Kafka 集群/高性能讲解
一、ZooKeeper 集群搭建
ZooKeeper 节点端口:2181/2182/2183
cp -r 复制zk节点
修改配置zoo.cfg
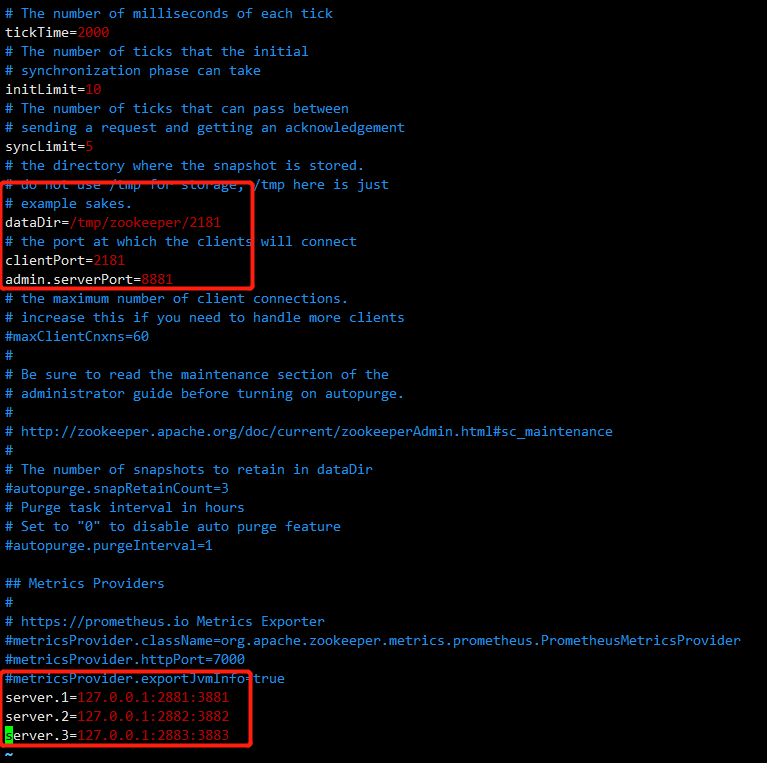
#客户端端口,三台分别为2181、2182、2183
clientPort=2181
#数据存储路径,三台分别为/tmp/zookeeper/2181,/tmp/zookeeper/2182,/tmp/zookeeper/2183
dataDir=/tmp/zookeeper/2181
#修改AdminServer的端口,三台分别为8881、8882、8883
admin.serverPort=8881
dataDir对应目录下分别创建myid文件,内容对应1、2、3
cd /tmp/zookeeper/2181 echo 1 > myid
配置集群
# server.服务器id=服务器IP地址:服务器直接通信端口:服务器之间选举投票端口 server.1=127.0.0.1:2881:3881 server.2=127.0.0.1:2882:3882 server.3=127.0.0.1:2883:3883
启动命令:进入bin目录
#启动zk ./zkServer.sh start #查看节点状态 ./zkServer.sh status #停止节点 ./zkServer.sh stop
二、Kafka 集群搭建
Kafka 节点端口:9092/9093/9094
cp -r 复制 Kafka 节点
修改配置server.properties
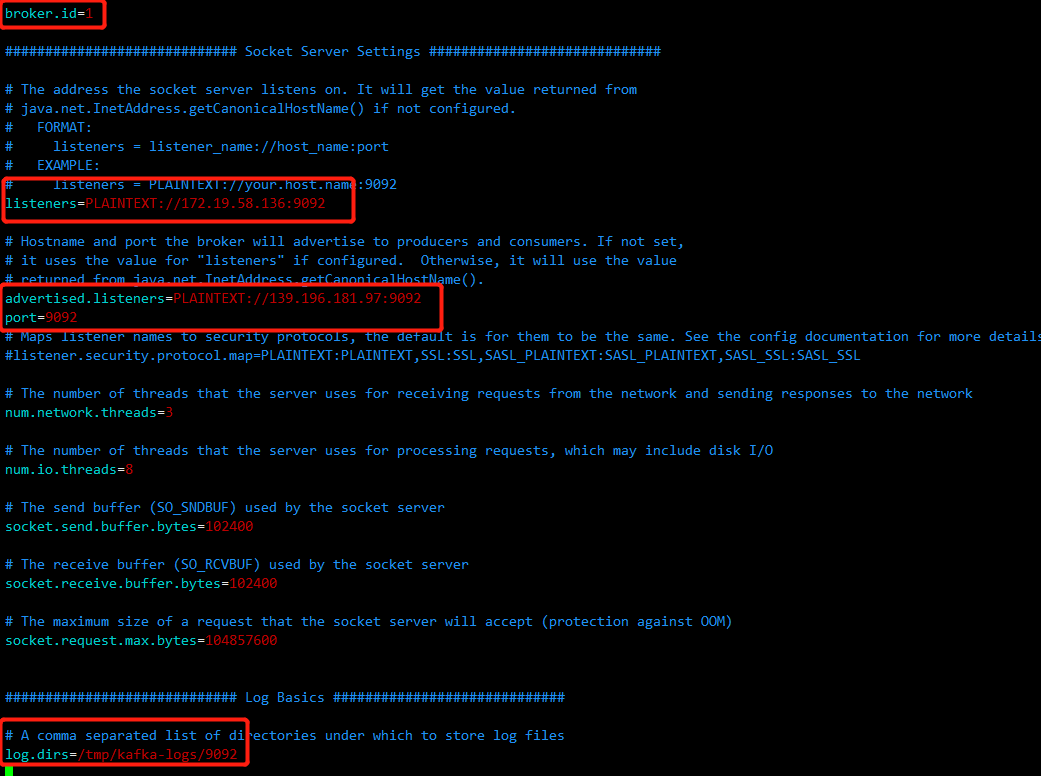
#内网中使用,内网部署 kafka 集群只需要用到 listeners,内外网需要作区分时 才需要用到advertised.listeners listeners=PLAINTEXT://172.18.123.229:9092 advertised.listeners=PLAINTEXT://112.74.55.160:9092 #每个节点编号1、2、3 broker.id=1 #端口 port=9092 #配置3个 log.dirs=/tmp/kafka-logs/9092 #zk地址 zookeeper.connect=localhost:2181,localhost:2182,localhost:2183

三、Kafka日志数据清理
Kafka 将数据持久化到了硬盘上,为了控制磁盘容量,需要对过去的消息进行清理
问题:如果让你去设计这个日志删除策略,你会怎么设计?【原理思想】很重要的体现,下面是 kafka 答案
- 内部有个定时任务检测删除日志,默认是5分钟 log.retention.check.interval.ms
- 支持配置策略对数据清理
- 根据segment单位进行定期清理
启用cleaner
- log.cleaner.enable=true
- log.cleaner.threads = 2 (清理线程数配置)
日志删除
- log.cleanup.policy=delete
#清理超过指定时间的消息,默认是168小时,7天, #还有log.retention.ms, log.retention.minutes, log.retention.hours,优先级高到低 log.retention.hours=168 #超过指定大小后,删除旧的消息,下面是1G的字节数,-1就是没限制 log.retention.bytes=1073741824 还有基于日志起始位移(log start offset),未来社区还有更多
- 基于【时间删除】 日志说明
配置了7天后删除,那7天如何确定呢?
每个日志段文件都维护一个最大时间戳字段,每次日志段写入新的消息时,都会更新该字段
一个日志段segment写满了被切分之后,就不再接收任何新的消息,最大时间戳字段的值也将保持不变
kafka通过将当前时间与该最大时间戳字段进行比较,从而来判定是否过期
- 基于【大小超过阈值】 删除日志 说明
假设日志段大小是500MB,当前分区共有4个日志段文件,大小分别是500MB,500MB,500MB和10MB 10MB那个文件就是active日志段。 此时该分区总的日志大小是3*500MB+10MB=1500MB+10MB 如果阈值设置为1500MB,那么超出阈值的部分就是10MB,小于日志段大小500MB,故Kafka不会执行任何删除操作,即使总大小已经超过了阈值; 如果阈值设置为1000MB,那么超过阈值的部分就是500MB+10MB > 500MB,此时Kafka会删除最老的那个日志段文件 注意:超过阈值的部分必须要大于一个日志段的大小
注意:log.retention.bytes 和 log.retention.minutes 任意一个达到要求,都会执行删除
日志压缩
- log.cleanup.policy=compact 启用压缩策略
- 按照消息 key 进行整理,有相同 key 不同 value 值,只保留最后一个
四、Kafka 零拷贝 ZeroCopy
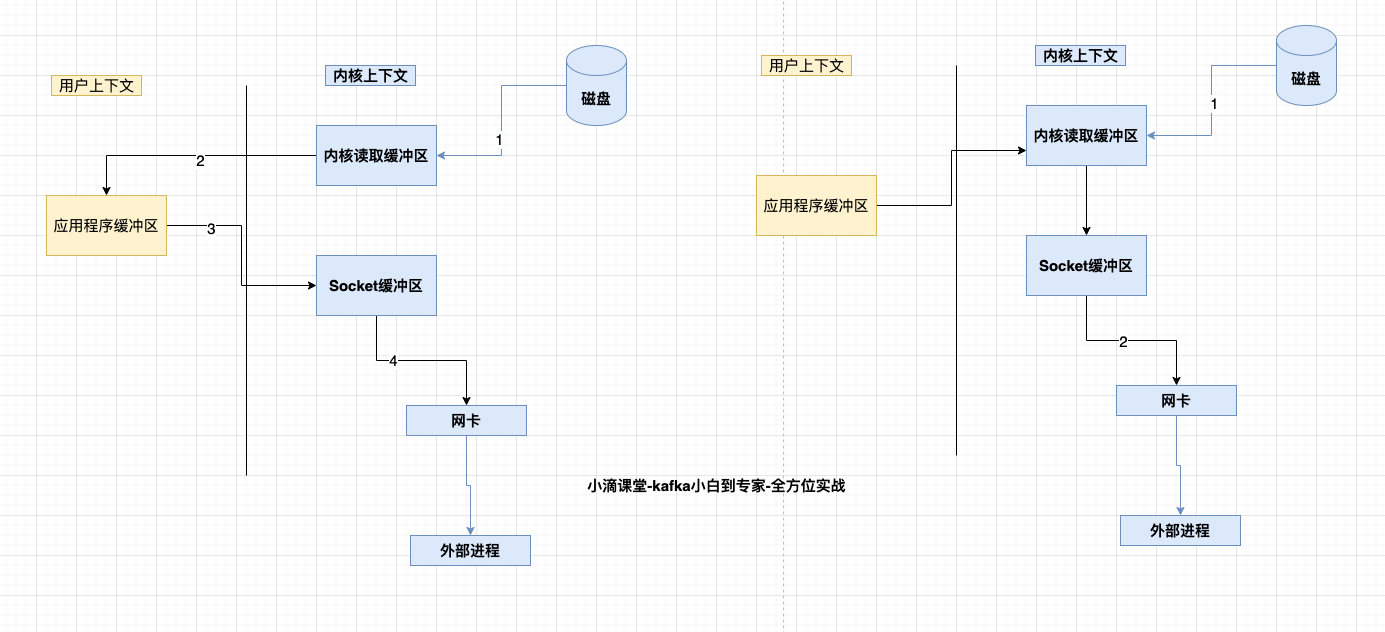
例子:将一个 File 读取并发送出去(Linux 有两个上下文:内核态、用户态)
-
File 文件的经历了4次copy
- 调用 read,将文件拷贝到了 kernel 内核态
- CPU 控制 kernel 态的数据 copy 到用户态
- 调用 write 时,user 态下的内容会 copy 到内核态的 socket 的 buffer 中
- 最后将内核态 socket buffer 的数据 copy 到网卡设备中传送
-
缺点:增加了上下文切换、浪费了2次无效拷贝(即步骤2和3)
ZeroCopy
- 请求 kernel 直接把 disk 的 data 传输给 socket,而不是通过应用程序传输。Zero copy 大大提高了应用程序的性能,减少不必要的内核缓冲区跟用户缓冲区间的拷贝,从而减少 CPU的开销和减少了 kernel 和 user 模式的上下文切换,达到性能的提升
- 对应零拷贝技术有 mmap 及 sendfile
-
- mmap:小文件传输快
- sendfile:大文件传输比 mmap 快
- 应用:Kafka、Netty、RocketMQ等都采用了零拷贝技术
五、Kafka 高性能原因总结
-
存储模型,Topic 多分区,每个分区多 segment 段
-
index 索引文件查找,利用分段和稀疏索引
-
磁盘顺序写入
-
异步操作少阻塞 sender 和 main 线程,批量操作(batch)
-
页缓存Page cache,没利用 JVM 内存,因为 JVM 容易 GC 影响性能
-
零拷贝ZeroCopy(SendFile)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号