
0.PTA得分截图

1.本周学习总结(0-5分)
1.1 查找的性能指标
ASL(Average Search Length),即平均查找长度,在查找运算中,由于所费时间在关键字的比较上,所以把平均需要和待查找值比较的关键字次数称为平均查找长度。
它的定义是这样的:
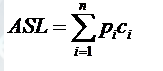
其中n为查找表中元素个数,Pi为查找第i个元素的概率,通常假设每个元素查找概率相同,Pi=1/n,Ci是找到第i个元素的比较次数。
在查找的过程中,经过几次的比较就是移动的次数。
ASL成功即是每个元素比较找到的次数的总和/总的元素个数
ASL失败即是找到结尾的后面没有可能再找到这个数了的比较的次数的总和/总共的需要查找的不成功的方式次数
一个算法的ASL越大,说明时间性能差,反之,时间性能好,这也是显而易见的。
1.2 静态查找
顺序查找
在顺序表中,查找方式为从头到尾,找到待查找元素即查找成功,若到尾部没有找到,说明查找失败。所以说,Ci(第i个元素的比较次数)在于这个元素在查找表中的位置,如第0号元素就需要比较一次,第一号元素比较2次......第n号元素要比较n+1次。所以Ci=i;所以
ASL(成功) = n(n+1) / n = (n+1)/2
从头找到尾,都没有找到,总共有n元素,每个元素都需要比较n次
ASL(不成功) = (n*n) / n = n
二分查找
二分查找算法也叫折半法查找法,要求待查找的列表必须是按关键字大小有序排列的顺序表。
查找过程如下所示:
(1)将表中间位置记录的关键字与查找关键字比较,如果两者相等则表示查找成功;否则利用中间位置记录将表分成前、后两个子表。
(2)如果中间位置记录的关键字大于查找关键字,则进一步查找前一个子表,否则查找后一个子表。
(3)重复以上过程,一直到找到满足条件的记录为止时表明查找成功。
(4)如果最终子表不存在,则表明查找不成功。
int BinSearch(RecType R[], int n, KeyType k)
{
int low = 0, high = n - 1, mid;
while (low <= high)
{
mid = (low + high) / 2;
if (k == R[mid].key)
return mid + 1;
if (k < R[mid].key)
high = mid + 1;
else
low = mid + 1;
}
return 0;
}
ASL成功:
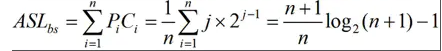
ASL失败:
ASL = (对应的层数*空结点数)/总空结点数
1.3 二叉搜索树
1.3.1 如何构建二叉搜索树(操作)
在二叉搜索树中:
① 若任意结点的左子树不空,则左子树上所有结点的值均不大于它的根结点的值;
② 若任意结点的右子树不空,则右子树上所有结点的值均不小于它的根结点的值;
③ 任意结点的左、右子树也分别为二叉搜索树。
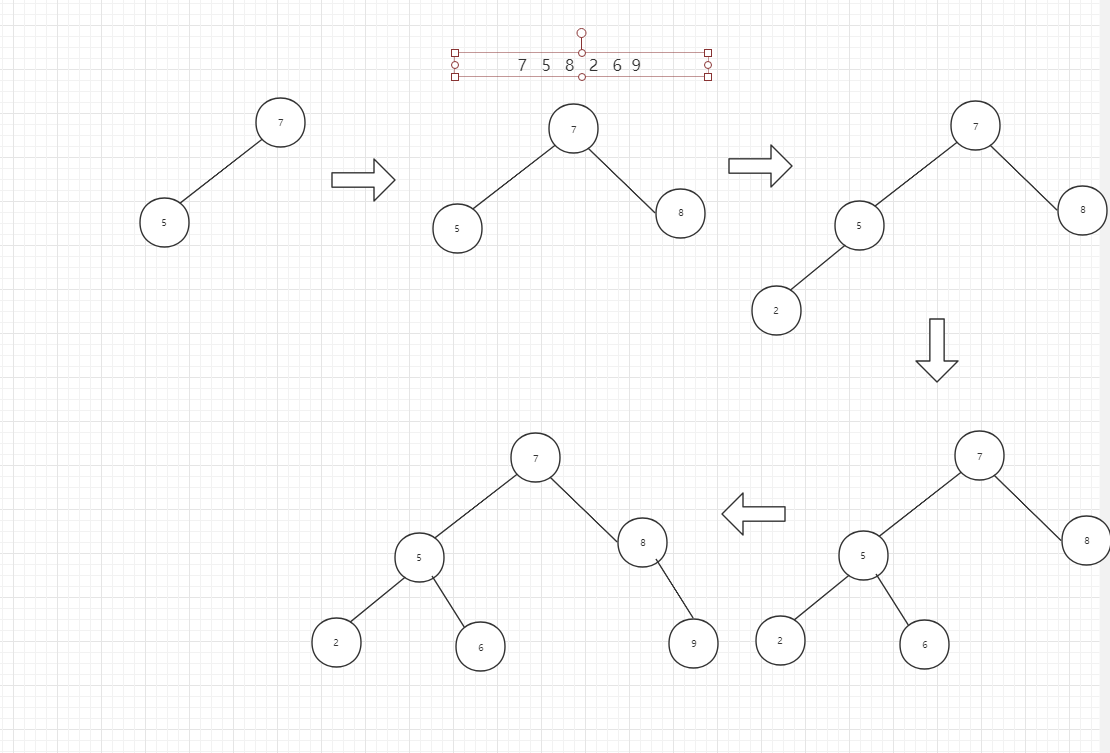
ASL 成功 = (1+22+33)/6 (结点数为6)
ASL不成功 = (21+36)/7 (叶子结点的空节点数为7)
插入是在叶子结点的底层进行插入
插入1:
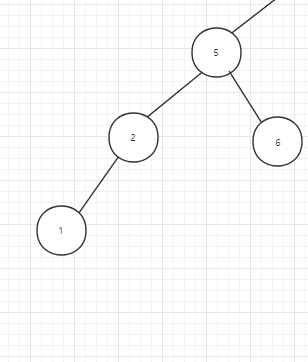
1小于结点7, 5 ,2,所以都会在他们的左子树上,最后来到叶子结点1的空结点,有位置进行插入。
删除则要分成三种删除:
1.叶子结点直接删除
2.只有左子树或者右子树,将其子孩子替换结点的位置
3.既有左子树又有右子树,则找到其左子树最大子结点,或者右子树最小,进行替换
1.3.2 如何构建二叉搜索树(代码)
1.如何构建、插入、删除及代码。
构建(插入操作):
Bintree InitTree(int x, SearchTree T) {
int i = 0;
if (T == NULL) {
T = (Bintree)malloc(sizeof(struct TreeNode));
if (T == NULL)
return 0;
else {
T->data = x;
T->right = NULL;//先右节点,在左节点
T->left = NULL;
}
}
else if (x < T->data) {
T->left = InitTree(x, T->left);
}
else if (x > T->data) {
T->right = InitTree(x, T->right);
}
else
printf("%d has inserted\n", x);
return T;
}
正常递归,先查找,后插入,遇到比插入结点大的数,递归左子树,小的,则递归右子树,直至找到空结点,然后进行插入。
删除:
Bintree Delete(int x, SearchTree T) {
Position temp;
if (T == NULL)
return 0;
else if (x < T->data)
T->left = Delete(x, T->left);
else if (x > T->data)
T->right = Delete(x, T->right);
else if (T->left && T->right) {
temp = FindMin(T->right);
T->data = temp->data;
T->right = Delete(T->data, T->right);
}
else {
temp = T;
if (T->left == NULL)
T = T->right;
else if (T->right == NULL)
T = T->left;
free(temp);
}
return T;
}
先查找到,然后进行删除操作,跟以上的删除操作类似,叶子结点直接删除,有左子树或右子树,则将孩子替换他,有左右子树,则将最小结点替换他。
时间复杂度为O(n)
递归操作可以减低算法的复杂度,且较为清晰明了。
1.4 AVL树
AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
所以AVL树可以提高查找的效率。
结合一组数组,介绍AVL树的4种调整做法。
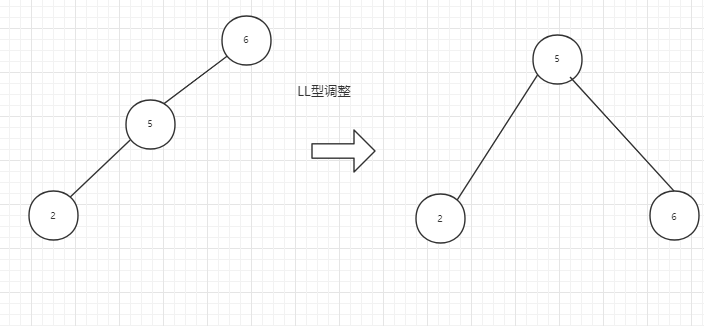
失衡结点的父亲结点替换其父节点,然后父亲结点及其右子树作为新的右子树
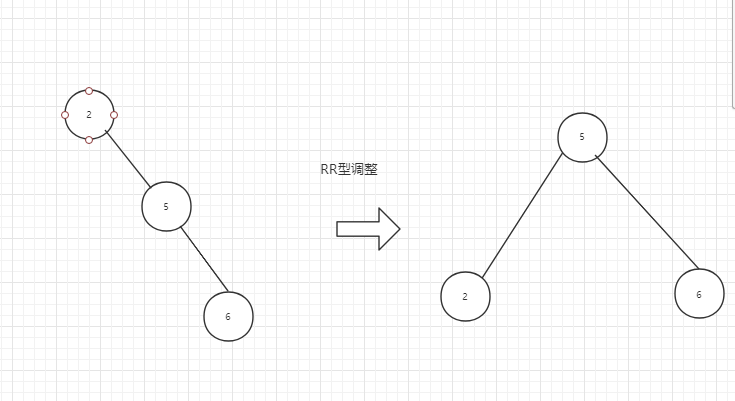
失衡结点的子节点替换他,且作为其左子树
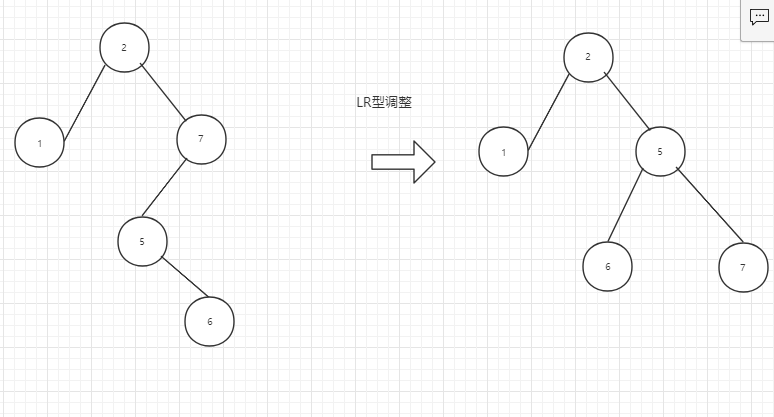
失衡结点的左孩子的右子树的结点上移作为根节点,左子树为其左孩子,结点跟其右子树为新的右子树
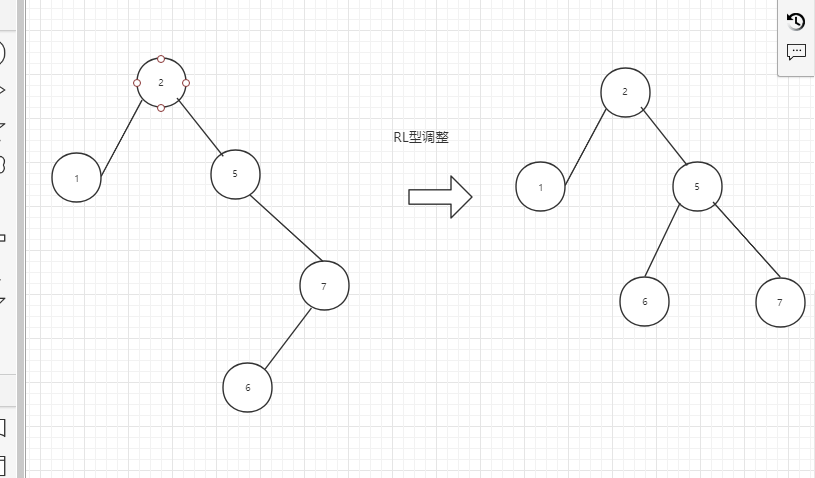
失衡结点的右孩子的左子树结点上移作为根节点,左子树为其左孩子,结点跟其右子树为新的右子树
h = log2(n)+1 (向上取整)
介绍基于AVL树结构实现的STL容器map的特点、用法。
map是STL的一个关联容器,它提供一对一的hash。
第一个可以称为关键字(key),每个关键字只能在map中出现一次;
第二个可能称为该关键字的值(value);
定义map对象:
map<int, string> m;
插入:
第一种 用insert函數插入pair
m.insert(pair<int, string>(000, "student_zero"))
第二种 用insert函数插入value_type数据
m.insert(map<int, string>::value_type(001, "student_one"));
第三种 用"array"方式插入
m[123] = "student_first";
m[456] = "student_second";
查找:
当所查找的关键key出现时,它返回数据所在对象的位置,如果沒有,返回iter与end函数的值相同。
// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = m.find("123");
if(iter != m.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
1.5 B-树和B+树
B-树和AVL树区别,其要解决什么问题?
对于一棵m阶B-tree,每个结点至多可以拥有m个子结点。各结点的关键字和可以拥有的子结点数都有限制,规定m阶B-tree中,根结点至少有2个子结点,除非根结点为叶子节点,相应的,根结点中关键字的个数为1m-1;非根结点至少有[m/2]([],向上取整)个子结点,相应的,关键字个数为[m/2]-1m-1。
B-树定义。结合数据介绍B-树的插入、删除的操作,尤其是节点的合并、分裂的情况
对比于AVL树的一个结点仅能存放一个数据,当数据量十分大的时候,树的高度就会特别高,查找效率就会变的不理想,而B-树能降低树的高度,提高查找效率
插入:
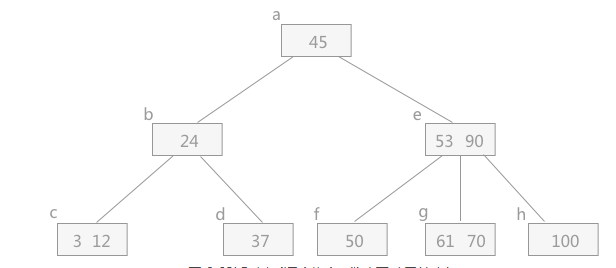
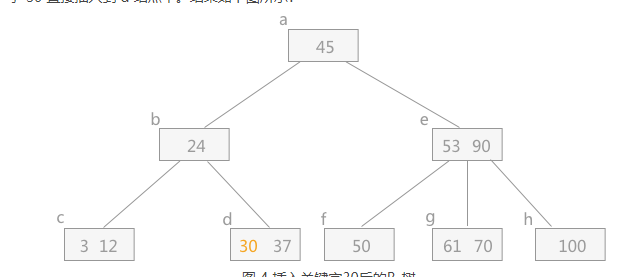
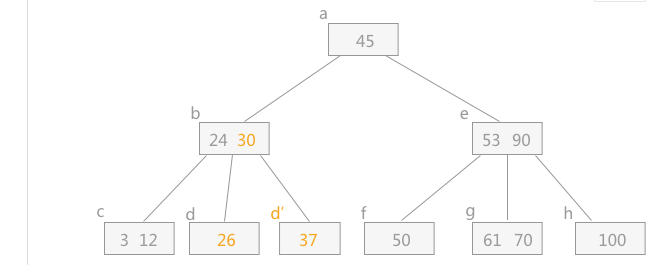
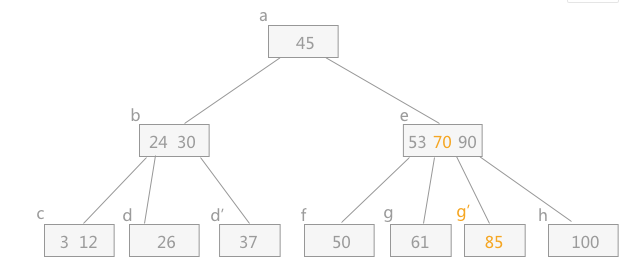
则当一个结点的结点数大于最多的个数时,需要将中间数往上提,作为其父亲结点,然后左右分别为左右子树
删除:
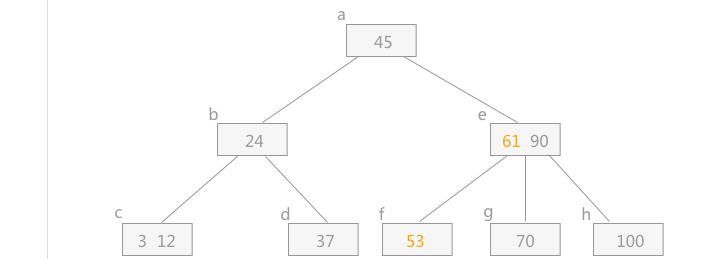
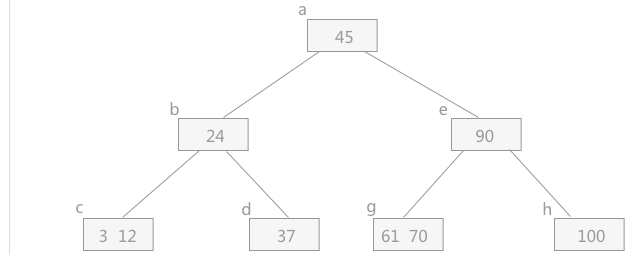
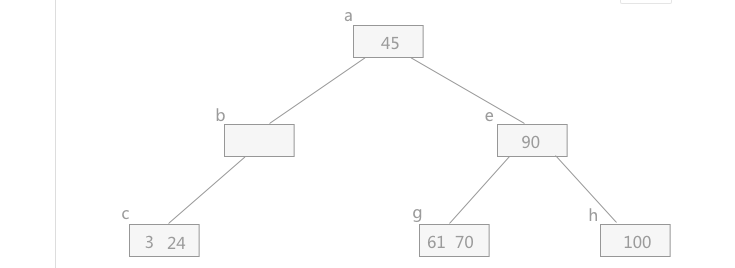
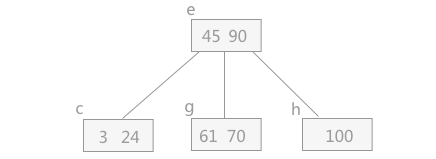
当删除元素,使结点数小于最小的元素个数时,需要进行合并操作,即将左子树上移替换,然后将右节点上移合并。这种合并方式即借孩子,将孩子借为父亲结点,然后扩大左右孩子的分支。
B+树:
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
用途:
B+ 树通常用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
1.6 散列查找。
哈希表的设计主要涉及哪几个内容?
哈希表(hash map)是一种实现关联数组抽象数据类型的数据结构,这种结构可以将关键码映射到给定值。哈希表使用哈希函数计算桶单元或槽位数组中的索引,从中可以找到所需的给定值。
构造的方法有直接定址法,除留余数法。
理想情况下,哈希函数会将每个关键码分配给一个唯一的存储桶单元,但是大多数哈希表设计都使用不完美的哈希函数,这可能会导致哈希冲突,也就是哈希函数会为多个关键码生成相同的索引。这种冲突必须以某种方式解决。
使用除留余数法:
-
开放地址法:
先将num%mod
然后如果该位置是空的,直接插入,如果不是,则产生了哈希冲突,使用用线性探查法,往后找到空位置进行插入

-
链地址法:

ASL成功= 直接能够查找到的个数查找次数 /总需要查找的个数
= (18+26+33+41)/18
ASL不成功= 查找到为空的次数/查找表的长度
= (12+23+32+4*1)/16
2.PTA题目介绍(0--5分)
介绍3题PTA题目
2.1 是否完全二叉搜索树(2分)
本题务必结合完全二叉搜索树经过层次遍历后在队列的特点去设计实现。结合图形介绍。
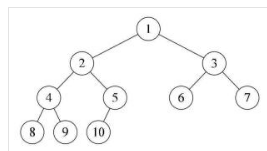
完全二叉树是符合顺序表的二叉链表结构的树,也就是其子结点为2i,2i+1,所有叶子结点均为度为1的结点,或者最后的一个结点的度为1或者0.
根据这种结构,只需进行层次遍历,如果遇到空结点在一个有值的结点前,则说明,该结点并非在最后,则不是完全二叉树。
2.1.1 伪代码(贴代码,本题0分)
先构建树,进行树的插入操作
for 0 to n
输入x
插入x
void InsertBST()
if 插入结点为空
new一个T结点,然后插入
else if 存在该结点
不进行插入
else if 大于该结点
将其递归到左子树
else if 小于该结点
将其递归到右子树
else
返回
int flag = 1;
bool LevelOrderBST(BinTree T)
创建队列q
入队T
while(q不为空)
if 为空结点
这时候说明未到最后一个元素,则不是完全二叉树 flag = 0
else
将其左右孩子入队
2.1.2 提交列表

2.1.3 本题知识点
主要是运用前面的完全二叉树的特性,树的层次遍历以及flag为全局变量的定义。
2.2 航空公司VIP客户查询(2分)
2.2.1 伪代码(贴代码,本题0分)
main()
for 0 to n
输入id及其lenth
将其id后五位数转化成数字,方便用除留余数法插入
调用插入函数
调用查找函数
insert()
除留余数法找出相对应的哈希链
if 这条哈希链为空
进行插入操作,插入id,及其里程,里程小于k,则k为其里程
else
查找是否为相同的id,如果是则进行里程累加,不是则在后面插入新的结点。
search()
除留余数法找出需要在哪条链进行查找
再将这条链遍历,进行查找,输出相应的信息
2.2.2 提交列表

2.2.3 本题知识点
2.3 基于词频的文件相似度(1分)
2.3.1 伪代码(贴代码,本题0分)
伪代码为思路总结,不是简单翻译代码。
创建map容器
int link[][]//容纳文件数据
for 0 to n//文件个数
while(输入#)
字母转化为小写
if 字母数小于10
link[i][num] = c//存入数据
if 遇到空格
if 字母个数大于3
单词存入map容器
for map容器[]的开始 到 末尾
for 0 to i
比较j跟i相同单词的个数,存入二维的比较数组
输入m
进行两两比较计算相似度
2.3.2 提交列表

2.3.3 本题知识点
运用了map容器
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号