

脚本编写--从日志中汇总数据
背景:CS提了支持工单,需要导出所有因为JD不符合格式要求而下架或者无法同步的职位。
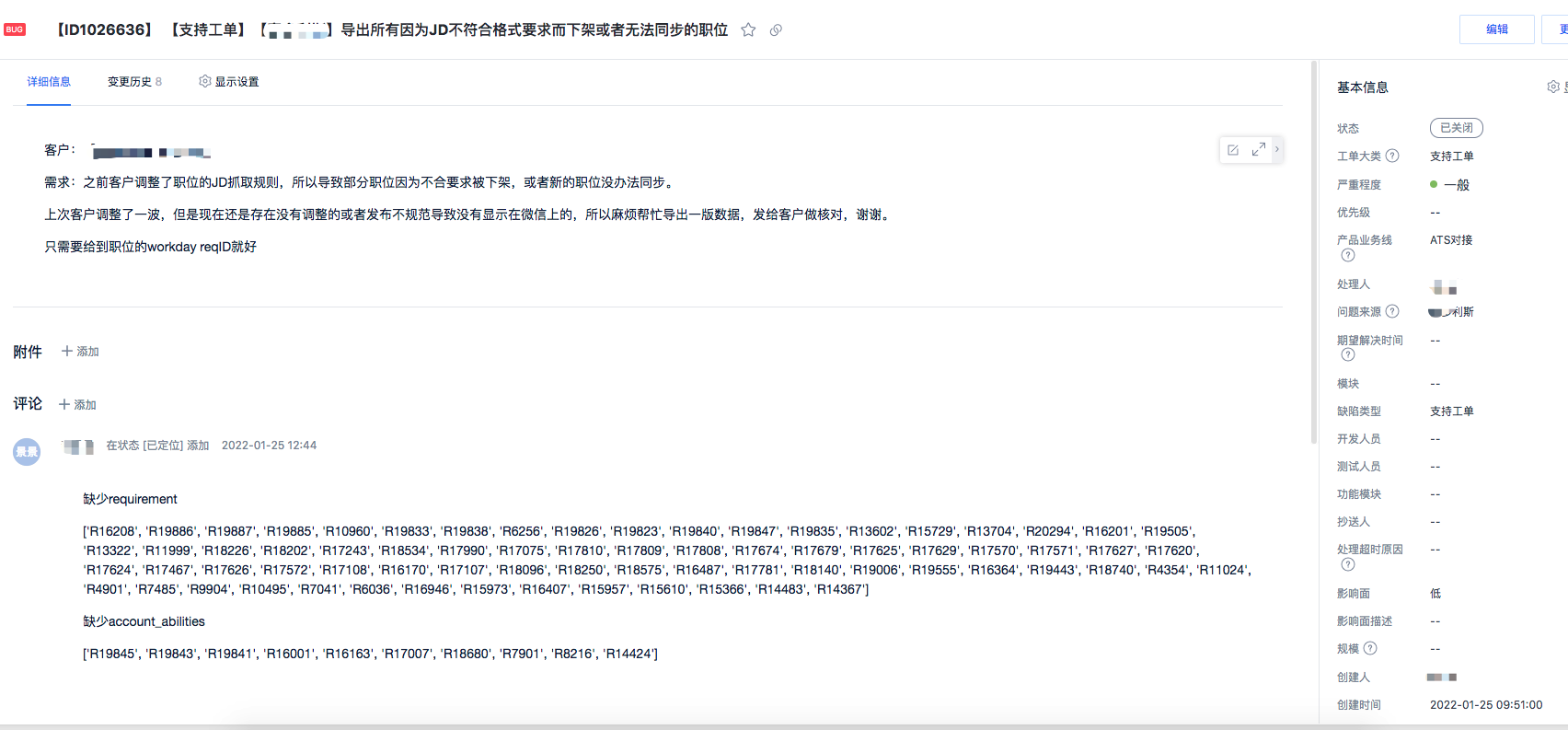
这些信息存在日志中,但是由于不符合规则的职位太多,手动去找太麻烦,所以想办法写脚本把数据导出。
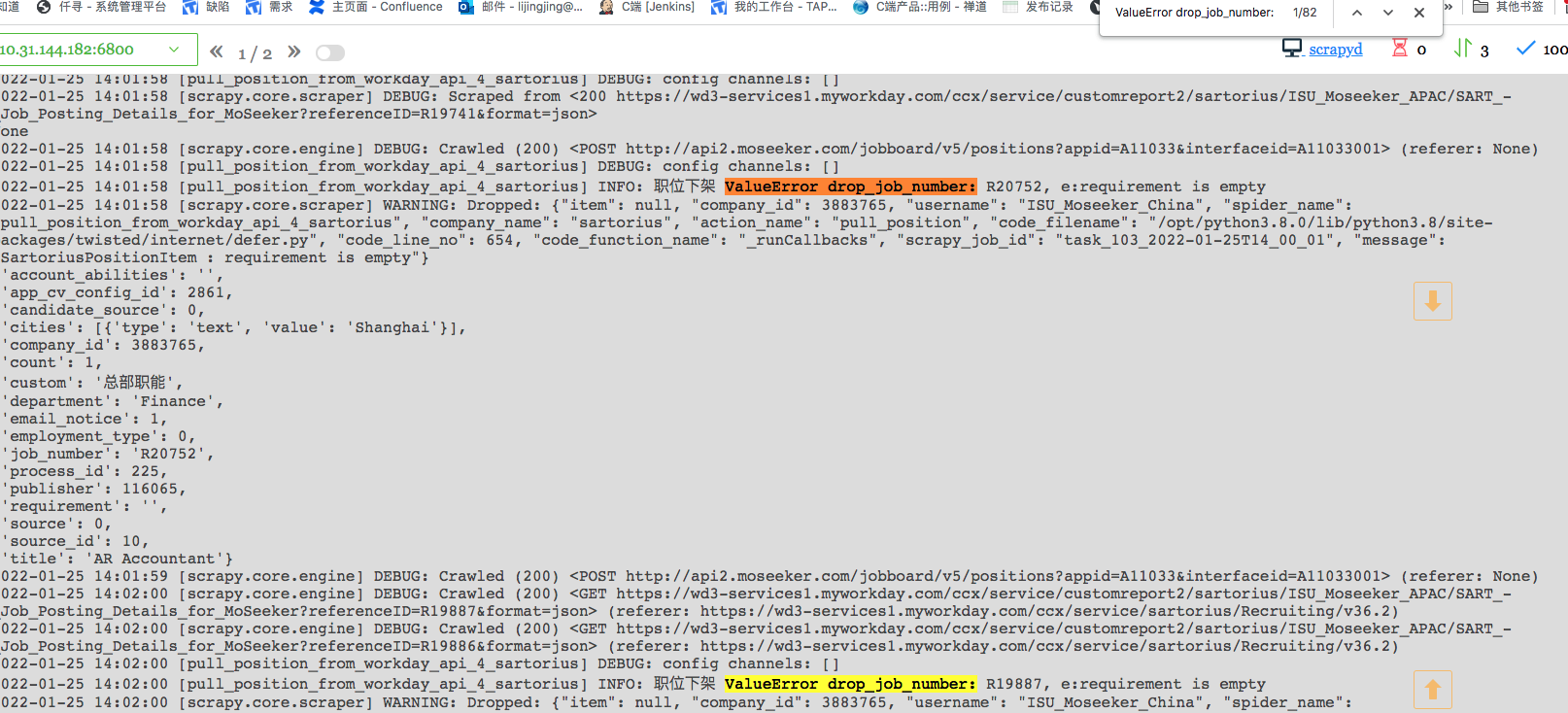
思路:把日志拷贝下来,用正则把职位jobnumber提取出来。
一:把日志文件error_log.txt放在files下
import re
tt=open('files/error_log.txt')
ff=tt.read()
regex = re.findall(r".*?INFO: 职位下架 ValueError drop_job_number: (?P<jobnumber>.*?), e:account_abilities is empty.*?", ff)
ww=open('files/result.txt','w')
ww.write(regex)
ww.close()
Traceback (most recent call last):
File "/Users/cyw/Documents/python_test/learn.py", line 301, in <module>
ww.write(regex)
TypeError: write() argument must be str, not list
要先把regex列表转成字符串 https://www.jb51.net/article/149359.htm
解决方法是使用字符串对象的方法join,其描述如下。大概意思是:s.join(iterable)是将括号内的迭代对象(如列表)使用s字符串作为链接将迭代对象中的元素拼接成一个字符串,返回该字符串。
regex_str=' '.join(regex)
最终代码
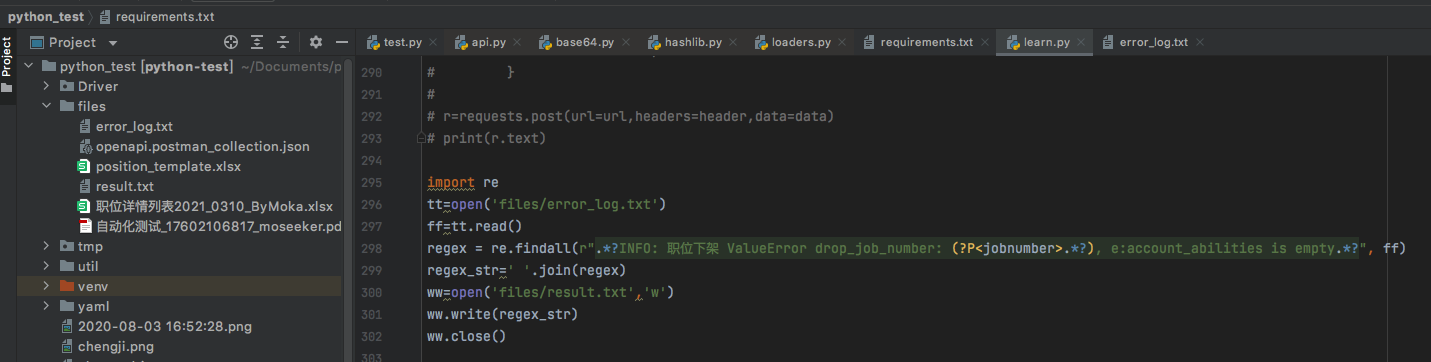
import re
tt=open('files/error_log.txt') #此处用的相对路径,也可以用绝对路径:/Users/cyw/Documents/python_test/files
ff=tt.read()
regex = re.findall(r".*?INFO: 职位下架 ValueError drop_job_number: (?P<jobnumber>.*?), e:account_abilities is empty.*?", ff)
regex_str=' '.join(regex)
ww=open('files/result.txt','w') #本来没有result.txt文件,用w如果该文件不存在,创建新文件。参考:https://www.runoob.com/python/python-files-io.html
ww.write(regex_str)
ww.close()

需要去数据库查看职位信息select * from jobdb.job_position where jobnumber in ("R20814","R20816","R16001","R14424","R8216","R7901")
需要给jobnumber加上双引号和逗号,可以用split
print("R21448 R6036 R7041 R7830 R9904 R7485 R4901 R11024 R4354 R14186 R9114".split())
可以把缺少requirement与account_abilities放一起处理,待优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号