百度百科爬虫
WebMagic的配置:http://www.cnblogs.com/justcooooode/p/7913365.html
爬取目标
最近需要对一些领域概念做分析,选择利用百度百科爬取对应的词条,从中获取信息和知识。
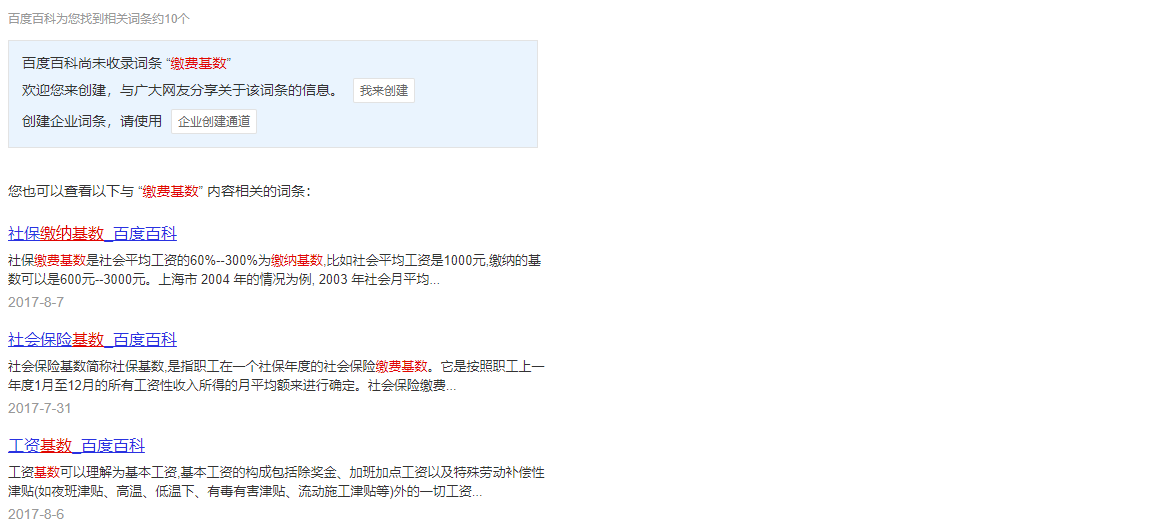
我将查询结果分为两类,一种是百科中已收录,另一种就是未被收录,虽然未被收录但还是能从中获取一些信息。
对于未被收录的词条,会给出与其相关的若干词条,所以这一部分也作为爬取内容。
而对于已收录的词条,我需要的信息是标题、同义词、摘要、Infobox、百度知心内容。

代码
1 /**
2 * @Title: BaiduBaikeSpider.java
3 * @Package: edu.heu.kg.spider
4 * @Description: TODO
5 * @author:LJH
6 * @date:2017年12月1日 上午9:43:16
7 */
8 package edu.heu.kg.spider;
9
10 import java.io.BufferedReader;
11 import java.io.BufferedWriter;
12 import java.io.FileOutputStream;
13 import java.io.FileReader;
14 import java.io.IOException;
15 import java.io.OutputStreamWriter;
16 import java.io.UnsupportedEncodingException;
17 import java.util.LinkedHashMap;
18 import java.util.LinkedList;
19 import java.util.List;
20 import java.util.Map;
21 import java.util.regex.Matcher;
22 import java.util.regex.Pattern;
23
24 import us.codecraft.webmagic.Page;
25 import us.codecraft.webmagic.Site;
26 import us.codecraft.webmagic.Spider;
27 import us.codecraft.webmagic.pipeline.ConsolePipeline;
28 import us.codecraft.webmagic.processor.PageProcessor;
29 import us.codecraft.webmagic.selector.Html;
30 import us.codecraft.webmagic.selector.JsonPathSelector;
31
32 public class BaiduBaikeSpider implements PageProcessor {
33
34 // 抓取配置
35 private Site site = Site.me().setRetryTimes(3).setSleepTime(500).setCharset("UTF-8").setUserAgent(
36 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36");
37 // 检索词
38 private static String word;
39 // 存储路经
40 private static final String PATH = "D:\\百科词条\\百度百科\\";
41
42 @Override
43 public Site getSite() {
44 return site;
45 }
46
47 @Override
48 public void process(Page page) {
49
50 if (page.getUrl().regex("https://baike.baidu.com/item/.*").match()) {
51
52 Html html = page.getHtml();
53
54 if (html.xpath("/html/body/div[3]/div[2]/div/div[2]/dl[1]/dd/h1/text()").match()) {
55
56 // 标题
57 String title = html.xpath("/html/body/div[3]/div[2]/div/div[2]/dl[1]/dd/h1/text()").toString();
58 // 同义词
59 String synonym = html.xpath("/html/body/div[3]/div[2]/div/div[2]/span/span/text()").all().toString();
60 // 摘要
61 String summary = html.xpath("/html/body/div[3]/div[2]/div/div[2]/div[@class='lemma-summary']/allText()")
62 .all().toString().replaceAll(",", "");
63 // 信息框
64 String infobox = html
65 .xpath("/html/body/div[3]/div[2]/div/div[2]/div[@class='basic-info cmn-clearfix']/dl/allText()")
66 .all().toString();
67
68 StringBuilder sb = new StringBuilder();
69 sb.append(word + "\t" + title + "\t" + synonym + "\t" + summary + "\t" + infobox + "\n");
70 try {
71 outPut(PATH + "百科词条.txt", sb.toString());
72 } catch (IOException e) {
73 e.printStackTrace();
74 }
75
76 // 百度知心,由于是动态加载,先获取id
77 String zhixinID = html.xpath("//*[@id=\"zhixinWrap\"]/@data-newlemmaid").toString();
78 String zhixinURL = "https://baike.baidu.com/wikiui/api/zhixinmap?lemmaId=" + zhixinID;
79 // 添加任务
80 page.addTargetRequest(zhixinURL);
81
82 }
83 // 如果不存在词条则获取最相关的词条,添加url到任务
84 else {
85 page.addTargetRequest("https://baike.baidu.com/search/none?word=" + word);
86 }
87 }
88 // 解析百度知心Json
89 else if (page.getUrl().regex("https://baike.baidu.com/wikiui/.*").match()) {
90
91 Map<String, List<String>> resultMap = new LinkedHashMap<>();
92 // 获取相关类型的数量,因为有的词是两个,有些是三个
93 List<String> tempList = new JsonPathSelector("$.[*]").selectList(page.getRawText());
94 int typeNums = tempList.size();
95 int count = typeNums;
96 while (count > 0) {
97 resultMap.put(new JsonPathSelector("$.[" + (typeNums - count) + "].tipTitle").select(page.getRawText()),
98 new JsonPathSelector("$.[" + (typeNums - count) + "].data[*].title")
99 .selectList(page.getRawText()));
100 count--;
101 }
102
103 StringBuilder sb = new StringBuilder();
104 sb.append(word + "\t");
105 resultMap.forEach((key, value) -> {
106 sb.append(key + ":" + value + "\t");
107 });
108 sb.append("\n");
109 try {
110 outPut(PATH + "相关词条_知心.txt", sb.toString());
111 } catch (IOException e) {
112 e.printStackTrace();
113 }
114 }
115 // 百度百科尚未收录词条,获取相关词条
116 else if (page.getUrl().regex("https://baike.baidu.com/search/none\\?word=.*").match()) {
117
118 List<String> list = page.getHtml().xpath("//*[@id=\"body_wrapper\"]/div[1]/dl/dd/a/@href").all();
119 try {
120 list = UrlDecode(list);
121 } catch (UnsupportedEncodingException e) {
122 e.printStackTrace();
123 }
124
125 StringBuilder sb = new StringBuilder();
126 sb.append(word + "\t" + list + "\n");
127 try {
128 outPut(PATH + "相关词条_未收录.txt", sb.toString());
129 } catch (IOException e) {
130 // TODO Auto-generated catch block
131 e.printStackTrace();
132 }
133
134 } else
135 System.out.println("Nothing!");
136
137 }
138
139 // URL解码
140 @SuppressWarnings("unused")
141 private static List<String> UrlDecode(List<String> rawList) throws UnsupportedEncodingException {
142
143 List<String> resultList = new LinkedList<>();
144 String reg = "https://baike.baidu.com/item/(.*)/\\d+";
145 Pattern p = Pattern.compile(reg);
146 Matcher m;
147 for (String str : rawList) {
148 m = p.matcher(str);
149 if (m.find()) {
150 resultList.add(java.net.URLDecoder.decode(m.group(1), "UTF-8"));
151 }
152 }
153 return resultList;
154
155 }
156
157 // 存储
158 private static void outPut(String path, String content) throws IOException {
159
160 FileOutputStream fos = new FileOutputStream(path, true);
161 OutputStreamWriter osw = new OutputStreamWriter(fos);
162 BufferedWriter bw = new BufferedWriter(osw);
163 bw.write(content);
164 bw.close();
165
166 }
167
168 public static void main(String[] args) throws IOException {
169
170 try {
171 BufferedReader br = new BufferedReader(new FileReader("D:\\nba.txt"));
172 while ((word = br.readLine()) != null) {
173 // 创建Spider,addUrl的参数可以为可变参数,但是会有问题
174 Spider.create(new BaiduBaikeSpider()).addPipeline(new ConsolePipeline())
175 .addUrl("https://baike.baidu.com/item/" + word).run();
176 }
177 br.close();
178 } catch (IOException e1) {
179 e1.printStackTrace();
180 }
181
182 }
183
184 }
结果
词条的基本信息:

词条相关信息:

转载请注明原文链接:http://www.cnblogs.com/justcooooode/p/8068045.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号