
11.Prometheus配置Alertmanager邮箱告警
注:Prometheus 主要通过 Alertmanager 服务来转发告警,要使用 Alertmanager 通过 QQ 邮箱发送告警通知,需要配置 SMTP 服务器,并启用 QQ 邮箱的 SMTP 服务。
1 获取授权码
1.1 打开QQ邮箱的SMTP
QQ 邮箱默认不允许外部应用直接使用密码登录 SMTP 服务器,因此需要获取一个授权码
登录QQ邮箱: 设置 -> 账号
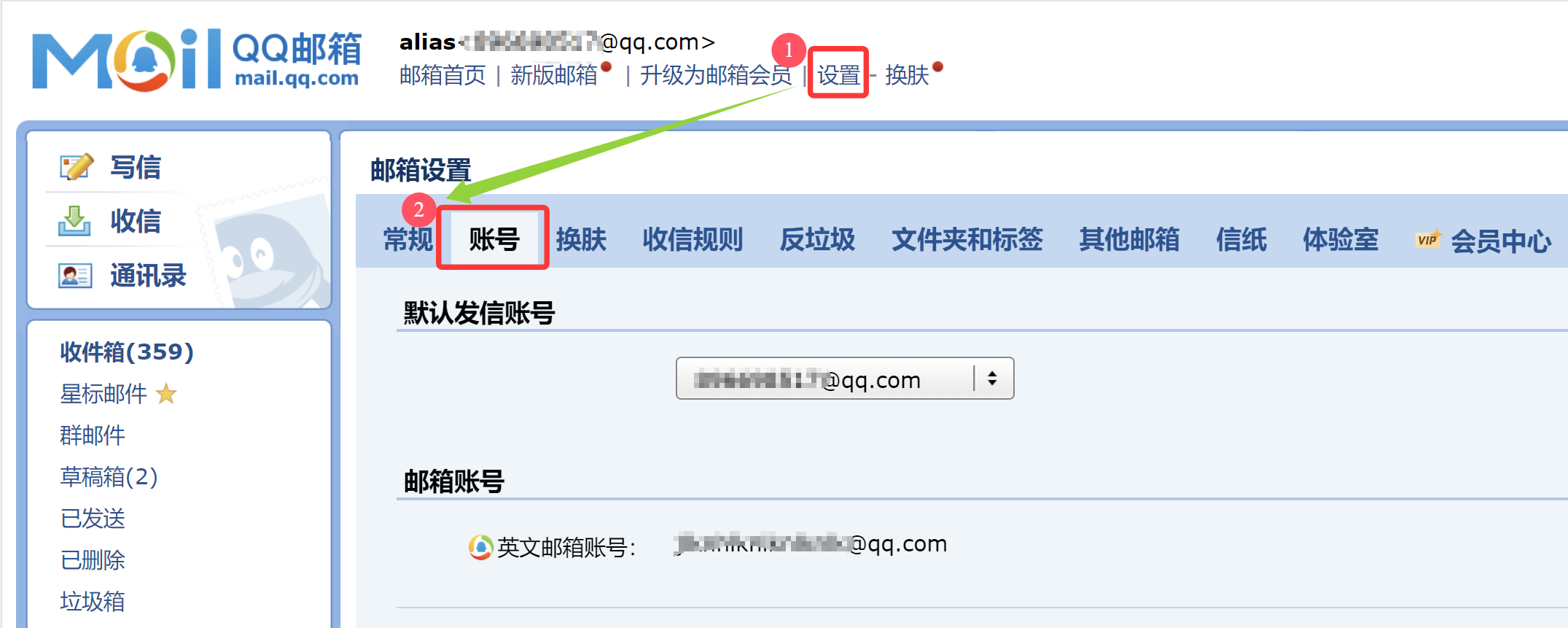
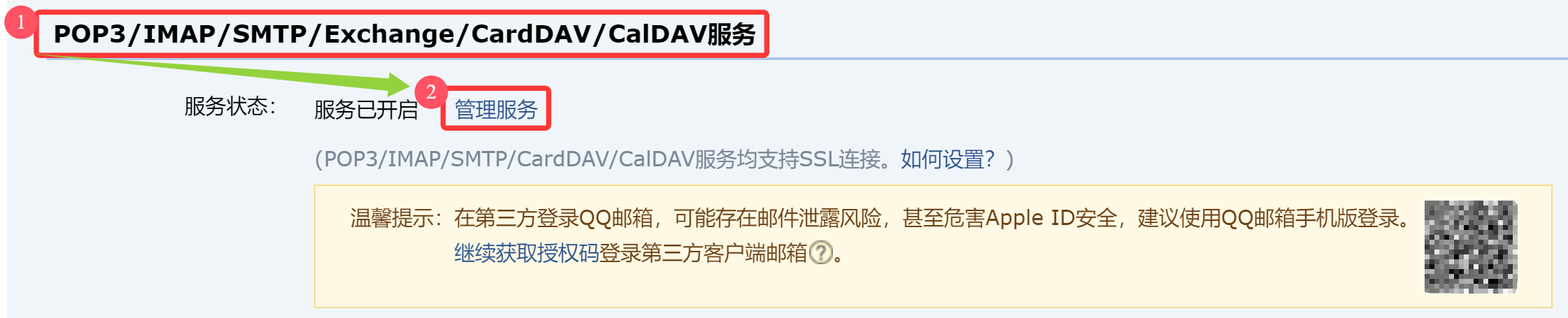
1.2 生成QQ邮箱的授权码

短信验证 请用手机 15*******17 发送短信,然后点击“我已发送”进行验证
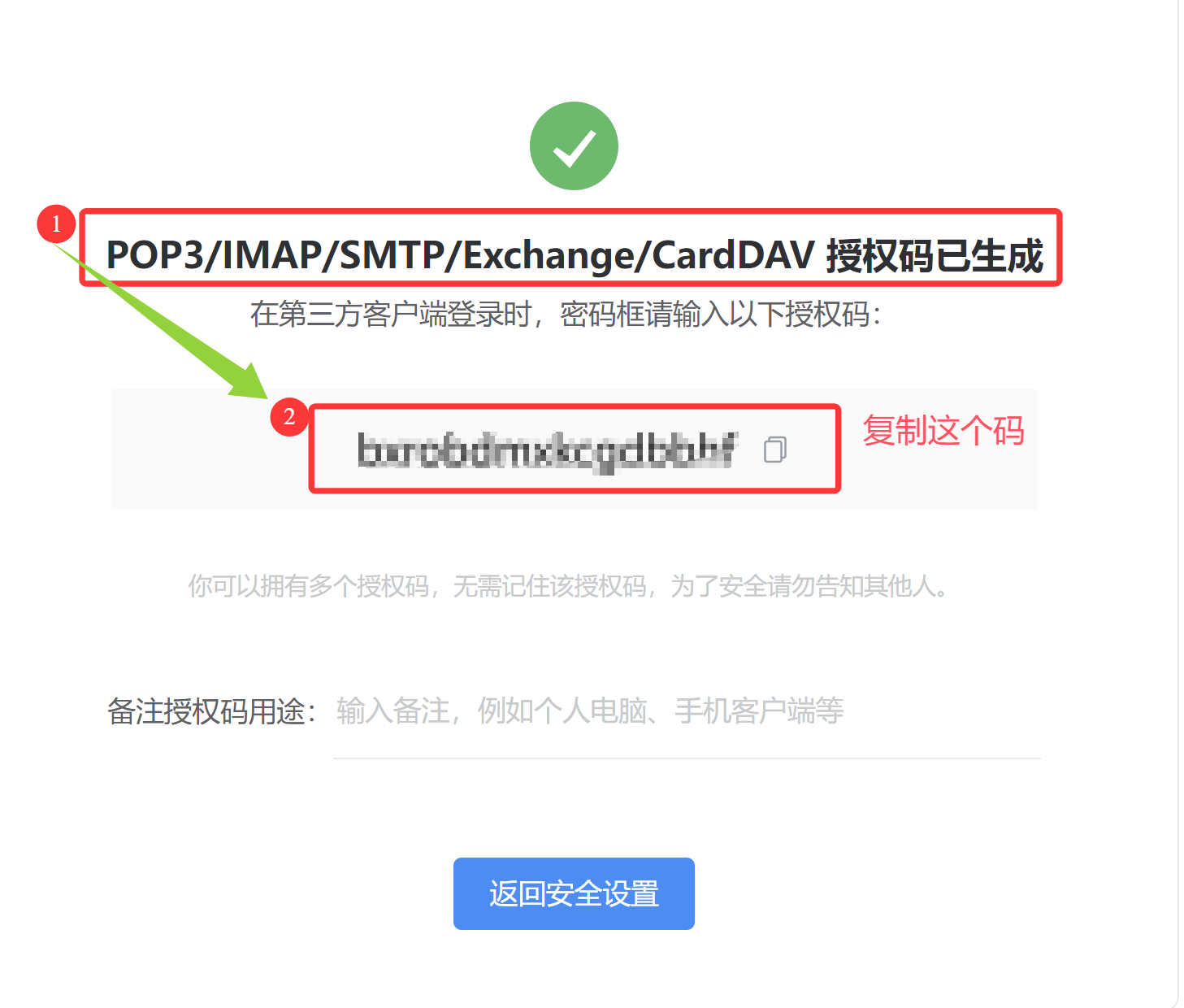
记录授权码,后续 Alertmanager 配置会用到。
2 配置 Alertmanager服务
2.1 编辑 Alertmanager 配置文件
编辑 Alertmanager 配置文件 /data/alertmanager/alertmanager.yml,增加SMTP相关配置global
[root@docker01 alertmanager]# cat alertmanager.yml global: resolve_timeout: 5m # 配置邮件发送信息 smtp_smarthost: 'smtp.qq.com:465' # 自己的邮箱 smtp_from: 'xxx@qq.com' # 自己的邮箱 smtp_auth_username: 'xxx@qq.com' # 这里是SMTP授权码,前面粘贴的 不是 QQ 邮箱密码 smtp_auth_password: 'bxroxxxxxxx' smtp_hello: 'qq.com' # 关闭tls认证 smtp_require_tls: false route: group_by: ['alertname', 'severity'] group_wait: 30s # 发送间隔 group_interval: 1m repeat_interval: 1m receiver: 'email' routes: - match: severity: critical receivers: - name: 'email' email_configs: # 自己的邮箱 - to: '896698517@qq.com' send_resolved: true # 告警抑制 inhibit_rules: # 定义触发抑制的告警条件 - source_match: severity: 'critical' # 定义被抑制的告警条件 target_match: severity: 'warning' # 当一个 severity 为 critical 的告警触发时,所有 severity 为 warning 且 alertname 和 instance 标签与 critical 告警相同的告警将被抑制,不会发送通知。 equal: ['alertname', 'severity', 'instance']
2.2 编辑 Alertmanager 告警规则
[root@docker01 rule]# cat /data/alertmanager/rule/alert.yml groups: - name: 主机状态监控 rules: - alert: 主机宕机 expr: up == 0 for: 1m labels: severity: critical annotations: summary: "{{ $labels.instance }} 主机宕机,请尽快处理" description: "{{ $labels.instance }} 已经宕机超过 1 分钟。请检查服务状态。"
2.3 重启 Alertmanager


[root@docker01 alertmanager]# systemctl restart alertmanager [root@docker01 alertmanager]# systemctl status alertmanager ● alertmanager.service Loaded: loaded (/etc/systemd/system/alertmanager.service; enabled; vendor preset: disabled) Active: active (running) since Mon 2025-04-14 10:54:41 CST; 2s ago Main PID: 6866 (alertmanager) Tasks: 8 Memory: 15.0M CGroup: /system.slice/alertmanager.service └─6866 /data/alertmanager/alertmanager --config.file=/data/alertmanager/alertmanager.yml --storage.path... Apr 14 10:54:41 docker01 systemd[1]: Started alertmanager.service. Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.392Z level=INFO source=main.go:191 msg=...910)" Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.392Z level=INFO source=main.go:192 msg=...tgo)" Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.396Z level=INFO source=cluster.go:185 m...=9094 Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.407Z level=INFO source=cluster.go:674 m...al=2s Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.466Z level=INFO source=coordinator.go:1...r.yml Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.466Z level=INFO source=coordinator.go:1...r.yml Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.473Z level=INFO source=tls_config.go:34...:9093 Apr 14 10:54:41 docker01 alertmanager[6866]: time=2025-04-14T02:54:41.473Z level=INFO source=tls_config.go:35...:9093 Apr 14 10:54:43 docker01 alertmanager[6866]: time=2025-04-14T02:54:43.410Z level=INFO source=cluster.go:699 m...4113s Hint: Some lines were ellipsized, use -l to show in full.
3 测试告警
3.1 关闭收集节点信息服务
[root@docker01 ~]# systemctl stop node_exporter.service
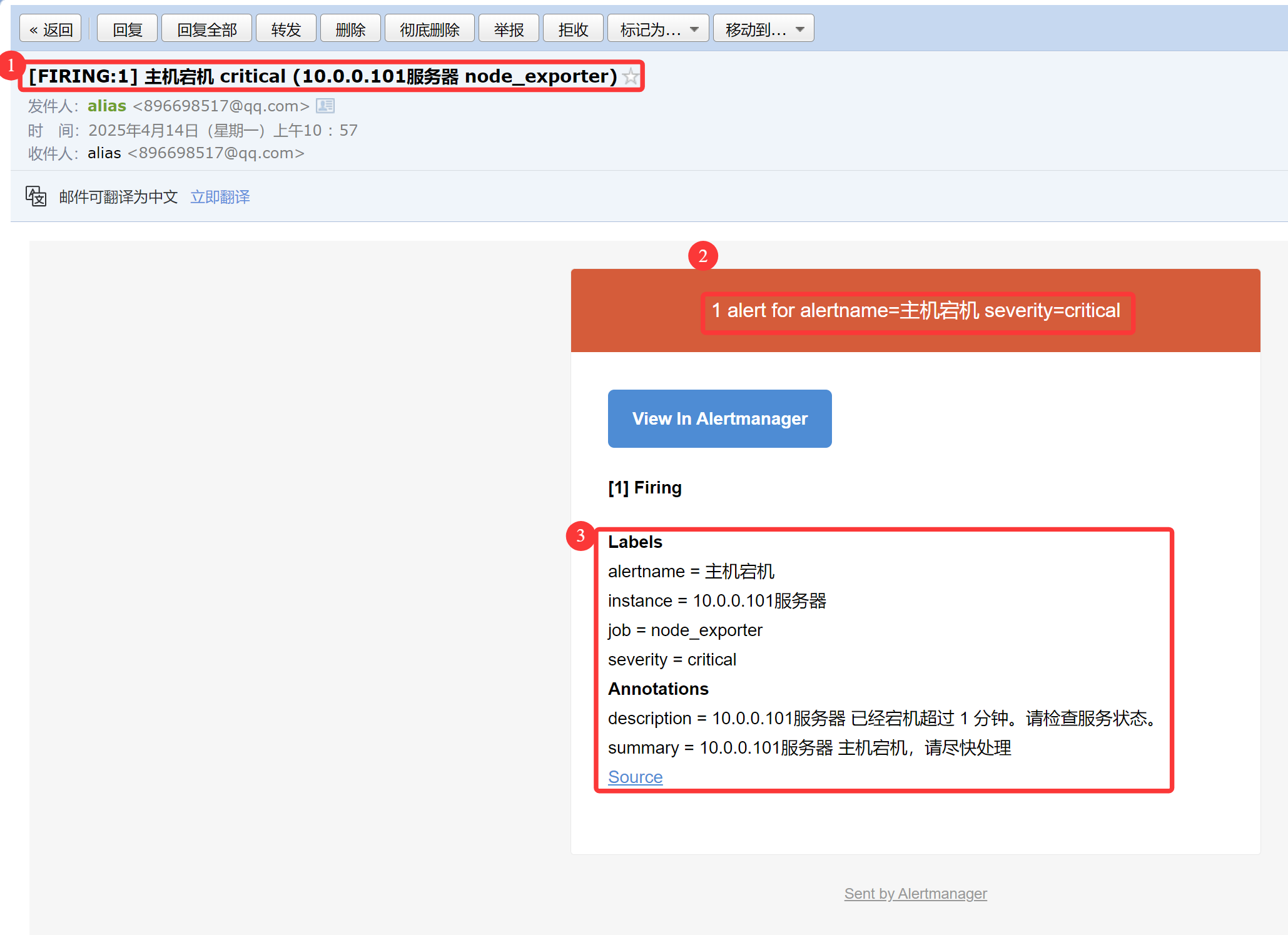
3.2 QQ邮箱收到告警短信
3.3 打开收集节点信息服务
[root@docker01 ~]# systemctl restart node_exporter.service
3.4 QQ邮箱收到告警恢复短信
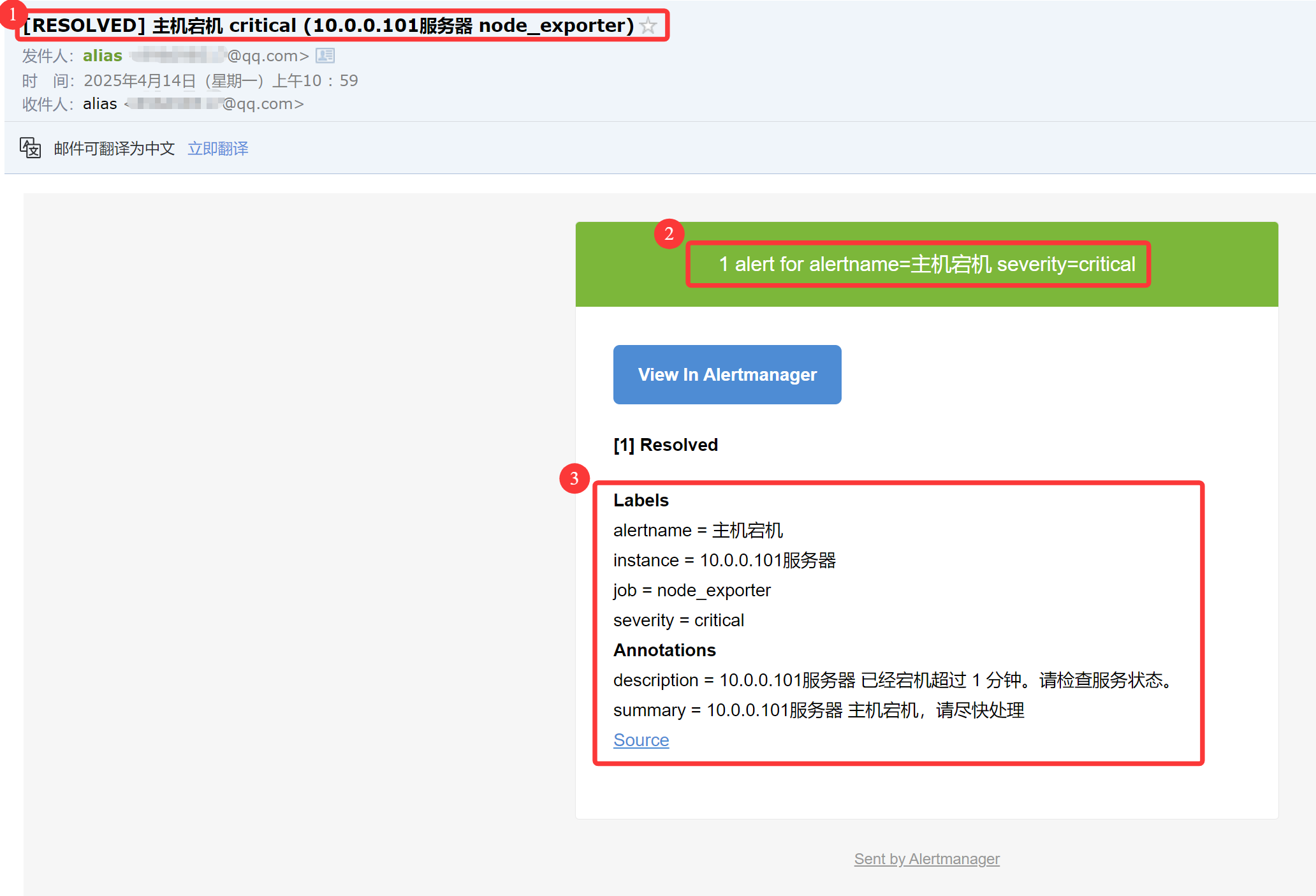
4 告警规则拓展
上面的告警规则只是简单的演示是否宕机,生产环境还会有内存,磁盘,CPU等方面的告警,下面将展示一个比较全面的告警规则
4.1 原Prometheus规则
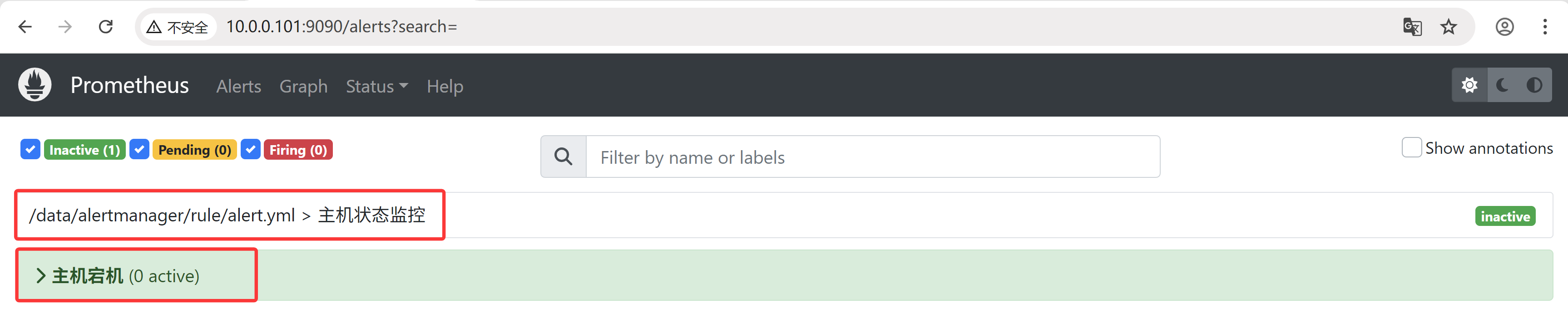
4.2 修改规则与检查语法
[root@docker01 rule]# cat /data/alertmanager/rule/alert.yml groups: - name: 主机信息监控 rules: - alert: 主机宕机 expr: up == 0 for: 1m labels: severity: critical annotations: summary: "{{ $labels.instance }} 主机宕机,请尽快处理" description: "{{ $labels.instance }} 已经宕机超过 1 分钟。请检查服务状态。" - alert: 内存使用率告警 expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80 for: 2m labels: severity: warning annotations: summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!" description: "{{ $labels.instance }} 内存使用率超过80%, 当前使用率{{ printf \"%.2f\" $value }}%." - alert: CPU使用率告警 expr: 100 - (avg by (instance, job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85 for: 1m labels: severity: warning annotations: summary: "{{ $labels.instance }} CPU使用率过高, 请尽快处理!" description: "{{ $labels.instance }} CPU使用大于85%, 当前使用率{{ printf \"%.2f\" $value }}%." - alert: 磁盘容量告警 expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80 for: 1m labels: severity: critical annotations: summary: "{{ $labels.mountpoint }} 磁盘分区使用率过高,请尽快处理!" description: "{{ $labels.instance }} 磁盘分区使用大于80%,当前使用率{{ printf \"%.2f\" $value }}%."
[root@docker01 prometheus]# /data/prometheus/promtool check config prometheus.yml Checking prometheus.yml SUCCESS: 1 rule files found SUCCESS: prometheus.yml is valid prometheus config file syntax Checking /data/alertmanager/rule/alert.yml SUCCESS: 4 rules found
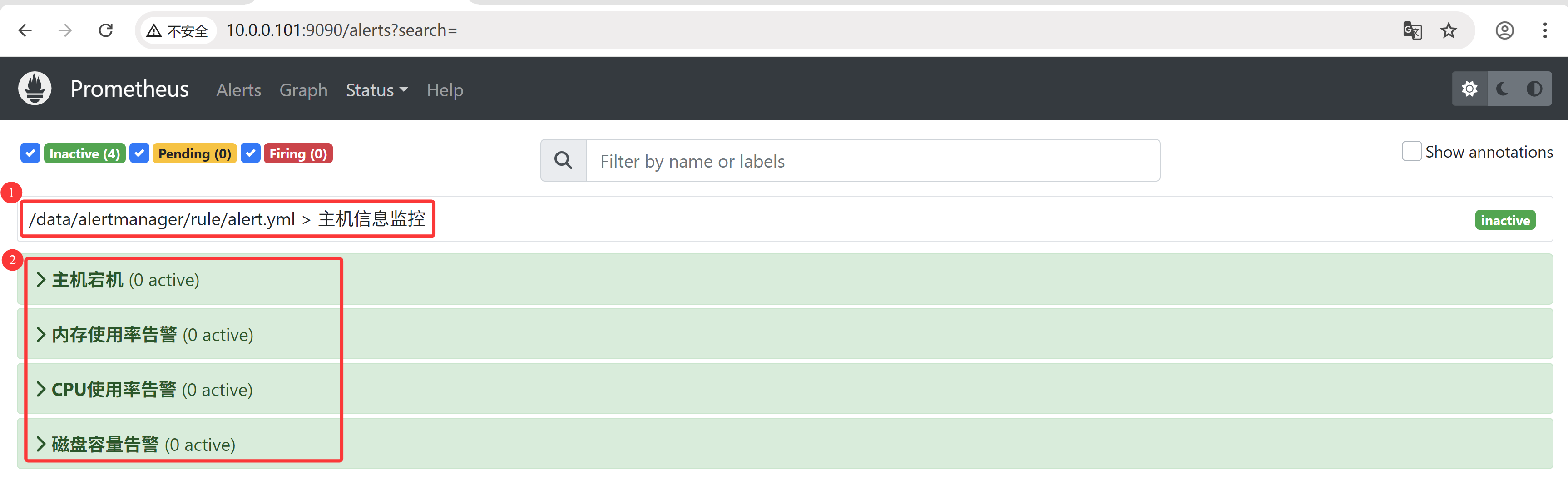
4.3 重启Prometheus
重启prometheus后,可以看到界面多了几个告警项
[root@docker01 rule]# systemctl restart prometheus.service [root@docker01 rule]# systemctl status prometheus.service ● prometheus.service - Prometheus Server Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: disabled) Active: active (running) since Mon 2025-04-14 16:05:59 CST; 9s ago Docs: https://prometheus.io/docs/introduction/overview Main PID: 8836 (prometheus) Tasks: 9 Memory: 40.9M CGroup: /system.slice/prometheus.service └─8836 /data/prometheus/prometheus --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/d... Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.742Z caller=head.go:793 level=info componen...nt=13 Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.742Z caller=head.go:793 level=info componen...nt=13 Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.742Z caller=head.go:830 level=info component=tsd…ms Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.747Z caller=main.go:1169 level=info fs_type...MAGIC Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.747Z caller=main.go:1172 level=info msg="TS...rted" Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.747Z caller=main.go:1354 level=info msg="Lo...s.yml Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.880Z caller=main.go:1391 level=info msg="up...ew=75 Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.881Z caller=main.go:1402 level=info msg="Complet…µs Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.882Z caller=main.go:1133 level=info msg="Se...sts." Apr 14 16:05:59 docker01 prometheus[8836]: ts=2025-04-14T08:05:59.882Z caller=manager.go:164 level=info compo...r..." Hint: Some lines were ellipsized, use -l to show in full.
———————————————————————————————————————————————————————————————————————————
无敌小马爱学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号