
28.B站薪享宏福笔记——第十一章(2)资源监控Prometheus
11 B站薪享宏福笔记——第十一章
—— kubernetes 中的必备的工具组件
11.3 资源监控方案
—— Prometheus 无可挑剔的选择
11.3.1 组件介绍

1.Prometheus 是一个开源的系统监控和报警工具(监控和报警需与其他组件一同工作,单 Prometheus 可以理解为 时序数据库),最初是在 SoundCloud 上构建的。Prometheus 于 2016 年加入 CNCF(云原生计算基金会),成为继 Kubernetes 之后的第二个托管项目,2018 年 8 月 9 日,CNCF 宣布开放源代码监控工具 Prometheus 已从孵化状态进入毕业状态

2.Cadvisor(猫头鹰监控) 是 Google 开源的一款用来检测、分析、展示单节点的一个容器性能指标和资源监控的可视化工具(也可以监控本机,针对单台物理机),监控包括容器的内存使用率、CPU 使用率、网络 IO 、磁盘 IO 、及文件系统使用情况,利用 Linux 的 Cgroup 获取容器及本机的资源使用情况,同时提供了一个 Web 界面用于查看容器的实时运行状态(拥有接口,可以对接 Prometheus)

3.kube-state-metrics 关注于获取 k8s 各种资源的最新状态,如 deployment控制器 或 daemonset控制器(完成的期望情况,是否完成指标)

4.Metrics Server 是从 api-server 中获取 cpu、内存使用率 等监控指标,当前的核心作用是为 HPA、kubectl top 等组件提供决策指标支持

5.Grafana 是一个监控仪表系统,它是由 Grafana Labs 公司开源的一个系统检测工具,Grafana 支持许多不同的数据源,每个数据源都有一个特定的查询编辑器,它可以帮助生成各种可视化仪表,同时它还有报警功能,可以在系统出现问题时发出通知

6.Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且可以对告警消息进行去重、降噪、分组、策略路由,是一款前卫的告警通知系统
11.3.2 架构图
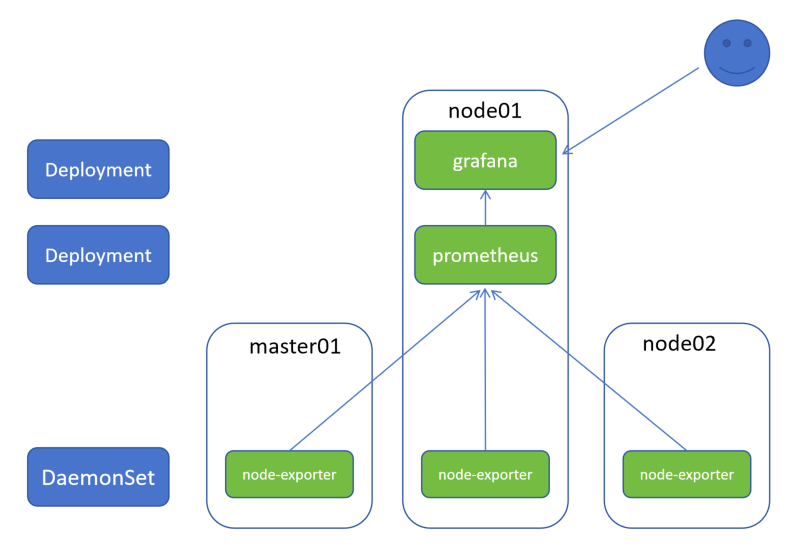
1.通过 DaemonSet 控制器部署 node-exporter,可以在每个节点物理机上运行一个 Pod(收集当前物理机上监控指标)
2.通过 Deployment 控制器部署 Proemtheus 和 Grafana
3.收集的数据指标被 Prometheus 捕获并存储,Prometheus 再对接 Grafana,通过 PQL(Prometheus 查询语言)将存储的数据通过图片的形式进行页面展示
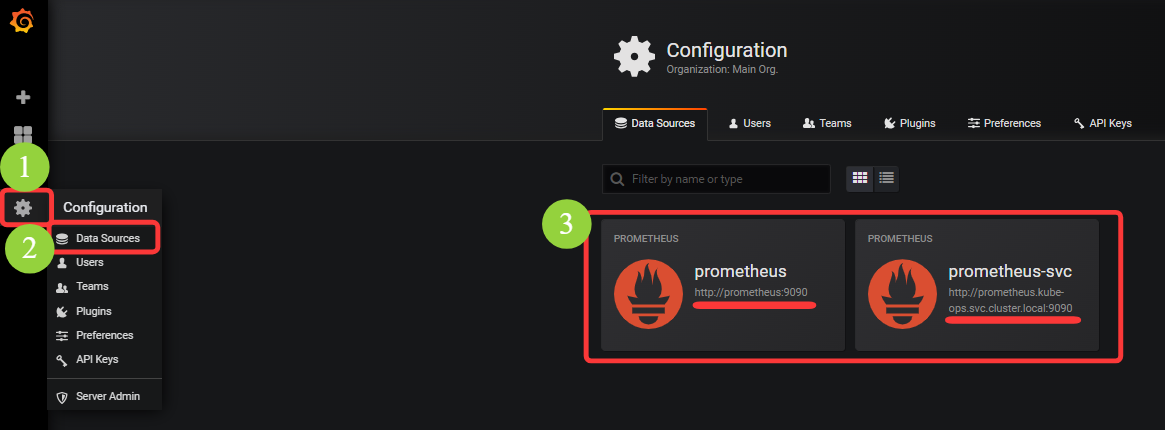
11.3.3 监控部署
(0)准备工作
# 上传文件 [root@k8s-master01 11.3]# rz -E rz waiting to receive. # Kubernetes_监控-1711686553279.json 是收集的 grafana 展示 SQL,prometheus-munaul.tar.gz 是压缩包 [root@k8s-master01 11.3]# ls Kubernetes_监控-1711686553279.json prometheus-munaul.tar.gz # 解压 [root@k8s-master01 11.3]# tar -xvf prometheus-munaul.tar.gz ......... [root@k8s-master01 11.3]# ls 1 10 2 3 4 5 6 7 8 9 Kubernetes_监控-1711686553279.json prometheus-images prometheus-munaul.tar.gz
# 各节点导入镜像,所有镜像都导入,后续会用到 # 主节点导入镜像 [root@k8s-master01 11.3]# for i in `ls prometheus-images/*`;do docker load -i $i;done ......... # 将镜像目录传送到其他两个 worK 节点 [root@k8s-master01 11.3]# scp -r prometheus-images n1:/root/ root@n1's password: grafana-grafana-5.3.4.tar 100% 229MB 30.2MB/s 00:07 grafana-promtail-2.8.3.tar 100% 190MB 30.0MB/s 00:06 prom-alertmanager-v0.15.3.tar 100% 34MB 34.9MB/s 00:00 prom-node-exporter-v0.16.0.tar 100% 23MB 33.0MB/s 00:00 prom-prometheus-v2.4.3.tar 100% 95MB 35.1MB/s 00:02 registry.k8s.io-kube-state-metrics-kube-state-metrics-v2.10.0.tar 100% 42MB 4.7MB/s 00:08 registry.k8s.io-metrics-server-metrics-server-v0.6.4.tar 100% 67MB 19.8MB/s 00:03 [root@k8s-master01 11.3]# scp -r prometheus-images n2:/root/ root@n2's password: grafana-grafana-5.3.4.tar 100% 229MB 29.3MB/s 00:07 grafana-promtail-2.8.3.tar 100% 190MB 25.3MB/s 00:07 prom-alertmanager-v0.15.3.tar 100% 34MB 36.0MB/s 00:00 prom-node-exporter-v0.16.0.tar 100% 23MB 29.3MB/s 00:00 prom-prometheus-v2.4.3.tar 100% 95MB 26.7MB/s 00:03 registry.k8s.io-kube-state-metrics-kube-state-metrics-v2.10.0.tar 100% 42MB 29.7MB/s 00:01 registry.k8s.io-metrics-server-metrics-server-v0.6.4.tar 100% 67MB 21.3MB/s 00:03
# 从节点导入镜像 [root@k8s-node01 ~]# for i in `ls /root/prometheus-images/*`;do docker load -i $i;done ......... [root@k8s-node02 ~]# for i in `ls /root/prometheus-images/*`;do docker load -i $i;done .........
(1)部署 Prometheus
[root@k8s-master01 11.3]# kubectl create namespace kube-ops namespace/kube-ops created [root@k8s-master01 11.3]# cat 1/1.prometheus-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090']
4.数据:prometheus.yml 文件名、全局声明:抓取指标数据的频率 15秒、抓取指标数据的超时时间 15秒 抓取的数据配置:任务名、静态配置方式获取、获取数据端口:本地 9090(即 prometheus 获取自己的数据)
[root@k8s-master01 11.3]# kubectl get storageclasses NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 57d [root@k8s-master01 11.3]# cat 1/2.prometheus-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: prometheus namespace: kube-ops spec: storageClassName: nfs-client accessModes: - ReadWriteMany resources: requests: storage: 10Gi
4.期望:动态存储:nfs-client(与上面 sc 名字相同)、资源写入模式:可多节点读写、存储:请求大小:基于动态存储:10G
[root@k8s-master01 11.3]# cat 1/3.prometheus-rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: kube-ops --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: - "" resources: - nodes - services - endpoints - pods - nodes/proxy verbs: - get - list - watch - apiGroups: - "" resources: - configmaps - nodes/metrics verbs: - get - nonResourceURLs: - /metrics verbs: - get --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: kube-ops
创建sa 、创建权限、将用户绑定到对应的权限上
[root@k8s-master01 11.3]# cat 1/4.prometheus-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: prometheus namespace: kube-ops labels: app: prometheus spec: selector: matchLabels: app: prometheus template: metadata: labels: app: prometheus spec: serviceAccountName: prometheus containers: - image: prom/prometheus:v2.4.3 name: prometheus command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能 - "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效 ports: - containerPort: 9090 protocol: TCP name: http volumeMounts: - mountPath: "/prometheus" subPath: prometheus name: data - mountPath: "/etc/prometheus" name: config-volume resources: requests: cpu: 100m memory: 512Mi limits: cpu: 100m memory: 512Mi securityContext: runAsUser: 0 volumes: - name: data persistentVolumeClaim: claimName: prometheus - configMap: name: prometheus-config name: config-volume
4.deployment期望:标签选择器:匹配标签:标签、标签值 Pod 模板:元数据、标签:标签、标签值 容器期望:sa 认证:sa 名称 容器组:基于镜像版本
容器名
启动命令
启动时传入参数:配置文件、数据目录、数据存放时间、打开 API 、支持热加载
端口:容器端口:9090、端口协议:TCP、端口名:http
卷挂载:卷路径、目标路径、卷名、卷路径、卷名
资源请求:最大值:cpu、内存、初始值:cpu、内存
安全上下文:容器运行启动用户
定义卷:卷名
通过 PVC 申请:名字
cm 配置:cm 名字
[root@k8s-master01 11.3]# cat 1/5.prometheus-svc.yaml apiVersion: v1 kind: Service metadata: name: prometheus namespace: kube-ops labels: app: prometheus spec: selector: app: prometheus type: NodePort ports: - name: web port: 9090 targetPort: http
4.期望:标签匹配:标签、标签值、类型:端口、端口定义:端口名、端口值、目标端口名称(上面 4.prometheus-deploy.yaml 中定义的 http 名称对应)
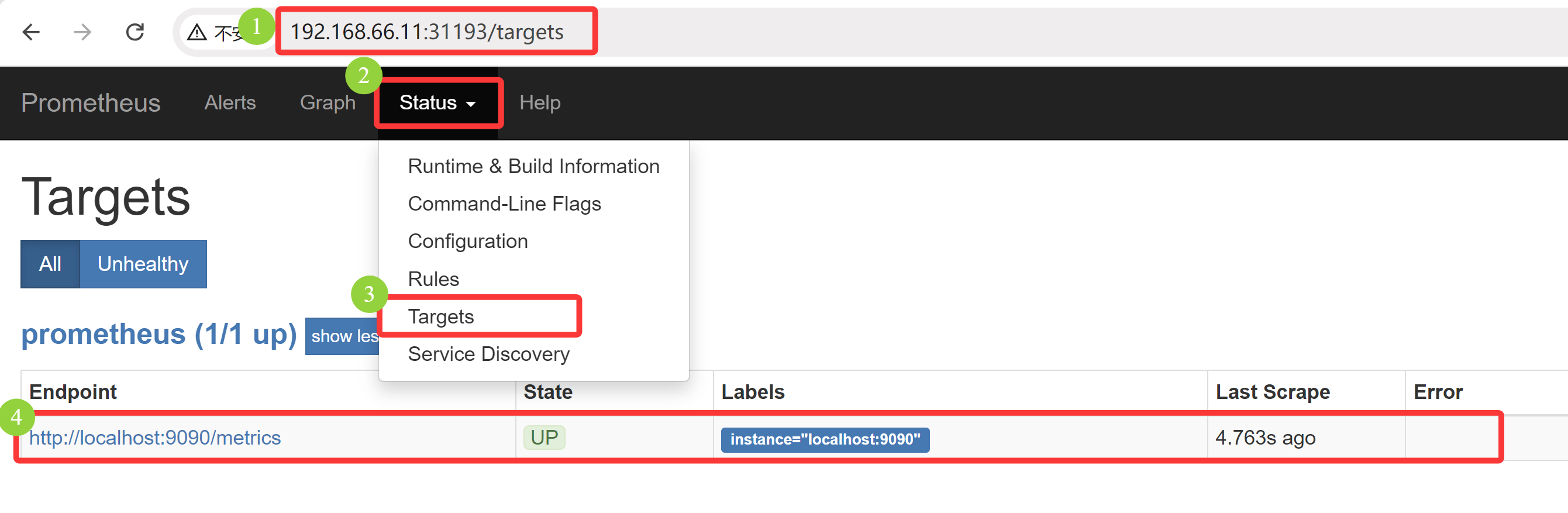
# 部署 [root@k8s-master01 11.3]# kubectl apply -f 1/1.prometheus-cm.yaml configmap/prometheus-config created [root@k8s-master01 11.3]# kubectl apply -f 1/2.prometheus-pvc.yaml persistentvolumeclaim/prometheus created [root@k8s-master01 11.3]# kubectl apply -f 1/3.prometheus-rbac.yaml serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/prometheus created clusterrolebinding.rbac.authorization.k8s.io/prometheus created [root@k8s-master01 11.3]# kubectl apply -f 1/4.prometheus-deploy.yaml deployment.apps/prometheus created [root@k8s-master01 11.3]# kubectl apply -f 1/5.prometheus-svc.yaml service/prometheus created [root@k8s-master01 11.3]# kubectl get pvc -n kube-ops NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE prometheus Bound pvc-ec0f6bc0-444a-463a-b02a-6c64c639eb97 10Gi RWX nfs-client <unset> 2m34s [root@k8s-master01 11.3]# kubectl get pod -o wide -n kube-ops NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES prometheus-844847f5c7-4z6d6 1/1 Running 0 2m32s 10.244.58.230 k8s-node02 <none> <none> [root@k8s-master01 11.3]# kubectl get svc -n kube-ops NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.15.109.180 <none> 9090:31193/TCP 2m37s
根据 NodePort ,可以使用浏览器访问 192.168.66.11:31193,查看状态是 UP,可知已经监控本身的端口数据
(2)监控 Ingress-nginx
Prometheus 的数据指标是通过一个公开的 HTTP(s)数据接口获取到的,不需要单独安装监控的 agent,只需要暴露一个 metrics 接口,Prometheus 就会去定期拉取数据,对于一些普通的 HTTP 服务,完全可以直接重用这个服务, Ingress 添加一个 /metrics 接口暴露给 Prometheus
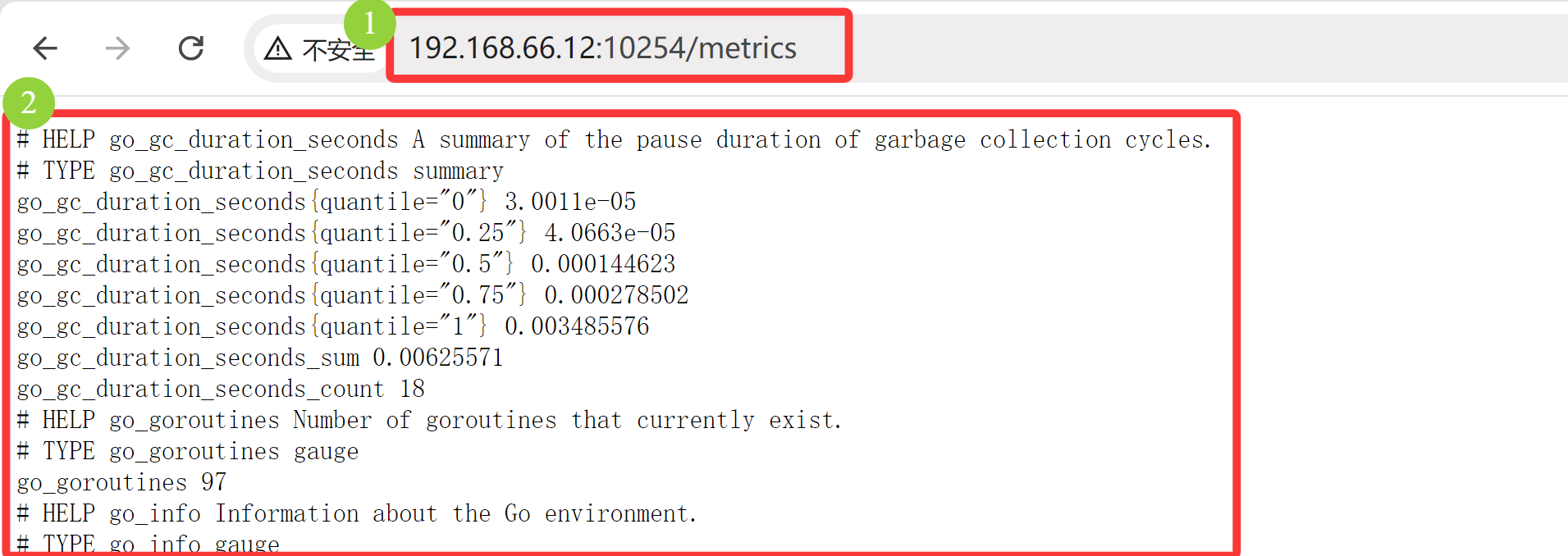
# 这里第十章 已经指定 安装了 metrics [root@k8s-master01 ingress-nginx]# helm install ingress-nginx -n ingress . -f values.yaml .......... # 卸载后修改配置,重新安装,这里定义 metrics 的端口 10254 [root@k8s-master01 ingress-nginx]# pwd /root/10/10.3/2、ingress-nginx/chart/ingress-nginx [root@k8s-master01 ingress-nginx]# helm uninstall ingress-nginx -n ingress [root@k8s-master01 ingress-nginx]# cat -n values.yaml 675 metrics: 676 port: 10254 677 portName: metrics 678 # if this port is changed, change healthz-port: in extraArgs: accordingly 679 enabled: true [root@k8s-master01 ingress-nginx]# helm install ingress-nginx -n ingress . -f values.yaml [root@k8s-master01 ingress-nginx]# helm list -n ingress NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION ingress-nginx ingress 1 2025-08-18 23:10:18.300902526 +0800 CST deployed ingress-nginx-4.8.3 1.9.4
浏览器访问:192.168.66.12:10254/metrics 、192.168.66.13:10254/metrics ,有数据的展示
[root@k8s-master01 11.3]# cat 2/1.prome-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254']
4.数据:prometheus.yml 文件名、全局声明:抓取指标数据的频率 30 秒、抓取指标数据的超时时间 30 秒 抓取的数据配置:任务名、静态配置方式获取、获取数据端口:本地 9090(即 prometheus 获取自己的数据) 任务名、静态配置方式获取、获取 IP 数据端口:本地 10254 任务名、静态配置方式获取、获取 IP 数据端口:本地 10254
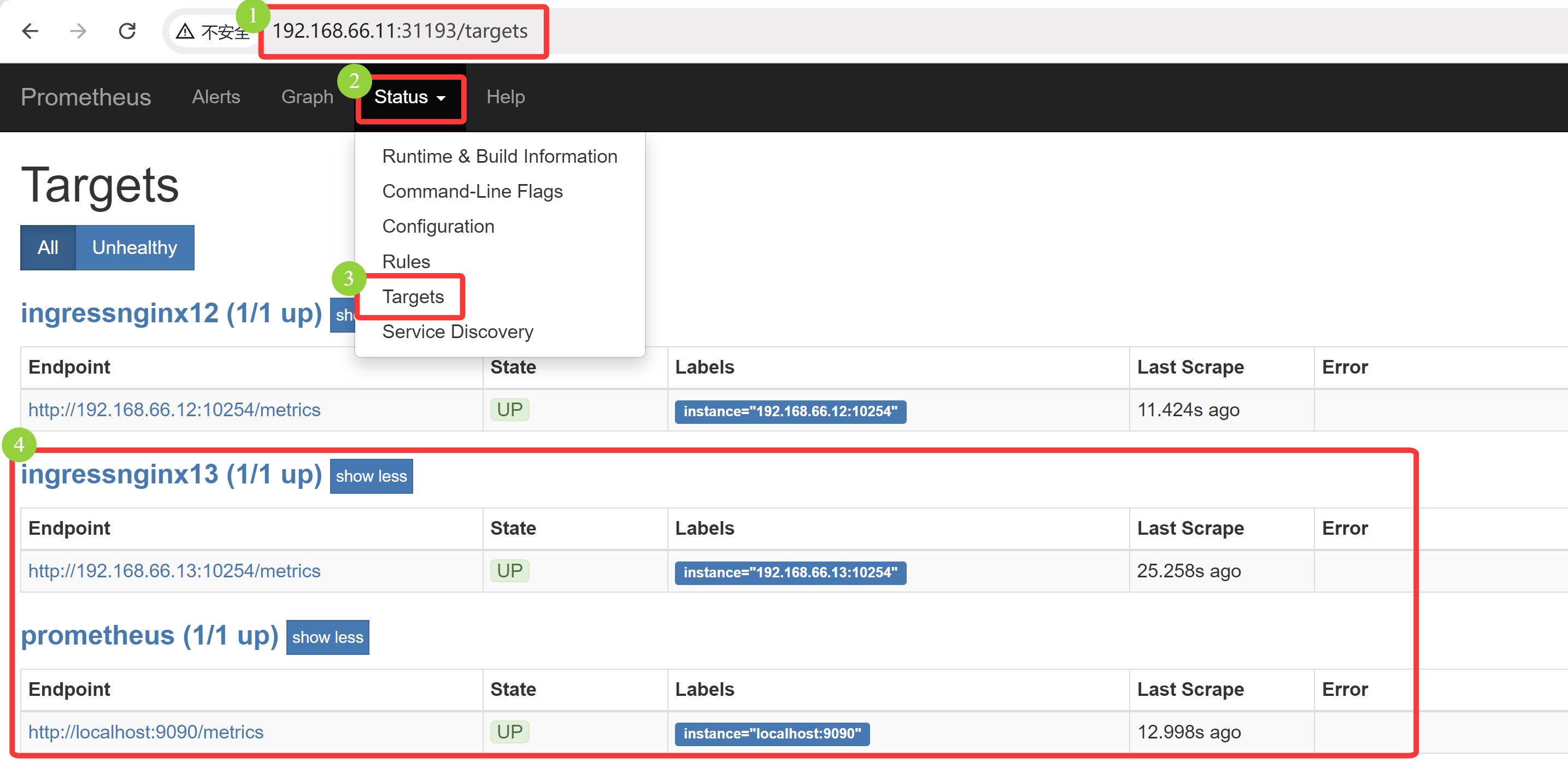
# 注意:这里可以先 kubectl describe configmap prometheus-config -n kube-ops 查看 prometheus.yml 配置是否更改,再触发热加载,否则,新配置没更改,触发热加载没有效果 [root@k8s-master01 11.3]# kubectl apply -f 2/1.prome-cm.yaml configmap/prometheus-config configured [root@k8s-master01 11.3]# kubectl get configmaps -n kube-ops NAME DATA AGE kube-root-ca.crt 1 7h42m prometheus-config 1 109m [root@k8s-master01 11.3]# kubectl describe configmap prometheus-config -n kube-ops Name: prometheus-config Namespace: kube-ops Labels: <none> Annotations: <none> Data ==== prometheus.yml: ---- global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] BinaryData ==== Events: <none> [root@k8s-master01 11.3]# kubectl get svc -n kube-ops NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.15.109.180 <none> 9090:31193/TCP 112m [root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
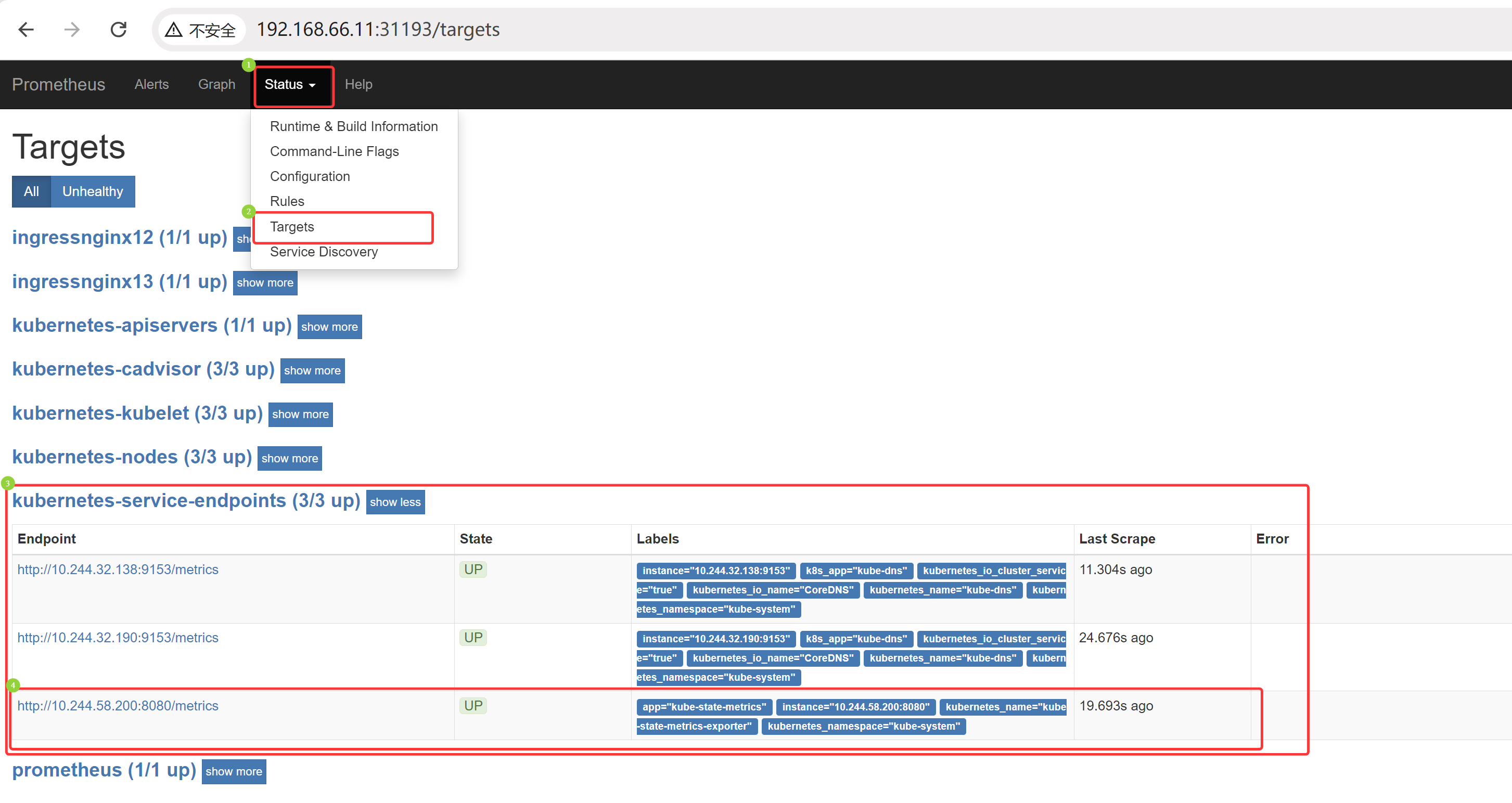
浏览器访问:192.168.66.11:31193/targets , 可以采集到 192.168.66.12 和 192.168.66.13 节点的信息
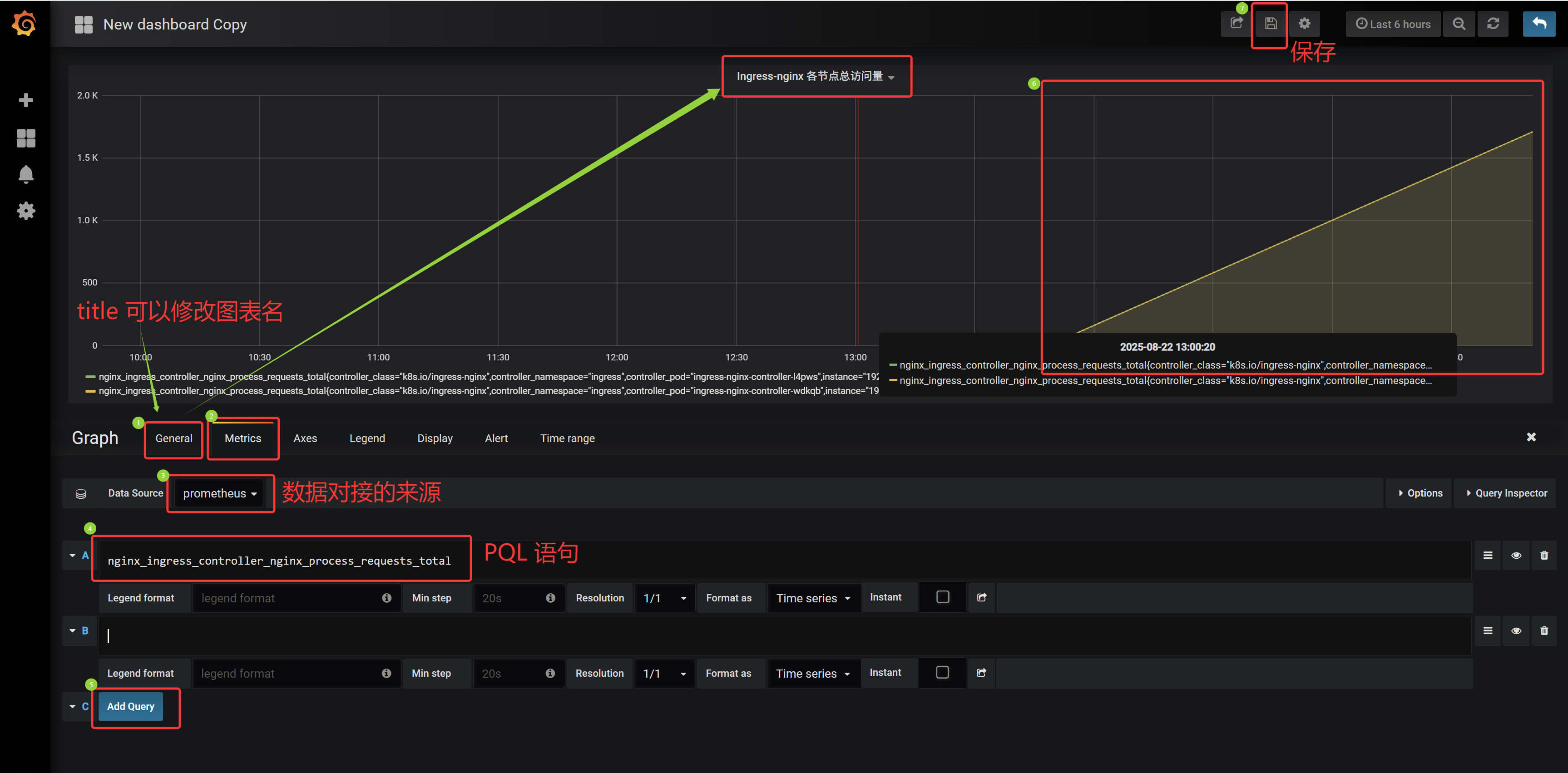
Ingress-nginx 总访问量: sum(nginx_ingress_controller_nginx_process_requests_total) Ingress-nginx 各节点访问量:nginx_ingress_controller_nginx_process_requests_total
Ingress-nginx 某节点访问量:nginx_ingress_controller_nginx_process_requests_total{instance="192.168.66.12:10254"}
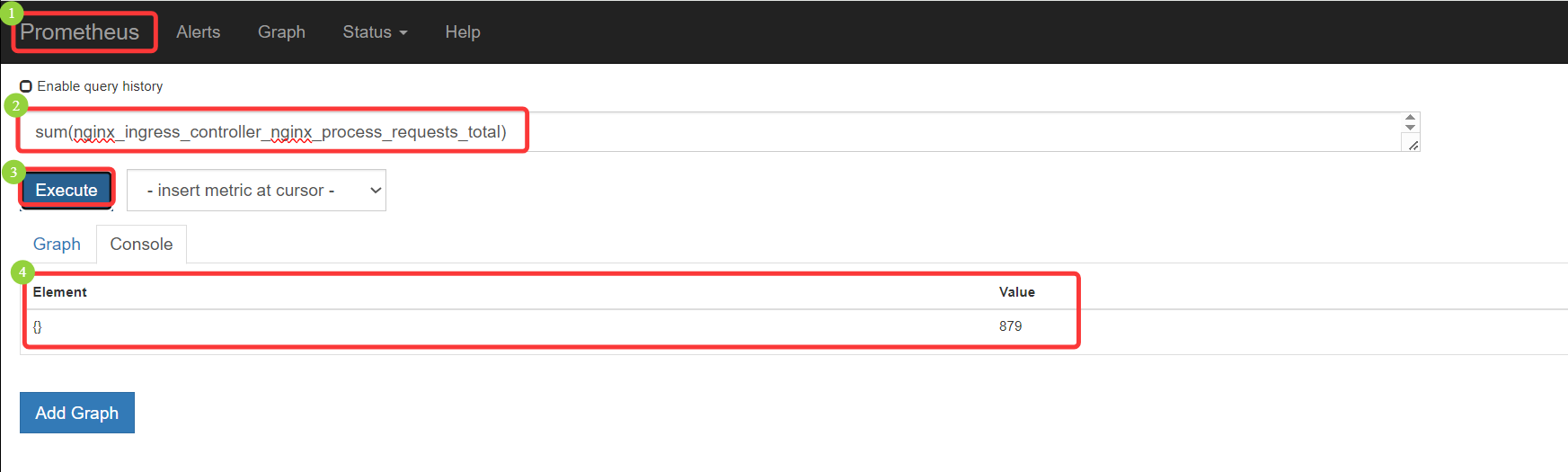
(3)节点监控 Node-exporter & Kubelet
a.Node-exporter 节点信息
node_exporter 用于抓取采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack、cpu、diskstats、filesystem、loadavg、meminfo、netstat 等,详细的监控点列表可以参考 github node_exporter
[root@k8s-master01 11.3]# cat 3/1.prome-node-exporter.yaml # 创建 prome-node-exporter.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: node-exporter namespace: kube-ops labels: name: node-exporter spec: selector: matchLabels: name: node-exporter template: metadata: labels: name: node-exporter spec: hostPID: true hostIPC: true hostNetwork: true containers: - name: node-exporter image: prom/node-exporter:v0.16.0 ports: - containerPort: 9100 resources: requests: cpu: 0.15 securityContext: privileged: true args: - --path.procfs - /host/proc - --path.sysfs - /host/sys - --collector.filesystem.ignored-mount-points - '"^/(sys|proc|dev|host|etc)($|/)"' volumeMounts: - name: dev mountPath: /host/dev - name: proc mountPath: /host/proc - name: sys mountPath: /host/sys - name: rootfs mountPath: /rootfs tolerations: - key: "node-role.kubernetes.io/control-plane" operator: "Exists" effect: "NoSchedule" volumes: - name: proc hostPath: path: /proc - name: dev hostPath: path: /dev - name: sys hostPath: path: /sys - name: rootfs hostPath: path: /
4.daemonset期望:选择器:匹配标签:标签、标签值 Pod模版:Pod元数据:标签、标签值 Pod期望:共享主机 PID、IPC、网络(获取物理机信息) 容器组:容器名、基于镜像版本、端口:容器端口、资源限制:初始值:cpu、安全上下文:开启特权模式(获取物理机信息) 添加启动命令参数(获取物理机信息,排除一些挂载点)
卷挂载:将 dev 挂载到 /host/dev,将 proc 挂载到 /host/proc,将 sys 挂载到 /host/sys,将 rootfs 挂载到 /rootfs 污点容忍:污点名、容忍策略、效果
定义卷:卷名 proc、主机卷挂载:路径 /proc、卷名 dev、主机卷挂载:路径 /dev、卷名 sys、主机卷挂载:路径 /sys、卷名 rootfs、主机卷挂载:路径 /
[root@k8s-master01 11.3]# kubectl apply -f 3/1.prome-node-exporter.yaml daemonset.apps/node-exporter created # 监控节点的 node-exporter Pod 已经部署完成
[root@k8s-master01 11.3]# kubectl get pod -o wide -n kube-ops NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-exporter-f6kvh 1/1 Running 0 17s 192.168.66.12 k8s-node01 <none> <none> node-exporter-hft7m 1/1 Running 0 17s 192.168.66.11 k8s-master01 <none> <none> node-exporter-rkzqg 1/1 Running 0 17s 192.168.66.13 k8s-node02 <none> <none> prometheus-844847f5c7-4z6d6 1/1 Running 1 (6h39m ago) 18h 10.244.58.247 k8s-node02 <none> <none>
在 Kubernetes 下,Prometheus 通过与 Kubernetes API 集成,目前主要支持 5 种服务发现模式(自动发现),分别是: Node 、Service、Pod、Endpoints、Ingress
通过指定 kubernetes_sd_configs 的模式为以上五种,例如:node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点,并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口
prometheus 发现 Node 模式的服务时,访问的端口默认是 10250,而 node-exporter 在通过 Pod 抓取节点指标数据,并指定 hostNetwork=true 时,Pod 在每个节点上绑定端口是 9100,所以需要做端口转换
# 将节点信息通过 10250 端口暴露,再转入 9100端口 的 Prometheus 数据采集端口
[root@k8s-master01 11.3]# cat 3/2.prome-cm.yaml # 修改 prometheus 配置文件 prome-cm.yaml .......... - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+)
..........
任务名、通过 k8s API 接口自动发现:角色、节点 重标签的配置:API 中获取的原标签、正则匹配:当前所有的 10250 端口、替换成第一个分组(即上面(.*)) 9100 端口、目标替换标签、动作:替换、动作:标签、运算符方式:__meta_kubernetes_node_label_(.+) 即将所有节点的标签也添加到监控数据中
Prometheus 去发现 Node 模式服务时,访问的端口默认是10250,而现在该端口下已经没有 /metrics 指标数据,kubelet 只读的数据接口统一通过10250端口进行暴露了,但是真的要替换成10250端口吗?不是的,因为要去配置上面通过 node-exporter 抓取到的节点指标数据,而上面指定了 hostNetwork=true ,所以在每个节 点上就会绑定一个端口9100,所以可以将10250替换成9100 ,这可以使用到 Prometheus 提供的 relabel_configs 中的 replace 能力,relabel 可以在 Prometheus 采集数据之前,通过Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之 外,还能根据 Target 实例的 Metadata 信息选择是否采集或忽略该 Target 实例
添加一个 action 为 labelmap ,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中
对于 kubernetes_sd_configs 下面可用的标签如下: 可用元标签:
__meta_kubernetes_node_name:节点对象的名称
_meta_kubernetes_node_label:节点对象中的每个标签
_meta_kubernetes_node_annotation:来自节点对象的每个注释
_meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在)
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
b.Kubelet 节点信息
Kubernetes 1.11+ 版本以后,kubelet 就移除了 10255 端口, metrics 接口又回到了 10250 端口,所以这里不需要替换端口,但是需要使用 https 的协议
可以通过监控 kubelet,从而确定 Pod 的监控信息
[root@k8s-master01 11.3]# cat 3/2.prome-cm.yaml # 修改 prometheus 配置文件 prome-cm.yaml .......... - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+)
任务名、通过 k8s API 接口自动发现:角色、节点
协议:https、证书配置:ca证书:ca 证书路径、跳过证书认证:开启
token 文件: sa token 文件位置
重标签的配置:动作:标签、运算符方式:__meta_kubernetes_node_label_(.+) 即将所有节点的标签也添加到监控数据中
c.node-exporter && kubelet 监控部署
[root@k8s-master01 11.3]# cat 3/2.prome-cm.yaml # 修改 prometheus 配置文件 prome-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+)
[root@k8s-master01 11.3]# kubectl apply -f 3/2.prome-cm.yaml configmap/prometheus-config configured [root@k8s-master01 11.3]# kubectl get configmaps -n kube-ops NAME DATA AGE kube-root-ca.crt 1 47h prometheus-config 1 41h # 查看 prometheus 的 configmap ,确定更新后,触发重载 [root@k8s-master01 11.3]# kubectl get configmaps prometheus-config -n kube-ops -o yaml .......... [root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
通过浏览器访问,如果关机重启过,可以 kubectl get svc -n kube-ops 获取端口值,然后 192.168.66.11:NodePort 访问
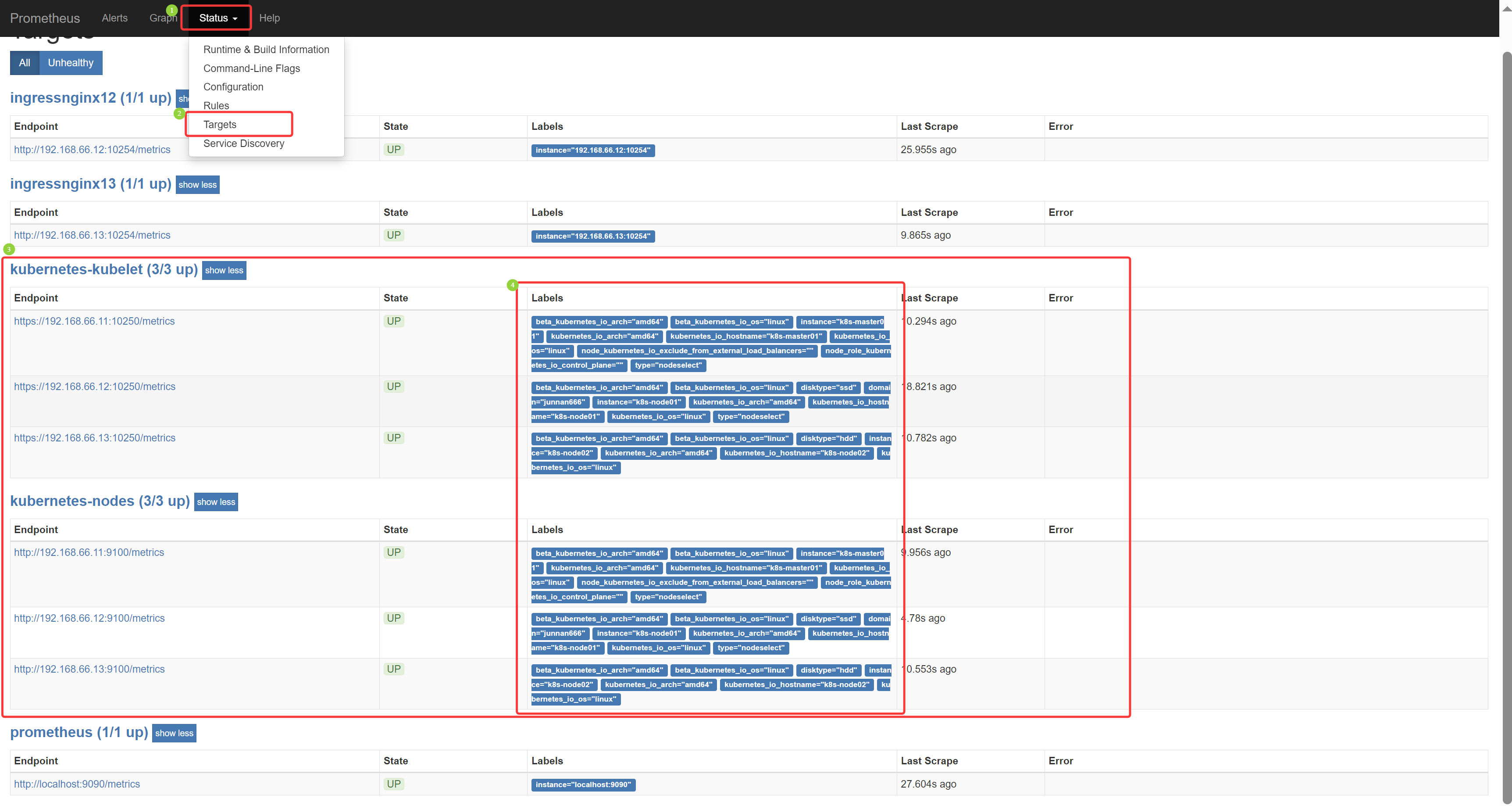
d.总结
目前通过 Prometheus 采集功能采集到:
Ingress-nginx 可以统计当前 Ingress 相关信息,例如:重写次数、总请求量 等
Node-exporter 可以监控当前每个节点物理资源使用情况,例如:cpu、内存、网络IO 等
Kubelet 可以监控当前 Pod 的基本概念,例如:Pod 成功、Pod 失败、running 状态 等
Prometheus 本身的监控指标
(4)容器监控 cAdvisor
说到容器监控想到 cAdvisor,前面说过 cAdvisor 已经内置在了 kubelet 组件中,不需要单独安装,cAdvisor 的数据路径为 /api/v1/nodes/<nodename>/proxy/metrics,同样这里使用 node 的服务发现模式,因为每个节点下面都有 kubelet
[root@k8s-master01 11.3]# cat 4/1.prome-cm.yaml # 修改 prometheus 配置文件,prome-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
任务名、通过 k8s API 接口自动发现:角色、节点 协议:https、证书配置:ca证书:ca 证书路径 token 文件: sa token 文件路径 重标签的配置:动作:标签、运算符方式:__meta_kubernetes_node_label_(.+) 即将所有节点的标签也添加到监控数据中 目标标签、替换地址(将 address 抓取后 替换成 kubernetes.default.svc:443 这种 Pod 内 基于 svc 的访问) 源标签:所有节点的名称、匹配(即匹配抓取所有节点的名称) 目标标签、替换成带有节点变量 的访问路径(即 k8s API 接口访问 metrics_path 的数据转发到 带有变量的路径)
kubernetes-kubelet 提供的是节点级别的整体状态和资源使用情况,而 kubernetes-cadvisor 则提供了更详细的容器级别的性能指标
[root@k8s-master01 11.3]# kubectl apply -f 4/1.prome-cm.yaml configmap/prometheus-config configured # 查看 prometheus 的 configmap ,确定更新后,触发重载 [root@k8s-master01 11.3]# kubectl get configmaps prometheus-config -n kube-ops -o yaml .......... [root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
通过浏览器访问,如果关机重启过,可以 kubectl get svc -n kube-ops 获取端口值,然后 192.168.66.11:NodePort 访问

(5)监控 ApiServer
监控 ApiServer 的请求频率、总请求量、ApiServer 消耗内存数、cpu资源 等
[root@k8s-master01 11.3]# cat 5/1.prome-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https
任务名、通过 k8s API 接口自动发现:角色、端点 协议:https、证书配置:ca证书:ca 证书路径 token 文件: sa token 文件路径 重标签的配置: 源标签:所有节点的名称空间、服务名、端点名 动作:保持 匹配:default.kubernetes.svc(即指定 默认名称空间下 kubernetes 的 svc,可以通过 kubectl get svc -n default 查看)
[root@k8s-master01 11.3]# kubectl apply -f 5/1.prome-cm.yaml configmap/prometheus-config configured # 查看 prometheus 的 configmap ,确定更新后,触发重载 [root@k8s-master01 11.3]# kubectl get configmaps prometheus-config -n kube-ops -o yaml .......... [root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
通过浏览器访问,如果关机重启过,可以 kubectl get svc -n kube-ops 获取端口值,然后 192.168.66.11:NodePort 访问
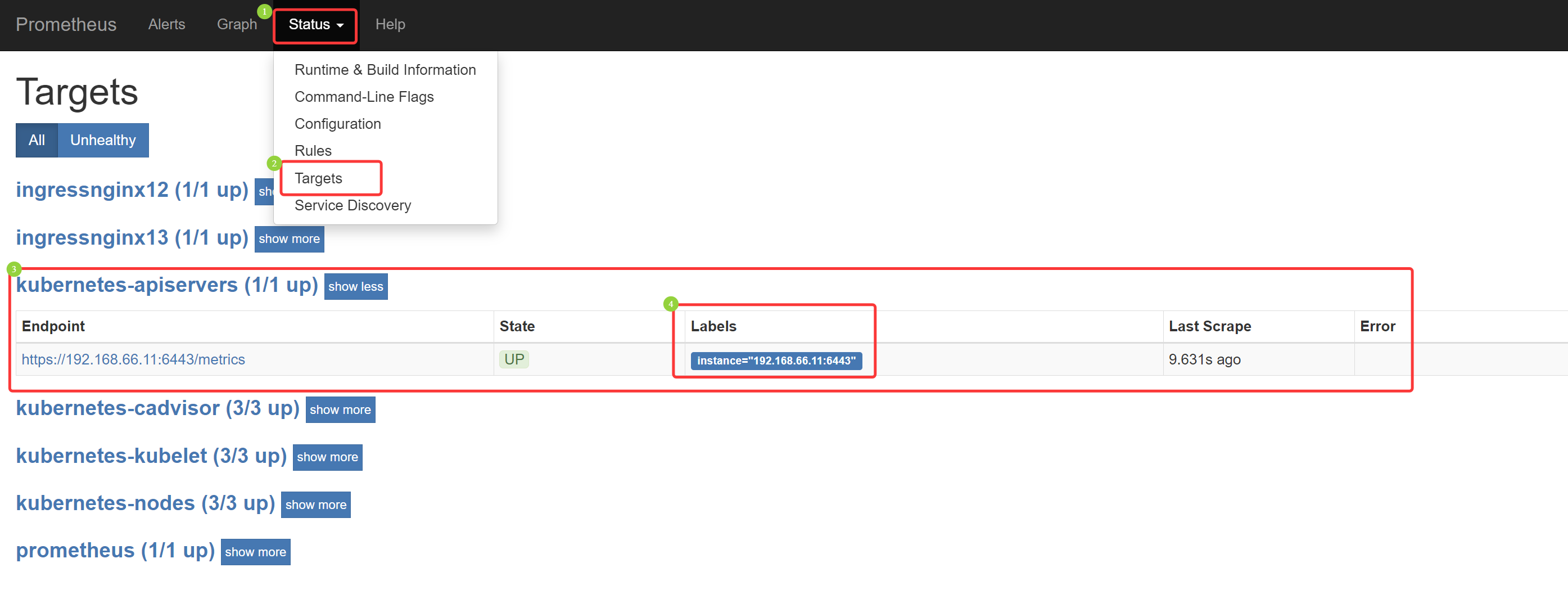
(6)监控 Service 自动启动
注意:上面每次添加都需要重新配置 configmap,随着监控 service 增多,重载次数将越来越多,因此可以配置 service 的描述信息有对应 key:value,就可以直接抓取日志到 Prometheus
[root@k8s-master01 11.3]# cat 6/1.prome-cm.yaml # 修改 prometheus,监控 Service apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name
任务名、通过 k8s API 接口自动发现:角色、端点
重标签的配置: 源标签:污点信息
源标签:协议 https
源标签:路径 修改成 metrics 路径、端点捕获后 修改端点信息、
源标签:添加 service 标签
源标签:名称空间替换
源标签:服务名替换
[root@k8s-master01 11.3]# kubectl apply -f 6/1.prome-cm.yaml configmap/prometheus-config configured # 查看 prometheus 的 configmap ,确定更新后,触发重载
[root@k8s-master01 11.3]# kubectl get configmaps prometheus-config -n kube-ops -o yaml .......... [root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
在 relabel_configs 中过滤 annotation 有 prometheus.io/scrape=true 的标签和标签值的 Service,就会抓取对应 service 的日志到 Prometheus
通过浏览器访问,如果关机重启过,可以 kubectl get svc -n kube-ops 获取端口值,然后 192.168.66.11:NodePort 访问
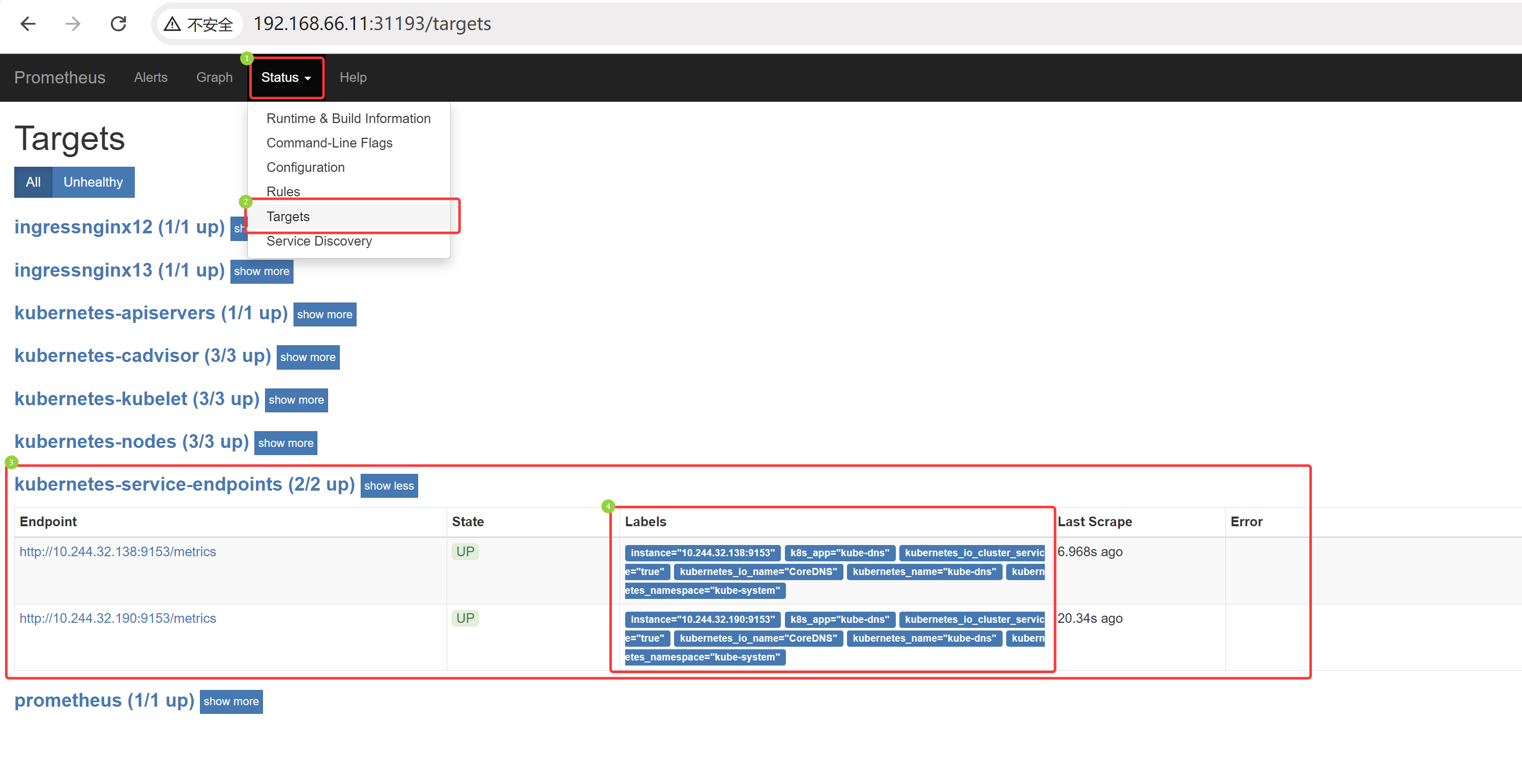
11.3.4 部署及监控 kube-state-metrics(7)
# 部署 kube-state-metrics,地址wget https://github.com/kubernetes/kube-state-metrics(老师课件中给带了) [root@k8s-master01 11.3]# pwd /root/11/11.3 [root@k8s-master01 11.3]# ls 7/kube-state-metrics-2.10.0/examples/standard/ cluster-role-binding.yaml cluster-role.yaml deployment.yaml service-account.yaml service.yaml [root@k8s-master01 11.3]# kubectl apply -f 7/kube-state-metrics-2.10.0/examples/standard/ clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created serviceaccount/kube-state-metrics created service/kube-state-metrics created [root@k8s-master01 11.3]# kubectl get pod -n kube-system --show-labels NAME READY STATUS RESTARTS AGE LABELS calico-kube-controllers-558d465845-bqxcd 1/1 Running 48 (76m ago) 57d k8s-app=calico-kube-controllers,pod-template-hash=558d465845 calico-node-8nxzh 1/1 Running 85 (76m ago) 85d controller-revision-hash=58666d59cc,k8s-app=calico-node,pod-template-generation=1 calico-node-rgspt 1/1 Running 85 (76m ago) 85d controller-revision-hash=58666d59cc,k8s-app=calico-node,pod-template-generation=1 calico-node-rxwq8 1/1 Running 86 (76m ago) 85d controller-revision-hash=58666d59cc,k8s-app=calico-node,pod-template-generation=1 calico-typha-5b56944f9b-l2d9z 1/1 Running 87 (76m ago) 85d k8s-app=calico-typha,pod-template-hash=5b56944f9b coredns-857d9ff4c9-ftpzf 1/1 Running 85 (76m ago) 85d k8s-app=kube-dns,pod-template-hash=857d9ff4c9 coredns-857d9ff4c9-pzjfv 1/1 Running 85 (76m ago) 85d k8s-app=kube-dns,pod-template-hash=857d9ff4c9 etcd-k8s-master01 1/1 Running 86 (76m ago) 85d component=etcd,tier=control-plane kube-apiserver-k8s-master01 1/1 Running 13 (76m ago) 13d component=kube-apiserver,tier=control-plane kube-controller-manager-k8s-master01 1/1 Running 87 (76m ago) 85d component=kube-controller-manager,tier=control-plane kube-proxy-fg4nf 1/1 Running 71 (76m ago) 73d controller-revision-hash=779547c8f9,k8s-app=kube-proxy,pod-template-generation=1 kube-proxy-frk9v 1/1 Running 69 (76m ago) 73d controller-revision-hash=779547c8f9,k8s-app=kube-proxy,pod-template-generation=1 kube-proxy-nrfww 1/1 Running 70 (76m ago) 73d controller-revision-hash=779547c8f9,k8s-app=kube-proxy,pod-template-generation=1 kube-scheduler-k8s-master01 1/1 Running 87 (76m ago) 85d component=kube-scheduler,tier=control-plane kube-state-metrics-885b7d5c8-pw9rb 1/1 Running 0 32s app.kubernetes.io/component=exporter,app.kubernetes.io/name=kube-state-metrics,app.kubernetes.io/version=2.10.0,pod-template-hash=885b7d5c8 # kube-state-metrics 默认是添加在 kube-system 的 service 中,没有添加 service 标签,需要添加标签
[root@k8s-master01 11.3]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE calico-typha ClusterIP 10.11.198.102 <none> 5473/TCP 85d kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP,9153/TCP 85d kube-state-metrics ClusterIP None <none> 8080/TCP,8081/TCP 7m29s
[root@k8s-master01 11.3]# cat 7/1.kube-state-metrics.yaml # 创建 kube-state-metrics 服务的 svc 文件,被监控,svc.yaml apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: 'true' prometheus.io/port: "8080" namespace: kube-system labels: app: kube-state-metrics name: kube-state-metrics-exporter spec: ports: - name: 80-8080 port: 80 protocol: TCP targetPort: 8080 selector: app.kubernetes.io/name: kube-state-metrics type: ClusterIP
3.元数据:描述信息:开启自动抓取(service 标签、标签值与上一个实验一致,所以会被自动抓取)、svc 端口、名称空间、标签:标签、标签值、svc 名 4.期望:端口:端口名、svc 端口、协议信息、目标 Pod 端口、选择器:标签、标签值、svc 类型
[root@k8s-master01 11.3]# kubectl apply -f 7/1.kube-state-metrics.yaml service/kube-state-metrics-exporter created
通过浏览器访问,如果关机重启过,可以 kubectl get svc -n kube-ops 获取端口值,然后 192.168.66.11:NodePort 访问
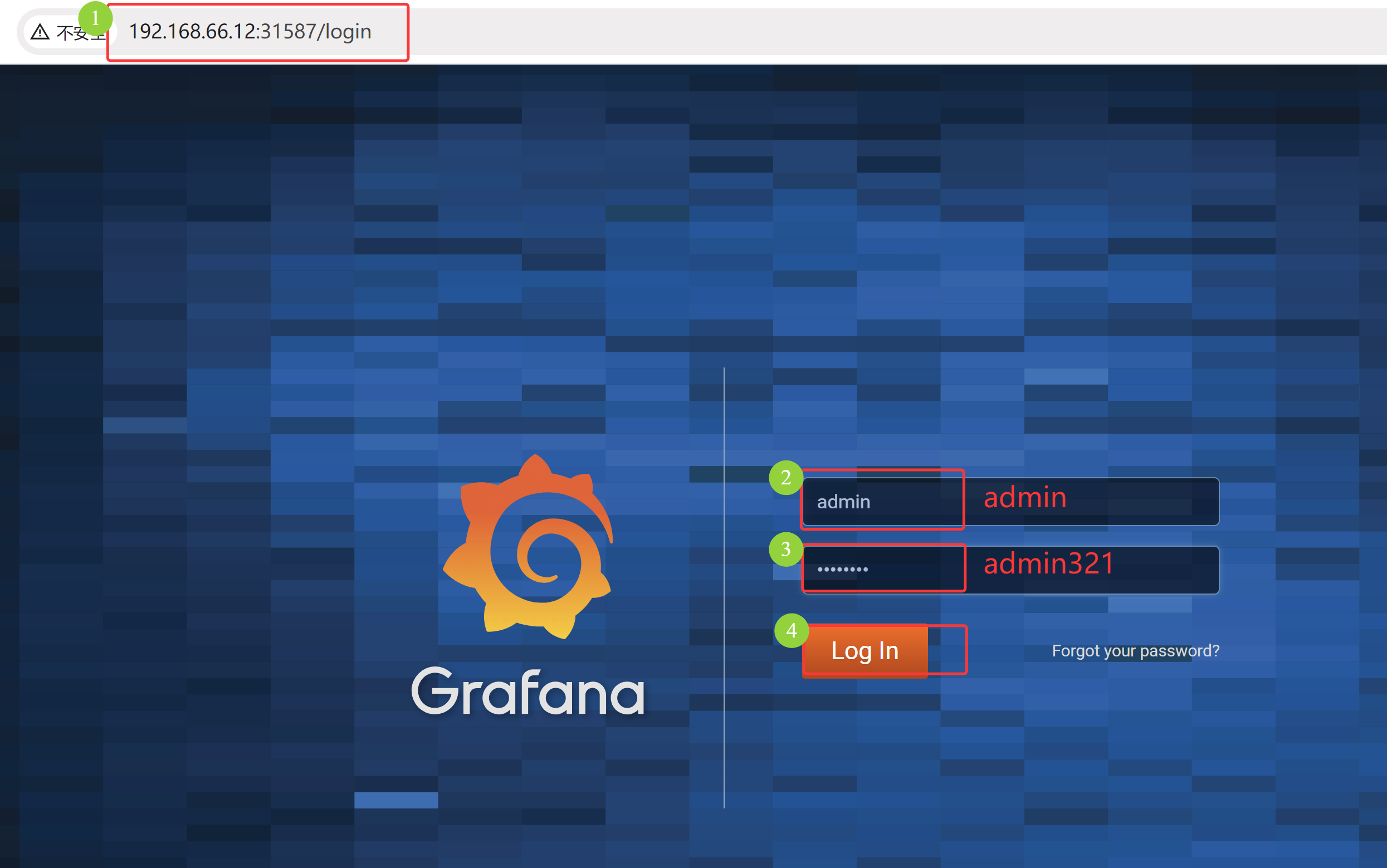
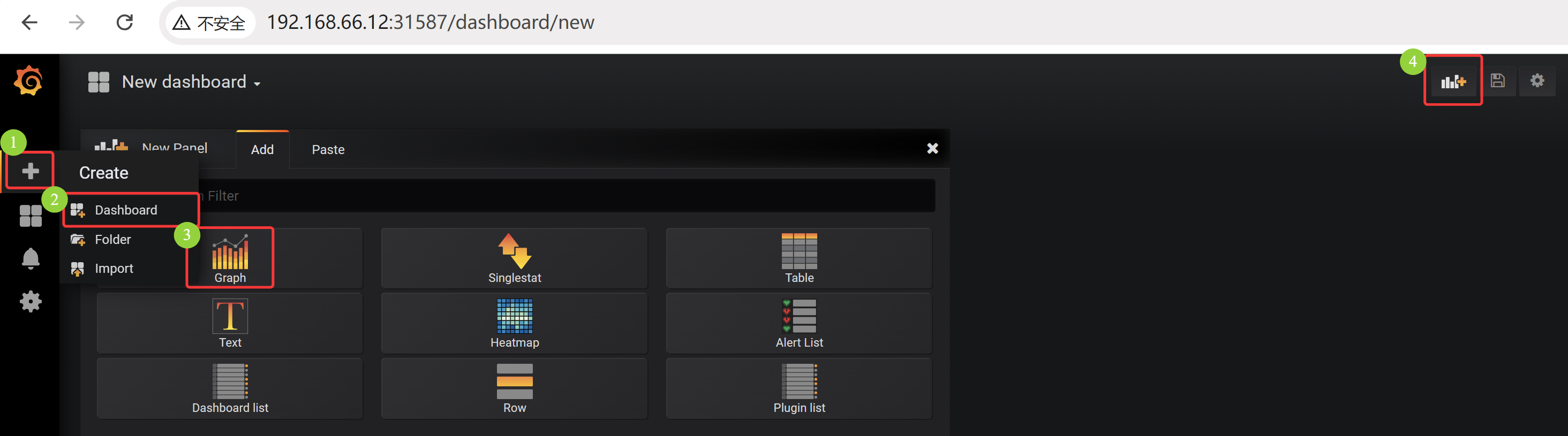
11.3.5 部署 Grafana 服务(8)
[root@k8s-master01 11.3]# cat 8/1.deployment.yaml # 创建 grafana 部署文件 apiVersion: apps/v1 kind: Deployment metadata: name: grafana namespace: kube-ops labels: app: grafana spec: revisionHistoryLimit: 10 selector: matchLabels: app: grafana template: metadata: labels: app: grafana spec: containers: - name: grafana image: grafana/grafana:5.3.4 imagePullPolicy: IfNotPresent ports: - containerPort: 3000 name: grafana env: - name: GF_SECURITY_ADMIN_USER value: admin - name: GF_SECURITY_ADMIN_PASSWORD value: admin321 readinessProbe: failureThreshold: 10 httpGet: path: /api/health port: 3000 scheme: HTTP initialDelaySeconds: 60 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 30 livenessProbe: failureThreshold: 3 httpGet: path: /api/health port: 3000 scheme: HTTP periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 resources: limits: cpu: 100m memory: 256Mi requests: cpu: 100m memory: 256Mi volumeMounts: - mountPath: /var/lib/grafana subPath: grafana name: storage securityContext: fsGroup: 472 runAsUser: 472 volumes: - name: storage persistentVolumeClaim: claimName: grafana
4.期望:保留历史版本、选择器:匹配标签:标签、标签值 Pod 模版:元数据:定义标签:标签、标签值 Pod期望:容器组:容器名、基于镜像版本、镜像拉取策略、定义端口:容器端口、端口名 定义环境变量:user 变量名、变量值、password 变量名、变量值 就绪探测 存活探测 资源限制:最大限制:cpu、内存、初始化限制:cpu、内存 卷挂载:挂载容器路径、声明绑定的卷目录(其他目录不绑定)、卷名 安全上下文:启动用户的组、启动用户 定义卷:卷名、基于 pvc 提供:pvc 名称
[root@k8s-master01 11.3]# cat 8/2.grafana-volume.yaml # 创建 grafana 存储 pv,grafana-volume.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: grafana namespace: kube-ops spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
4.期望:基于 storageClassName 名提供、读写模式、单节点读写、资源限制:申请:存储 1G(用于存储用户名密码,图表的格式)
[root@k8s-master01 11.3]# cat 8/3.grafana-svc.yaml # 创建 grafan svc 文件,grafana-svc.yaml apiVersion: v1 kind: Service metadata: name: grafana namespace: kube-ops labels: app: grafana spec: type: NodePort ports: - port: 3000 selector: app: grafana
4.期望:svc 类型:端口暴露、端口:3000、选择器:标签、标签值
# Grafana 目录是由服务器提供创建,权限不一定是正确的,由定时任务修改目录的权限范围
[root@k8s-master01 11.3]# cat 8/4.grafana-chown-job.yaml # 创建 job,调整 grafana 挂载目录权限,grafana-chown-job.yaml apiVersion: batch/v1 kind: Job metadata: name: grafana-chown namespace: kube-ops spec: template: spec: restartPolicy: Never containers: - name: grafana-chown command: ["chown", "-R", "472:472", "/var/lib/grafana"] image: busybox imagePullPolicy: IfNotPresent volumeMounts: - name: storage subPath: grafana mountPath: /var/lib/grafana volumes: - name: storage persistentVolumeClaim: claimName: grafana
4.期望:重启策略:永不、容器组:容器名、启动执行命令:目录授权操作、基于镜像版本、镜像拉取策略、卷绑定:绑定卷名、目标目录(不绑定其他目录)、绑定路径、定义卷:卷名:基于 pvc 提供、pvc 类名
[root@k8s-master01 11.3]# kubectl apply -f 8/1.deployment.yaml deployment.apps/grafana created [root@k8s-master01 11.3]# kubectl apply -f 8/2.grafana-volume.yaml persistentvolumeclaim/grafana created [root@k8s-master01 11.3]# kubectl apply -f 8/3.grafana-svc.yaml service/grafana created [root@k8s-master01 11.3]# kubectl apply -f 8/4.grafana-chown-job.yaml job.batch/grafana-chown created [root@k8s-master01 11.3]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE grafana-8695bfd76c-wd5b7 1/1 Running 0 3m7s grafana-chown-6zh2k 0/1 Completed 0 2m54s node-exporter-f6kvh 1/1 Running 4 (18m ago) 2d21h node-exporter-hft7m 1/1 Running 4 (18m ago) 2d21h node-exporter-rkzqg 1/1 Running 4 (18m ago) 2d21h prometheus-844847f5c7-4z6d6 1/1 Running 5 (18m ago) 3d16h # 查看运行用户验证目录授权 [root@k8s-master01 11.3]# kubectl exec -it grafana-8695bfd76c-wd5b7 -n kube-ops -- /bin/bash grafana@grafana-8695bfd76c-wd5b7:/usr/share/grafana$ id uid=472(grafana) gid=472(grafana) groups=472(grafana) grafana@grafana-8695bfd76c-wd5b7:/usr/share/grafana$ cd /var/lib/ grafana@grafana-8695bfd76c-wd5b7:/var/lib$ ls -ltr total 0 drwxr-xr-x 2 root root 6 Jun 26 2018 misc drwxr-xr-x 3 root root 40 Oct 11 2018 systemd drwxr-xr-x 2 root root 106 Oct 11 2018 pam drwxr-xr-x 1 root root 42 Nov 13 2018 apt drwxr-xr-x 2 root root 38 Nov 13 2018 ucf drwxr-xr-x 1 root root 93 Nov 13 2018 dpkg drwxrwxrwx 4 grafana grafana 50 Aug 22 06:01 grafana grafana@grafana-8695bfd76c-wd5b7:/var/lib$ exit exit # 查看 grafana 的 svc [root@k8s-master01 11.3]# kubectl get svc -n kube-ops NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.9.126.66 <none> 3000:31587/TCP 4m28s prometheus NodePort 10.15.109.180 <none> 9090:31193/TCP 3d16h
通过浏览器访问,如果关机重启过,可以 kubectl get svc -n kube-ops 获取端口值,然后 192.168.66.11:NodePort 访问
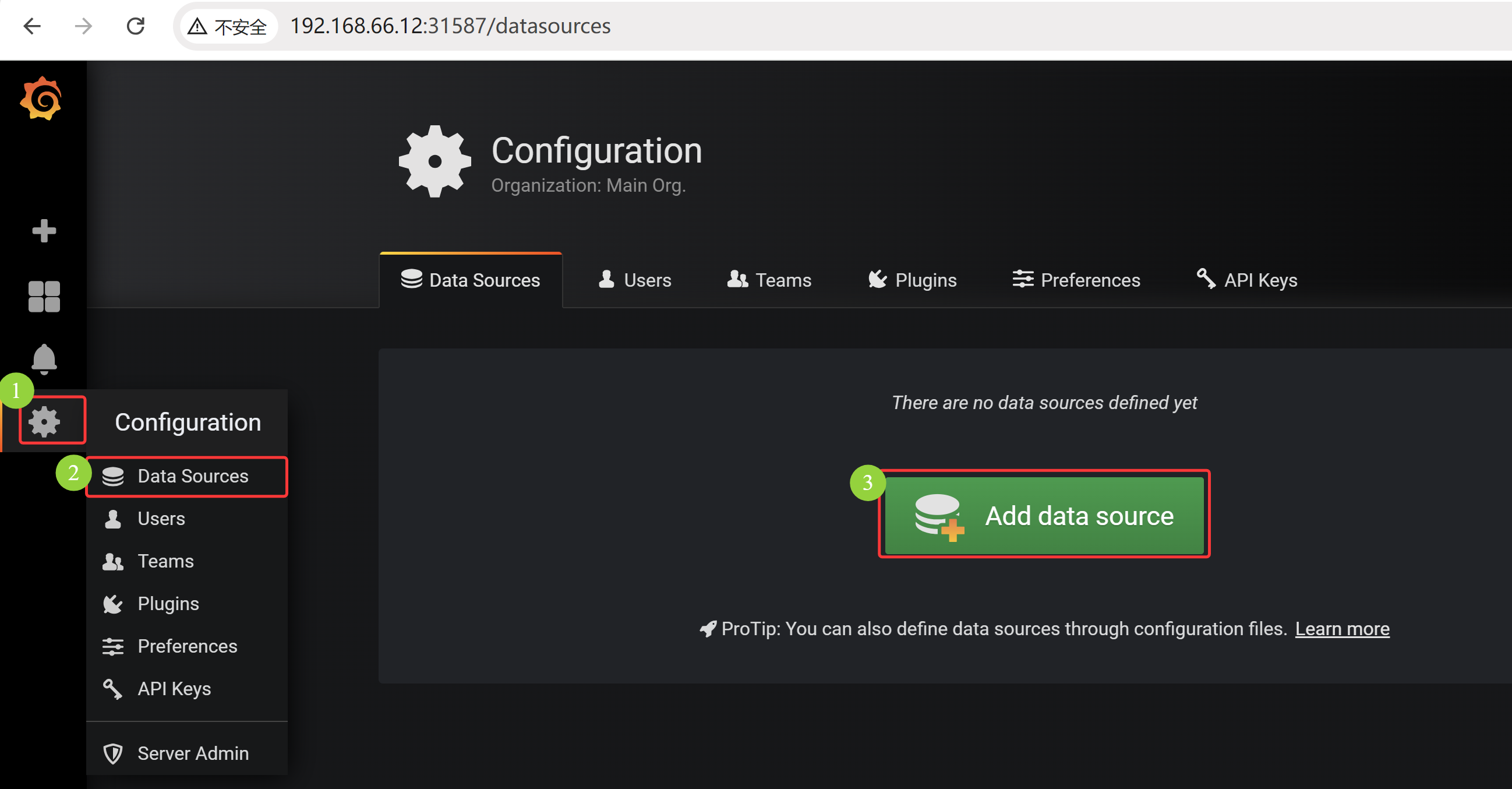
# 同在一个 namespace 下,可以基于 svc 同名称空间访问,也可以 加上名称空间访问(二者选其一) [root@k8s-master01 11.3]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE grafana-8695bfd76c-wd5b7 1/1 Running 0 79m grafana-chown-6zh2k 0/1 Completed 0 78m node-exporter-f6kvh 1/1 Running 4 (94m ago) 2d22h node-exporter-hft7m 1/1 Running 4 (94m ago) 2d22h node-exporter-rkzqg 1/1 Running 4 (94m ago) 2d22h prometheus-844847f5c7-4z6d6 1/1 Running 5 (94m ago) 3d17h [root@k8s-master01 11.3]# kubectl exec -it grafana-8695bfd76c-wd5b7 -n kube-ops -- /bin/bash grafana@grafana-8695bfd76c-wd5b7:/usr/share/grafana$ curl http://prometheus:9090 <a href="/graph">Found</a>. grafana@grafana-8695bfd76c-wd5b7:/usr/share/grafana$ curl http://prometheus.kube-ops.svc.cluster.local:9090 <a href="/graph">Found</a>. grafana@grafana-8695bfd76c-wd5b7:/usr/share/grafana$ exit exit
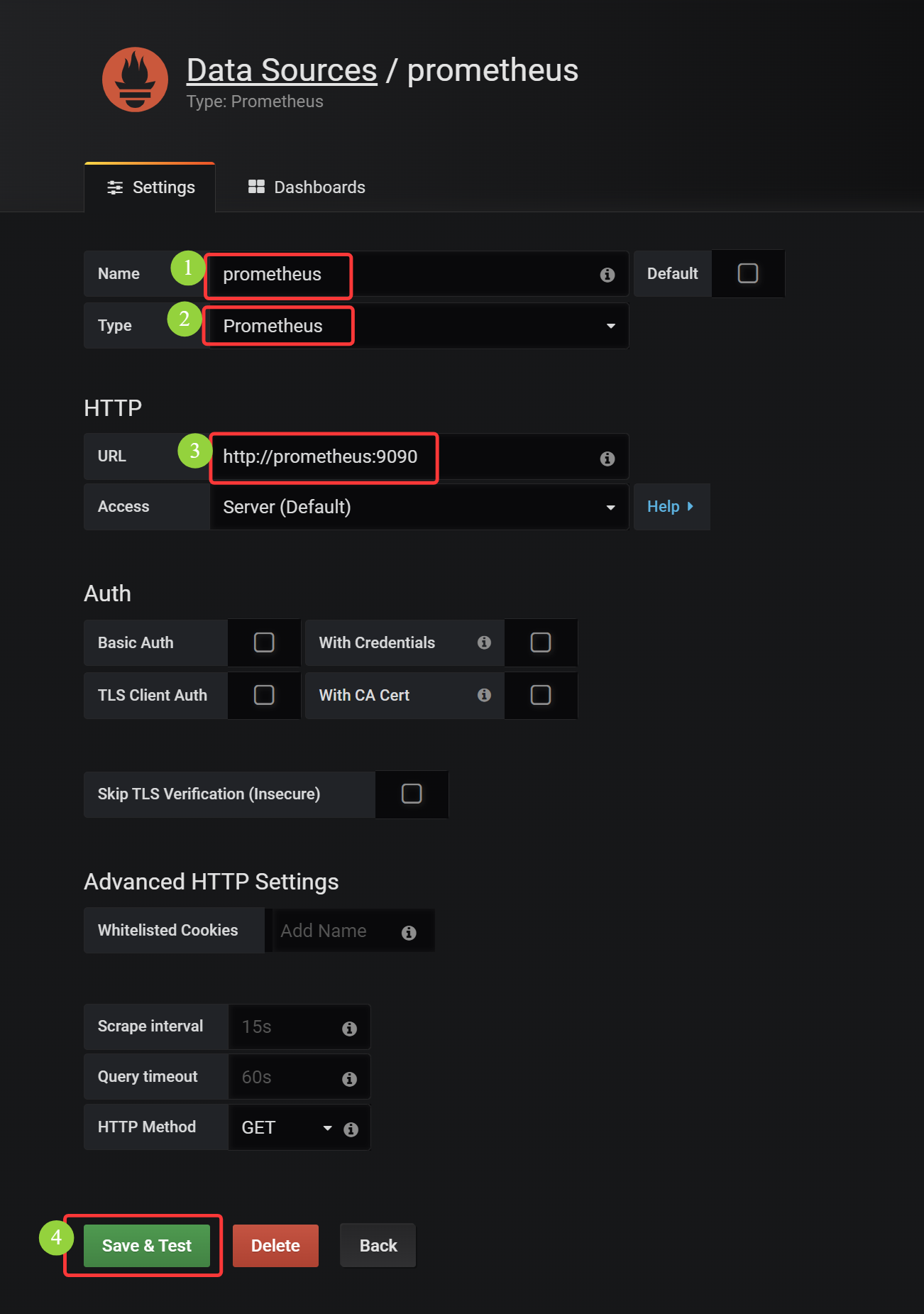
# prometheus 中的 PQL 同样适用于 Grafana Ingress-nginx 总访问量: sum(nginx_ingress_controller_nginx_process_requests_total) Ingress-nginx 各节点访问量:nginx_ingress_controller_nginx_process_requests_total Ingress-nginx 某节点访问量:nginx_ingress_controller_nginx_process_requests_total{instance="192.168.66.12:10254"}
点击 Dashboards -> home -> 点击自己命名的主题名,既可展示监控图表
点击 Create -> Import -> Upload .json File ->
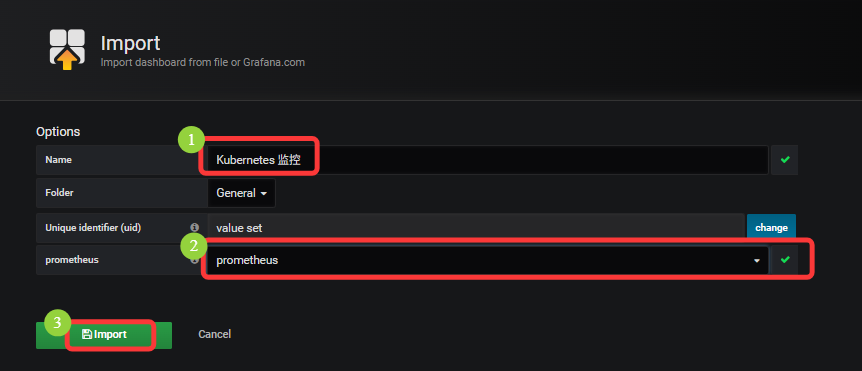
展示监控:
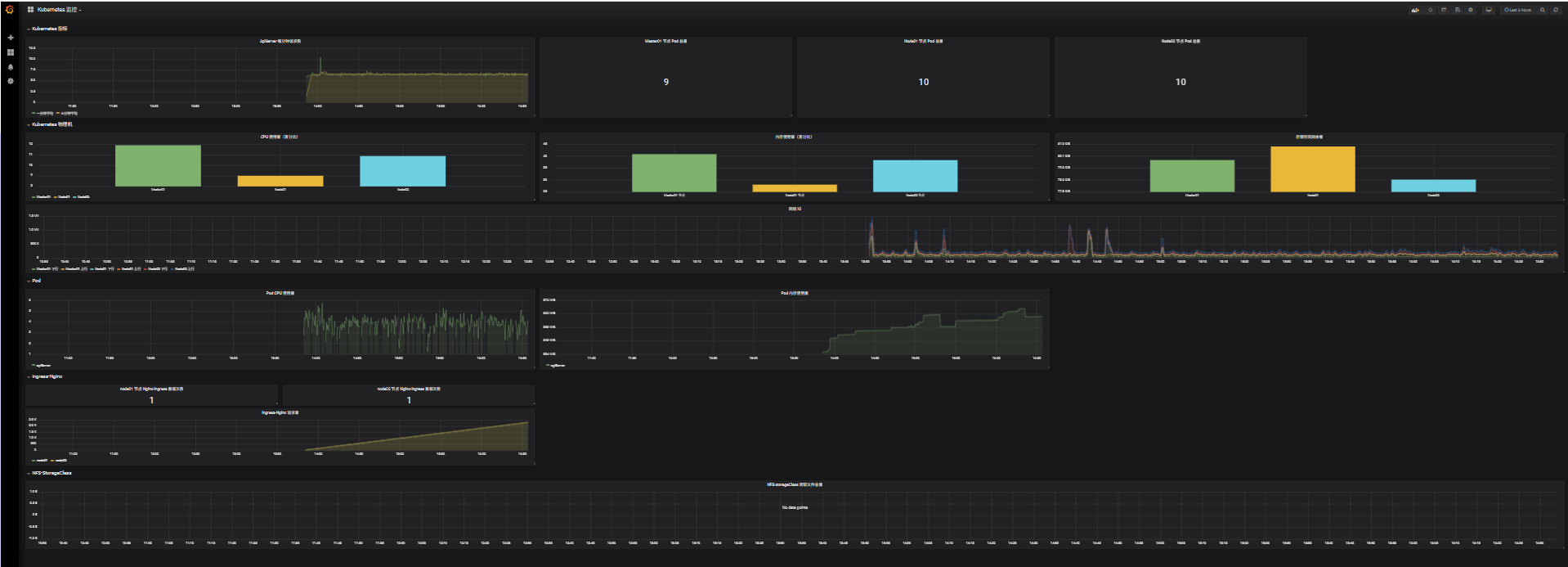
# 存储空间剩余量 ,可能由于操作系统版本不同,/dev/mapper/ 下文件名不同 [root@k8s-master01 11.3]# ll /dev/mapper/ total 0 crw------- 1 root root 10, 236 Aug 22 13:46 control lrwxrwxrwx 1 root root 7 Aug 22 13:46 rl_loaclhost-root -> ../dm-0 lrwxrwxrwx 1 root root 7 Aug 22 13:46 rl_loaclhost-swap -> ../dm-1 # 存储空间剩余量,修改 device 和 instance 的名称既可监控 node_filesystem_avail_bytes{device="/dev/mapper/rl_loaclhost-root",mountpoint="/rootfs",instance="k8s-master01"} # Ingress-Nginx 请求量 是因为 IP 和 Pod 名不对应 [root@k8s-master01 11.3]# kubectl get pod -n ingress -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ingress-nginx-controller-l4pws 1/1 Running 5 (172m ago) 3d17h 192.168.66.12 k8s-node01 <none> <none> ingress-nginx-controller-wdkqb 1/1 Running 5 (172m ago) 3d17h 192.168.66.13 k8s-node02 <none> <none> ingress-nginx-defaultbackend-89db9d699-f45t6 1/1 Running 5 (172m ago) 3d17h 10.244.85.242 k8s-node01 <none> <none> jaeger-ddb59666b-dd4vj 1/1 Running 27 (172m ago) 28d 10.244.85.235 k8s-node01 <none> <none> # Ingress-Nginx 请求量 ,修改 controller_pod instance job 信息即可监控 nginx_ingress_controller_nginx_process_requests_total{controller_class="k8s.io/ingress-nginx",controller_namespace="ingress",controller_pod="ingress-nginx-controller-l4pws",instance="192.168.66.12:10254",job="ingressnginx12"}
# NFS storageClass 读取文件总量 是因为目前 Prometheus 没有这个 PQL 函数语句
11.3.6 监控 metrics.server
a.概念
从 Kubernetes v1.8 开始,资源使用情况的监控可以通过 Metrics API 的形式获取,例如容器 CPU 和 内存使用率,这些资源使用情况可以由用户直接访问(例如,通过 kubectl top 查看资源使用情况)或集群中的控制器(例如 Horizontal Pod Autoscaler ,HPA集群自动扩缩容)使用来进行决策,具体的组件为 Metrics Server,用来替换之前的 heapster,heapster 从 v1.11 开始逐渐被废弃
Metrics-Server 是集群核心监控数据的聚合器,通俗地讲,它存储了集群中各节点的监控数据,并且提供了 API 以供分析和使用,Metrics-Server 作为一个 Deployment 对象默认部署在 Kubernetes 集群中,不过准确的说,它是 Dployment、Service、ClusterRole、ClusterRoleBinding、APIService、RoleBinging 等资源对象的综合体
b.部署
# metrics 的 资源清单 https://github.com/kubernetes-sigs/metrics-server kubectl apply -f https://github.com/kubernetes-sigs/metricsserver/releases/latest/download/components.yaml
[root@k8s-master01 11.3]# cat 9/1.components.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - nodes/metrics verbs: - get - apiGroups: - "" resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: https selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-preferred-address-types=InternalIP # InternalIP\Hostname\InternalDNS\ExternalDNS\ExternalIP, Hostname 默认的通过主机名通讯,InternalIP 需要显示设置后才能通过 IP 通讯 - --kubelet-insecure-tls # 如果不想设置 kubelet 的证书认证,可以通过此选项跳过认证 image: registry.k8s.io/metrics-server/metrics-server:v0.6.4 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 20 periodSeconds: 10 resources: requests: cpu: 100m memory: 200Mi securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
sa 认证信息
创建集群角色,做集群角色的权限控制
角色绑定
集群角色绑定
定义 svc
定义 deployment
APIService 安全认证
# 未启动资源监控前,无法获取资源使用情况 [root@k8s-master01 11.3]# kubectl top node error: Metrics API not available [root@k8s-master01 11.3]# kubectl top pod error: Metrics API not available [root@k8s-master01 11.3]# kubectl apply -f 9/1.components.yaml serviceaccount/metrics-server created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrole.rbac.authorization.k8s.io/system:metrics-server created rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created service/metrics-server created deployment.apps/metrics-server created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created [root@k8s-master01 11.3]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-558d465845-bqxcd 1/1 Running 49 (3h29m ago) 57d calico-node-8nxzh 1/1 Running 86 (3h29m ago) 86d calico-node-rgspt 1/1 Running 86 (3h29m ago) 86d calico-node-rxwq8 1/1 Running 87 (3h28m ago) 86d calico-typha-5b56944f9b-l2d9z 1/1 Running 88 (3h29m ago) 86d coredns-857d9ff4c9-ftpzf 1/1 Running 86 (3h29m ago) 86d coredns-857d9ff4c9-pzjfv 1/1 Running 86 (3h29m ago) 86d etcd-k8s-master01 1/1 Running 87 (3h29m ago) 86d kube-apiserver-k8s-master01 1/1 Running 14 (3h29m ago) 14d kube-controller-manager-k8s-master01 1/1 Running 88 (3h29m ago) 86d kube-proxy-fg4nf 1/1 Running 72 (3h29m ago) 74d kube-proxy-frk9v 1/1 Running 70 (3h28m ago) 74d kube-proxy-nrfww 1/1 Running 71 (3h29m ago) 74d kube-scheduler-k8s-master01 1/1 Running 88 (3h29m ago) 86d kube-state-metrics-885b7d5c8-pw9rb 1/1 Running 1 (3h28m ago) 18h metrics-server-75bbd6fd46-mb6lk 1/1 Running 0 96s # 资源监控启动后,可以获取节点和 Pod 的资源使用情况 [root@k8s-master01 11.3]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master01 265m 6% 2029Mi 57% k8s-node01 126m 6% 1542Mi 43% k8s-node02 136m 6% 1875Mi 53% [root@k8s-master01 11.3]# kubectl top pod -n kube-ops NAME CPU(cores) MEMORY(bytes) grafana-8695bfd76c-wd5b7 1m 85Mi node-exporter-f6kvh 2m 21Mi node-exporter-hft7m 2m 22Mi node-exporter-rkzqg 2m 23Mi prometheus-844847f5c7-4z6d6 10m 440Mi
c.监控原理图
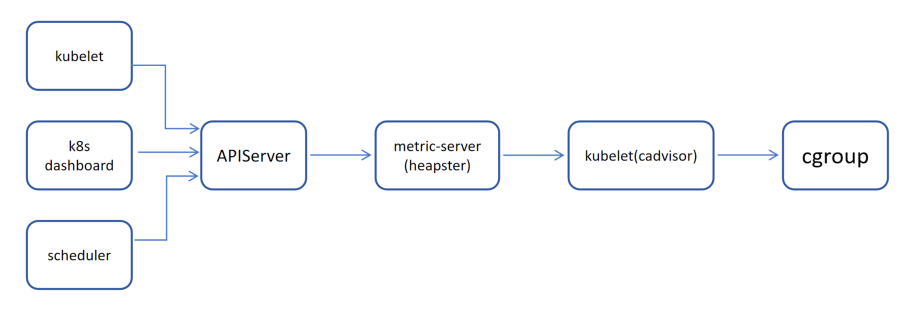
1.由 kubectl、k8s dashboard、scheduler 发起对 apiserver 发起接口的调用
2.apiserver 找到 metrics-server(或 heapster)的 service,这里如果找不到提示 (Metrics API not available)
3.metrics-server(或 heapster)的 Pod 去找 kubelet 节点的 cadvisor 获取节点和容器的资源使用情况
4.底层 cadvisor 是通过 cgroup 文件系统 来获取文件实际使用情况
11.3.7 Alertmanager 部署(10)
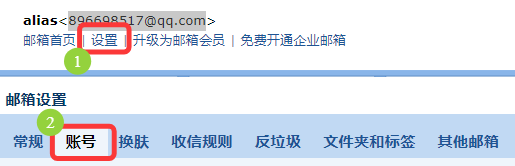
注意:这里使用的是 QQ邮箱,需要获取 QQ邮箱 的授权码
登录 QQ邮箱 -> 设置 -> 账号 -> 点击(POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务)下的 继续获取授权码 -> 发送短信验证 -> 页面获取授权码
[root@k8s-master01 11.3]# cat 10/1.alertmanager-conf.yaml apiVersion: v1 kind: ConfigMap metadata: name: alert-config namespace: kube-ops data: config.yml: |- global: # 在没有报警的情况下声明为已解决的时间 resolve_timeout: 5m # 配置邮件发送信息 smtp_smarthost: 'smtp.qq.com:465' smtp_from: '896698517@qq.com' smtp_auth_username: '896698517@qq.com' smtp_auth_password: 'eqkwunxlcdawbejd' smtp_hello: 'QQ.com' smtp_require_tls: false # 所有报警信息进入后的根路由,用来设置报警的分发策略 route: # 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面 group_by: ['alertname', 'cluster'] # 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。 group_wait: 30s # 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。 group_interval: 5m # 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们 repeat_interval: 5m # 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器 receiver: default # 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。 routes: - receiver: email group_wait: 10s match: team: node receivers: - name: 'default' email_configs: - to: '896698517@qq.com' send_resolved: true - name: 'email' email_configs: - to: '896698517@qq.com' send_resolved: true
[root@k8s-master01 11.3]# cat 10/2.prometheus-cm.yaml # 修改 prometheus 配置文件,prometheus-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"]
# 在 prometheus 中增加了 alertmanagers 的监控端口( alertmanager 与 prometheus 后面资源清单中部署在同一 Pod 内,所以可以回环接口获取信息)
[root@k8s-master01 11.3]# cat 10/3.prometheus-svc.yaml # 修改 prometheus service 文件, prometheus-svc.yaml apiVersion: v1 kind: Service metadata: name: prometheus namespace: kube-ops labels: app: prometheus spec: selector: app: prometheus type: NodePort ports: - name: web port: 9090 targetPort: http - name: altermanager port: 9093 targetPort: 9093
# Prometheus 同一 svc 名,增加了 altermanager 的端口暴露
[root@k8s-master01 11.3]# cat 10/4.promethus-alertmanager-deploy.yaml # 合并 altermanager 至 prometheus deploy 文件,promethus-alertmanager-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: prometheus namespace: kube-ops labels: app: prometheus spec: selector: matchLabels: app: prometheus template: metadata: labels: app: prometheus spec: serviceAccountName: prometheus containers: - name: alertmanager image: prom/alertmanager:v0.15.3 imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/config.yml" - "--storage.path=/alertmanager/data" ports: - containerPort: 9093 name: alertmanager volumeMounts: - mountPath: "/etc/alertmanager" name: alertcfg resources: requests: cpu: 100m memory: 256Mi limits: cpu: 100m memory: 256Mi - image: prom/prometheus:v2.4.3 name: prometheus command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能 - "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效 ports: - containerPort: 9090 protocol: TCP name: http volumeMounts: - mountPath: "/prometheus" subPath: prometheus name: data - mountPath: "/etc/prometheus" name: config-volume resources: requests: cpu: 100m memory: 512Mi limits: cpu: 100m memory: 512Mi securityContext: runAsUser: 0 volumes: - name: data persistentVolumeClaim: claimName: prometheus - configMap: name: prometheus-config name: config-volume - name: alertcfg configMap: name: alert-config
# 基于原 prometheus deployment 增加了 alertmanager
环境变量指定配置文件路径和名称
开放容器端口
卷绑定
资源限制
[root@k8s-master01 11.3]# kubectl apply -f 10/1.alertmanager-conf.yaml configmap/alert-config created [root@k8s-master01 11.3]# kubectl apply -f 10/2.prometheus-cm.yaml configmap/prometheus-config configured [root@k8s-master01 11.3]# kubectl apply -f 10/3.prometheus-svc.yaml service/prometheus configured [root@k8s-master01 11.3]# kubectl apply -f 10/4.promethus-alertmanager-deploy.yaml deployment.apps/prometheus configured # prometheus 中启动了 两个容器
[root@k8s-master01 11.3]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE grafana-8695bfd76c-wd5b7 1/1 Running 1 (6h25m ago) 25h grafana-chown-6zh2k 0/1 Completed 0 25h node-exporter-f6kvh 1/1 Running 5 (6h25m ago) 3d22h node-exporter-hft7m 1/1 Running 5 (6h25m ago) 3d22h node-exporter-rkzqg 1/1 Running 5 (6h25m ago) 3d22h prometheus-7ff947ccbd-j4f4r 2/2 Running 0 3m39s # 可以通过 端口 登录两个的 web 页面
[root@k8s-master01 11.3]# kubectl get svc -n kube-ops NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.9.126.66 <none> 3000:31587/TCP 25h prometheus NodePort 10.15.109.180 <none> 9090:31193/TCP,9093:31783/TCP 4d17h
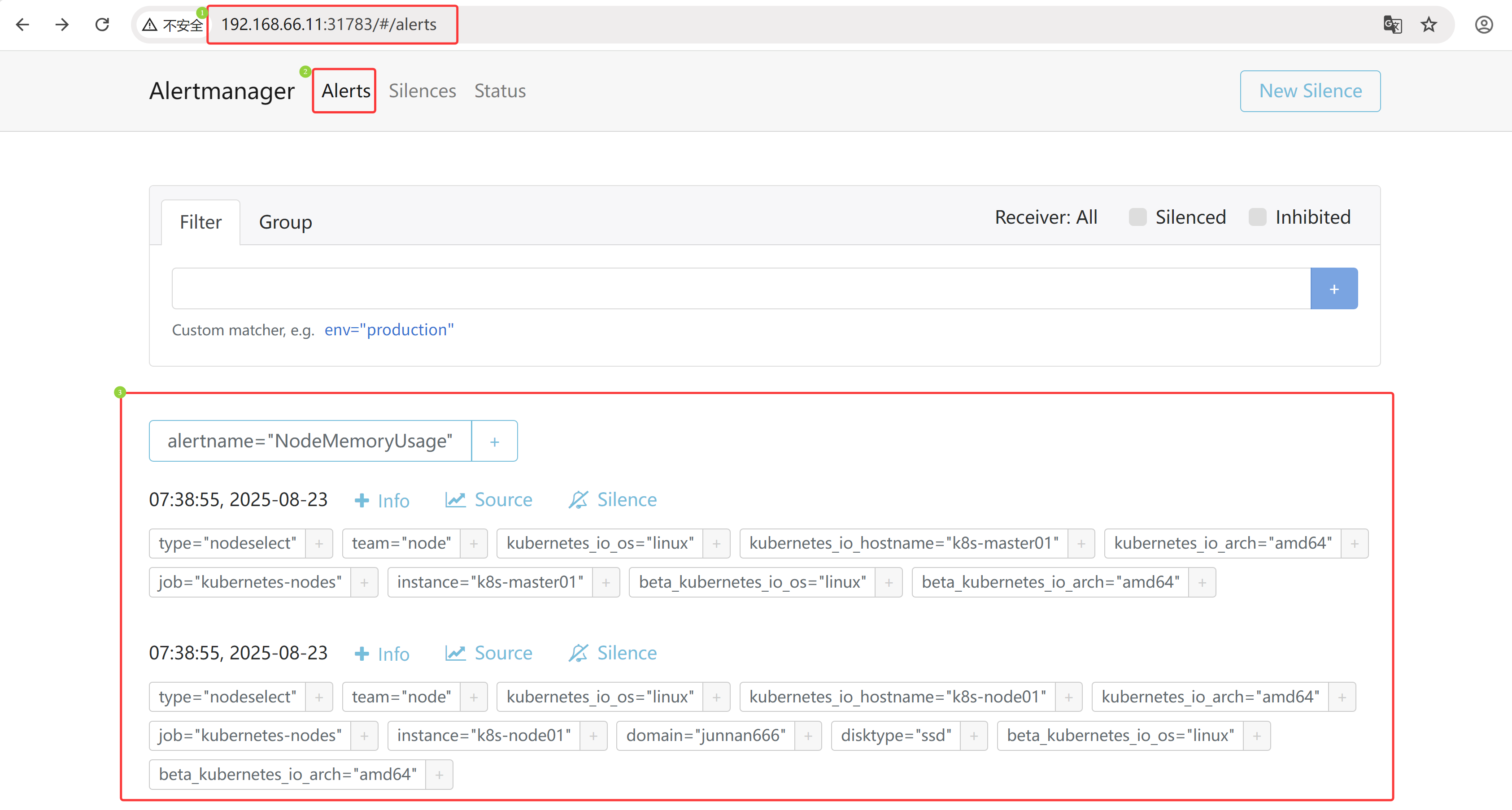
# 可以通过 192.168.66.11:31783 登录 alertmananger 管理端
[root@k8s-master01 11.3]# cat 10/5.prometheus-cm-test.yaml # 修改 prometheus cm,添加监控 mem 使用量,prometheus-cm-test.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: rules.yml: | groups: - name: test-rule rules: - alert: NodeMemoryUsage expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 2 for: 2m labels: team: node annotations: summary: "{{$labels.instance}}: High Memory usage detected" description: "{{$labels.instance}}: Memory usage is above 2% (current value is: {{ $value }}" prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] rule_files: - /etc/prometheus/rules.yml
[root@k8s-master01 11.3]# kubectl apply -f 10/5.prometheus-cm-test.yaml configmap/prometheus-config configured
[root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
QQ 邮箱接收到告警信息
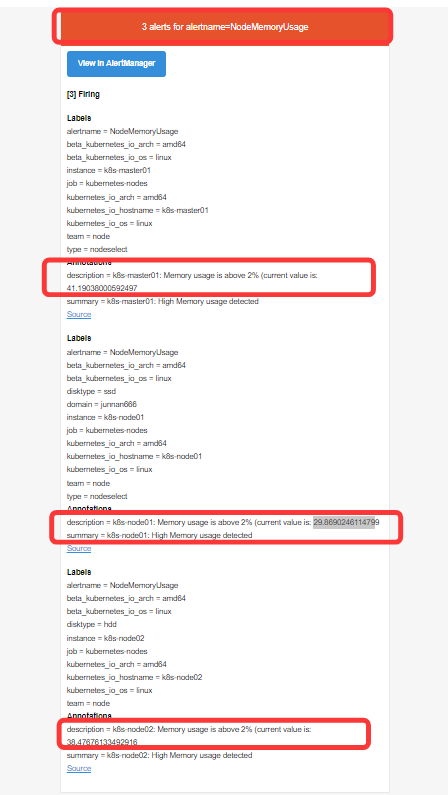
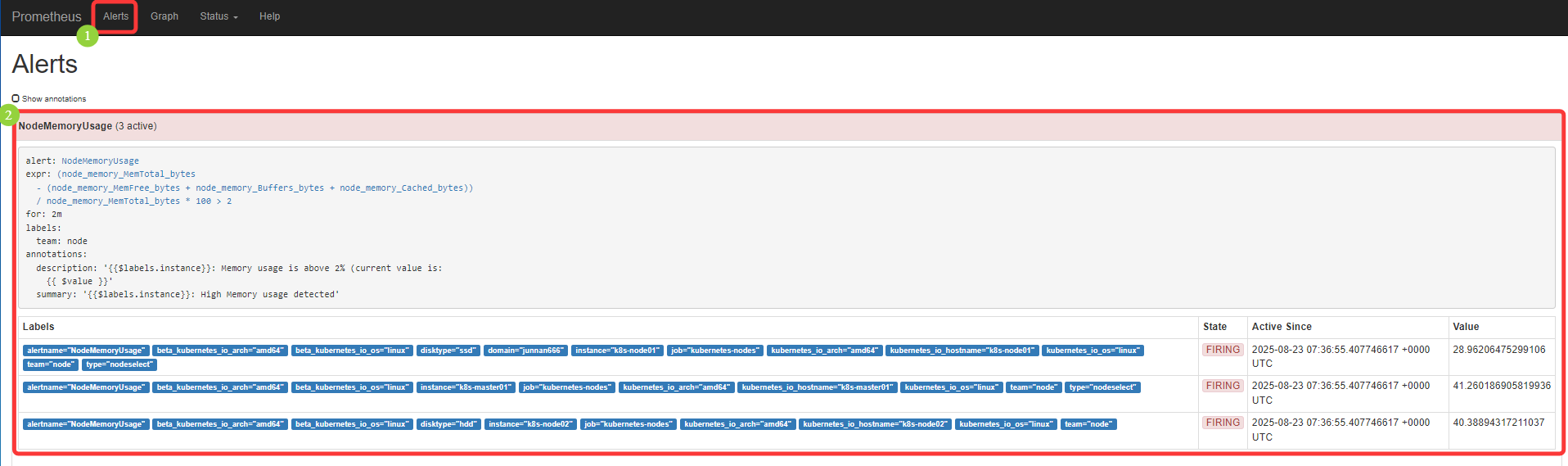
Promethues 中的告警信息
Alertmanager 中的告警信息
关闭 (POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务)下的 授权码功能
[root@k8s-master01 11.3]# cat 10/6.prometheus-cm-test.yaml # 删除监控 mem 项,prometheus-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: rules.yml: | groups: prometheus.yml: | global: scrape_interval: 30s scrape_timeout: 30s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'ingressnginx12' static_configs: - targets: ['192.168.66.12:10254'] - job_name: 'ingressnginx13' static_configs: - targets: ['192.168.66.13:10254'] - job_name: 'kubernetes-nodes' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] rule_files: - /etc/prometheus/rules.yml
# 消除实验影响
# 关闭告警功能,告警的邮箱地址等已取消 [root@k8s-master01 11.3]# kubectl apply -f 10/6.prometheus-cm-test.yaml configmap/prometheus-config configured [root@k8s-master01 11.3]# curl -X POST "http://10.15.109.180:9090/-/reload"
———————————————————————————————————————————————————————————————————————————
无敌小马爱学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号