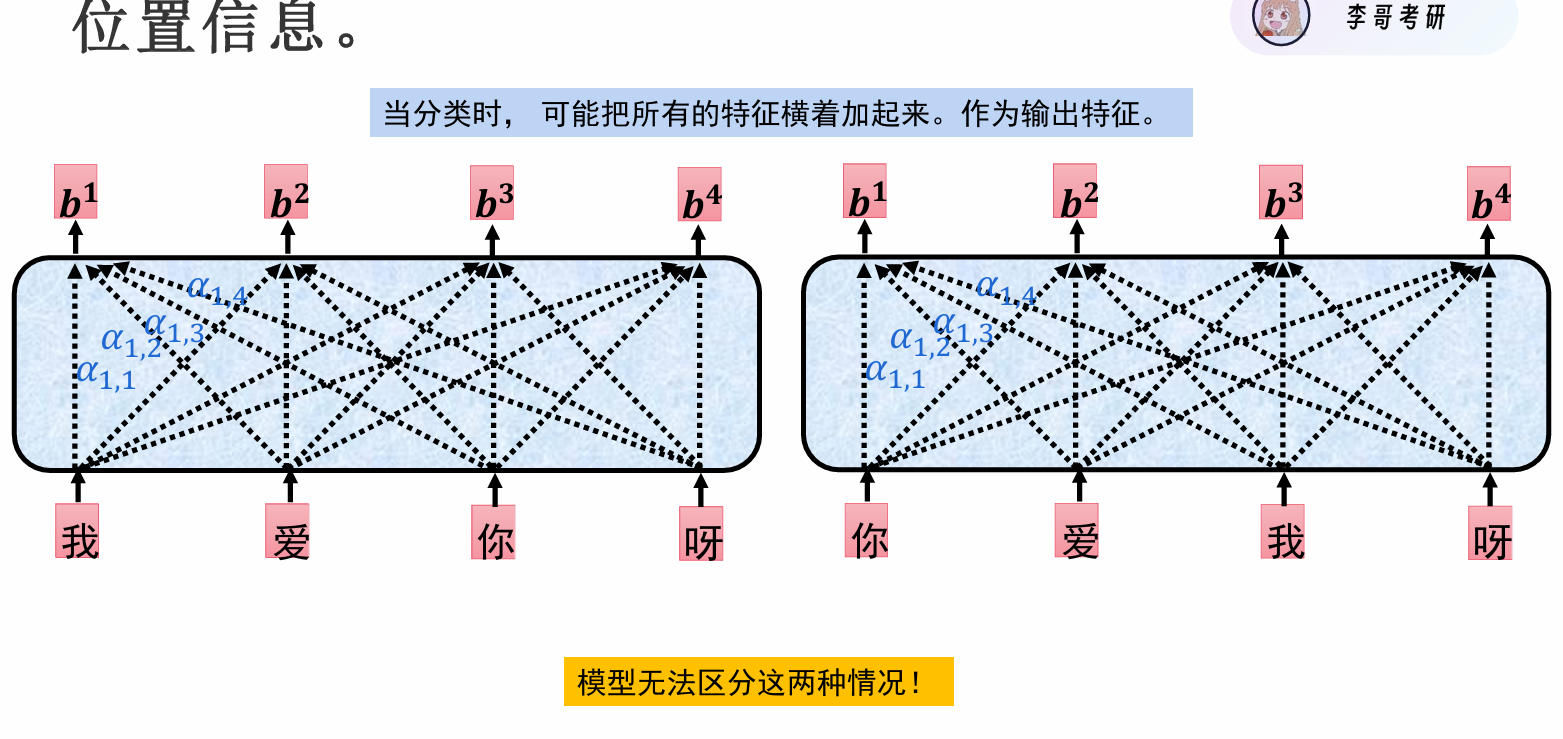
我爱你呀和你爱我呀输出结果一样
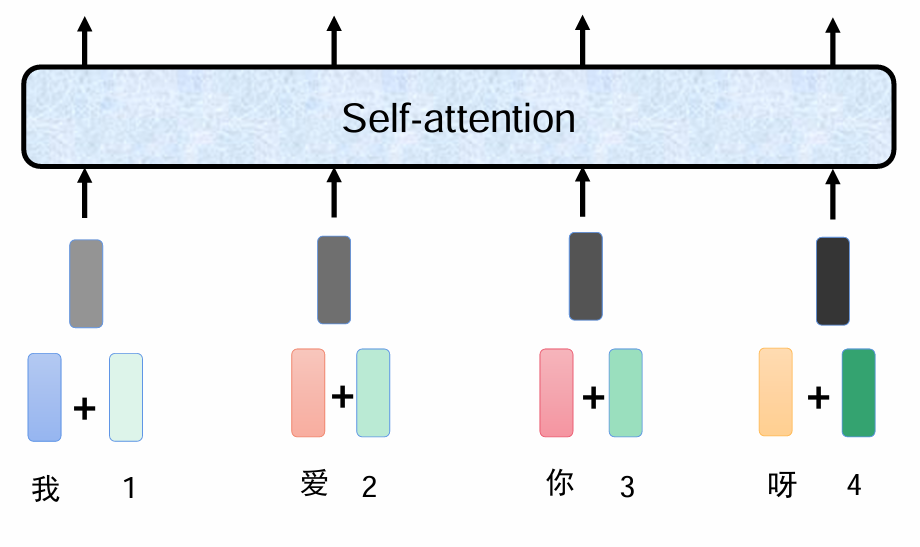
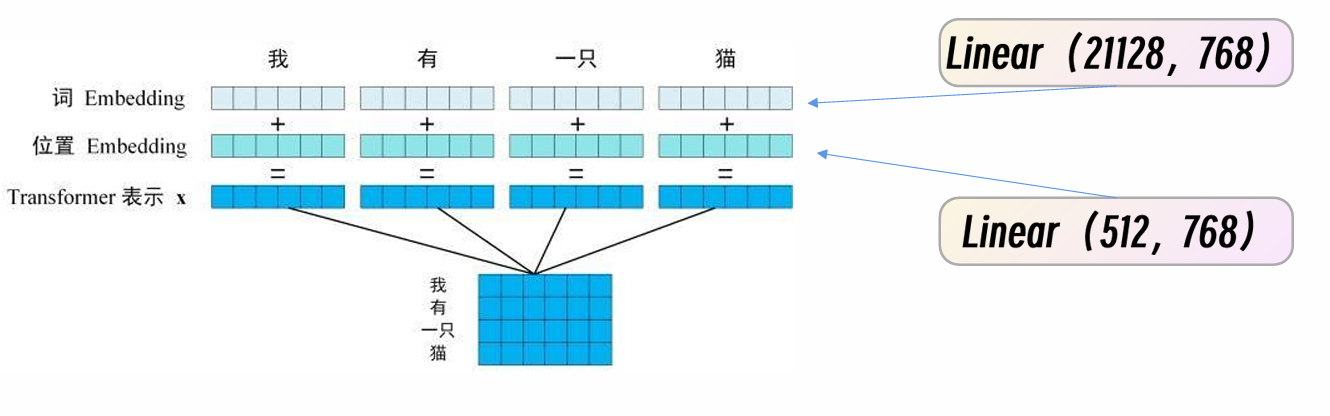
一个字是一个token 768维向量
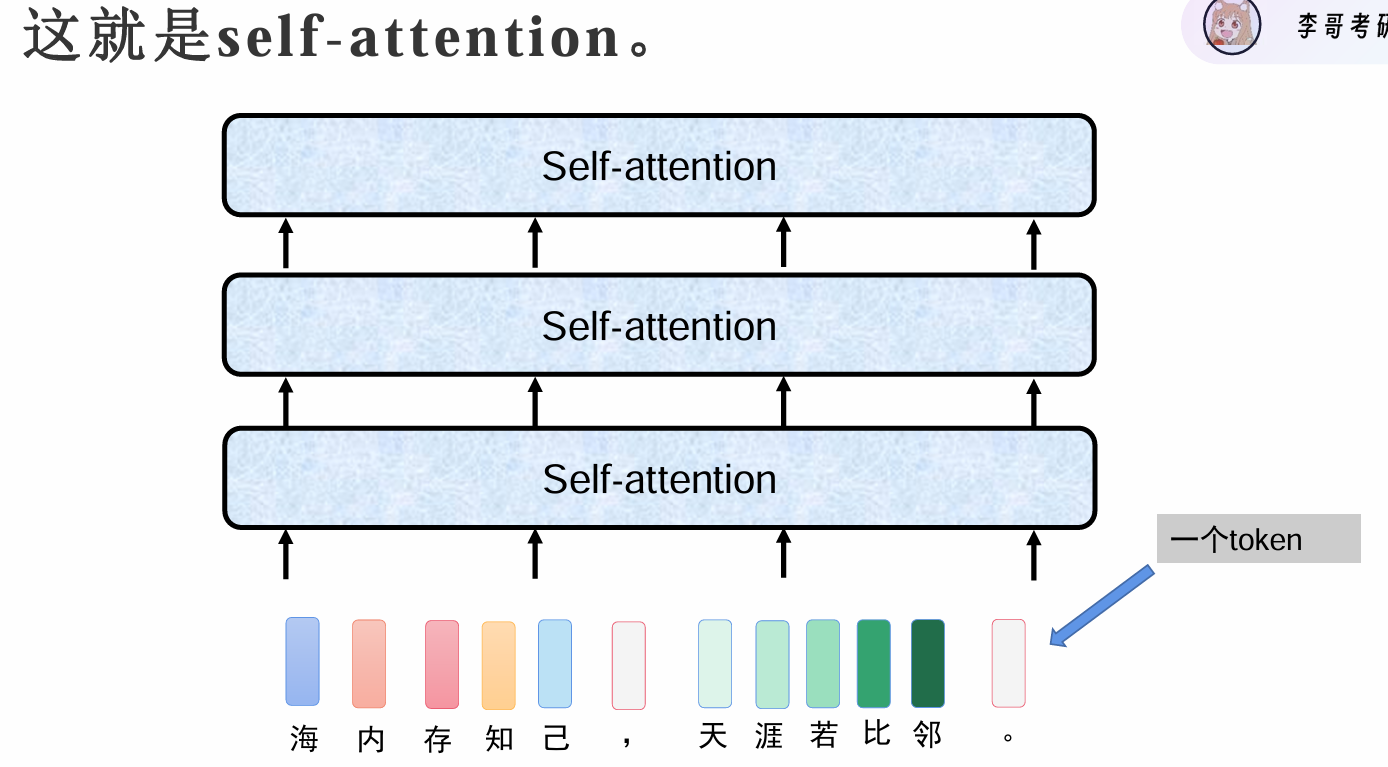
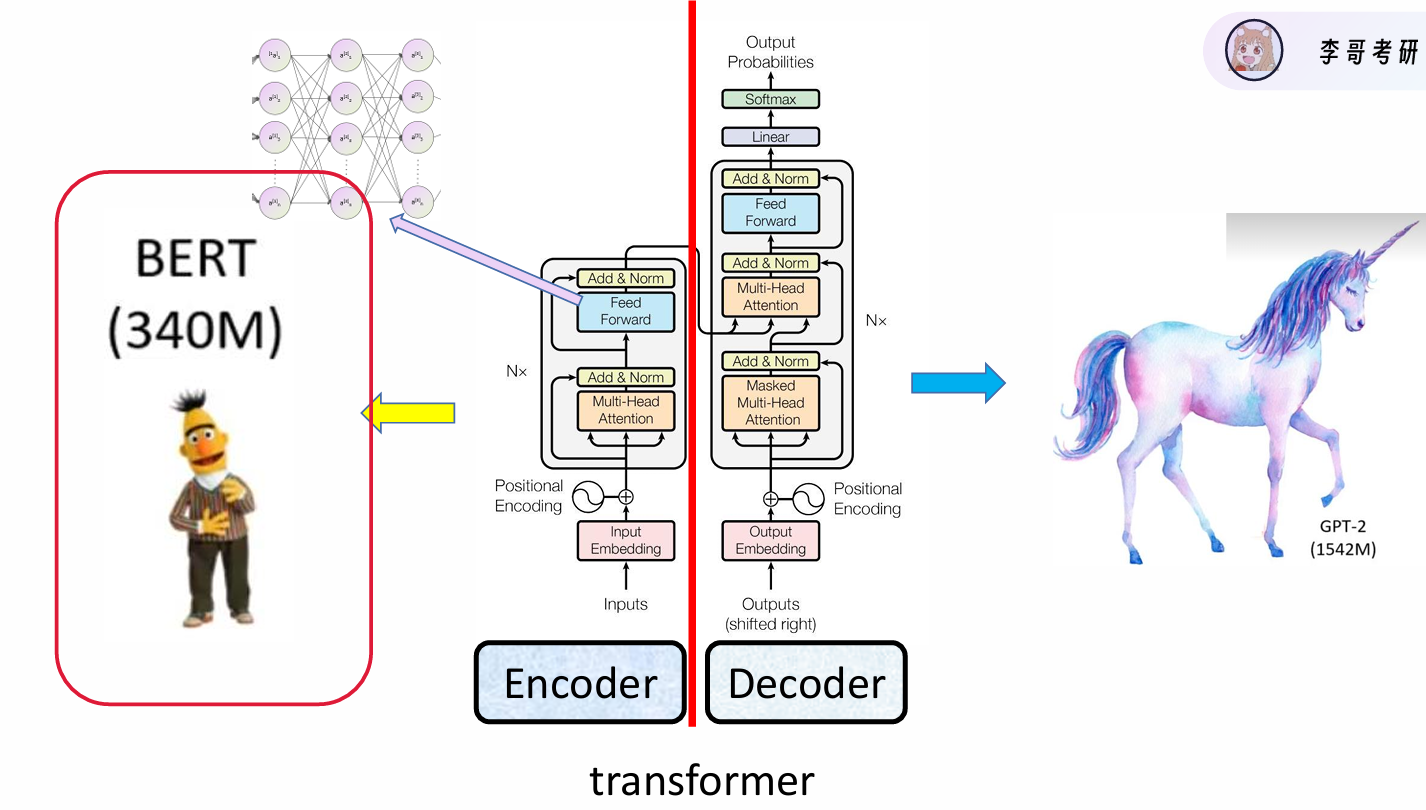
左边文字分类 右边生成模型GPT
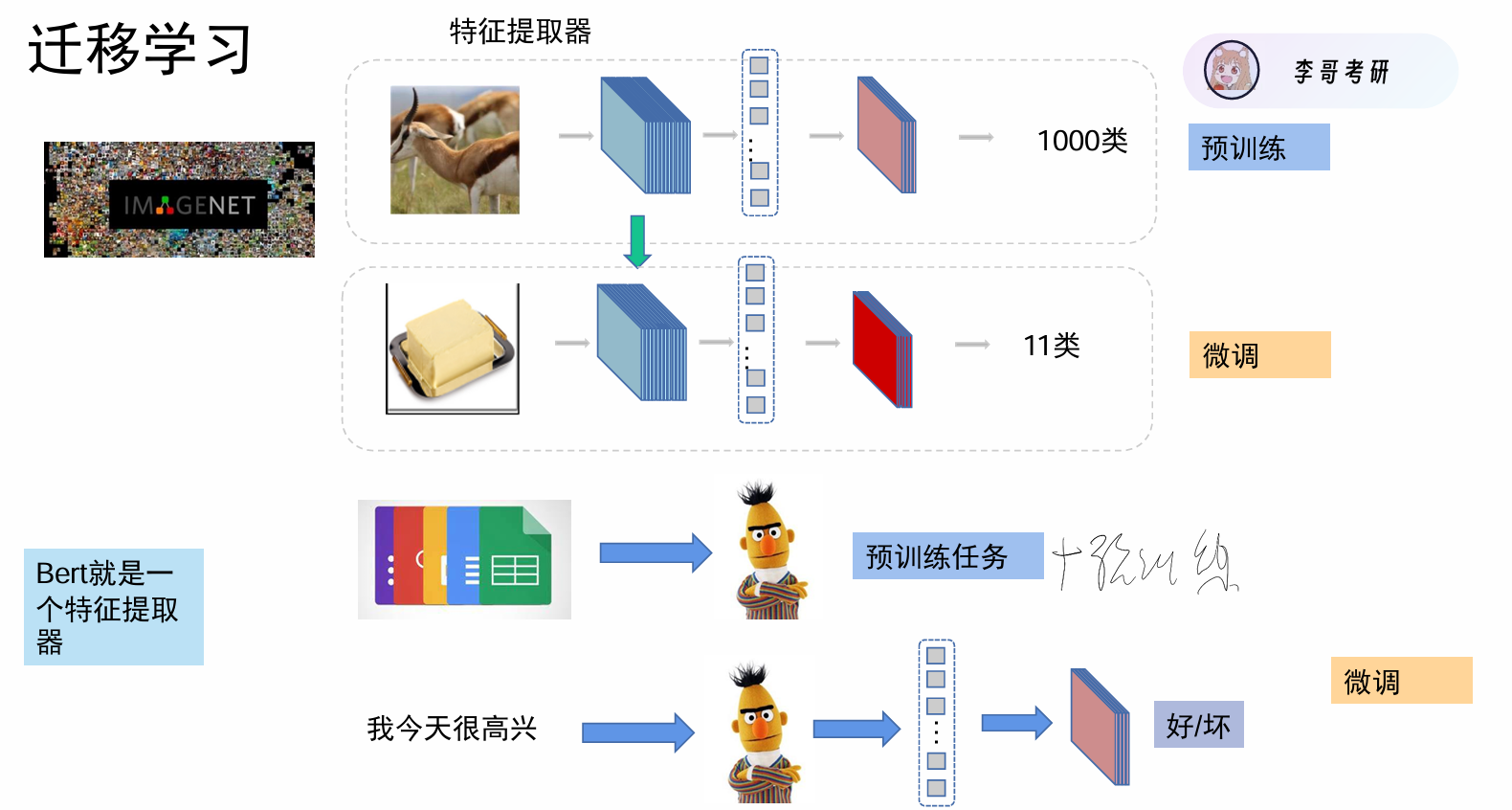
上游在大数据集上进行预训练,训练出好的特征提取器,下游进行微调.在大规模文本上进行无监督预训练,完成后迁移到下游进行任务

判断句子是否相连
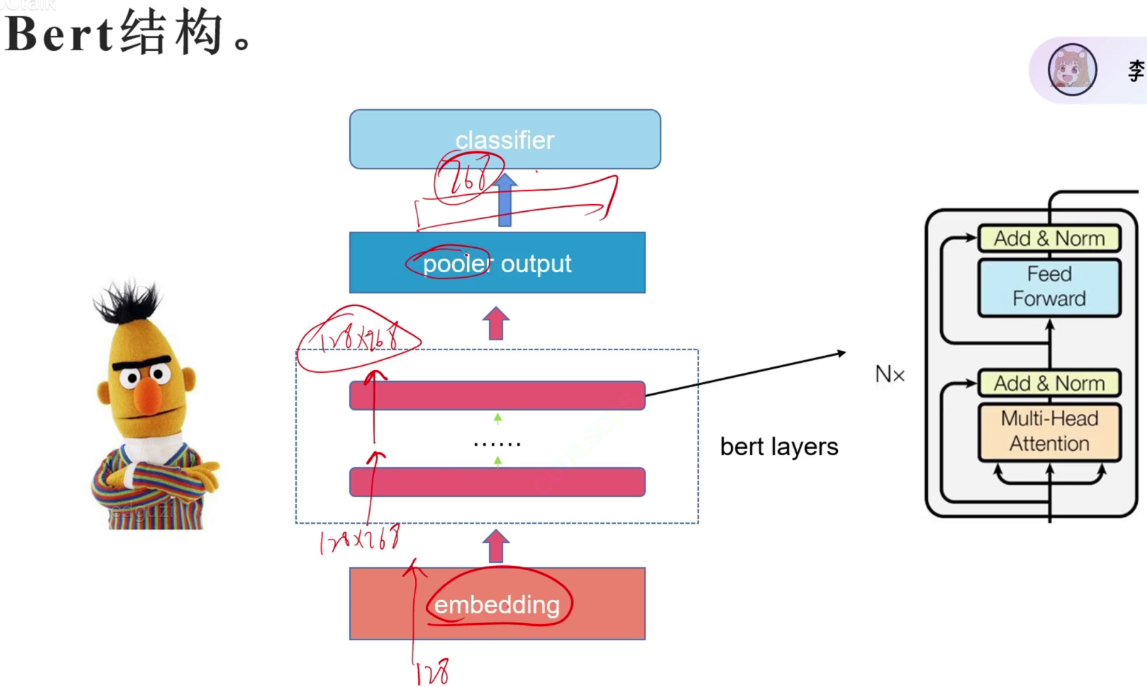
BERT结构
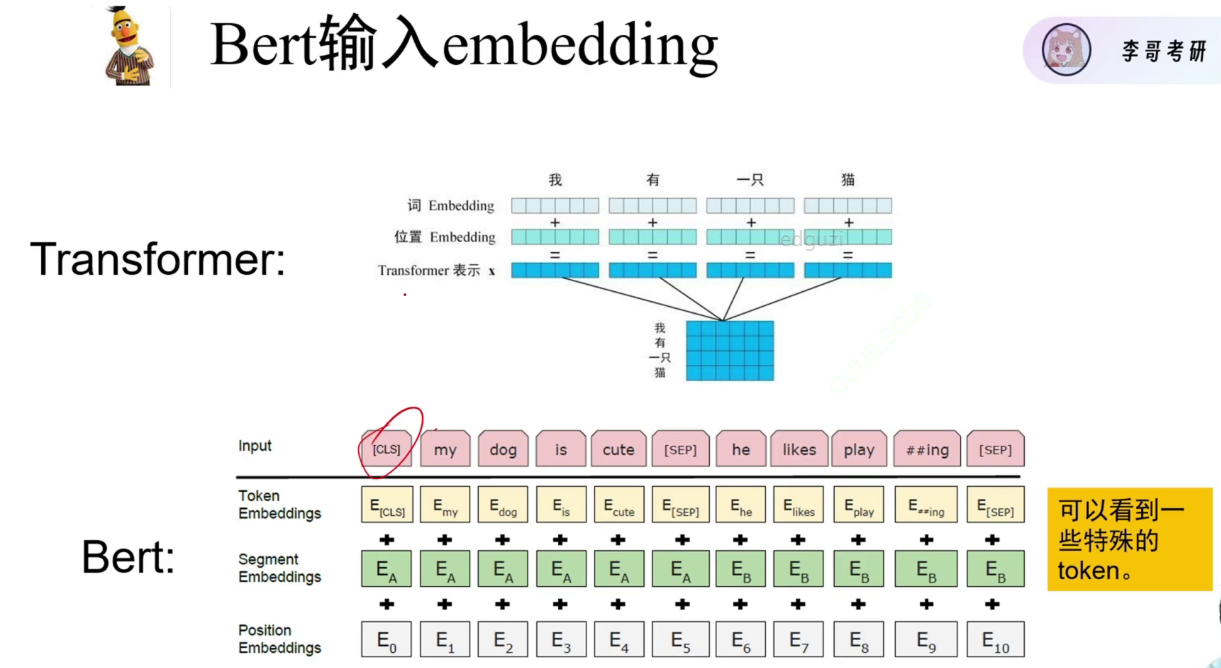
classification,sep表示逗号或句号 sentence embedding句子编码
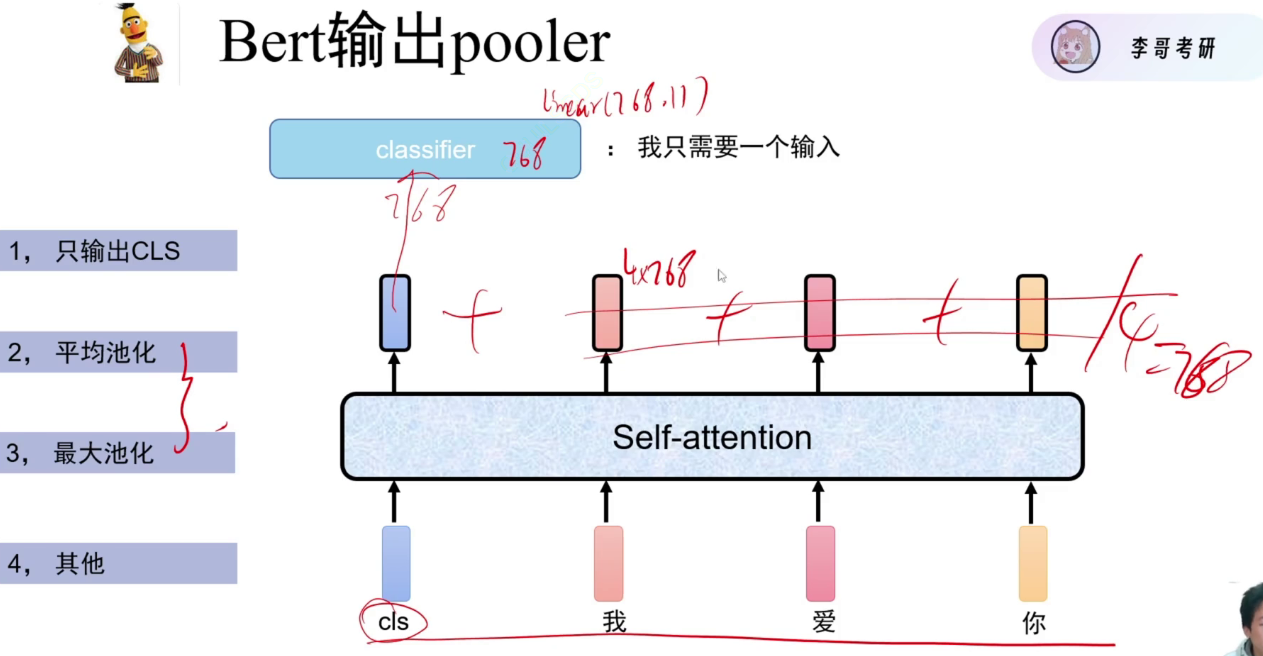
第一种最常用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号