

结对项目之词频统计——增强功能
一:基本信息
1.1本次作业的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
1.2项目git的地址:https://gitee.com/ntucs/PairProg
1.3结队成员:李赟波 1613072025
江文浩 1613072024
二、项目分析
-
程序运行模块(方法、函数)介绍
Task 1. 接口封装 —— 将基本功能封装成(类或独立模块)
import re
class workCount:
def process_file(dst): # 读取文件
lines = len(open(dst, 'r').readlines()) # 借助readlines可以获得文本的行数
with open(dst) as f:
bvffer = f.read()
f.close()
return bvffer
def process_buffer(bvffer):
if bvffer:
for ch in ':,.-_':
bvffer = bvffer.lower().replace(ch, " ")
bvffer = bvffer.strip().split()
word_re = "^[a-z]{4}(\w)*"
# 正则匹配至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写
words = []
for i in range(len(bvffer)):
word = re.match(word_re, bvffer[i]) # 匹配list中的元素
if word: # 匹配成功,加入words
words.append(word.group())
word_freq = {}
for word in words: # 对words进行统计
word_freq[word] = word_freq.get(word, 0) + 1
return word_freq, len(words)
def output_result(word_freq):
doc=open('result.txt','w')
if word_freq:
print('lines',count,file=doc)
print('words:' + str(word_freq.__len__()),file=doc)
for word in word_freq[:10]:
# print(str(word),':',word_freq[word]
print(word[0],':',word[1],file=doc)
doc.close()
def print_result(dst):
buffer = workCount.process_file(dst)
word_freq, counts_words = workCount.process_buffer(buffer)
print('统计单词数:' + str(counts_words))
print('统计最多的10个单词及其词频')
workCount.output_result(word_freq)
写一个test.py,通过import argparse模块,进行测试
import re
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParse
parser.add_argument('dst')
args = parser.parse_args() # 将变量以标签-值的字典形式存入args
dst = args.file #通过键值对形式取值
re.workCount.print_result(dst)
Task 2. 增加新功能
- 词组统计:能统计文件夹中指定长度的词组的词频
- 自定义输出:能输出用户指定的前n多的单词与其数量
- 封装代码
-
class words: def process_file(dst): # 读文件到缓冲区 global count try: # 打开文件 file=open(dst,'r',encoding='ISO-8859-1') file1= open(dst, 'r', encoding='ISO-8859-1') except IOError as s: print('IOError',s) return None try: # 读文件到缓冲区 bvffer=file.read() except: print("Read File Error!") return None lines=file1.readlines() print(lines) for line in lines: # line=line.replace('\n',' ') line=line.strip() # print(line) # line.strip('\n') # line.strip('\t') # if len(line)!=0: count+=1 else: continue file.close() file1.close() return bvffer def parses(): two_phrase_dst = 'venv/src/phrase.txt' three_phrase_dst = 'venv/src/phrase_three.txt' # 正则表达式 two_phrase_re = '[a-z]+\s[a-z]+' # 匹配二个单词的短语 three_phrase_re = '[a-z]+\s[a-z]+\s[a-z]+' # 匹配三个单词的短语 print('二个单词的短语:') phrase_words = create_stop_words(two_phrase_dst) word_freq = process_buffer(txt_dst, phrase_words, two_phrase_re) output_result(word_freq) print('三个单词的短语:')
文章示例

结果图
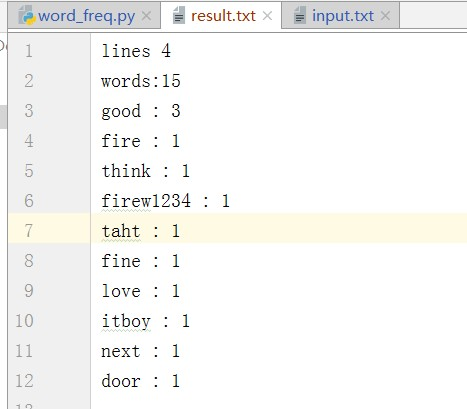
三、性能分析
因为本次代码基本与作业四差别不是很大,而所以本次就没进行过多的创新,直接使用了作业四的代码。所以本次的运行速度还是很快的。
四、PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 15 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 200 | 180 |
| · Analysis | · 需求分析(含学习新技术 | 25 | 20 |
| · Design | · 编写设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 15 | 10 |
| · Coding Standard | · 代码规范 | 3 | 3 |
| · Design | · 具体设计 | 30 | 26 |
| Coding | · 具体编码 | 60 | 56 |
| · code review | · 代码复审 | 20 | 19 |
| · test | 测试 | 25 | 20 |
| Reporting | 报告 | 40 | 30 |
| · Test report | 测试报告 | 20 | 15 |
| · Size measurement | · 计算工作量 | 10 | 10 |
| · Postmortem | · 事后总结 | 10 | 10 |
| 合计 | 350 | 280 |
五、事后分析与总结
1、 简述结对编程时,针对某个问题的讨论决策过程
在如何加入多元词组的词频统计中出现了问题,后使用了正则表达式解决了这一问题
2、评价
(1)江文浩对李赟波的评价:李赟波同学个人能力非常优秀,能够灵活运用已经学习的各门专业知识,在代码编写与调试方面也非常熟练。期待与他下一次的合作。
(2)李赟波对江文浩的评价:虽然编程能力方面不足但积极查阅资料,为项目做出贡献。
3、关于结对过程的建议
结对编程能够增强我们的合作能力,能够及时发现一些问题,而不是自己一个人困在一个问题里面出不来,合作更有利于发现问题和解决问题,还能够提供不同的思路和解决方法,合作是开发项目的非常重要的一个环节。
4、结对编程照片

5、其它:
希望下次还能有一起合作完成别的语言项目的机会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号