

[大数据学习研究]2.利用VirtualBox模拟Linux集群
1. 在主机Macbook上设置HOST
前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了。不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip地址了。
sudo vim /etc/hosts
或者
sudo vim /private/etc/hosts
这两个文件其实是一个,是通过link做的链接。注意要加上sudo, 以管理员运行,否则不能存盘。
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhost
50.116.33.29 sublime.wbond.net
127.0.0.1 windows10.microdone.cn
# Added by Docker Desktop
# To allow the same kube context to work on the host and the container:
127.0.0.1 kubernetes.docker.internal192.168.56.100 hadoop100
192.168.56.101 hadoop101
192.168.56.102 hadoop102
192.168.56.103 hadoop103
192.168.56.104 hadoop104
# End of section
2. 复制虚拟机
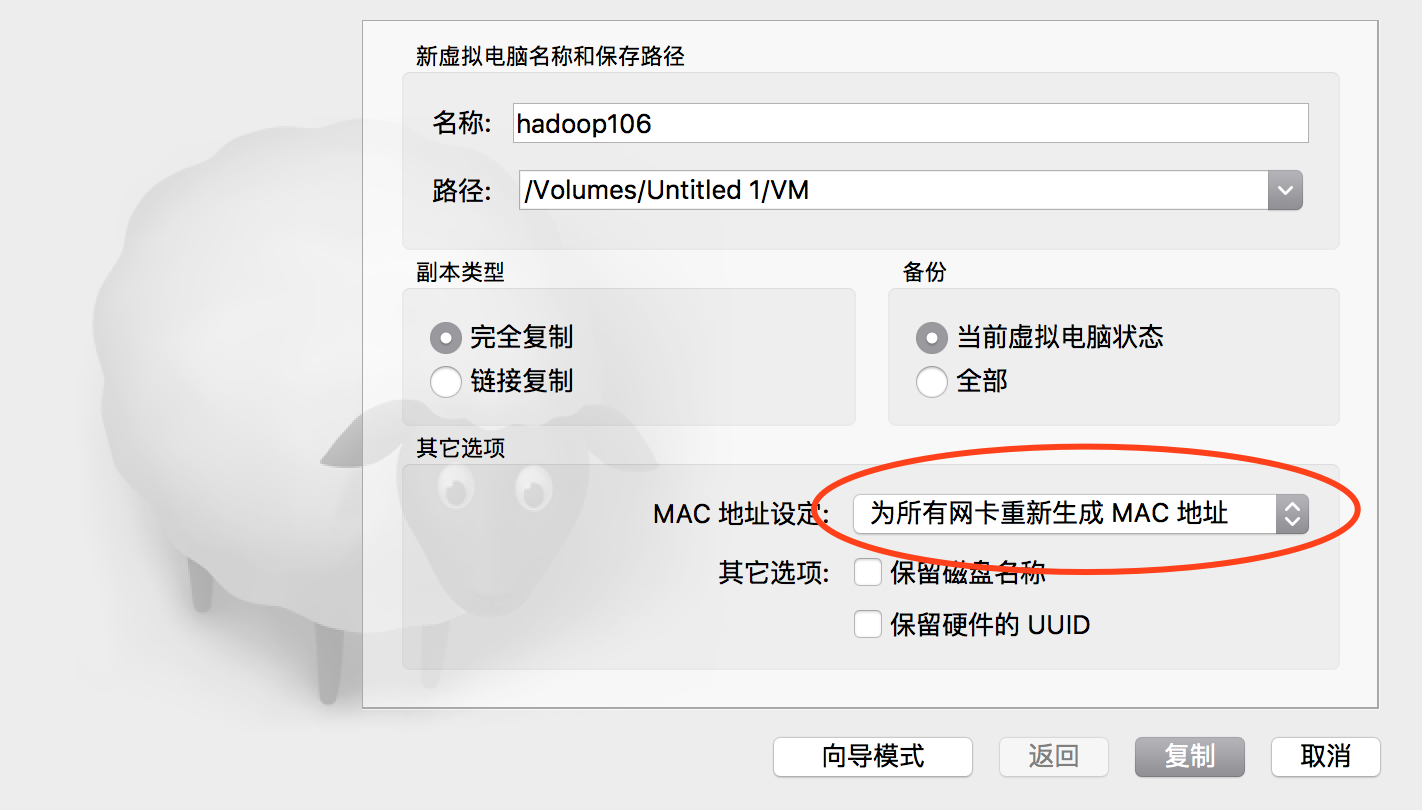
然后我们需要由上次配好的这一台虚拟机,复制出来多台,以便形成一个集群。首先关闭虚拟,在上面点右键,选复制,出现如下对话框,我选择把所有网卡都重新生成Mac地址,以便模拟完全不同的计算器环境。
3. 修改每一台的HOST, IP地址
复制完毕后,记得登录到虚拟机,按照前面提到的方法修改一下静态IP地址,免得IP地址冲突。
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
另外,最好也在每台Linux 虚拟机里也设置一下HOSTNAME,以便这些虚拟机之前相互通讯时也可以使用hostname。需要依次把几台机器的hostname都设置好。
[root@hadoop101 ~]# hostnamectl set-hostname hadoop107
[root@hadoop101 ~]# hostname
hadoop107
4. xcall让服务器集群同时运行命令
因为我们同时有好几台机器,如果挨个挨个的登录上去操作,难免麻烦,可以写个shell脚本,以后从其中一台发起命令,让所有机器都执行就方便多了。下面是个例子。 我有hadopp100,hadopp101、hadopp102、hadopp103、hadopp104这个五台虚拟机。我希望以hadopp100为堡垒,统一控制所有其他的机器。 在/user/local/bin 下创建一个xcall的文件,内容如下:
touch /user/local/bin/xcall
chmod +x /user/local/bin/xcall
vi /user/local/bin/xcall
#!/bin/bash
pcount=$#
if((pcount==0));then
echo no args;
exit;
fiecho ---------running at localhost--------
$@
for((host=101;host<=104;host++));do
echo ---------running at hadoop$host-------
ssh hadoop$host $@
done
~
比如我用这个xcall脚本在所有机器上调用pwd名称,查看当前目录,会依次提示输入密码后执行。
[root@hadoop100 ~]# xcall pwd
---------running at localhost--------
/root
---------running at hadoop101-------
root@hadoop101's password:
/root
---------running at hadoop102-------
root@hadoop102's password:
/root
---------running at hadoop103-------
root@hadoop103's password:
/root
---------running at hadoop104-------
root@hadoop104's password:
/root
[root@hadoop100 ~]#
5. scp与rsync
然后我们说一下 scp这个工具。 scp可以在linux间远程拷贝数据。如果要拷贝整个目录,加 -r 就可以了。
[root@hadoop100 ~]# ls
anaconda-ks.cfg
[root@hadoop100 ~]# scp anaconda-ks.cfg hadoop104:/root/
root@hadoop104's password:
anaconda-ks.cfg 100% 1233 61.1KB/s 00:00
[root@hadoop100 ~]#
另外还可以用rsync, scp是不管目标机上情况如何,都要拷贝以便。 rsync是先对比一下,有变化的再拷贝。如果要远程拷贝的东西比较大,用rsync更快一些。 不如rsync在centOS上没有默认安装,需要首先安装一下。在之前的文章中,我们的虚拟机已经可以联网了,所以在线安装就可以了。
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
命令 命令参数 要拷贝的文件路径/名称 目的用户@主机:目的路径
选项
-r 递归
-v 显示复制过程
-l 拷贝符号连接
[root@hadoop100 ~]# xcall sudo yum install -y rsync
比如,把hadoop100机器上的java sdk同步到102上去:
[root@hadoop100 /]# rsync -r /opt/modules/jdk1.8.0_121/ hadoop102:/opt/modules/jdk1.8.0_121/
然后我们需要一个能把内容自动同步到集群内所有机器的xsync命令;
#!/bin/bash
#1 获取输入参数的个数,如果没有参数则退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname#3 获取上级目前的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir# 获取当前用户名
user=`whoami`#5 循环
for((host=100;host<105;host++));do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo ---------hadoop$host
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
6. SSH免密登录设置
在执行上面的命令时,发现每次都要输入密码,这个也挺烦的,而且后期hadoop集群在启动时也会需要各机器之前相互授权,如果每次都输入密码,确实太麻烦了,所以需要设置一下ssh免密登录。
首先用ssh-keygen -t rsa 生成秘钥对,过程中都按回车介绍默认值即可。然后用ssh-copy-id 其他主机,把公钥发送给要登录的目标主机,在这个过程中需要输入密码以便授权。成功后就可以按照提示用ssh 远程登录到其他主机了,并不要求输入密码。
[root@hadoop104 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:X0I1F6IntPPIJgVHXjmSZ6hmaeWifXa7TmJR9I9YCo8 root@hadoop104
The key's randomart image is:
+---[RSA 2048]----+
| ..+o*.o. |
| ==*== |
| =X+o.o |
| B+.@ + o |
| *S.E * . .|
| . .+o+. |
| o+... |
| . o. |
| .o. |
+----[SHA256]-----+
[root@hadoop104 ~]# ssh-copy-id hadoop100
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop100's password:Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop100'"
and check to make sure that only the key(s) you wanted were added.[root@hadoop104 ~]# 当前在hadoop04下
[root@hadoop104 ~]# ssh hadoop100
Last failed login: Mon Sep 16 13:15:35 CST 2019 from hadoop103 on ssh:notty
There were 5 failed login attempts since the last successful login.
Last login: Mon Sep 16 09:37:51 2019 from 192.168.56.1
[root@hadoop100 ~]# 已经在目标主机下了
按照上面的方法,把所有集群之间都设置好免密登录,也就是每台机器上都ssh-keygen生成一个秘钥对,然后ssh-copy-id到其他几台虚拟机。
好了,到现在基本的工具和集群环境搭建起来了,后面就可以开始hadoop的学习了。
题外话
学习研究的话可以用虚拟机,真要认真做点事还是要上云,比如阿里云。如果你需要,可以用我的下面这个链接,有折扣返现。
https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=vltv9frd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号