
23.B站薪享宏福笔记——第八章 k8s 调度器
8 k8s 调度器
——— 调度器 kubernetes 中最核心的实现之一
8.1 调度器概念
——— 理解特性、使用特性
8.1.1 调度器 - 概念
Scheduler 是 Kubernetes 的调度器,主要的任务是把定义的 Pod 分配到集群的节点上。以下为随机分配示意图
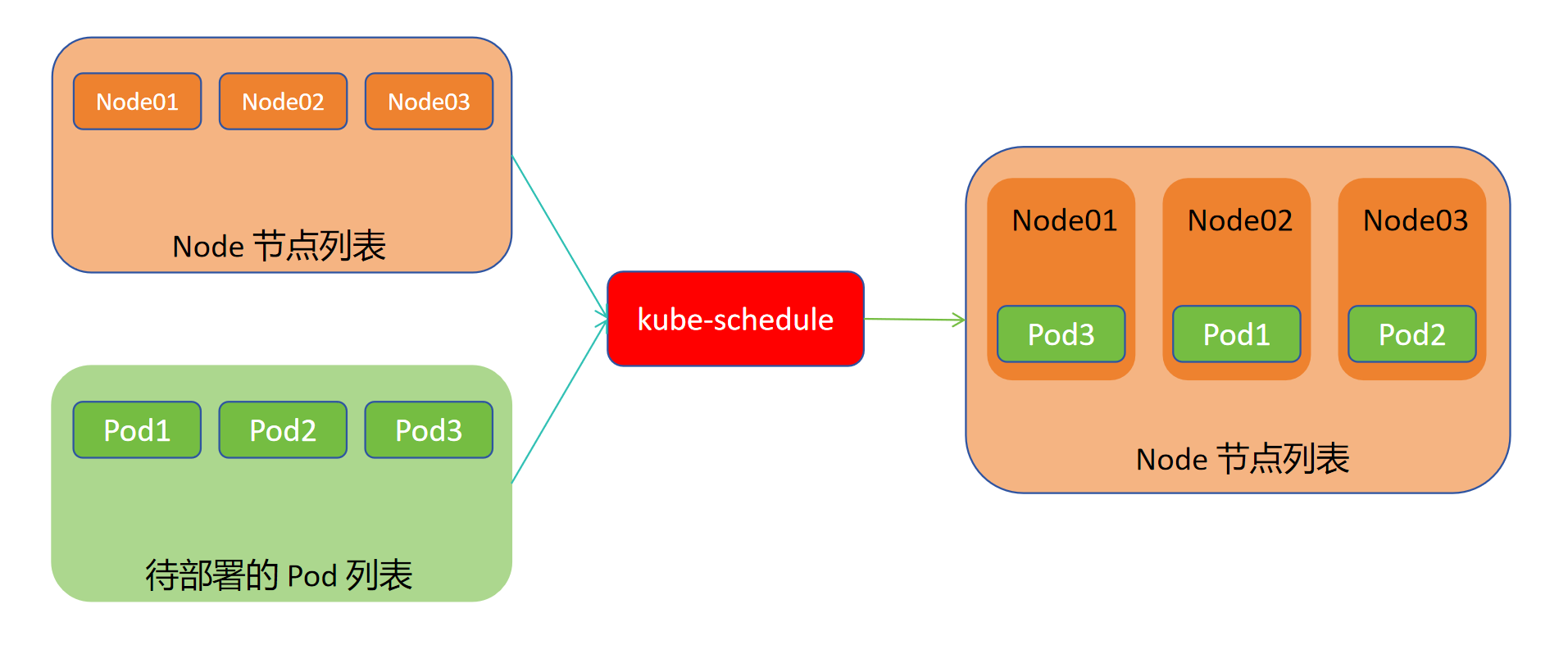
Scheduler 是作为单独的程序运行的(可以独立于集群外),启动之后会一直监听 API Server,获取 Pod.Spec.NodeName 为空的 Pod(未分配的 Pod),对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上
概念听起来是非常简单的,但有很多要考虑的问题:
公(ping)平:如何保证每个节点都能被分配资源
资源高效利用:集群所有资源最大化被使用(常见CPU、磁盘、内存、网络等)
效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作
灵活:允许用户根据自己的需求控制调度的逻辑
8.1.2 调度器 - 自定义调度器
除了 Kubernetes 自带的调度器 default-scheduler,也可以编写自己的调度器。通过 spec.schedulername 参数指定调度器的名字,可以为 pod 选择某个调度器进行调度。
比如下面的 pod 选择 my-scheduler 进行调度,而不是默认的 default-scheduler:
(1)模拟调度场景
# 目前没有创建 my-scheduler 调度器,所以 Pod 调度不成功
[root@k8s-master01 8.1]# cat 1.deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: myapp name: myapp spec: replicas: 1 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: schedulerName: my-scheduler containers: - image: myapp:v1.0 name: myapp
4.期望:副本数、标签选择器:匹配标签:标签、标签值、Pod 模板:Pod 元数据:Pod 标签、标签值、Pod 期望:调度器名称、容器组:基于镜像版本、容器名
[root@k8s-master01 8.1]# kubectl apply -f 1.deployment.yaml deployment.apps/myapp created [root@k8s-master01 8.1]# kubectl get pod NAME READY STATUS RESTARTS AGE myapp-7f575b6b8-qdzp5 0/1 Pending 0 2s [root@k8s-master01 8.1]# kubectl describe pod myapp-7f575b6b8-qdzp5 .......... Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: <none>
(2)自建调度器
# 在 kubernetes Master 节点开启 apiServer 的代理(堵塞住一个终端) [root@k8s-master01 ~]# kubectl proxy --port=8001 Starting to serve on 127.0.0.1:8001
[root@k8s-master01 8.1]# cat my-scheduler.sh #!/bin/bash SERVER='localhost:8001' while true; do for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName =="my-scheduler") | select(.spec.nodeName == null) |.metadata.name' | tr -d '"') do NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"')) NUMNODES=${#NODES[@]} CHOSEN=${NODES[$[ $RANDOM % $NUMNODES]]} curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1","kind":"Binding","metadata": {"name":"'$PODNAME'"},"target": {"apiVersion":"v1","kind": "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/ echo "Assigned $PODNAME to $CHOSEN" done sleep 1 done
1.使用代理的接口 2.获取指定为 my-scheduler 调度器且没有绑定节点的 Pod 名 3.获取当前节点列表 4.从节点中随机挑选一个节点 5.向 api-servier 发送,把 pod 和 node 节点的关联发送给 api-server 6.终端返回通知 pod 和 节点 的绑定关系 休眠一秒,继续抓取 pod,继续此操作(不具备 cpu 、内存、磁盘等判断逻辑等)
# 安装 jq ,在 epel-release 源中 [root@k8s-master01 8.1]# yum -y install epel-release [root@k8s-master01 8.1]# yum -y install jq [root@k8s-master01 8.1]# chmod +x my-scheduler.sh [root@k8s-master01 8.1]# ./my-scheduler.sh { "kind": "Status", "apiVersion": "v1", "metadata": {}, "status": "Success", "code": 201 }Assigned myapp-7f575b6b8-qdzp5 to k8s-node01 ^C # 调度成功,Pod 被绑定到节点,且开始运行 [root@k8s-master01 8.1]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-7f575b6b8-qdzp5 1/1 Running 0 23m 10.244.85.218 k8s-node01 <none> <none>
8.1.3 调度器 - 过程
调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为 预选;然后对通过的节点按照优先级排序,这个是 优选;最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误(比预选满足多,则进行优选,刚达到预选则符合预选都会调度,预选都不满足则不进行调度,比如3个Pod,预选节点符合3个以上,开始优选、预选刚好3个节点,则每个节点都调度、预选少于3个节点,则不能使Pod完全调度或不调度)
(1)预选(各版本一直更新中.....)
PodFitsResources:节点上剩余的资源是否大于 pod 请求的资源
PodFitsHost:如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配
PodFitsHostPorts:节点上已经使用的 port 是否和 pod 申请的 port 冲突(nodeport 物理机)
PodSelectorMatches:过滤掉和 pod 指定的 label 不匹配的节点
NoDiskConflict:已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非他们都是只读
(2)优选
如果在 预选 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度(调度频率越来越慢),直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,则继续 优选 ,过程:按照优先级大小对节点排序
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)
这些优先级选项包括:
LeastRequestedPriority:通过计算 CPU 和 Memory 的使用率来决定权重,使用率越低权重越高。换句话说,这个优先级指标倾向于资源使用比例更低的节点
BalancedResourceAllocation:节点上 CPU 和 Memory 使用率越接(jin)近,权重越高。这个应该和上面一起使用,不应该单独使用(例如:node01节点内存使用90,磁盘使用10,node02节点内存使用50,磁盘使用50,两个节点(ping)平均值都是50,但node01相对值80,node02相对值0,所以 node02 更被倾向于调度)
ImageLocalityPriority:倾向于已经有所使用镜像的节点,镜像总大小值越大,权重越高
8.1.4 调度器 - 综合
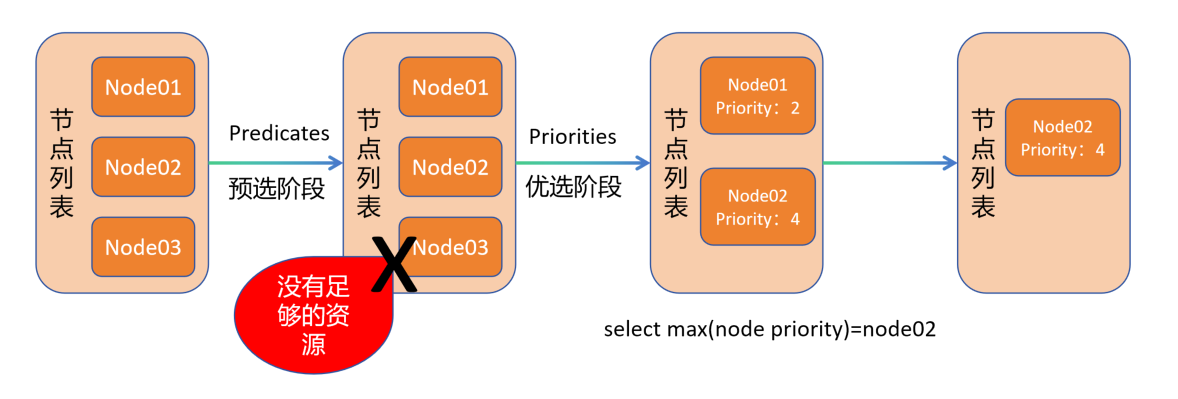
1.Pod 被调度前,kube-schedule 罗列了一个节点列表,node01、node02、node03进入预选
2.node03 因为资源不足预选时被排除节点列表,node01、node02 符合要求
3.开始进入优选,node01权重为2,node02权重为4,通过权重最大算法,node02 与 pod 进行绑定关联
8.2 亲和性
——— 一种调度的偏好特性
8.2.1 节点亲和性
(1)pod.spec.affinity.nodeAffinity
[root@k8s-master01 ~]# kubectl explain pod.spec.affinity.nodeAffinity KIND: Pod VERSION: v1 FIELD: nodeAffinity <NodeAffinity> DESCRIPTION: Describes node affinity scheduling rules for the pod. Node affinity is a group of node affinity scheduling rules. FIELDS:
软性策略(最好在一起,迫不得已不能也就算了,想和张三做同桌,做不成也得上学) preferredDuringSchedulingIgnoredDuringExecution <[]PreferredSchedulingTerm> The scheduler will prefer to schedule pods to nodes that satisfy the affinity expressions specified by this field, but it may choose a node that violates one or more of the expressions. The node that is most preferred is the one with the greatest sum of weights, i.e. for each node that meets all of the scheduling requirements (resource request, requiredDuringScheduling affinity expressions, etc.), compute a sum by iterating through the elements of this field and adding "weight" to the sum if the node matches the corresponding matchExpressions; the node(s) with the highest sum are the most preferred. 硬性策略(必须在一起,宁死不屈,必须每科都合格,才能拿毕业证) requiredDuringSchedulingIgnoredDuringExecution <NodeSelector> If the affinity requirements specified by this field are not met at scheduling time, the pod will not be scheduled onto the node. If the affinity requirements specified by this field cease to be met at some point during pod execution (e.g. due to an update), the system may or may not try to eventually evict the pod from its node.
(2)节点亲和性 - 软策略
[root@k8s-master01 8]# cat 2.preferred.yaml apiVersion: v1 kind: Pod metadata: name: node-affinity-preferred labels: app: node-affinity-preferred spec: containers: - name: node-affinity-preferred-pod image: myapp:v1.0 affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: domain operator: In values: - junnan666
4.Pod期望:容器组:容器名、基于镜像版本、亲和性:节点亲和性:软策略:权重、亲和类型:匹配运算符:key 值、运算符、values 值
[root@k8s-master01 8]# kubectl get node --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= k8s-node01 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux k8s-node02 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux [root@k8s-master01 8]# kubectl apply -f 2.preferred.yaml pod/node-affinity-preferred created # 软策略是希望,达不成希望该启动也得启动 [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-affinity-preferred 1/1 Running 0 2m8s 10.244.85.220 k8s-node01 <none> <none> # 执行以下命令,node01 和 node02 部署的 pod 次数应该接(jin)近持(ping)平(也可能某一个cpu、内存、磁盘等占用高导致权重低) [root@k8s-master01 8]# for i in `seq 20`;do kubectl delete -f 2.preferred.yaml;kubectl apply -f 2.preferred.yaml;kubectl get pod -o wide ;done node01 10次 node02 10次 # 给 node01 节点打上标签,再次执行循环命令,每次调度都是调度到 node01 节点 # 因为之前希望最好调度到有 junnan666 标签的节点上,没有这个标签,那该启动也得启动,node01 和 node02 谁启动都一样 # 但是现在 node01 有这个标签的节点出现了,那么每次都尽可能往这个带有符合标签的节点上调度 [root@k8s-master01 8]# kubectl label node k8s-node01 domain=junnan666 node/k8s-node01 labeled [root@k8s-master01 8]# kubectl get node --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= k8s-node01 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,domain=junnan666,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux k8s-node02 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux [root@k8s-master01 8]# for i in `seq 20`;do kubectl delete -f 2.preferred.yaml;kubectl apply -f 2.preferred.yaml;kubectl get pod -o wide ;done node01 20次
# 举例:
运行一个数据库,有一个节点是 SSD 固态硬盘,其他节点为机械硬盘,增加软策略,使之尽可能调度到带有 SSD固态硬盘的节点上,这样即使带有 SSD固态硬盘的节点因内存、cpu、磁盘等资源不足或损坏,数据库仍能到带有机械硬盘的节点上运行。
(3)节点亲和性 - 硬策略
[root@k8s-master01 8]# cat 3.required.yaml apiVersion: v1 kind: Pod metadata: name: node-affinity-required labels: app: node-affinity-required spec: containers: - name: node-affinity-required-pod image: myapp:v1.0 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-node04
4.Pod 期望:容器组:容器名、基于镜像版本、亲和性:节点亲和:硬亲和:节点选择器:匹配运算符:key 值、运算符、values 值
# 找不到 node04 节点就不进行调度 [root@k8s-master01 8]# kubectl apply -f 3.required.yaml pod/node-affinity-required created [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-affinity-required 0/1 Pending 0 6s <none> <none> <none> <none> [root@k8s-master01 8]# kubectl describe pod node-affinity-required .......... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 13s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 node(s) didn't match Pod's node affinity/selector. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling. [root@k8s-master01 8]# kubectl get node --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= k8s-node01 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,domain=junnan666,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux k8s-node02 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux
[root@k8s-master01 8]# cat 4.required.new.yaml apiVersion: v1 kind: Pod metadata: name: node-affinity-required labels: app: node-affinity-required spec: containers: - name: node-affinity-required-pod image: myapp:v1.0 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: In values: - ssd # 硬亲和不符合标签不调度,修改节点标签,当有符合的节点后,只调度符合的节点进行预选 [root@k8s-master01 8]# kubectl label node k8s-node01 disktype=ssd node/k8s-node01 labeled [root@k8s-master01 8]# kubectl label node k8s-node02 disktype=hdd node/k8s-node02 labeled [root@k8s-master01 8]# kubectl get node --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= k8s-node01 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,domain=junnan666,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux k8s-node02 Ready <none> 27d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=hdd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux [root@k8s-master01 8]# for i in `seq 20`;do kubectl delete -f 4.required.new.yaml;kubectl apply -f 4.required.new.yaml;kubectl get pod -o wide ;done node01 20次
8.2.2 Pod 亲和性
(1)pod.spec.affinity.podAffinity
[root@k8s-master01 8]# kubectl explain pod.spec.affinity.podAffinity KIND: Pod VERSION: v1 FIELD: podAffinity <PodAffinity> DESCRIPTION: Describes pod affinity scheduling rules (e.g. co-locate this pod in the same node, zone, etc. as some other pod(s)). Pod affinity is a group of inter pod affinity scheduling rules. FIELDS: preferredDuringSchedulingIgnoredDuringExecution <[]WeightedPodAffinityTerm> The scheduler will prefer to schedule pods to nodes that satisfy the affinity expressions specified by this field, but it may choose a node that violates one or more of the expressions. The node that is most preferred is the one with the greatest sum of weights, i.e. for each node that meets all of the scheduling requirements (resource request, requiredDuringScheduling affinity expressions, etc.), compute a sum by iterating through the elements of this field and adding "weight" to the sum if the node has pods which matches the corresponding podAffinityTerm; the node(s) with the highest sum are the most preferred. requiredDuringSchedulingIgnoredDuringExecution <[]PodAffinityTerm> If the affinity requirements specified by this field are not met at scheduling time, the pod will not be scheduled onto the node. If the affinity requirements specified by this field cease to be met at some point during pod execution (e.g. due to a pod label update), the system may or may not try to eventually evict the pod from its node. When there are multiple elements, the lists of nodes corresponding to each podAffinityTerm are intersected, i.e. all terms must be satisfied.
(2)Pod亲和性 - 软策略
[root@k8s-master01 8]# cat 5.perferred.yaml apiVersion: v1 kind: Pod metadata: name: pod-aff-prefer labels: app: pod-aff spec: containers: - name: myapp image: myapp:v1.0 affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - pod-1 topologyKey: kubernetes.io/hostname
4.Pod 期望:容器组:容器名、基于镜像版本、亲和性:pod亲和性:软策略:权重(必须做选择时,谁的权重更高)、pod亲和性运算:匹配标签:标签匹配符:key 值、运算符、values 符、拓扑域 拓扑域:拓扑域帮助 Kubernetes 理解节点之间的拓扑关系,比如哪些节点在同一机房、同一机架或同一可用区。Pod 先匹配标签key/values,然后匹配拓扑域,再进行预选、优选
# 因为是 pod 软亲和,所以即使没有亲和的 pod-1,仍能启动,删除创建亲和策略的 pod-1。 [root@k8s-master01 8]# kubectl apply -f 5.perferred.yaml pod/pod-aff-prefer created [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-aff-prefer 1/1 Running 0 5s 10.244.85.241 k8s-node01 <none> <none> [root@k8s-master01 8]# kubectl delete -f 5.perferred.yaml pod "pod-aff-prefer" deleted [root@k8s-master01 8]# cat test.yaml apiVersion: v1 kind: Pod metadata: name: pod-demo namespace: default labels: app: pod-1 spec: containers: - name: myapp-1 image: myapp:v1.0 [root@k8s-master01 8]# kubectl apply -f test.yaml pod/pod-demo created [root@k8s-master01 8]# kubectl get pod -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS pod-demo 1/1 Running 0 12s 10.244.85.246 k8s-node01 <none> <none> app=pod-1 [root@k8s-master01 8]# kubectl get node k8s-node02 --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-node02 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=hdd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux # 因为有亲和的策略,所以经过循环,每次 pod-aff-prefer 都首先匹配有 pod-1 标签的 pod 的节点,再匹配符合拓扑域的节点,因为节点拓扑域相同,不受限制,所以每次都与 pod-demo 部署在同一节点 [root@k8s-master01 8]# for i in `seq 20`;do kubectl apply -f 5.perferred.yaml;kubectl get pod -o wide;kubectl delete -f 5.perferred.yaml;done pod/pod-aff-prefer created NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-aff-prefer 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none> pod-demo 1/1 Running 0 82s 10.244.85.246 k8s-node01 <none> <none> pod "pod-aff-prefer" deleted
........
(3)Pod亲和性 - 硬策略
[root@k8s-master01 8]# cat 6.required.yaml apiVersion: v1 kind: Pod metadata: name: pod-aff-req labels: app: pod-aff-req spec: containers: - name: pod-aff-req-c image: myapp:v1.0 affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - pod-1 topologyKey: kubernetes.io/hostname
4.Pod 期望:容器组:容器名、基于镜像版本、亲和性:pod 亲和性:硬策略:标签选择:匹配运算符:key 值、运算符、values 值、拓扑域
[root@k8s-master01 8]# kubectl apply -f 6.required.yaml pod/pod-aff-req created [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-aff-req 0/1 Pending 0 9s <none> <none> <none> <none> [root@k8s-master01 8]# kubectl describe pod pod-aff-req .......... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 23s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 node(s) didn't match pod affinity rules. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
# test.yaml 与前面pod软亲和 yaml 文件一致 [root@k8s-master01 8]# kubectl apply -f test.yaml pod/pod-demo created # 之前 pod-aff-req 一直是 pending 状态,当有 pod-1 标签的 pod-demo 出现后,pod-aff-req 也启动到与他相同的 node02 节点 [root@k8s-master01 8]# kubectl get pod -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS pod-aff-req 1/1 Running 0 7m42s 10.244.58.218 k8s-node02 <none> <none> app=pod-aff-req pod-demo 1/1 Running 0 11s 10.244.58.215 k8s-node02 <none> <none> app=pod-1 [root@k8s-master01 8]# for i in `seq 20`;do kubectl delete -f 6.required.yaml;kubectl apply -f 6.required.yaml;kubectl get pod -o wide ;done pod "pod-aff-req" deleted pod/pod-aff-req created NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-aff-req 0/1 ContainerCreating 0 0s <none> k8s-node02 <none> <none> pod-demo 1/1 Running 0 3m20s 10.244.58.215 k8s-node02 <none> <none> pod "pod-aff-req" deleted ........
8.2.3 Pod 反亲和性
(1)pod.spec.affinity.podAntiAffinity
[root@k8s-master01 8]# kubectl explain pod.spec.affinity.podAntiAffinity KIND: Pod VERSION: v1 FIELD: podAntiAffinity <PodAntiAffinity> DESCRIPTION: Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod in the same node, zone, etc. as some other pod(s)). Pod anti affinity is a group of inter pod anti affinity scheduling rules. FIELDS:
# 软亲和,最好不在一起,能不在一起就不在一起 preferredDuringSchedulingIgnoredDuringExecution <[]WeightedPodAffinityTerm> The scheduler will prefer to schedule pods to nodes that satisfy the anti-affinity expressions specified by this field, but it may choose a node that violates one or more of the expressions. The node that is most preferred is the one with the greatest sum of weights, i.e. for each node that meets all of the scheduling requirements (resource request, requiredDuringScheduling anti-affinity expressions, etc.), compute a sum by iterating through the elements of this field and adding "weight" to the sum if the node has pods which matches the corresponding podAffinityTerm; the node(s) with the highest sum are the most preferred. # 硬亲和,一定不能在一起 requiredDuringSchedulingIgnoredDuringExecution <[]PodAffinityTerm> If the anti-affinity requirements specified by this field are not met at scheduling time, the pod will not be scheduled onto the node. If the anti-affinity requirements specified by this field cease to be met at some point during pod execution (e.g. due to a pod label update), the system may or may not try to eventually evict the pod from its node. When there are multiple elements, the lists of nodes corresponding to each podAffinityTerm are intersected, i.e. all terms must be satisfied.
(2)Pod反亲和性 - 软策略
[root@k8s-master01 8]# cat 7.podAntiAffinity.preferred.yaml apiVersion: v1 kind: Pod metadata: name: pod-antiaff-prefer labels: app: pod-aff spec: containers: - name: myapp image: myapp:v1.0 affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - pod-1 topologyKey: kubernetes.io/hostname
4.Pod 期望:容器组:容器名、基于镜像版本、亲和性:pod 反亲和性:软策略:权重、亲和性运算:匹配标签:标签运算符:key 值、运算符、value 值、拓扑域
[root@k8s-master01 8]# kubectl apply -f test.yaml pod/pod-demo created [root@k8s-master01 8]# kubectl get pod -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS pod-demo 1/1 Running 0 24s 10.244.58.217 k8s-node02 <none> <none> app=pod-1 [root@k8s-master01 8]# kubectl apply -f 7.podAntiAffinity.preferred.yaml pod/pod-antiaff-prefer created # 可以使用上面循环体,当 pod-demo 固定在 node02,pod-antiaff-prefer 会一直启动在 node01,当再启动一个 pod-demo 让他固定在 node01 时,pod-antiaff-prefer 启动在那个节点都烦,但是也不得不启动,所以这两个烦的pod所在节点,也就无所谓启动在那个节点了 [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-antiaff-prefer 1/1 Running 0 7s 10.244.85.252 k8s-node01 <none> <none> pod-demo 1/1 Running 0 61s 10.244.58.217 k8s-node02 <none> <none> # nodeName 固定节点,后面会讲,这里主要模拟两个 Pod 分布在 pod-antiaff-prefer 都烦的节点上,pod-antiaff-prefer 仍会启动 [root@k8s-master01 8]# cat test.new.yaml apiVersion: v1 kind: Pod metadata: name: pod-demo-1 namespace: default labels: app: pod-1 spec: nodeName: k8s-node01 containers: - name: myapp-1 image: myapp:v1.0 [root@k8s-master01 8]# kubectl apply -f test.new.yaml pod/pod-demo-1 created [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-antiaff-prefer 1/1 Running 0 4m43s 10.244.85.252 k8s-node01 <none> <none> pod-demo 1/1 Running 0 5m37s 10.244.58.217 k8s-node02 <none> <none> pod-demo-1 1/1 Running 0 6s 10.244.85.255 k8s-node01 <none> <none> # 既然两个都烦,就无所谓那个节点了,会随机启动 [root@k8s-master01 8]# for i in `seq 10`;do kubectl delete -f 7.podAntiAffinity.preferred.yaml;kubectl apply -f 7.podAntiAffinity.preferred.yaml;kubectl get pod -o wide ;done pod "pod-antiaff-prefer" deleted pod/pod-antiaff-prefer created NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-antiaff-prefer 0/1 ContainerCreating 0 0s <none> k8s-node02 <none> <none> pod-demo 1/1 Running 0 6m32s 10.244.58.217 k8s-node02 <none> <none> pod-demo-1 1/1 Running 0 61s 10.244.85.255 k8s-node01 <none> <none> pod "pod-antiaff-prefer" deleted pod/pod-antiaff-prefer created NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-antiaff-prefer 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none> pod-demo 1/1 Running 0 6m40s 10.244.58.217 k8s-node02 <none> <none> pod-demo-1 1/1 Running 0 69s 10.244.85.255 k8s-node01 <none> <none> pod "pod-antiaff-prefer" deleted
..........
(3)Pod反亲和性 - 硬策略
[root@k8s-master01 8]# cat 8.podAntiAffinity.perferred.yaml apiVersion: v1 kind: Pod metadata: name: pod-antiaff-req labels: app: pod-aff-req spec: containers: - name: myapp image: myapp:v1.0 affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - pod-1 topologyKey: kubernetes.io/hostname
4.Pod 期望:容器组:容器名、基于镜像版本、亲和性:pod 反亲和性:硬策略:匹配标签:标签运算符:key 值、运算符、value 值、拓扑域
# 两个 pod 都是烦的,但却分布两个节点,所以反亲和硬策略没有可调度节点 [root@k8s-master01 8]# kubectl get pod -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS pod-demo 1/1 Running 0 26m 10.244.58.217 k8s-node02 <none> <none> app=pod-1 pod-demo-1 1/1 Running 0 21m 10.244.85.255 k8s-node01 <none> <none> app=pod-1 [root@k8s-master01 8]# kubectl apply -f 8.podAntiAffinity.perferred.yaml pod/pod-antiaff-req created [root@k8s-master01 8]# kubectl get pod -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS pod-antiaff-req 0/1 Pending 0 29s <none> <none> <none> <none> app=pod-aff-req pod-demo 1/1 Running 0 30m 10.244.58.217 k8s-node02 <none> <none> app=pod-1 pod-demo-1 1/1 Running 0 24m 10.244.85.255 k8s-node01 <none> <none> app=pod-1 # 当删除一个 烦的 pod 后,pod-antiaff-req 有一个不烦的,就部署到不烦的一个节点 [root@k8s-master01 8]# kubectl delete pod pod-demo-1 pod "pod-demo-1" deleted [root@k8s-master01 8]# kubectl get pod -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS pod-antiaff-req 1/1 Running 0 52s 10.244.85.192 k8s-node01 <none> <none> app=pod-aff-req pod-demo 1/1 Running 0 30m 10.244.58.217 k8s-node02 <none> <none> app=pod-1
8.2.4 亲和性 总结
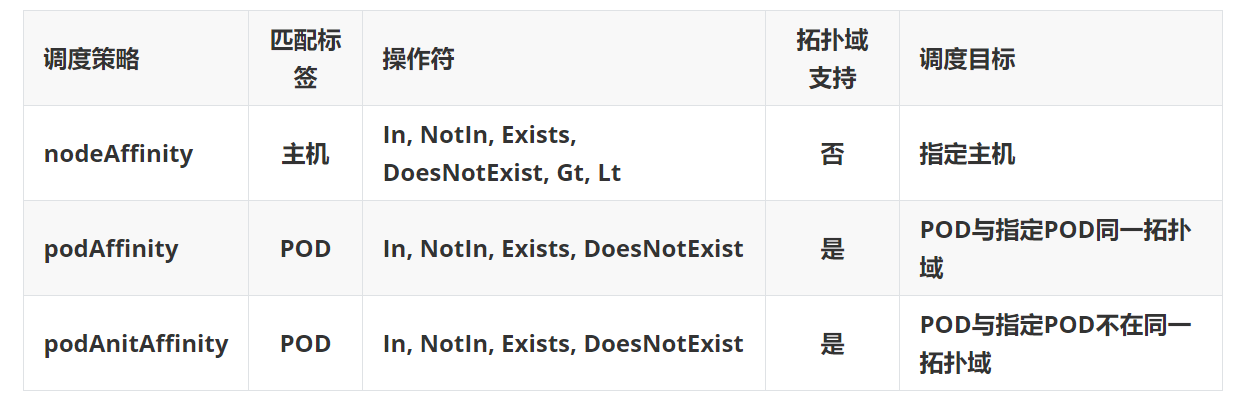
Gt、Lt:在节点添加 cpu 核心数 标签,进行高密度运算,软亲和 cpu核心数高的节点(schedule正常调度是不具备访问pod核心数,但是我估计可以后面通过RBAC也可以实现 cpu核心数的 Gt、Lt)。
8.3 容忍与污点
——— 一种排斥的特性
8.3.1 污点与容忍初识
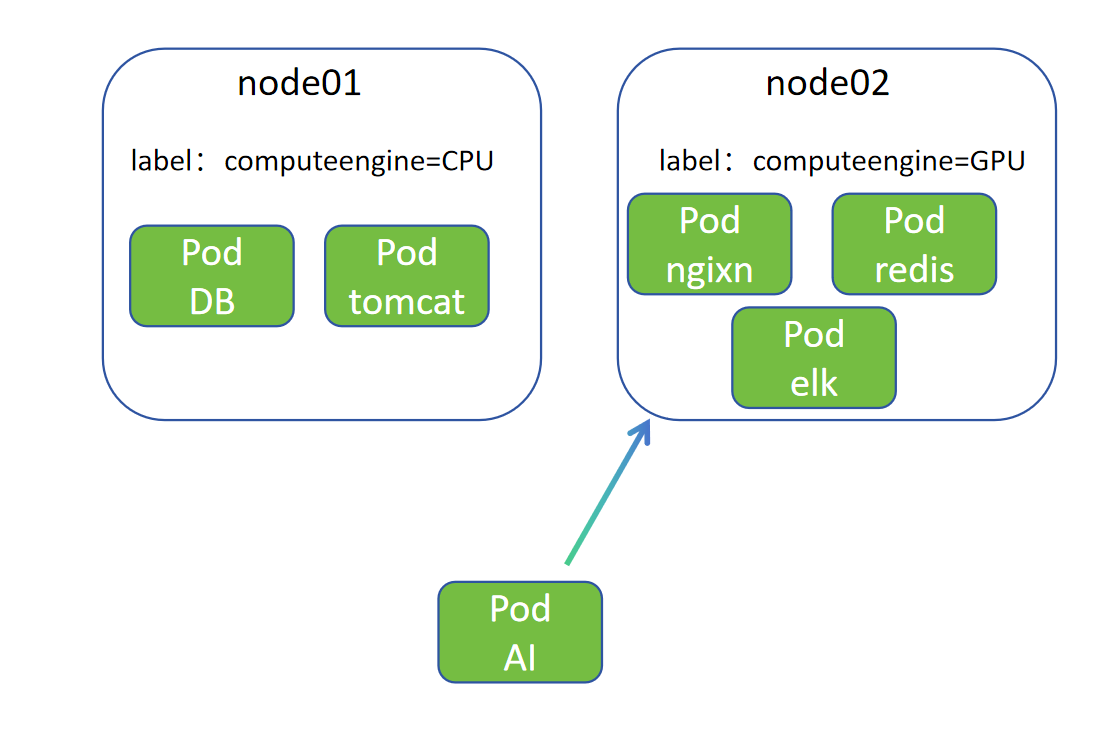
1.Node01 节点绑定 CPU,Node02 节点绑定 GPU,当节点未做任何污点情况,调度器正常预选、优选调度
2.当部署 AI Pod 需要高算力,需要调度到 GPU 节点上,但是 Node01、Node02 此前因部署其他 Pod 已经分配资源(cpu、磁盘),导致 Node02 资源不足以部署 AI Pod(因为cpu、磁盘不足,但是GPU没有被消耗)
3.未学习污点前解决思路:其他 Pod 软亲和 CPU,AI Pod 硬亲和 GPU,但是这种需要在每个 Pod 上打 软亲和标签
4.污点作用:有了污点,只有在 Pod 上做了容忍,Pod 才能调度到有污点的节点,否则不调度(与默认右侧通行类似,需要不右侧通行才标注,而不是和亲和性一样,每条路都提示右侧通行)
总结:有污点,不惧怕,主要是看能不能容忍的了污点,但能容忍污点的节点也不意味着就一定可以被调度,多个节点满足还要参加预选、优选
8.3.2 污点
(1)概念
污点Taint 和 容忍toleration 相互配置,可以用来避免 pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 污点taint,这表示对于那些不能容忍这些 污点taint 的 pod,是不会被该节点接受的。如果将 容忍toleration 应用于 pod 上,则表示这些 pod 可以(但不要求)被调度到具有匹配 污点taint 的节点上(能容忍污点,不是就一定会被部署 Pod)
(2)组成
key=value:effect
每个污点有一个 key 和 value 作为污点的标签、值,其中 value 可以为空, effect 描述污点的作用。当前 污点taint effect 支持如下三个选项:
NoSchedule:表示 k8s 不会将 Pod 调度到具有该污点的 Node 上(不调度)
PreferNoSchedule:表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上(尽量不调度)
NoExecte:表示 k8s 不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去(不仅不调度还驱逐其上Pod)
(3)实验
# 查看污点,node-role.kubernetes.io/control-plane 是 key,没有 value 为空,NoSchedule 调度策略 [root@k8s-master01 8]# kubectl describe node k8s-master01 Name: k8s-master01 ........ Taints: node-role.kubernetes.io/control-plane:NoSchedule ........ # 添加污点,一个节点可以配置多个污点 [root@k8s-master01 8]# kubectl taint node k8s-master01 computeengine=GPU:NoSchedule node/k8s-master01 tainted [root@k8s-master01 8]# kubectl describe node k8s-master01 Name: k8s-master01 ........ Taints: computeengine=GPU:NoSchedule node-role.kubernetes.io/control-plane:NoSchedule ........ # 去除污点 [root@k8s-master01 8]# kubectl taint node k8s-master01 computeengine=GPU:NoSchedule- node/k8s-master01 untainted [root@k8s-master01 8]# kubectl describe node k8s-master01 Name: k8s-master01 ........ Taints: node-role.kubernetes.io/control-plane:NoSchedule ........ # 去掉 官方自带的 污点,虽然没有 value ,但是要带上 = 号,所有没有 value 污点去除都是这样(亲测不加也可以) [root@k8s-master01 8]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane=:NoSchedule- node/k8s-master01 untainted [root@k8s-master01 8]# kubectl describe node k8s-master01 Name: k8s-master01 ........ Taints: <none> ........ # 再次部署之前第五章学习的 daemonset 控制器资源,可以部署 k8s-master01,因为之前被打了污点 [root@k8s-master01 8]# cat 9.daemonset.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: daemonset-demo labels: app: daemonset-demo spec: selector: matchLabels: name: daemonset-demo template: metadata: labels: name: daemonset-demo spec: containers: - name: daemonset-demo-container image: myapp:v1.0 [root@k8s-master01 8]# kubectl apply -f 9.daemonset.yaml daemonset.apps/daemonset-demo created [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES daemonset-demo-cpm8c 1/1 Running 0 4s 10.244.32.147 k8s-master01 <none> <none> daemonset-demo-q89pj 1/1 Running 0 4s 10.244.85.253 k8s-node01 <none> <none> daemonset-demo-x9bqc 1/1 Running 0 4s 10.244.58.225 k8s-node02 <none> <none>
8.3.3 容忍
(1)容忍早已存在
# 加回官方原污点策略 [root@k8s-master01 8]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule node/k8s-master01 tainted [root@k8s-master01 8]# kubectl describe node k8s-master01 Name: k8s-master01 ........ Taints: node-role.kubernetes.io/control-plane:NoSchedule ........ [root@k8s-master01 8]# kubectl get pod -n kube-system |grep k8s-master01 etcd-k8s-master01 1/1 Running 37 (7h17m ago) 28d kube-apiserver-k8s-master01 1/1 Running 47 (7h17m ago) 28d kube-controller-manager-k8s-master01 1/1 Running 37 (7h17m ago) 28d kube-scheduler-k8s-master01 1/1 Running 37 (7h17m ago) 28d [root@k8s-master01 8]# kubectl get daemonset -n kube-system NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE calico-node 3 3 3 3 3 kubernetes.io/os=linux 28d kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 28d # 运算符存在 operator: Exists ,代表所有污点都可以容忍 [root@k8s-master01 8]# kubectl get daemonset kube-proxy -n kube-system -o yaml ........ tolerations: - operator: Exists ........
(2)概念
设置了污点的 Node 将根据 污点taint 的 effect:NoSchedule(不调度)、PreferNoSchedule(尽量不调度)、NoExecute(不调度并驱逐) 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。但可以在 Pod 上设置容忍(Toleration),意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上
节点需要更新、下线、迭代:可以通过污点将 Pod 驱逐,然后再对节点、对集群做下线操作
(3)容忍设置
tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoExecute" tolerationSeconds: "3600"
1.容忍:key 值、运算符、value 值、容忍策略、驱逐的容忍时间
(4)特殊类型
1.当不指定 value 时,表示容忍所有的污点 value(相同的 key2,无论有没有 value 都可以容忍)
tolerations: - key: "key2" operator: "Equal" effect: "NoExecute"
2.当不指定 key 值时,表示容忍所有的污点 key(表示无论什么 key 和 value 都可以容忍)
tolerations: operator: "Exists"
3.当不指定 effect 值时,表示容忍所有的污点作用(相同的 key,无论有没有 value 都可以容忍)
tolerations: - key: "key" operator: "Exists"
4.有多个 Master 存在时,防止资源浪费,可以设置(多主集群时,各组件高可用,运行有保障,同时设置成 PreferNoScheudle,当流量增大,主节点也可以参加调度,防止突然“雪崩”,为增加工作节点赢得时间)
# 将主节点 master01 设置为 尽量不调度,注意:污点要先删除再添加,不能在原来上改,那样将变成增加污点 [root@k8s-master01 ~]# kubectl describe node k8s-master01 .......... Taints: node-role.kubernetes.io/control-plane:NoSchedule .......... [root@k8s-master01 ~]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule- node/k8s-master01 untainted [root@k8s-master01 ~]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane:PreferNoSchedule node/k8s-master01 tainted [root@k8s-master01 ~]# kubectl describe node k8s-master01 .......... Taints: node-role.kubernetes.io/control-plane:PreferNoSchedule ..........
# 开始时不调度,Pod 数量 10 -> 100 -> 150 -> 300 工作节点压力过大时,才会往 master01 上调度 [root@k8s-master01 ~]# kubectl create deployment mydeployment --image=myapp:v1 --replicas=10 deployment.apps/mydeployment created [root@k8s-master01 ~]# kubectl scale deployment mydeployment --replicas=300 deployment.apps/mydeployment scaled [root@k8s-master01 ~]# kubectl get pod -o wide|grep k8s-master01|wc -l 86
8.4 固定节点调度
——— 想让Pod去哪就去哪
8.4.1 指定节点调度 nodeName
将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配
[root@k8s-master01 ~]# kubectl explain pod.spec.nodeName KIND: Pod VERSION: v1 FIELD: nodeName <string> DESCRIPTION: NodeName is a request to schedule this pod onto a specific node. If it is non-empty, the scheduler simply schedules this pod onto that node, assuming that it fits resource requirements.
[root@k8s-master01 8]# cat 10.nodename.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nodename-test spec: replicas: 7 selector: matchLabels: app: nodename template: metadata: labels: app: nodename spec: nodeName: k8s-master01 containers: - name: myweb image: myapp:v1.0 ports: - containerPort: 80
4.deploymen 控制器期望:副本数、选择器、标签匹配:标签、标签值、Pod 模板:Pod 元数据:Pod 标签、Pod 标签值、Pod 期望:固定节点、容器组:容器名、基于镜像版本、端口:端口号、端口值
# 还原集群 主节点master01 污点 [root@k8s-master01 8]# kubectl describe nodes k8s-master01 Name: k8s-master01 ........ Taints: node-role.kubernetes.io/control-plane:PreferNoSchedule ........ [root@k8s-master01 8]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane:PreferNoSchedule- node/k8s-master01 untainted [root@k8s-master01 8]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule node/k8s-master01 tainted [root@k8s-master01 8]# kubectl describe nodes k8s-master01 Name: k8s-master01 ........ Taints: node-role.kubernetes.io/control-plane:NoSchedule ........
# maser01污点还原为不调度,但是仍然启动在 master01 上,说明 nodename 跳过了污点(nodename 直接匹配节点,节点存在,查看资源是否足够,足够就直接调度到固定节点) [root@k8s-master01 8]# kubectl apply -f 10.nodename.yaml deployment.apps/nodename-test created [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nodename-test-86cc596675-5ds57 1/1 Running 0 33s 10.244.32.166 k8s-master01 <none> <none> nodename-test-86cc596675-7jljm 1/1 Running 0 33s 10.244.32.161 k8s-master01 <none> <none> nodename-test-86cc596675-fmwcg 1/1 Running 0 33s 10.244.32.168 k8s-master01 <none> <none> nodename-test-86cc596675-lxpnc 1/1 Running 0 33s 10.244.32.159 k8s-master01 <none> <none> nodename-test-86cc596675-pdgg8 1/1 Running 0 33s 10.244.32.164 k8s-master01 <none> <none> nodename-test-86cc596675-vgx6n 1/1 Running 0 33s 10.244.32.163 k8s-master01 <none> <none> nodename-test-86cc596675-zstjb 1/1 Running 0 33s 10.244.32.167 k8s-master01 <none> <none>
8.4.2 指定节点标签调度 nodeSelector
通过 Kubernetes 的 label-selector 机制选择节点,由调度器调度策略匹配 label,而后调度 Pod 到目标节点,该匹配规则属于强制匹配
[root@k8s-master01 8]# kubectl explain pod.spec.nodeSelector KIND: Pod VERSION: v1 FIELD: nodeSelector <map[string]string> DESCRIPTION: NodeSelector is a selector which must be true for the pod to fit on a node. Selector which must match a node's labels for the pod to be scheduled on that node. More info: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
[root@k8s-master01 8]# cat 11.nodeselector.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nodeselect-test spec: replicas: 2 selector: matchLabels: app: nodeselect template: metadata: labels: app: nodeselect spec: nodeSelector: type: nodeselect containers: - name: myweb image: myapp:v1.0 ports: - containerPort: 80
4.deployment 期望:Pod 副本数、选择器:匹配标签:标签、标签值、Pod 模板:Pod 元数据、Pod 标签:标签、标签值、Pod 期望:节点选择器:标签、标签值、容器组:镜像名、基于镜像版本、端口:端口、端口值
[root@k8s-master01 8]# kubectl apply -f 11.nodeselector.yaml deployment.apps/nodeselect-test created # 强制约束,节点没有标签值,所以不调度 pending 状态 [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nodeselect-test-6999759c99-9mmhj 0/1 Pending 0 20s <none> <none> <none> <none> nodeselect-test-6999759c99-n5m5s 0/1 Pending 0 20s <none> <none> <none> <none> [root@k8s-master01 8]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= k8s-node01 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,domain=junnan666,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux k8s-node02 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=hdd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux # 给主节点 master01 添加标签后,仍然未调度,说明 nodeselect 考虑污点,不进行调度(与nodename不考虑污点不同) [root@k8s-master01 8]# kubectl label nodes k8s-master01 type=nodeselect node/k8s-master01 labeled [root@k8s-master01 8]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=,type=nodeselect k8s-node01 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,domain=junnan666,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux k8s-node02 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=hdd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nodeselect-test-6999759c99-9mmhj 0/1 Pending 0 2m23s <none> <none> <none> <none> nodeselect-test-6999759c99-n5m5s 0/1 Pending 0 2m23s <none> <none> <none> <none> # 给工作节点node01 添加标签后,Pod 调度,nodeselect 标签匹配成功 [root@k8s-master01 8]# kubectl label nodes k8s-node01 type=nodeselect node/k8s-node01 labeled [root@k8s-master01 8]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master01 Ready control-plane 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=,type=nodeselect k8s-node01 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,domain=junnan666,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux,type=nodeselect k8s-node02 Ready <none> 28d v1.29.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=hdd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux [root@k8s-master01 8]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nodeselect-test-6999759c99-9mmhj 1/1 Running 0 3m40s 10.244.85.224 k8s-node01 <none> <none> nodeselect-test-6999759c99-n5m5s 1/1 Running 0 3m40s 10.244.85.228 k8s-node01 <none> <none>
———————————————————————————————————————————————————————————————————————————
无敌小马爱学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号