Modeling Conversation Structure and Temporal Dynamics for Jointly Predicting Rumor Stance and Veracity-ACL19
记录一下,论文建模对话结构和时序动态来联合预测谣言立场和真实性及其代码复现。
1 引言
之前的研究发现,公众对谣言消息的立场是识别流行的谣言的关键信号,这也能表明它们的真实性。因此,对谣言的立场分类被视为谣言真实性预测的重要前置步骤,特别是在推特对话的背景下。
1.1 建模推特对话结构
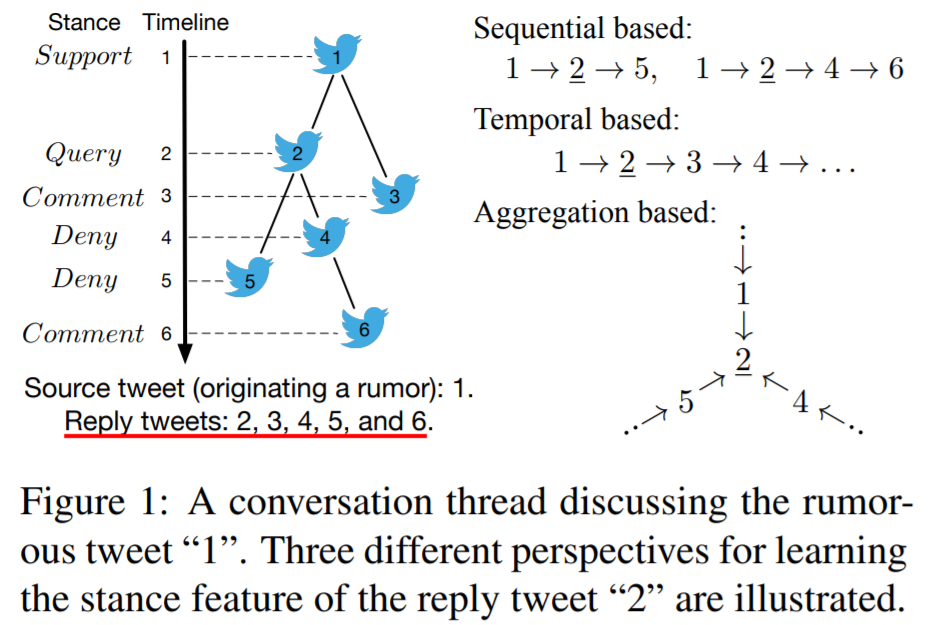
一些先进的谣言立场分类方法试图模拟Twitter对话的序列属性或时序属性。在本文中,我们提出了一个基于结构属性的新视角:通过聚合相邻推文的信息来学习推文表示。
直观地看,一条推文在对话束中的邻居比更远的邻居更有信息,因为它们的对话关系更接近,它们的立场表达有助于中心推文的立场进行分类。例如,在图1中,推文“1”、“4”和“5”是推文“2”的一跳邻居,它们对预测“2”立场的影响较大 两跳邻居“3”)。本文用图卷积网络(GCN)来在潜空间中联合表示推文内容和对话结构,它旨在通过聚合其邻居来学习每条推文的姿态特征的特性。本文基于消息传递的方法来利用对话中的内在结构以学习推文表示。
1.2 编码立场时序动态
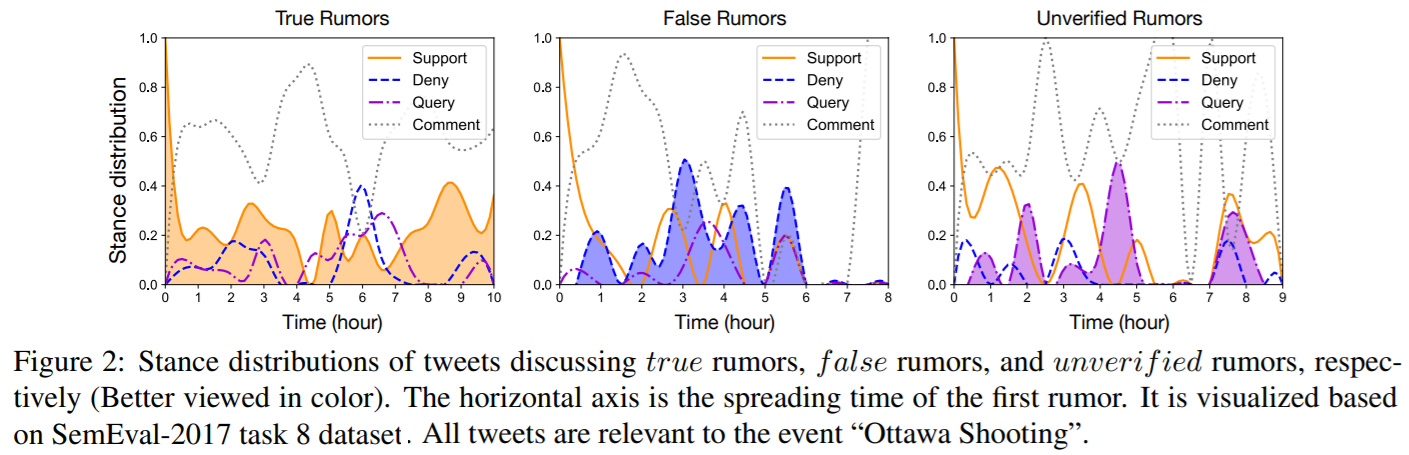
此外,为了确定人们反应的立场,另一个挑战是我们如何利用公众的立场来准确地预测谣言的真实性。本文观察到,公众立场的时序动态可以表明谣言的真实性。图2分别显示了讨论真实谣言、虚假谣言和不真实谣言的推文的立场分布 。
正如我们所看到的,支持的立场主导了传播的开始阶段。然而,随着时间的推移,否认针对虚假谣言的推文的比例显著增加。与此同时,询问针对尚未验证谣言的推文的比例也显示出上升趋势。基于这一观察结果,本文进一步提出用RNN来建模立场演化的时序动态,捕获立场中包含立场特征的关键信号,以进行有效的真实性预测。
1.3 联合立场分类和真实性预测
此外,现有的方法大多分别处理立场分类和真实性预测,这一方式是次优的,它限制了模型的泛化。如前所示,这两个任务是密切相关的,其中立场分类可以提供指示性线索,以促进真实性预测。因此,联合建模这两个任务可以更好地利用它们之间的相互关系(互相帮助)。
1.4 Hierarchical multi-task learning framework for jointly Predicting rumor Stance and Veracity
基于以上考虑,本文提出了一种层次化的多任务学习框架来联合预测谣言的立场和真实性,从而深度集成了谣言的立场分类任务和真实性预测任务。
本文框架的底部组件通过基于聚合的结构建模,对讨论谣言的对话中的推文的立场进行了分类,并设计了一种为会话结构定制的新的图卷积操作。最上面的组件通过利用立场演化的时间动态来预测谣言的真实性,同时考虑到内容特征和由底部组件学习到的立场特征。两个组件被联合训练,以利用两个任务之间的相互关系来学习更强大的特征表示。
2 模型
2.1 问题描述
考虑一个推特对话束$C$,它由一个源推文$t_1$和一些回复推文${ \{ t_2,t_3,\dots,t_{|C|} \}}$直接或间接响应$t_1$,此外每个推文$t_1 (i \in [1,|C|])$表达了它对谣言的立场。对话束C是一个树状结构,其中源tweet $t_1$是根节点,而推文之间的回复关系构成了edges。
本文主要关注两个任务:第一个任务是谣言立场分类,其目的是确定$C$中每条推文的立场,属于$\{supporting, denying, querying, commenting\}$ 第二个任务是预测谣言的真实性,目的是确定谣言的真实性,属于$\{true, f alse, unverif ied\}$。
2.2 Hierarchical-PSV

本文出了一个层次的多任务学习框架来联合预测谣言的立场和真实性(Hierarchical-PSV),图3说明了其整体架构。
其底部的组件是对会话结构中的tweet的立场进行分类(节点分类任务),它通过使用定制的图卷积(Conversational-GCN)对会话结构进行编码来学习立场特征。最重要的部分是预测谣言的真实性,它考虑了从底部的部分学习到的特征,并用一个循环神经网络(Stance-Aware RNN)来建模立场演化的时序动态。
2.3 Conversational-GCN: Aggregation-basedStructure Modeling for Stance Prediction
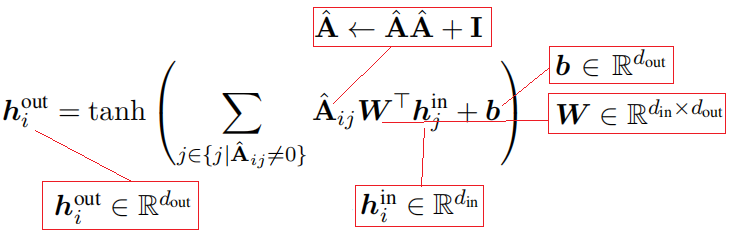
其输入是邻接矩阵$\mathbf{A}$(非0项,代表节点对之间的对话、评论或转发关系)和节点初始特征(基于词嵌入和BiGRU编码得到推文文本表示)。
Conversational-GCN相比GCN的改进就是将其原始的滤波器,即自环归一化领接矩阵变为了二阶领接矩阵且去除归一化操作,来扩大感受野(邻居范围)。
之所以这样做,是因为本文认为:
1)树状的对话结构可能非常深,这意味着在本文的例子中,GCN层的感受野受到了限制。虽然我们可以堆叠多个GCN层来扩展感受野,然而在处理深度的对话结构仍有困难而且会增加参数量。
2)归一化矩阵$\hat {\mathbf{A}}$在一定程度上削弱了其推文的重要性。
Conversational-GCN可以表示为如下的矩阵乘法形式:
![]()
具体来说,第一个GCN层将所有推文的内容特征作为输入,而最后一个GCN层的输出表示对话中所有的推文的立场特征$\hat {\mathbf{s}}$。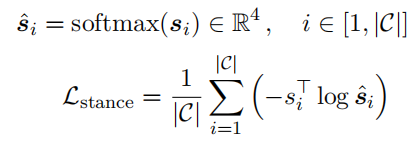
在这里,立场分类即节点分类任务。
2.4 Stance-Aware RNN: Temporal Dynamics Modeling for Veracity Prediction
Stance-Aware RNN试图建模推文立场的时序动态变化,它在每个时间步的输入包括原始推文文本表示$\mathbf{c}$还有推文的立场特征$\mathbf{s}_i$。经过GRU后,其所有时间步隐状态通过最大池化,从而获得捕获了立场演化的全局信息的表示通过$\mathbf{v}$。
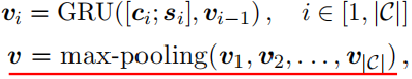
在这里,真实度预测被视为序列分类任务:
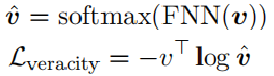
2.5 Jointly Learning Two Tasks
为了利用前一个任务(立场分类)和后续任务(真实性预测)之间的相互关系,本文联合训练了两个组件。具体来说,这两个任务的损失函数相加得到一个最终损失函数L,并被联合优化以学习模型。
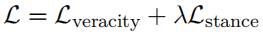
2.6 复现代码
在实现中,由于没有立场监督信号,故没有立场分类这一部分。此外,为了便于实现,在ConversationGCN处使用了常规的GCN。
# -*- coding: utf-8 -*-
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from tqdm import tqdm
class GlobalMaxPool1d(nn.Module):
def __init__( self ):
super (GlobalMaxPool1d, self ).__init__()
def forward( self , x):
return torch.max_pool1d(x, kernel_size = x.shape[ 2 ])
class ConvGCN(nn.Module):
def __init__( self , dim_in, dim_hid, dim_out, dim_stance = 4 , dropout = 0.5 ):
"""
Conversational-GCN
:Params:
T (int): the number of splited timesteps for propagation graph
dim_in (int): 结点的初始输入特征维度 k
dim_hid (int): 默认(固定)的结点嵌入的维度(等于结点池化后的图的嵌入维度)
dim_out (int): 模型最终的输出维度,用于分类
num_layers (int): LGAT的层数(邻居聚集的迭代次数)
dropout (float):
"""
super (ConvGCN, self ).__init__()
self .dropout = dropout
# dim_hid -> embed_size
self .word_embeddings = nn.Parameter(nn.init.xavier_uniform_(
torch.zeros(dim_in, dim_hid, dtype = torch. float , device = device), gain = np.sqrt( 2.0 )), requires_grad = True )
# BiGRU for obtaining post embedding (batch_size = 1)
bigru_num_layers = 1
bigru_num_directions = 2
bigru_hidden = dim_hid / / 2
self .BiGRU = nn.GRU(dim_hid, bigru_hidden, bigru_num_layers, bidirectional = True )
self .H0 = torch.zeros(bigru_num_layers * bigru_num_directions, 1 , bigru_hidden, device = device)
# Graph Convolution
self .conv1 = GCNConv(dim_hid, dim_hid)
self .conv2 = GCNConv(dim_hid, dim_stance)
# GRU for modeling the temporal dynamics
rnn_num_layers = 1 # rnn_hidden = dim_hid
self .GRU = nn.GRU(dim_hid + dim_stance, dim_hid + dim_stance, rnn_num_layers)
self .H1 = torch.zeros(rnn_num_layers, 1 , dim_hid + dim_stance, device = device)
self .MaxPooling = GlobalMaxPool1d()
self .prediction_layer = nn.Linear(dim_hid + dim_stance, dim_out)
nn.init.xavier_normal_( self .prediction_layer.weight)
def forward( self , words_indices, edge_indices):
features = []
edge_indice = edge_indices[ 0 ].to(device) # only one snapshot
words_indices = words_indices.to(device) # get post embedding
for i in range (words_indices.shape[ 0 ]):
word_indice = torch.nonzero(words_indices[i], as_tuple = True )[ 0 ]
# assert word_indice.shape[0] > 0, "words must large or equal to one"
if word_indice.shape[ 0 ] = = 0 :
word_indice = torch.tensor([ 0 ], dtype = torch. long ).to(device)
words = self .word_embeddings.index_select( 0 , word_indice.to(device))
_, hn = self .BiGRU(words.unsqueeze( 1 ), self .H0) # (num_layers * num_directions, batch, hidden_size)
post_embedding = hn.flatten().unsqueeze( 0 )
features.append(post_embedding)
x0 = torch.cat(features, dim = 0 )
content = torch.clone(x0)
x1 = self .conv1(x0, edge_indice)
x1 = F.relu(x1)
x1 = F.dropout(x1, self .dropout)
x2 = self .conv2(x1, edge_indice)
x2 = F.relu(x2)
x = torch.cat((content, x2), 1 )
gru_output, _ = self .GRU(x.unsqueeze( 1 ), self .H1)
z = self .MaxPooling(gru_output.transpose( 0 , 2 ))
return self .prediction_layer(z.squeeze( 1 ).transpose_( 0 , 1 )) # 使用BCE(不需事先计算softmax)
数据加载
def load_rawdata(file_path):
""" json file, like a list of dict """
with open (file_path, encoding = "utf-8" ) as f:
data = json.loads(f.read())
return data
def get_edges(data):
"""依据src_id's data,加载propagation network edges with relative index in a graph"""
tweet_num = len (data)
mids = [tweet[ "mid" ] for tweet in data] # 使用"mid"才能找到所有转发关系
mids_id = {mids[i]: i for i in range (tweet_num)} # mid: id from mid to index,按顺序生成mid的id
mid_edges = [(mid, data[mids_id[mid]][ "parent" ]) for mid in mids if data[mids_id[mid]][ "parent" ] ! = None ]
return [(mids_id[edge[ 0 ]], mids_id[edge[ 1 ]]) for edge in mid_edges]
def get_static_edgeindex(edges):
""" 获取传播图的edge_indices列表,要保证得到的绝对边索引对应结点特征 (for second)"""
graph = nx.Graph() # len(split_edges)= T,和新增的边相关的结点就是Interacting结点
graph.add_edges_from(edges)
edge_index = list (nx.adjacency_matrix(graph).nonzero()) # 结点和边的Id以及安排了,不需再处理
return edge_index
def load_data(ids, T, thres_num, is_dynamic = False ):
"""
依据weibo的id,加载所有的结点特征和传播结构
:params:
weibo_id (string): 微博id
:returns:
graph_list: a list of Diffusion graph objects which contain elements as follows:
1.features: numpy ndarray 结点数N by 特征维度k的结点初始嵌入矩阵
2.edge_indices: list(numpy ndarray) 对话结构的邻接矩阵
"""
graph_list = []
for weibo_id in ids:
txt_data = load_sptext(weibo_id) # 从磁盘上加载以稀疏矩阵存储的text matrix
data = load_rawdata(data_path + "Weibo/{0}.json" . format (weibo_id))
edges = get_edges(data)
edge_indices = get_static_edgeindex(edges)
graph_list.append(DiffGraph(txt_data, edge_indices))
return graph_list # 直接把graph list中的DiffGraph拿来Pickle
class DiffGraph():
def __init__( self , text_data, edge_indices):
self .text_data = text_data
self .edge_indices = [torch.tensor(edges, dtype = torch. long ) for edges in edge_indices]
def get_wordindices( self ):
return torch.from_numpy( self .text_data.toarray())
其余的数据加载和划分、模型初始化以及训练和评估的代码可自行添加。
3 实验
3.1 两个任务的对比实验
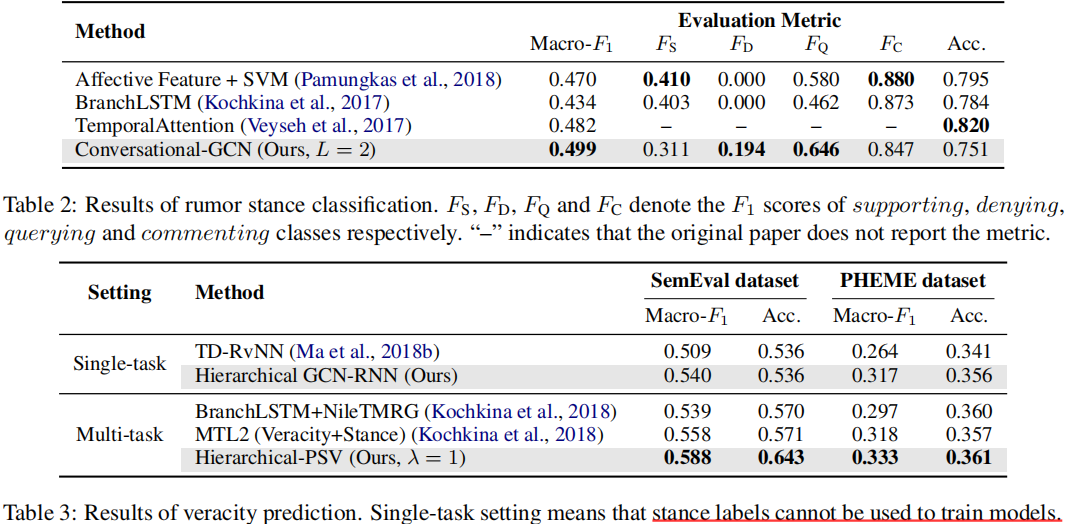
3.2 超参数实验
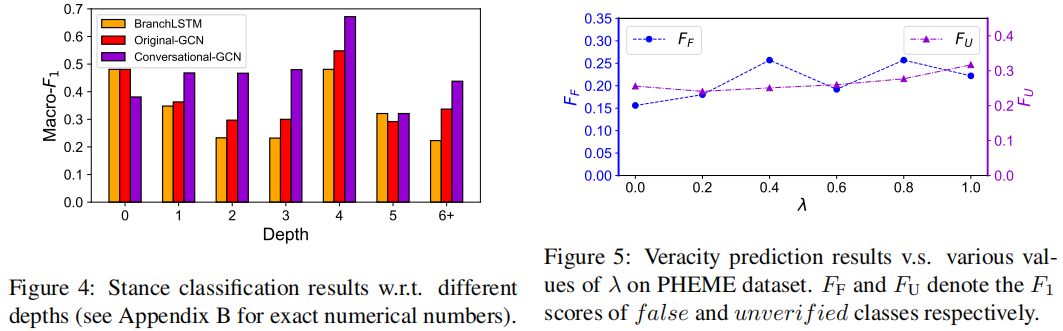
可以观察到,Conversational-GCN在大多数深度水平上明显优于原始-GCN和BranchLSTM。BranchLSTM可能更喜欢在对话中发布“较浅”的推文,因为他它们经常使用出现在多个分支中推文。结果表明,Conversational-GCN在识别对话中发布的“深度”推文立场方面具有优势。
当λ从0.0增加到1.0时,识别假谣言和未被验证谣言的性能通常会提高。因此,当立场分类的监督信号变强时,学习到的立场特征可以产生更准确的预测谣言真实性的线索。
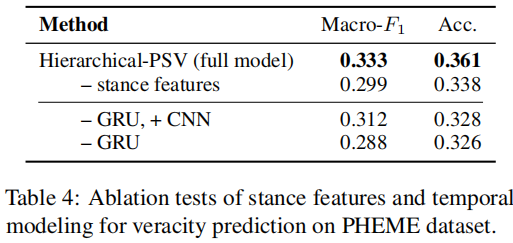
3.3 消融实验
3.4 Case study
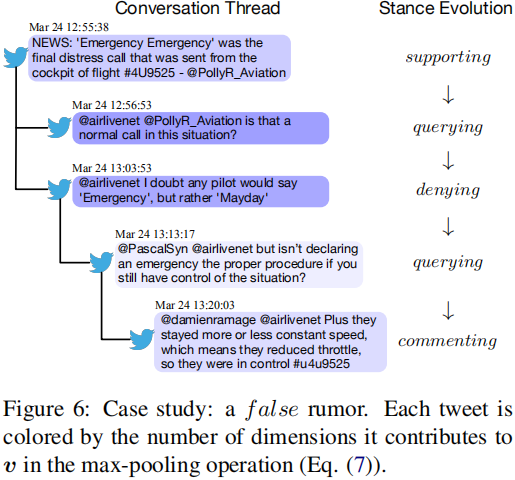
图6显示了本文模型识别的一个假谣言。可以看到,回复推文的立场呈现出一个典型的时序模式,“支持→查询→否认”。
本文模型用RNN捕捉了这种立场演化,并正确预测了其真实性。此外,根据推文的可视化显示,最大池化操作在会话中捕获了信息丰富的推文。因此,本文的框架可以在传播过程中注意到谣言真实性的显著性指标,并将它们结合起来,给出正确的预测。
4 总结
本文提出了一个联合立场检测和谣言分类的层次化多任务学习模型来编码帖子传播过程中的传播结构特征和时序动态。
该模型先利用双向GRU提取帖子的文本特征,然后引入GCN来对帖子的文本特征以及帖子间的关系进行建模,以学习编码了上下文信息的帖子立场特征,最后通过GRU捕捉帖子的立场随时间的动态变化来检测谣言。
尽管本文发表于19年,其效果不弱于SOTA,这表明了基于数据探查和分析来发现问题而做出改进的有效性。当然,值得注意的是,本文提出的模型可能在某些场景下失效,即其假设不再成立的情形,例如是否有某一类谣言,公众对其立场的变化并不代表什么,甚至可能误分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号