
01.Python自动获取小说工具
1.1 怎么发送请求?
1.添加pip环境变量:右键“此电脑” → “属性” → “高级系统设置” → “环境变量” → “Path 的值“ 2.安装:pip install requests 或者 python -m pip install requests 注意: Python 3.7.2 是 2018 年发布的旧版本,它内置的 OpenSSL 版本是 1.1.0j,而新版本的 urllib3(2.0+)要求至少 OpenSSL 1.1.1+ 解决办法:降级 urllib3 到兼容版本(快速解决) py -m pip install "urllib3<2.0" 3.验证 requests 模块加载成功 import requests print(requests.__version__) # 打印 requests 模块版本 ------------------------------------------------ 执行后 C:\Users\马俊南\AppData\Local\Programs\Python\Python37\python.exe D:\Pycharm\code\python项目实战\01python自动获取小说工具\01.python自动获取小说工具.py 2.31.0 Process finished with exit code 0
1.2 发送给谁
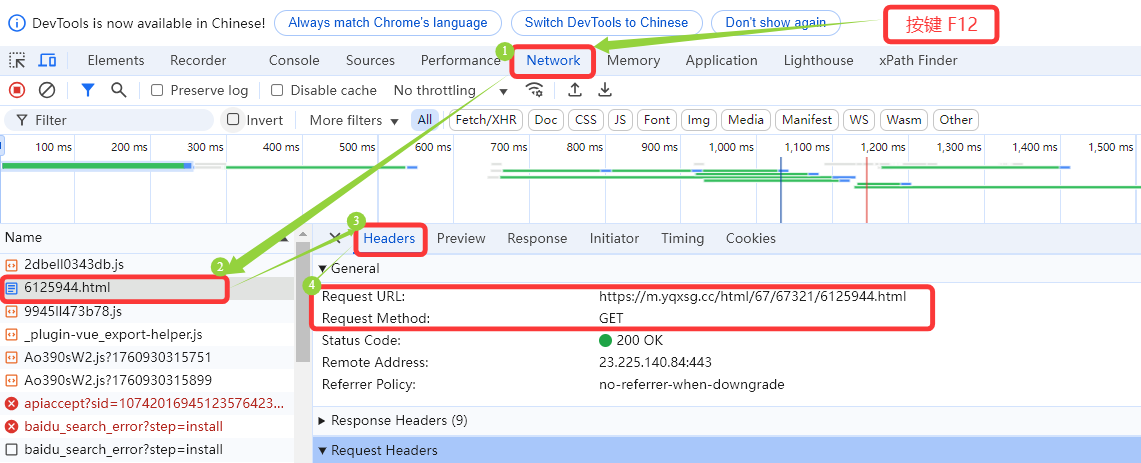
由网址的图片中信息可知,网址 https://m.yqxsg.cc/html/67/67321/6125944.html 和 请求方法 GET
1.3 发送请求
1.3.1 伪装信息
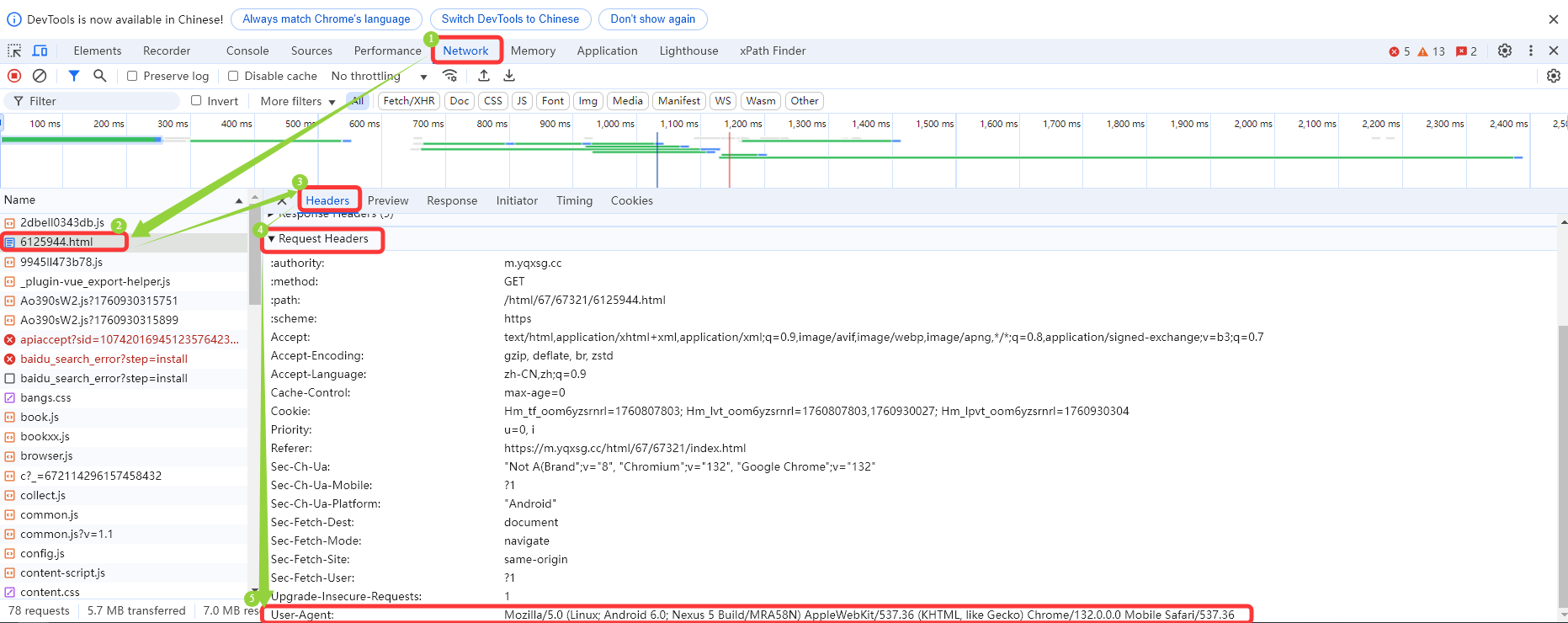
本地浏览器访问服务器提供的头部信息
user-agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Mobile Safari/537.36
# 2 发送给谁? url ='https://m.yqxsg.cc/html/67/67321/6125944.html' # 爬虫小说网站的地址 # 3 发送请求 # 3.1 浏览器访问是正常用户,而代码访问需要伪装自己为正常浏览器 headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Mobile Safari/537.36' }
1.3.2 访问获取
# 3.2 访问的 url 和 伪装用户信息 resp = requests.get(url,headers=headers) # 使用 resp 接收服务器响应
1.3.3 设置编码
# 3.3 取得信息乱码, 需要设置编码 resp.encoding = 'utf-8'
1.3.4 报文拆取
浏览器中安装 XPath Helper 用于在浏览器界面拆解需要的内容格式
# 3.4 只取有用的信息 e = etree.HTML(resp.text) # 代码的格式转换, 与网页相同 info = '\n'.join(e.xpath('//article[@class="content"]/p/text()')) # 网页内容列表多个相加 # 获取标题(xpath 返回列表) title = e.xpath('//h1/text()') # 网页标题 title_text = title[0].strip() if title else '无标题' # 提取字符串,并去除前后空格
1.4 保存信息
# 5 保存 with open('从斗罗大陆开始的人生赢家.txt','w',encoding='utf-8') as f: # 打开文件写入 f.write(title_text+'\n\n'+info) # 标题 换行 内容
1.5 代码优化
# 1 怎么发送请求? # pip install requests import requests # pip install lxml 字符串或标签中提取数据 from lxml import etree import os # 系统模块 用于打开目录 import re # 用于清理文件名 # 设置小说名和保存目录 novel_name = "从斗罗大陆开始的人生赢家" save_dir = novel_name # 自动创建目录(如果不存在) os.makedirs(save_dir, exist_ok=True) # 清理文件名中的非法字符 def sanitize_filename(filename): # 替换 Windows 文件名不允许的字符 return re.sub(r'[<>:"/\\|?*]', '_', filename) # 2 发送给谁? url ='https://www.bqgyy.net/book/15960/3750515.html' # 爬虫小说网站的地址 while True: # 3 发送请求 # 3.1 浏览器访问是正常用户,而代码访问需要伪装自己为正常浏览器 headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Mobile Safari/537.36' } # 3.2 访问的 url 和 伪装用户信息 resp = requests.get(url,headers=headers) # 使用 resp 接收服务器响应 # 3.3 取得信息乱码, 需要设置编码 resp.encoding = 'utf-8' # 3.4 只取有用的信息 e = etree.HTML(resp.text) # 代码的格式转换, 取内容与网页相同 info = '\n'.join(e.xpath('//article[@class="content"]/p/text()')) # 网页内容是列表, 多个列表内容相加 # 获取标题(xpath 返回列表) title = e.xpath('//h1/text()') # 网页标题 title_text = title[0].strip() if title else '无标题' # 提取字符串,并去除前后空格 safe_title = sanitize_filename(title_text) # 调用函数格式转换去除 / next_url = e.xpath('//a[@id="next_url"]/@href') # 下一章内容的路径 # print(next_url[0]) url = f'https://www.bqgyy.net{next_url[0]}' # 下一章内容的 url 替换 # 4 每步测试 # print(resp.text) print(title_text) # 打印爬虫的标题 # print(info) # 打印爬虫的网页内容 # 5 保存 file_path = os.path.join(save_dir, f'{safe_title}.txt') # ✅ 正确拼接路径 with open(file_path, 'w', encoding='utf-8') as f: # 打开文件写入 f.write(title_text + '\n\n' + info) # 标题 换行 内容 if title_text == "第二十章 晴天童话(2 / 2)": break print(f"已保存:{file_path}") ------------------------------------------------ 执行后 C:\Users\马俊南\AppData\Local\Programs\Python\Python37\python.exe D:\Pycharm\code\python项目实战\01python自动获取小说工具\01.python自动获取小说工具.py 第1章 没有外挂的穿越者等于咸鱼(1 / 2) 第1章 没有外挂的穿越者等于咸鱼(2 / 2) 第二章 武魂觉醒仪式(1 / 2) 第二章 武魂觉醒仪式(2 / 2) 第三章 您的外挂已到账(求推荐,求收藏)(1 / 2) 第三章 您的外挂已到账(求推荐,求收藏)(2 / 2) 第四章 强大的外挂(1 / 2) 第四章 强大的外挂(2 / 2) 第五章 黑影忍者军团(求推荐,求收藏)(1 / 2) 第五章 黑影忍者军团(求推荐,求收藏)(2 / 2) 第六章 黑影唐三(1 / 2) 第六章 黑影唐三(2 / 2) 第七章 魂兽永不为奴(求推荐,求收藏)(1 / 2) 第七章 魂兽永不为奴(求推荐,求收藏)(2 / 2) 第八章 猎魂森林(1 / 2) 第八章 猎魂森林(2 / 2) 第九章 这里有一只迷路的铁甲兽(求推荐,求收藏)(1 / 2) 第九章 这里有一只迷路的铁甲兽(求推荐,求收藏)(2 / 2) 第十章 黑影魂环(1 / 2) 第十章 黑影魂环(2 / 2) 第十一章 青楼是合法行当(求推荐,求收藏)(1 / 2) 第十一章 青楼是合法行当(求推荐,求收藏)(2 / 2) 第十二章 加入武魂殿(1 / 2) 第十二章 加入武魂殿(2 / 2) 第十三章 万恶的封建社会(求推荐,求收藏)(1 / 2) 第十三章 万恶的封建社会(求推荐,求收藏)(2 / 2) 第十四章 新生老大(1 / 2) 第十四章 新生老大(2 / 2) 第十五章 揍哭小舞(求推荐,求收藏)(1 / 2) 第十五章 揍哭小舞(求推荐,求收藏)(2 / 2) 第十六章 初见大师(1 / 2) 第十六章 初见大师(2 / 2) 第十七章 属于穿越者的宝藏(求推荐,求收藏)(1 / 2) 第十七章 属于穿越者的宝藏(求推荐,求收藏)(2 / 2) 第十八章 回梦糖豆(新书已签约)(1 / 2) 第十八章 回梦糖豆(新书已签约)(2 / 2) 第十九章 来自地球的童话故事(求推荐,求收藏)(1 / 2) 第十九章 来自地球的童话故事(求推荐,求收藏)(2 / 2) 第二十章 晴天童话(1 / 2) 第二十章 晴天童话(2 / 2) 已保存:从斗罗大陆开始的人生赢家\第二十章 晴天童话(2 _ 2).txt Process finished with exit code 0
1.6 通义生成代码
# 1 怎么发送请求? import requests from lxml import etree import os import re # 用于清理文件名 # 设置小说名和保存目录 novel_name = "从斗罗大陆开始的人生赢家" save_dir = novel_name # 自动创建目录(如果不存在) os.makedirs(save_dir, exist_ok=True) # 清理文件名中的非法字符 def sanitize_filename(filename): # 替换 Windows 文件名不允许的字符 return re.sub(r'[<>:"/\\|?*]', '_', filename) # 2 发送给谁? url = 'https://www.bqgyy.net/book/15960/3750515.html' while True: try: # 3 发送请求 headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Mobile Safari/537.36' } resp = requests.get(url, headers=headers) resp.encoding = 'utf-8' e = etree.HTML(resp.text) # 提取内容 info = '\n'.join(e.xpath('//article[@class="content"]/p/text()')) title = e.xpath('//h1/text()') title_text = title[0].strip() if title else '无标题' # ✅ 清理文件名 safe_title = sanitize_filename(title_text) # 获取下一章链接 next_link = e.xpath('//a[@id="next_url"]/@href') if next_link: url = f'https://www.bqgyy.net{next_link[0]}' else: print("已到达最后一章。") break # 4 打印标题(调试) print(title_text) # 5 保存文件 file_path = os.path.join(save_dir, f'{safe_title}.txt') # 使用安全的文件名 with open(file_path, 'w', encoding='utf-8') as f: f.write(title_text + '\n\n' + info) # 判断是否停止 if title_text == "第二十章 晴天童话(2 / 2)": break except Exception as exc: print(f"爬取失败:{url}") print(f"错误信息:{exc}") break print(f"已保存:{file_path}")
———————————————————————————————————————————————————————————————————————————
无敌小马爱学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号