记忆集和卡表
这里说的记忆集是一般意义上的,而不是G1那种
其中, 第三种“卡精度”所指的是用一种称为“卡表”( Card Table) 的方式去实现记忆集[1], 这也是
目前最常用的一种记忆集实现形式, 一些资料中甚至直接把它和记忆集混为一谈。 前面定义中提到记
忆集其实是一种“抽象”的数据结构, 抽象的意思是只定义了记忆集的行为意图, 并没有定义其行为的
具体实现。 卡表就是记忆集的一种具体实现, 它定义了记忆集的记录精度、 与堆内存的映射关系等。
关于卡表与记忆集的关系, 读者不妨按照Java语言中HashMap与Map的关系来类比理解。
RSet记录了其他Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。
而Card Table则是一种points-out(我引用了谁的对象)的结构,每个Card 覆盖一定范围的Heap(一般为512Bytes)。
G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。
这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。每个Region都有一个对应的Rset。
我画了一个图
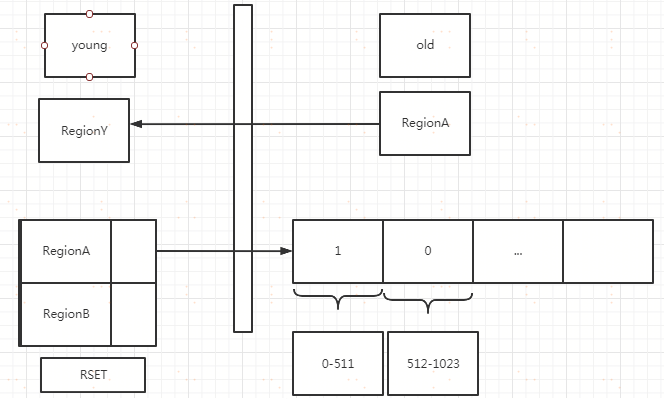
RSET可以理解为一个HashMap,key是跨带引用的其他Region的地址,value是一个卡表,卡表可以理解是一个数组,
数组的每一项代码着RegionA的内存中的一块有没有指定年轻代的引用,如果有那么可以理解成这个卡项是1。
1 为啥用卡表呢?
因为如果用对象,粒度就太小了,扫描的时候会消耗更多的时间
2 如何维护RSET呢
后置写屏障,写屏障是每个线程都有一个队列,专门记录变更后的引用关系,该队列满了之后会交给全局的处理队列,
JVM默认1秒钟处理这个全局队列一次,以此来维护引用关系的变更。而且在一个混合GC过程中的,remark阶段,会把每个线程的写屏障队列和全局队列完全清空,全部处理干净
这样,就能保证在最后的清理阶段判断垃圾是足够准确的。
引用自深入理解JVM


 浙公网安备 33010602011771号
浙公网安备 33010602011771号