
ConcurrentHashMap如何保证线程安全
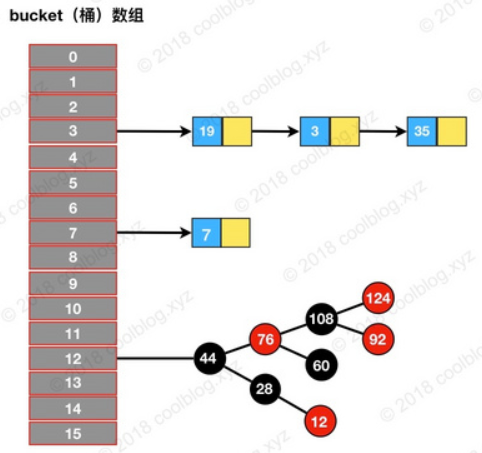
以前看过HashMap的内部实现,知道HashMap是使用Node数组+链表+红黑树的数据结构来实现,如下图所示。但是HashMap是非线程安全,在多线程环境不能够使用。
不过JDK在其并发包中为我们提供了线程安全的ConcurrentHashMap。因此,来学习以下其内部是如何保证线程安全的。
HashMap的数据结构
一、Unsafe和CAS
ConcurrentHashMap的大部分操作和HashMap是相同的,例如初始化,扩容和链表向红黑树的转变等。但是,在ConcurrentHashMap中,大量使用了U.compareAndSwapXXX
的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的
一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一
点与乐观锁,SVN的思想是比较类似的。
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentHashMap.class;
SIZECTL = U.objectFieldOffset
(k.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset
(k.getDeclaredField("transferIndex"));
BASECOUNT = U.objectFieldOffset
(k.getDeclaredField("baseCount"));
CELLSBUSY = U.objectFieldOffset
(k.getDeclaredField("cellsBusy"));
Class<?> ck = CounterCell.class;
CELLVALUE = U.objectFieldOffset
(ck.getDeclaredField("value"));
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
同时,在ConcurrentHashMap中还定义了三个原子操作,用于对指定位置的节点进行操作。这三种原子操作被广泛的使用在ConcurrentHashMap的get和put等方法中,
正是这些原子操作保证了ConcurrentHashMap的线程安全。
// 获取tab数组的第i个node
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// 利用CAS算法设置i位置上的node节点。在CAS中,会比较内存中的值与你指定的这个值是否相等,如果相等才接受
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// 利用volatile方法设置第i个节点的值,这个操作一定是成功的。
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
二、ConcurrentHashMap的put方法
接下来,我们来看下ConcurrentHashMap中最主要的put方法的实现,在put方法中调用了putVal方法,其源码如下:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable(); // table是在首次插入元素的时候初始化,lazy
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, // 如果这个位置没有值,直接放进去,由CAS保证线程安全,不需要加锁
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { // 节点上锁,这里的节点可以理解为hash值相同组成的链表的头节点,锁的粒度为头节点。
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
从上面我们可以发现ConcurrentHashMap的put方法的主要流程如下:

因此,我们可以发现JDK8中ConcurrentHashMap的实现使用的是锁分离思想,只是锁住的是一个node,而锁住Node之前的操作是基于在volatile和CAS之上无锁并且线程安全的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号