
06.Python操作Excel自动化开发
6.1 Python操作Excel自动化开发
6.1.1 python获取Excel数据
import requests from lxml import etree # url='https://dianying.contentchina.com/detail/213415.html' # url='https://dianying.contentchina.com/list/------.html' url='https://dianying.contentchina.com/list/------.html' headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Mobile Safari/537.36' } txt = requests.get(url,headers=headers) test = etree.HTML(txt.text) name_test = test.xpath('//div/a[@class]/@href') print(f'电影名\t评分\t导演') for i in range(16,len(name_test) - 2): url = f'https:{name_test[i]}' resp = requests.get(url,headers=headers) e = etree.HTML(resp.text) movie = e.xpath('//div/div/h1/text()') movie_text = movie[0].strip() if movie else '无标题' score = e.xpath('//div/div/h1/em/text()') score_text = score[0].strip() if score else '无标题' dire = e.xpath('//div/ul/li[2]/em/text()') dire_text = dire[0].strip() if dire else '无标题' name = e.xpath('//div/ul/li[2]/div/a/text()') name_text = name[0].strip() if name else '无标题' print(f'{movie_text}\t{score_text}\t{name_text}')
6.1.2 Excel数据
数据复制到 excel 中,将数据文件放到和处理excel的 Python 文件同一层级
电影名 评分 导演 东极岛 9.1 管虎 摸金玦之天星陵 9.2 王建闯 前任的诱惑 9.6 闫博钦 猫和老鼠:星盘奇缘 9.6 张钢 聊斋:兰若寺 9.1 崔月梅 特种保镖 8.2 周天宇 生化危机6:终章 9.1 保罗·安德森 八佰 9.4 管虎 731大溃逃 8 常彦 营救飞虎 9.2 刘浩良 超人 9.8 詹姆斯·古恩 碟中谍8:最终清算 9.3 克里斯托弗·麦奎里 毕正明的证明 9.3 佟志坚 哪吒之魔童降世 8.6 杨宇 窥情 8.8 陈安琪 花漾少女杀人事件 9.4 周璟豪 罗小黑战记 9.5 动作 功夫 8.5 周星驰 裂战 9.2 关越 铁血抗联之血战松山涧 9.8 韩雨江 爱情和香烟 8.5 约翰·特托罗 人工进化 8.9 文森佐·纳塔利 性与早餐 7.7 MilesBrandman 花芯 9 安藤寻 一眉道人 9.3 林正英 杀手之王 8.6 董玮 疯狂动物城(国语版) 9.8 拜恩·霍华德 熊出没·原始时代 9.1 丁亮 我的朋友他的妻子 7.8 申东日 再见阿龙 9.1 郑中基 志愿军:雄兵出击 9.3 陈凯歌 禁忌 9.2 米格尔·戈麦斯 狼群 9.7 蒋丛 亮剑之血债血偿 9.8 侯杰 二次曝光 8.3 李玉 赌侠1 9.4 王晶 人猿泰山 9.2 W·S· Van Dyke 速度与激情10 9.4 路易斯·莱特里尔 决战中途岛 9.3 罗兰·艾默里奇 铁血女枪手 9.7 宋争 死寂 9.3 温子仁
6.1.3 自动化开发
# pandas 是控制execl工具, xlsx 使用的xlrd库需要手动安装, writer 需要openpyxl作为引擎,pip install pandas 、pip install xlrd、pip install openpyxl import pandas as pd # 读取数据 data = pd.read_excel('yingping.xlsx') # print(data['评分']) # 只取评分这一列 data['c'] = data['评分'].apply(lambda x:x ) # 基于评分在数据中新创建一列 c data['t'] = data['导演'].apply(lambda x:x ) # 基于导演在数据中新创建一列 t # print(data[data['c'] == 9.1]) # c列筛选出得分9.1的一列 writer = pd.ExcelWriter('temp.xlsx') # 打开 xlsx 文件 ''' # 写入一个文件名, 写入sheet_name页名, 写完后关闭 # writer = pd.ExcelWriter('temp.xlsx') # data.to_excel(writer, sheet_name='原始数据') # writer.close() ''' # for i in data['c'].unique(): # 基于c去重,进行for循环 # # print(data[data['c'] == i]) # 打印等于评分i # data[data['c'] == i].to_excel(writer, sheet_name= str(i)) # 筛选等于循环中i的评分,写入xlsx文件,sheet 命名为 i # writer.close() for i in data['t'].unique(): # 基于t去重,进行for循环 # print(data[data['t'].str.contains('陈')]) # 打印导演中包含陈的 data[data['t'] == i].to_excel(writer, sheet_name=str(i)) # 筛选导演包含循环中i的,写入xlsx文件,sheet 命名为 i writer.close()
6.2 执行后Excel
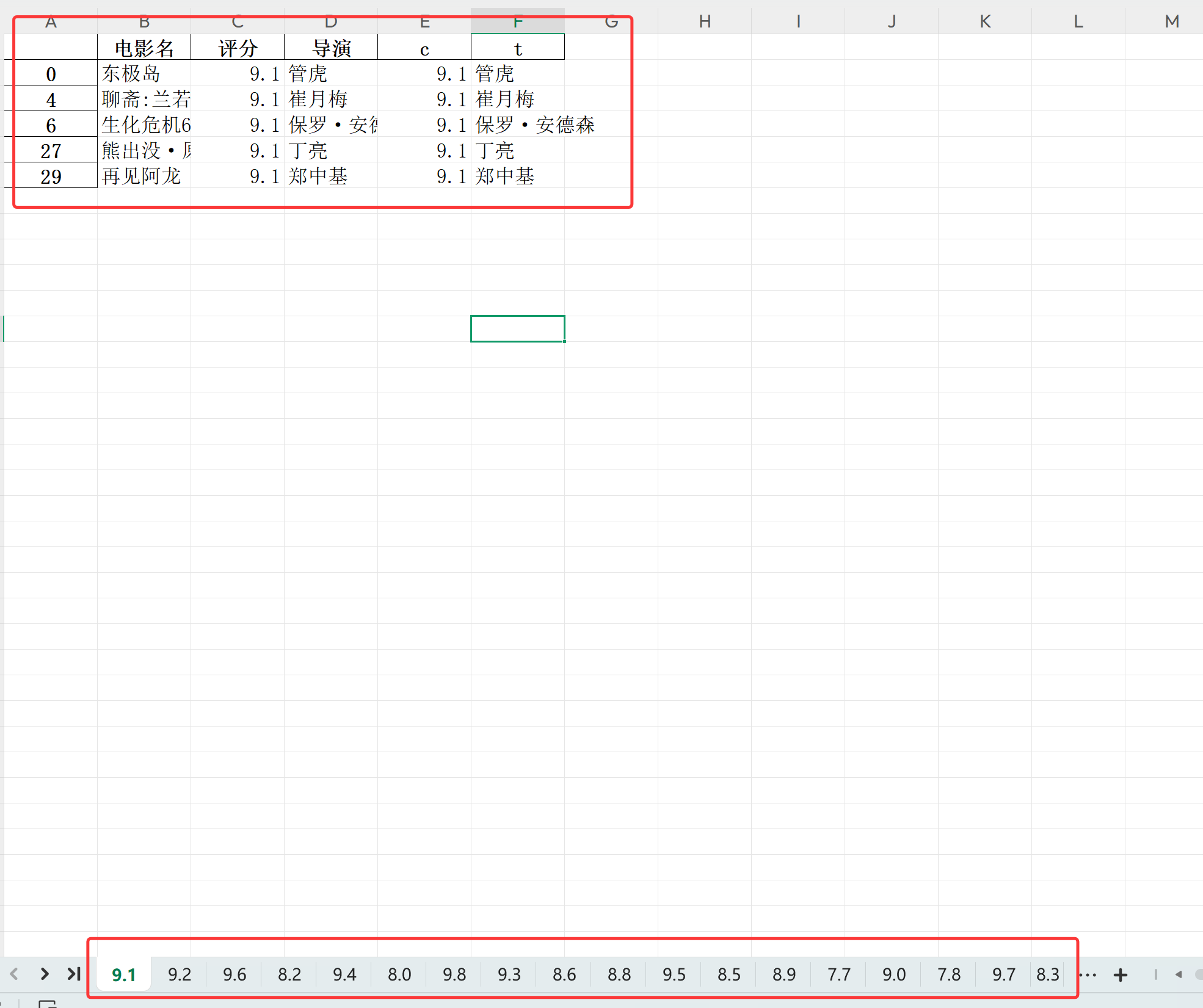
6.2.1 第一个for
根据电影评分区分,以每个评分为一个sheet页
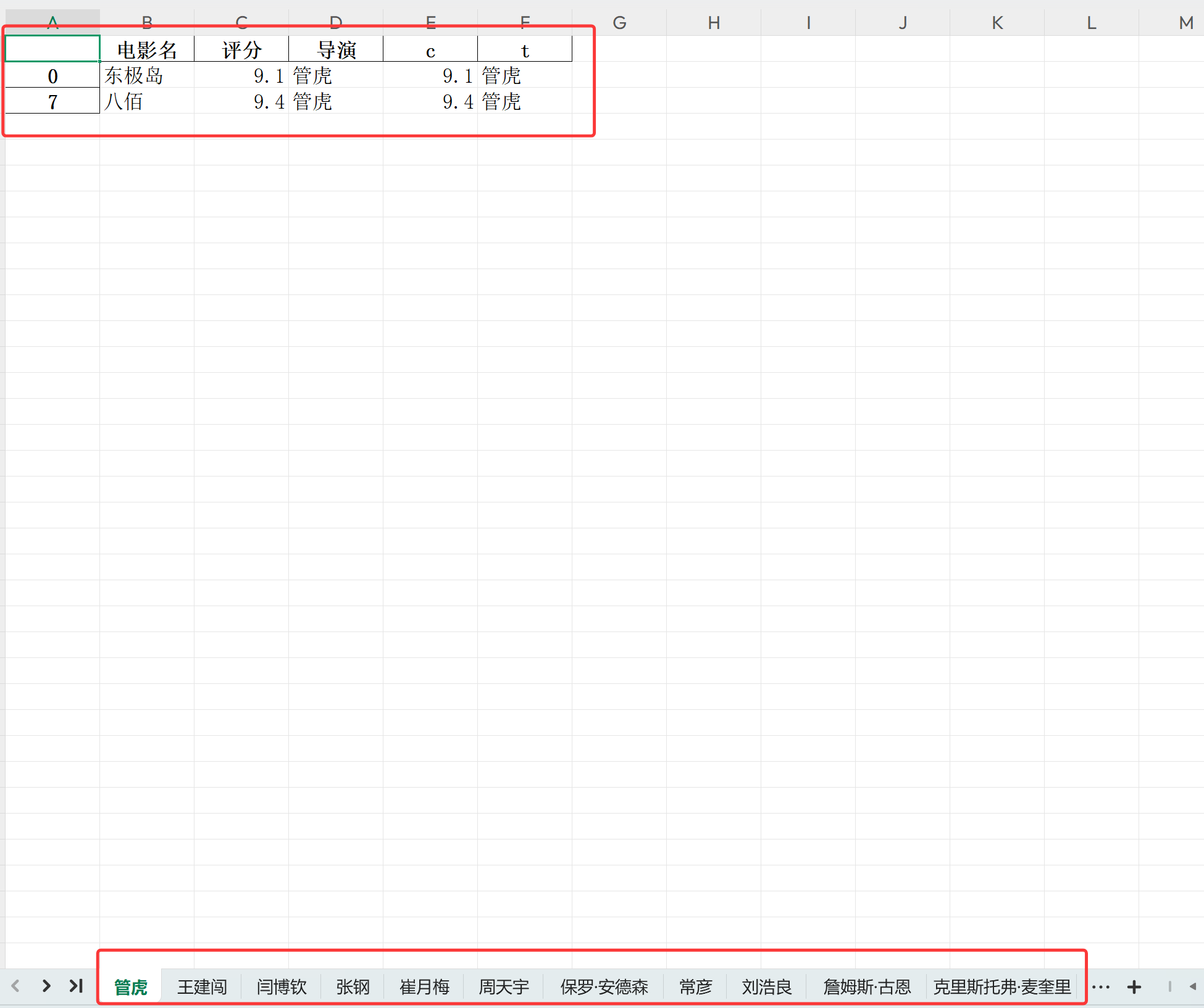
6.2.2 第二个for
根据导演名区分,以每个导演名为一个sheet页
———————————————————————————————————————————————————————————————————————————
无敌小马爱学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号