因为工作需要,准备开发一个网站统计系统(感谢 ztotem,liy 同学大力支持)。
该系统主要功能:统计网站中加了计数器代码的页面每天的PV、UV、IP(精确到小时) ,另外需要分析页面来源网站的一些数据 ……
大概解读一下:
1.统计代码是统一的,所有页面都使用统一的代码,类似 Google Analytics 的那种:
2.用户访问页面,触发统计代码,只是在服务器上记录下一行log文本数据。如下:
2009-12-01 00:00:00,http://www.google.com/,35996674711058921174,121.28.39.163,http://www.baidu.com/s?wd=google,|Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; Maxthon),8|1024x768
每个页面的每个用户的每次访问都只是记录一行log文本数据,文本数据
因为工作需要,准备开发一个网站统计系统(感谢 ztotem,liy 同学大力支持)。
该系统主要功能:统计网站中加了计数器代码的页面每天的PV、UV、IP(精确到小时) ,另外需要分析页面来源网站的一些数据 ……
初步设计了架构:
![]()
大概解读一下:
1.统计代码是统一的,所有页面都使用统一的代码,类似 Google Analytics 的那种:
<script src="http://www.google-analytics.com/urchin.js" type="text/javascript"></script>
2.用户访问页面,触发统计代码,只是在服务器上记录下一行log文本数据。如下:
2009-12-01 00:00:00,http://www.google.com/,35996674711058921174,121.28.39.163,http://www.baidu.com/s?wd=google,|Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; Maxthon),8|1024x768
每个页面的每个用户的每次访问都只是记录一行log文本数据,文本数据可以按照小时分文件,按照url的不同分目录,这样将每个文件的大小进行控制。
这一行log数据中包括:
访问页面时间(2009-12-01 00:00:00),
访问页面URL(www.google.com),
唯一用户ID(35996674711058921174,
由统计代码JS文件生成Cookies保存在用户本地),
用户IP地址(121.28.39.163),
来源地址(http://www.baidu.com/s?wd=google),
用户操作系统,浏览器,屏幕等等信息(均由统计代码JS文件获取)……
每个页面的每个用户的每次访问都只是记录一行log文本数据,文本数据可以按照小时分文件,按照url的不同分目录,这样将每个文件的大小进行控制。
![]()
测试发现,因为访问量太大,直接写log文件,服务器IO根本来不及,总是丢失数据, ztotem同学想出了先写缓存,再由缓存排队写log文件的办法。
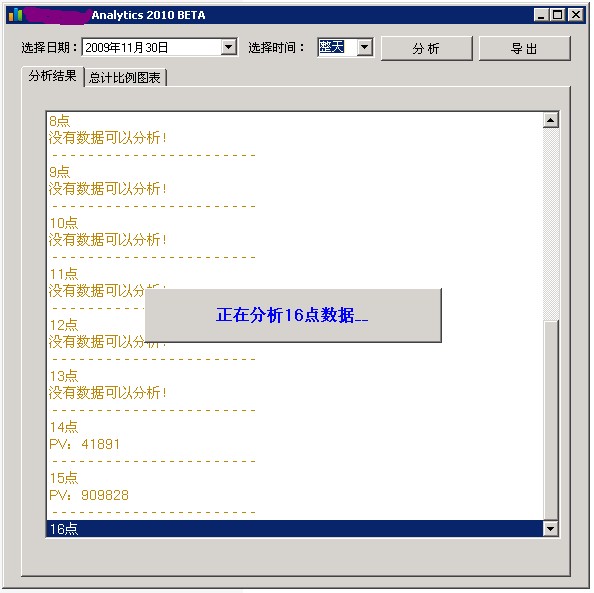
3.另外开发一个后台处理程序,来处理这些log文件。(以下form为示例,实际应该是一直默默运行的services)
![]()
通过该程序的分析,将相关数据保存至数据库中。
数据库的设计如下:
![]()
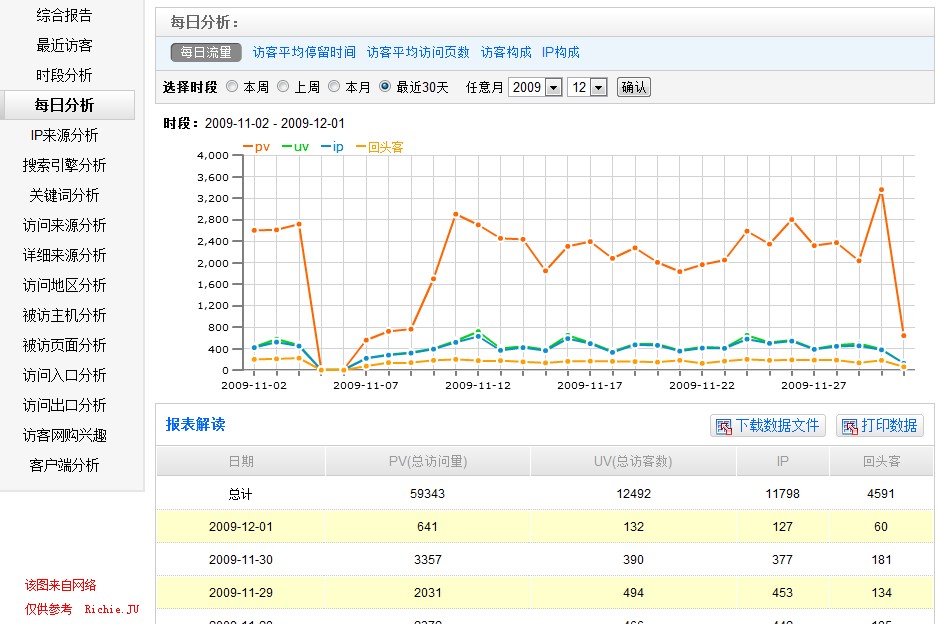
4.管理后台再直接调用数据库里的相关数据形成图表显示:
![]()






 浙公网安备 33010602011771号
浙公网安备 33010602011771号