

MySql的回顾三:流程控制函数/统计函数/分组查询
路漫漫其修远兮,吾将上下而求索,又到了周末,我继续带各位看官学习回顾Mysql知识。
上次说到了流程控制函数,那就从流程控制函数来继续学习吧!
#五.流程控制函数 #1.if函数:if else的效果 IF(条件表达式,成立返回1,不成立返回2) #与Java三元运算相同
SELECT IF(10>5,'大','小');
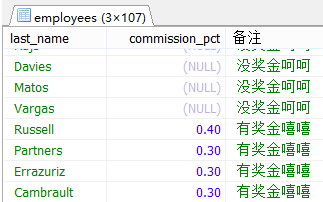
SELECT last_name,commission_pct,IF(commission_pct IS NULL,'没奖金呵呵','有奖金嘻嘻') AS 备注
FROM employees;
#2.CASE函数的使用一: swirch case的效果【等值判断】
回顾:switch(变量或表达式){
case 常量1:语句1;break;
...
default:语句n;break;
}
mysql中
case 要判断的字段或表达式或变量
when 常量1 then 要显示的值1或者语句1;[语句要加分号,值不用加]
when 常量2 then 要显示的值2或者语句2;
...
else要显示的值n或者语句n;[默认值]
end[结尾]
case在SELECT后面相当于表达式用,后面不能放语句,只能是值.
在后续的学习中,存储过程与函数内就可以单独,用不搭配SELECT,就用语句.
先是表达式的操作
案例:查询员工的工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
SELECT salary 原始工资,department_id,
CASE department_id
WHEN 30 THEN salary*1.1
WHEN 40 THEN salary*1.2
WHEN 50 THEN salary*1.3
ELSE salary
END AS 新工资
FROM employees;

#2.CASE函数的使用二:类是于多重IF【区间判断】
回顾Java中:if(条件1){
语句1;
}else if(条件2){
语句2;
}...
else{
语句n;
}
mysql中:
case
when 条件1 then 要显示的值1或者语句[语句后面要加分号;]
when 条件2 then 要显示的值2或者语句[语句后面要加分号;]
...
else 要显示的值n或语句n
end
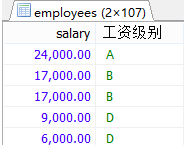
案例:查询员工的工资的情况
如果工资>20000,显示A级别
如果工资>15000,显示B级别
如果工资>10000,显示C级别
否则,显示D级别
SELECT salary,
CASE
WHEN salary>20000 THEN 'A'
WHEN salary>15000 THEN 'B'
WHEN salary>10000 THEN 'C'
ELSE 'D'
END AS '工资级别'
FROM employees;
==============流程函数到此结束,要想熟练运用还需要勤加练习。===============
提供几道习题供读者试试手!
#计算有几种工资。
SELECT COUNT(DISTINCT salary),
COUNT(salary)
FROM employees;

#5.count 函数的详细介绍
SELECT COUNT(salary) FROM employees;

#COUNT(统计所有列)
SELECT COUNT(*) FROM employees;
#把表的行生成一个列每一列都是1。统计1的总数。count里面可以用任意常量值。
SELECT COUNT(1) FROM employees;
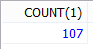
#考虑到效率问题:
#5.5之前都是MYISAM 下COUNT(*)最高,计数器直接返回
#5.5之后默认都是INNODB下COUNT()与COUNT(1)都差不多,
比COUNT(字段)效率高,如果是字段要判断字段是否为NULL。
#6.和分组函数一同查询的字段有限制
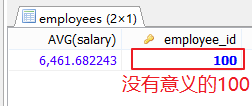
SELECT AVG(salary),employee_id FROM employees;
#1.查询公司员工工资的最大值,最小值,平均值,总和。
SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees;

SELECT MAX(salary) AS 最大值,MIN(salary) AS 最小值,
ROUND(AVG(salary)) AS 最小值,SUM(salary) AS总和
FROM employees;

#2.查询员工表中最大入职时间和最小入职时间的相差天数。
#DATEDIFF计算天数。DATEIFF(参数1-参数2)
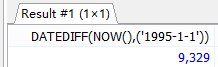
SELECT DATEDIFF(NOW(),('1995-1-1'));
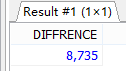
SELECT DATEDIFF(MAX(hiredate),MIN(hiredate)) AS DIFFRENCE
FROM employees;
#3.查询部门编号为90的员工个数。
SELECT COUNT(*) AS个数
FROM employees
WHERE department_id=90;
#进阶5.分组查询GROUP BY子句语法。
可以使用GROUP BY子句将表中的数据分成若干组。
语法:
SELECT 分组函数,列(要求出现在GROUP BY的后面)
FROM 表
【WHERE筛选条件】
GROP BY 分组的列表
【ORDER BY 子句】
注意:
查询列表必须特殊,要求是分组函数和GROUP BY后出现的字段
特点:
1.分组查询中的筛选条件分为两类

2.GROUP BY 子句支持单个字段分组,多个字段分组(多个字段之间用逗号隔开没有顺序要求)
也支持表达式或函数分组(用的较少)
3.也可以添加排序(排序放在整个分组查询的最后)
#引入:查询每个部门的平均工资。
SELECT AVG(salary)
FROM employees;
#引入:查询每个部门的平均工资,保留两位小数。
SELECT ROUND(AVG(salary),2) AS 平均工资
FROM employees;

#简单的分组查询,添加分组前的筛选WHERE
#案例1:查询每个工种的最高工资。
SELECT MAX(salary) AS 最高工资,job_id AS 工种编号
FROM employees
GROUP BY job_id;

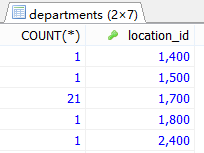
#案例2:查询每个位置上的部门个数。
SELECT COUNT(*) AS 总数,location_id
FROM departments
GROUP BY location_id;
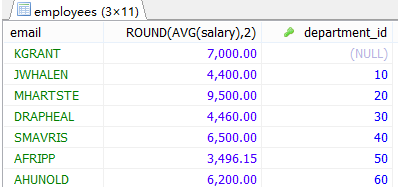
#添加筛选条件
#查询邮箱中包含a字符的,平均工资保留两位小数,每个部门的平均工资
SELECT email,ROUND(AVG(salary),2),department_id
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;
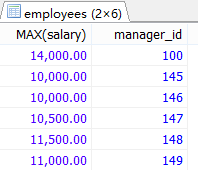
#案例2:查询每个领导手下员工有奖金的的最高工资
SELECT MAX(salary),manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
添加复杂的筛选,添加分组后的筛选HAVING
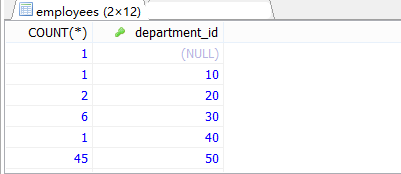
#案例1:查询哪个部门的员工个数>2
#①查询每个部门的员工个数
SELECT COUNT(*),department_id
FROM employees
GROUP BY department_id;
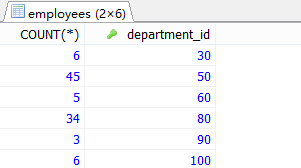
#②根据①的结果,查询哪个部门的员工个数>2
SELECT COUNT(*) AS 总数,department_id AS 部门编号
FROM employees
GROUP BY department_id
HAVING COUNT(*)>2;
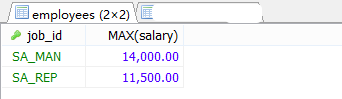
#案例2.查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资。
#①查询每个工种有奖金的员工的最高工资。
#原始表能筛选的就放在FROM 后面用WHERE。
SELECT job_id AS 员工编号,MAX(salary) AS 最高工资
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id;
#②根据①结果继续筛选,最高工资>12000。
SELECT job_id AS 员工编号,MAX(salary) AS 最高工资
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
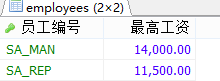
#案例3.查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资。
#①查询领导编号>102的每个领导手下的最低工资
SELECT MIN(salary) AS 最低工资,manager_id AS 领导编号
FROM employees
WHERE manager_id > 102
GROUP BY manager_id;

#②最低工资大于5000的。
SELECT MIN(salary) AS 最低工资,manager_id AS 领导编号
FROM employees
WHERE manager_id > 102
GROUP BY manager_id
HAVING 最低工资 > 5000;
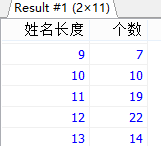
#案例:按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些
#MYSQL内GROUP BY与HAVING后面支持别名,WHERE不支持别名。但ORACLE数据库的GROUP BY与HAVING是不支持别名的。
SELECT LENGTH(CONCAT(last_name,first_name)) AS 姓名长度,
COUNT(*) AS 个数
FROM employees
GROUP BY 姓名长度
HAVING 姓名长度 > 5;
#按多个字段分组
#案例:查询每个部门工种的员工的平均工资(保留两位小数)。
SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种
FROM employees
GROUP BY 部门,工种;

#添加排序
#案例:查询每个部门每个工种的员工的平均工资,并且按平均工资的高低显示。
SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种
FROM employees
GROUP BY 工种,部门
ORDER BY 平均工资 DESC;
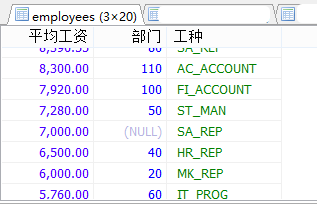
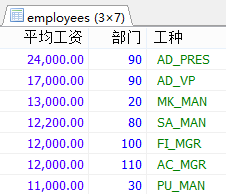
#案例:查询部门不能为空的,每个部门每个工种的员工的平均工资,并且按平均工资的高低显示。
SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种
FROM employees
WHERE department_id IS NOT NULL
GROUP BY 工种,部门
ORDER BY 平均工资 DESC;
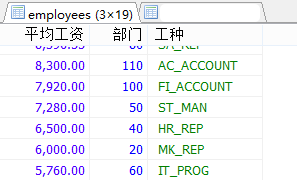
#案例:查询部门不能为空的,每个部门每个工种的员工的平均工资高于10000的,并且按平均工资的高低显示。
SELECT ROUND(AVG(salary),2) AS 平均工资,department_id AS 部门,job_id AS 工种
FROM employees
WHERE department_id IS NOT NULL
GROUP BY 工种,部门
HAVING 平均工资 > 10000
ORDER BY 平均工资 DESC;
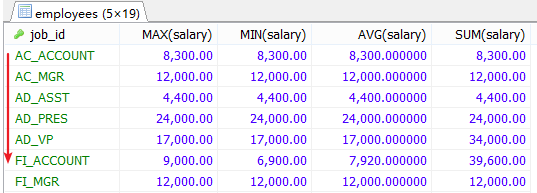
加强练习:
#1.查询各job_id的员工工资的最大值,最小值,平均值,总和,并按job_id升序。
SELECT job_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees
GROUP BY job_id
ORDER BY job_id ASC;
#2.查询员工最高工资和最低工资的差距(DIFFERENCE)。
SELECT MAX(salary) - MIN(salary) AS DIFFERENCE
FROM employees;
=======================================================
SELECT MAX(salary) AS 最高,MIN(salary) AS 最低,MAX(salary)-MIN(salary) AS DIFFERENCE
FROM employees;

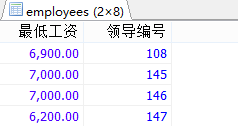
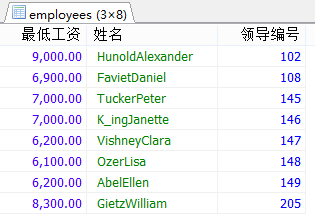
#3.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不能计算在内。
SELECT MIN(salary),CONCAT(last_name,first_name),manager_id
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary)>6000;
到此结束,MySql的统计,分组查询到此结束。如果没有感觉的看官可以自己手动练习一下。
夏天的太阳总是那么亮的刺眼,但多沐浴一下阳光也补钙,想不到吧!o(^▽^)o
宝剑锋从磨砺出,梅花香自苦寒来.
感谢浏览,如有发现问题,还请留言,我会尽快处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号