Redis-主从同步
如何设置主从同步
redis可以通过执行SLAVEOF命令或者设置slaveof配置让一个redis去复制另外一个redis.简称主从同步复制。

主从同步的步骤
2.8版本以前
redis复制功能分为同步(sync)和命令传播(command propagate)两个操作。
- sync是将从服务器的数据库状态更新到和主库一致
- 命令传播是主的数据发生了修改,主将修改的命令传播到从库里去,让从库也执行同样的修改来达到一致。
sync
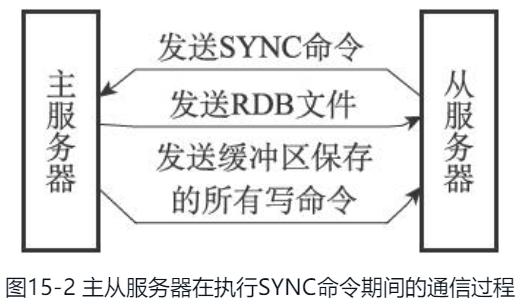
当client往redis server 发送SLAVEOF命令时,就会发生主从同步的操作。sync命令的步骤是:
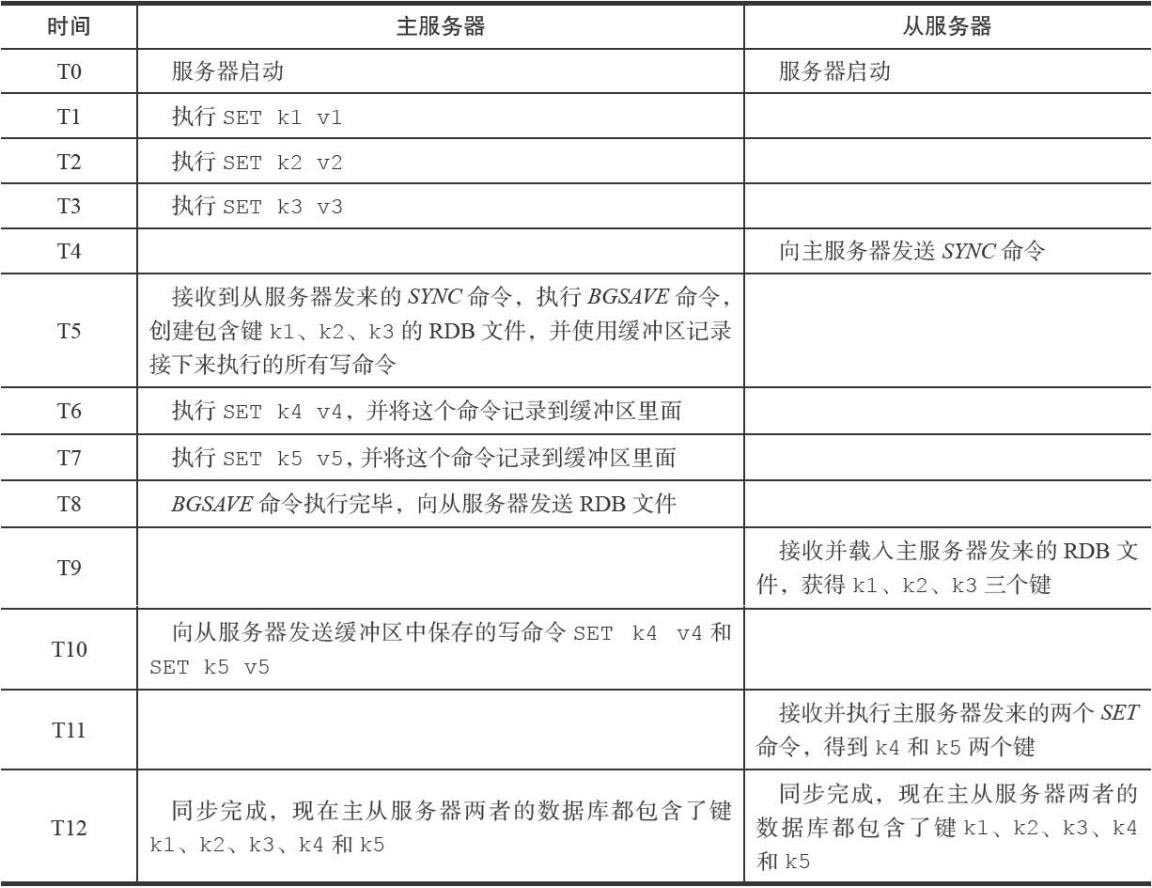
1、从服务器向主发送SYNC命令
2、主收到SYNC命令后开始执行BGSAVE命令,在后台生产一个RDB文件,并创建一个缓冲区记录从现在开始执行的所有写命令
3、当主的BGSAVE命令执行完毕后,主将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库更新至主执行BGSAVE命令时的数据库状态
4、主将记录在缓冲区的所有写命令发送给从,从执行这些写命令,将自己的数据库更新到和主一致
如下是一个主从同步的例子
命令传播:
在执行完了同步操作后,主从的数据一致了。这个时候如果主有写操作,主会将这个写操作传播给从库,让从库也执行相应的写操作。这就是命令传播。
2.8版本以前的缺陷
主从复制分为两种:
- 初次复制:从库没有与之对应的主库的数据
- 断线重连复制:处于命令传播阶段的主从因为网络原因中断了复制,后续重连后继续复制主库。
对于初次复制来说,2.8版本以前能很好的完成任务,对断线重连来说,2.8以前的同步会效率低下。例如如下例子:

2.8以前,断线重连会导致全量复制,效率肯定很低下。如果非必要,尽量不去执行SYNC命令。
另外SYNC命令也是一个非常耗时的操作:
1、主库需要执行BGSAVE命令来生成RDB文件,这个文件操作会耗费主库的大量CPU、内存和磁盘IO资源。
2、主库需要将自己生成的RBD文件发送给从库,这个发送操作会耗费主从之间大量的网络资源。
3、接收到RDB文件的从库需要载入主库的RBD文件,在载入期间从库因为阻塞不能处理命令请求。
2.8及2.8以后(统称新版本)
为了解决2.8以前版本的问题,新版本使用了PSYNC命令来替代SYNC命令执行复制时同步的操作。
PSYNC命令有全量同步(full resynchronization)和部分重同步(partial resynchronization)两种模式:
- 全量同步是初次复制的情况,完整同步的执行步骤和SYNC命令基本一致,都是让主生成RDB,以及向从库发送保持在缓冲区里面的写命令来同步的。
- 部分重同步是断线重连的复制情况,从库断了之后,主库能将断开期间的写命令发送给从库,从库接收并执行这些写命令就可以了。
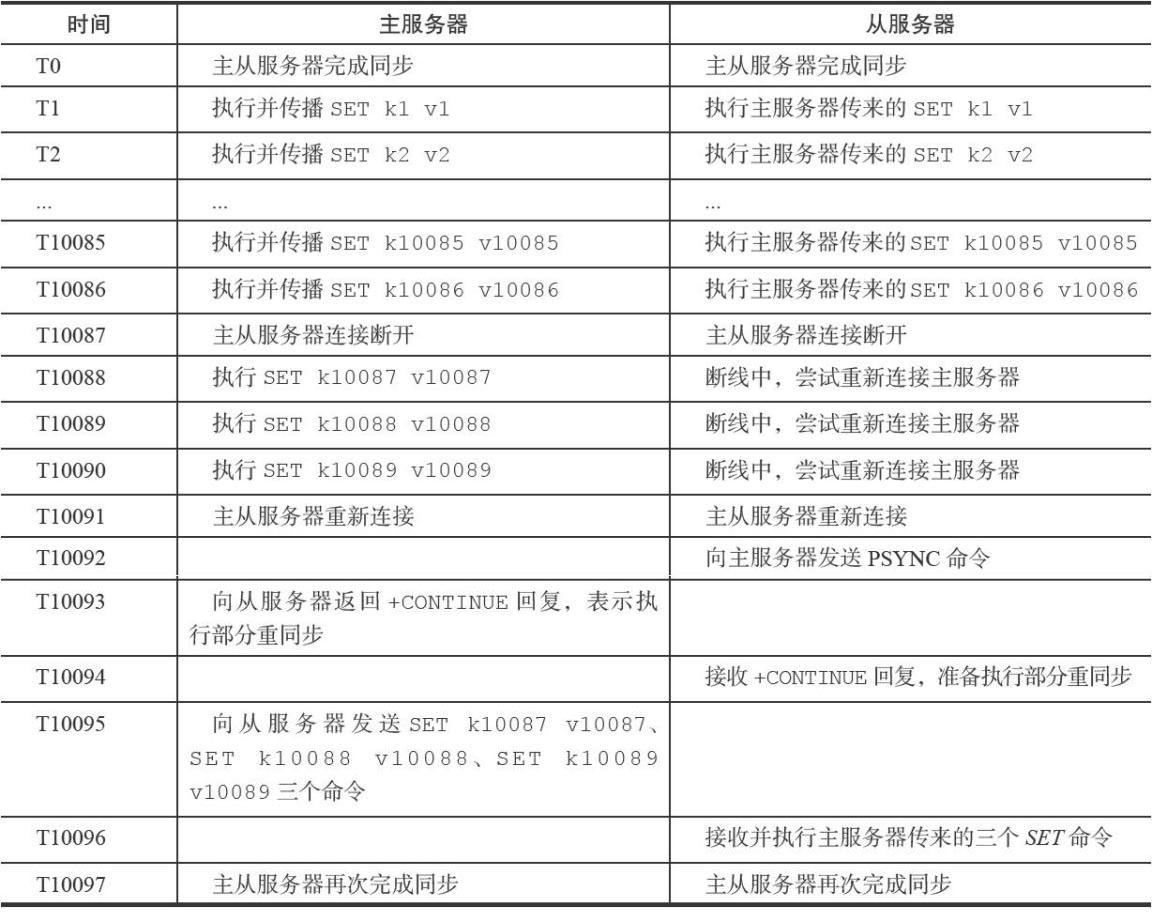

所以部分重同步 只需要将缓存起来的写命令发送到从库就好。比起SYNC应该是节省了不少的资源。
部分重同步的实现:
部分重同步的实现细节是有3部分组成:
- 主库的复制偏移量和从库的复制偏移量
- 主库的复制积压缓冲区
- 服务器的运行ID
复制偏移量
在复制的时候,主从库会分别维护一个复制偏移量:
- 主向从传播N个字节的数据时,就将自己的复制偏移量的值加上N
- 从库每次接受到主库传过来的N个字节数据时,将自己的复制偏移量的值加上N
例如:

有了偏移量就能很好的判断主从是否一致:
- 如果主从的偏移量一致,则表示主从的数据时一致的
- 如果主从的偏移量不一致,表示主从的数据不一致
问题:如下图,如果主从的偏移量不一致(A的offset=10086,主的offset=10119).那么此时是做全量复制还是部分重同步呢?主又是如何补偿从在离线期间丢失的数据呢?这就要看 复制积压缓冲区 了。
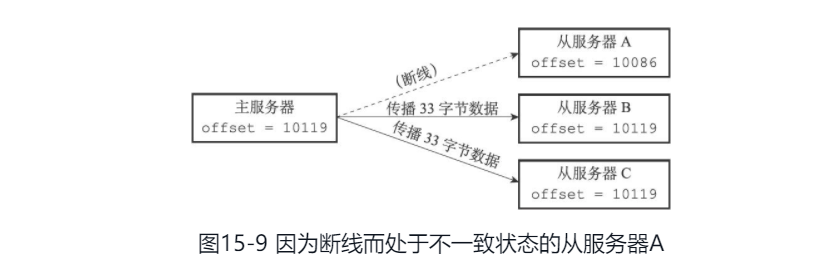
复制积压缓冲区
复制积压缓冲区是主库维护的一个定长的先进先出(FIFO)的队列。
在主进行命令传播的时候,它不仅会将写命令发送给所有的从服务器,也会将写命令入队到复制积压缓冲区。
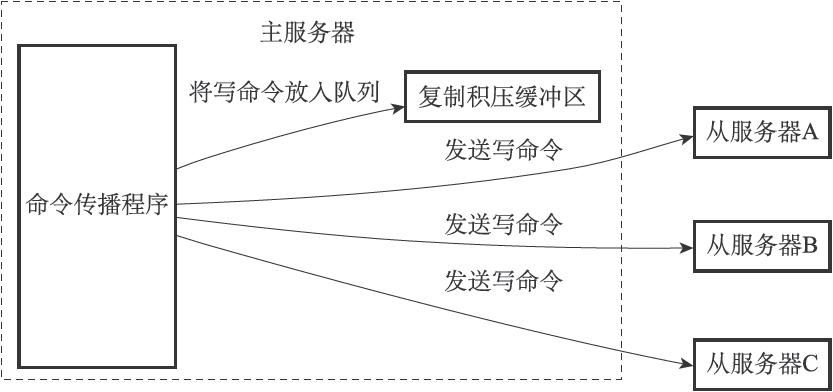
所以主的复制积压缓冲区会保持一部分最近传播的写命令,并且 复制积压缓冲区 会为队列中的每个字节记录相应的复制偏移量。
当从服务器连上主服务器后,从库通过PSYNC命令将自己的复制偏移量offset发送给主库,主库会根据这个offset决定是全量复制还是部分重同步;
- 如果从库的offset在缓冲区的范围内 (即从库离线的时候的,主库的新增写数据还都在缓冲区内),那么主选择 部分重同步。
- 相反,如果从库的offset已经不在缓冲区内 (即从库离线后,主库的新增写数据已经超出了缓冲区的容量了),那么主库选择全量同步。

redis复制积压缓冲区默认大小为1M,如果主有大量写命令,或者从离线后重连所需时间很长,那么这个缓冲区的大小就需要调整了。
如果这个复制积压缓冲区的大小设置不恰当,那么PSYNC命令的复制重同步模式就不能正常发挥作用了。积压缓冲区的大小可以根据公式来计算。
second*write_size_per_second
- second 是从库断线后重新连上主库所需的平均时间以秒计算
- write_size_per_second 是每秒主库写入的数据量,以协议格式的写命令的长度总和
例如:如果主每秒写入1M数据,而从库离线重连需要5s才能重连到主库,那么复制及压缓冲区的大小不能低于5M. 通常的配置方式是secondwrite_size_per_second2 这样可以保证大部分离线情况都能部分重同步来处理了。
服务运行ID
部分重同步还需要用到服务器运行ID:
- 每个redis服务器都有自己的runID
- runID在服务器启动时,自动生成,由40个随机16进制字符串组成。
当从对主初次复制,从会保存主的runID,当从离线重连后,从会向主发送自己存的主的runID,主来判断,
- 如果从发过来的runID和主自己的runID是一致的,那就说明从离线之前就是复制自己的这个主服务器,主可以尝试进行部分重同步操作
- 如果主校验从发送的runID和自己的不一致,说明从库离线之前连的不是自己的主库,主库会进行全量同步。
总结:
redis同步有两种,一种是全量同步,一种是增量同步。
全量同步发生在首次同步的时候,或者增量已经超过了缓冲区的时候。
增量同步发生在离线重连的时候。
增量同步的原理是:
1、主从在建立连接的时候,从库会存储主库的runID
2、主从在同步的时候会维护各自的偏移量
3、主库在广播命令的时候也会将写操作存储在缓冲区内一份,缓冲区的大小默认1M,建议自己去设置一下(最少要是 second*write_size_per_second,最好是2倍的最低值)
3、从库在离线重连后,先发送自己记录的主库的runID到主库,主库判断 如果runID相同(如果不同直接全量同步),再判断从库的偏移量是否在缓冲区内(如果不在,直接全量同步),如果在就进行增量同步。
参考内容:
Redis设计与实现-黄健宏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号